
ホームページ >テクノロジー周辺機器 >AI >ガートナー、2023 年の中国のデータ分析と人工知能技術の成熟度曲線を発表
ガートナー、2023 年の中国のデータ分析と人工知能技術の成熟度曲線を発表

- PHPz転載
- 2023-09-14 15:37:10650ブラウズ
Gartner は、2026 年までに中国のホワイトカラーの仕事の 30% 以上が再定義され、生成 AI を使用および管理するスキルが非常に人気になると予測しています。
ガートナーの中国におけるデータ分析と AI の 2023 年のハイプ サイクルでは、中国のデータ、分析、AI に関連する 4 つの基本的なテーマが明らかになりました。それは、ビジネスの成果を優先する中国のデータ戦略、地域のデータと分析、および AI エコシステムです。データセンターの崩壊、そして人工知能が国家権力の新たな象徴となる。
この曲線では、最も多くのテクノロジーが予想される拡大期に入ろうとしています。 Gartner のシニア リサーチ ディレクター、Zhang Tong 氏は次のように述べています。「イノベーションは従来のボトルネックの解決策としてよく宣伝されており、ハードウェア リソースの不足、拡張性、持続可能な運用、セキュリティ リスクの軽減、テクノロジーなど、中国の CIO に共通する懸念を解決すると期待されています。 AI モデルの独立性、制御性、マルチドメインへの適用性が、明確なビジネス価値をもたらします。しかし、エンド ユーザーは、抽象的な戦略概念よりも具体的な影響を重視します。」
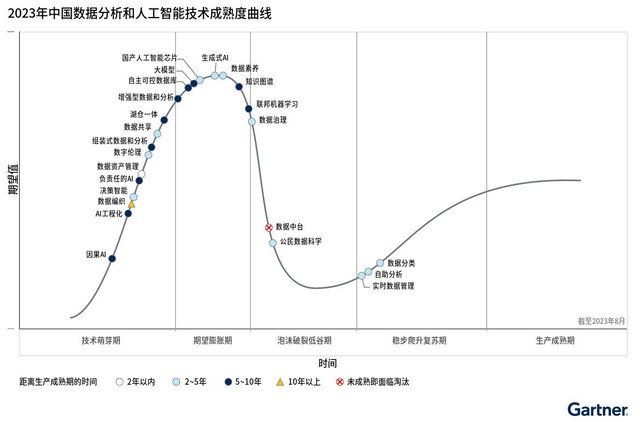
出典 : Gartner (2023 年 8 月) )
データ ウィービング
データ ウィービングは、データ統合、アクティブ メタデータ、ナレッジ グラフ、データ プロファイリング、マシンを含む、柔軟で再利用可能なデータ パイプライン、サービス、セマンティクスを取得するための設計フレームワークです。学習とデータ分類。データ ウィービングは、データ管理に対する既存の支配的なアプローチを覆し、もはやデータとユースケースに合わせて「オーダーメイド」されるのではなく、「まず観察してから使用する」ものになります。
Gartner のシニア リサーチ ディレクター、Zhang Tong 氏は次のように述べています。「データ、分析、AI のユースケースの出現と、急速に変化するデータ セキュリティ規制により、中国のデータ管理は複雑さと不確実性をもたらしています。データ ウィービングは埋没コストを最大限に活用すると同時に、データ管理インフラストラクチャに対する新たな支出の優先順位付けとコスト管理のガイダンスも提供します。"
データ資産管理
データ資産管理とは、管理を指します。 、処理と利用 業務運営にとって貴重な資産であるデータを生成するプロセス。データ資産管理は、システム内の画像、動画、ファイル、資料、トランザクションデータなど、さまざまなデータ形式に適用され、データの取得から破棄までのデータライフサイクル全体を対象として、データを同一の環境で管理することを目的としています。資産として活用し、そこから価値を創造します。
データは、新たな生産要素として、企業組織にとって競争上の優位性となっています。データは高速、多様、大量で事実に基づいているため、組織はプロセスを統合してデータの洞察を生成する必要があります。
Gartner のシニアリサーチディレクター、Zhang Tong 氏は次のように述べています。「データ資産は、運用品質と意思決定レベルを向上させるだけでなく、より多くのビジネス価値を生み出すことができます。また、新しいビジネス モデルを生成し、データを使用して「直接収益化します。しかし、価値創造が加速しているにもかかわらず、データ資産には依然として潜在的なリスクが存在します。企業組織は、規制違反や偶発的なデータ漏洩を避けるために、データ資産を注意深く管理する必要があります。」
#組み立てられたデータと分析組み立てられたデータと分析 (D&A) は、コンテナーまたはビジネス マイクロサービス ベースのアーキテクチャとデータ ウィービングの概念を活用して、既存の資産を柔軟でモジュール式のユーザー フレンドリーなデータ分析と人工知能 (AI) 機能に組み立てます。このテクノロジーは、一連のテクノロジーを使用して、データ管理および分析アプリケーションを、ローコードおよびノーコード機能をサポートするデータ分析および AI コンポーネントまたはその他のアプリケーション モジュールに変換し、適応的でインテリジェントな意思決定をサポートします。 急速に変化するビジネス環境に直面して、中国の企業や機関は機敏性を向上させ、洞察の出力をスピードアップする必要があります。 Assembled D&A は、企業組織がモジュラー データと分析機能を使用して、複数の洞察と参考情報をさまざまな対策に統合し、断片的な開発を回避するのに役立ちます。企業組織は、さまざまな使用シナリオに対処するために D&A 機能を組み立てまたは再編成することで、配信の柔軟性をさらに向上させることができます。 大規模モデル大規模モデルは、広範囲のデータセットで自己教師ありの方法でトレーニングされた大規模なパラメーター モデルであり、そのほとんどは Transformer アーキテクチャまたは拡散ディープ ニューラル ネットワーク アーキテクチャに基づいています。 . そして近い将来、マルチモーダルになる可能性があります。ビッグ モデルという名前は、その重要性とさまざまな下流の使用シナリオに幅広く適合することに由来しています。さまざまなシナリオに適応するこの機能は、モデルの十分かつ広範な事前トレーニングの恩恵を受けます。 大規模モデルは現在、自然言語処理に推奨されるアーキテクチャとなっており、コンピューター ビジョン、オーディオおよびビデオ処理、ソフトウェア エンジニアリング、化学、金融、法律に適用されています。大規模モデルから派生した一般的なサブコンセプトは、テキスト トレーニングに基づく大規模言語モデルです。 Gartner のシニアリサーチディレクター、Zhang Tong 氏は次のように述べています。「大規模なモデルは、さまざまな自然言語のユースケースにおけるアプリケーションに強化された効果を提供する可能性があるため、垂直産業やビジネス機能に大きな影響を与えるでしょう。従業員の生産性を向上させ、顧客エクスペリエンスを自動化および強化し、コスト効率よく新しい製品やサービスを作成してデジタル変革を加速できます。」データ ミドル オフィス
データ ミドル オフィス (DMO) は、組織戦略とテクノロジーの実践です。データセンターを通じて、さまざまなビジネス分野のユーザーが企業データを効率的に使用して、単一の信頼できる情報源に基づいて意思決定を行うことができます。データセンターの構築は、企業向けに組み立て可能で再利用可能なデータと分析機能を構築する方法となり、これらの機能は独自のデジタル オペレーションを提供し、テクノロジー スタックを通じてバリュー チェーン全体にわたるデジタル オペレーションを統合できます。
多くの中国企業がデータミドルエンドの手法を採用する理由は、データと分析アーキテクチャの技術的な冗長性を減らし、さまざまなシステムのデータアイランドを開放し、再利用可能なデータと分析機能を促進するためです。しかし、データセンターは多くの場合、アジャイルな D&A 機能を構築するという約束を果たせていないため、市場での地位は弱まっています。多くの組織やベンダーは、この概念を社内で採用したり、単にプロモーションから削除したりすることに消極的です。
以上がガートナー、2023 年の中国のデータ分析と人工知能技術の成熟度曲線を発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。