
ホームページ >テクノロジー周辺機器 >AI >パラメータ数1,800億、世界トップのオープンソース大型モデルFalconが正式発表! Crush LLaMA 2、パフォーマンスは GPT-4 に近い
パラメータ数1,800億、世界トップのオープンソース大型モデルFalconが正式発表! Crush LLaMA 2、パフォーマンスは GPT-4 に近い

- PHPz転載
- 2023-09-13 16:13:011106ブラウズ
一夜にして、世界で最も強力なオープンソース大型モデル Falcon 180B がネットワーク全体を爆発させました。
1,800 億のパラメータ、ファルコンは 3 兆 5,000 億のトークンでトレーニングを完了し、ハグ フェイス ランキングで直接トップになりました。
ベンチマーク テストでは、Falcon 180B が推論、コーディング、熟練度、知識テストなどのさまざまなタスクで Llama 2 を破りました。
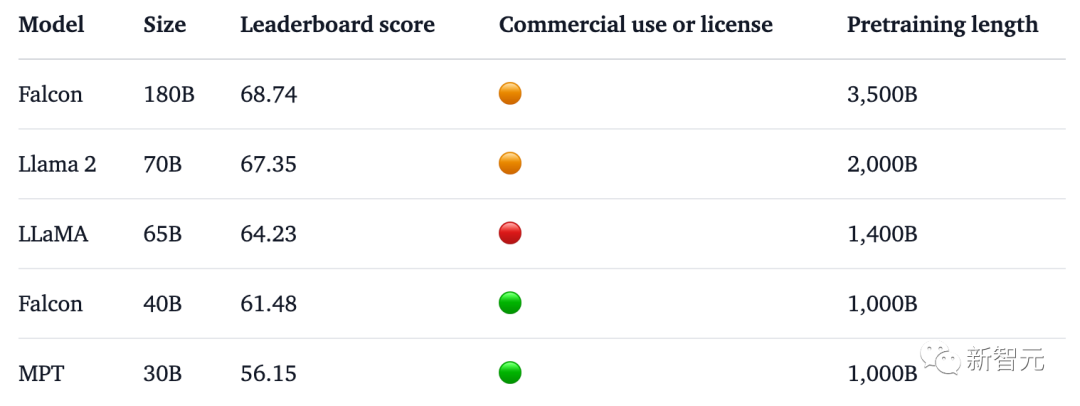
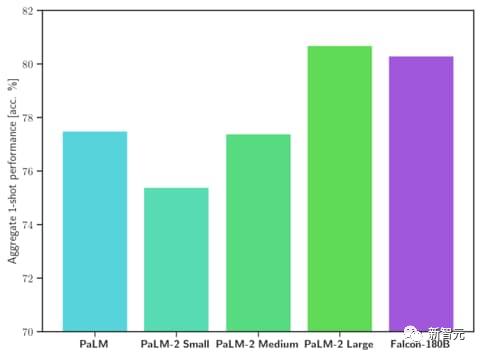
Falcon 180B は Google PaLM 2 と同等の性能を備えており、そのパフォーマンスは GPT-4 に近いです。
しかし、NVIDIA の上級科学者 Jim Fan はこれに疑問を呈しました。
-Falcon-180B のトレーニング データでは、コードのみ5%を占めます。
コードは、推論能力の向上、ツールの使用方法の習得、AI エージェントの強化に最も役立つデータです。実際、GPT-3.5 は Codex に基づいて微調整されています。
# - エンコーディングのベースライン データがありません。
コーディング能力がなければ、「GPT-3.5 より優れている」または「GPT-4 に近い」と主張することはできません。これはトレーニング後の調整ではなく、トレーニング前のレシピに不可欠な部分である必要があります。
#- パラメータが 30B を超える言語モデルの場合は、ハイブリッド エキスパート システム (MoE) を採用する時期が来ています。 これまでのところ、OSS MoE LLM
ファルコン 180B とは何ですか?

これまで、Falcon は 3 つのモデル サイズを発表しました。それぞれ1.3B、7.5B、40Bです。
公式紹介によると、Falcon 180B は 40B のアップグレード版で、アブダビにある世界有数の技術研究センターである TII によって打ち上げられ、無料で商用利用できます。 。

今回、研究者らは、モデルのスケーラビリティを向上させるためにマルチクエリ アテンションを使用するなど、ベース モデルに技術革新を加えました。
トレーニングプロセスでは、Falcon 180B は Amazon クラウド機械学習プラットフォームである Amazon SageMaker に基づいており、3.5 兆トークンのトレーニングを完了しています。最大 4096 GPU でトレーニング。
合計 GPU 計算時間、約 7,000,000。
Falcon 180B のパラメータサイズは Llama 2 (70B) の 2.5 倍であり、学習に必要な計算量は Llama 2 の 4 倍です。
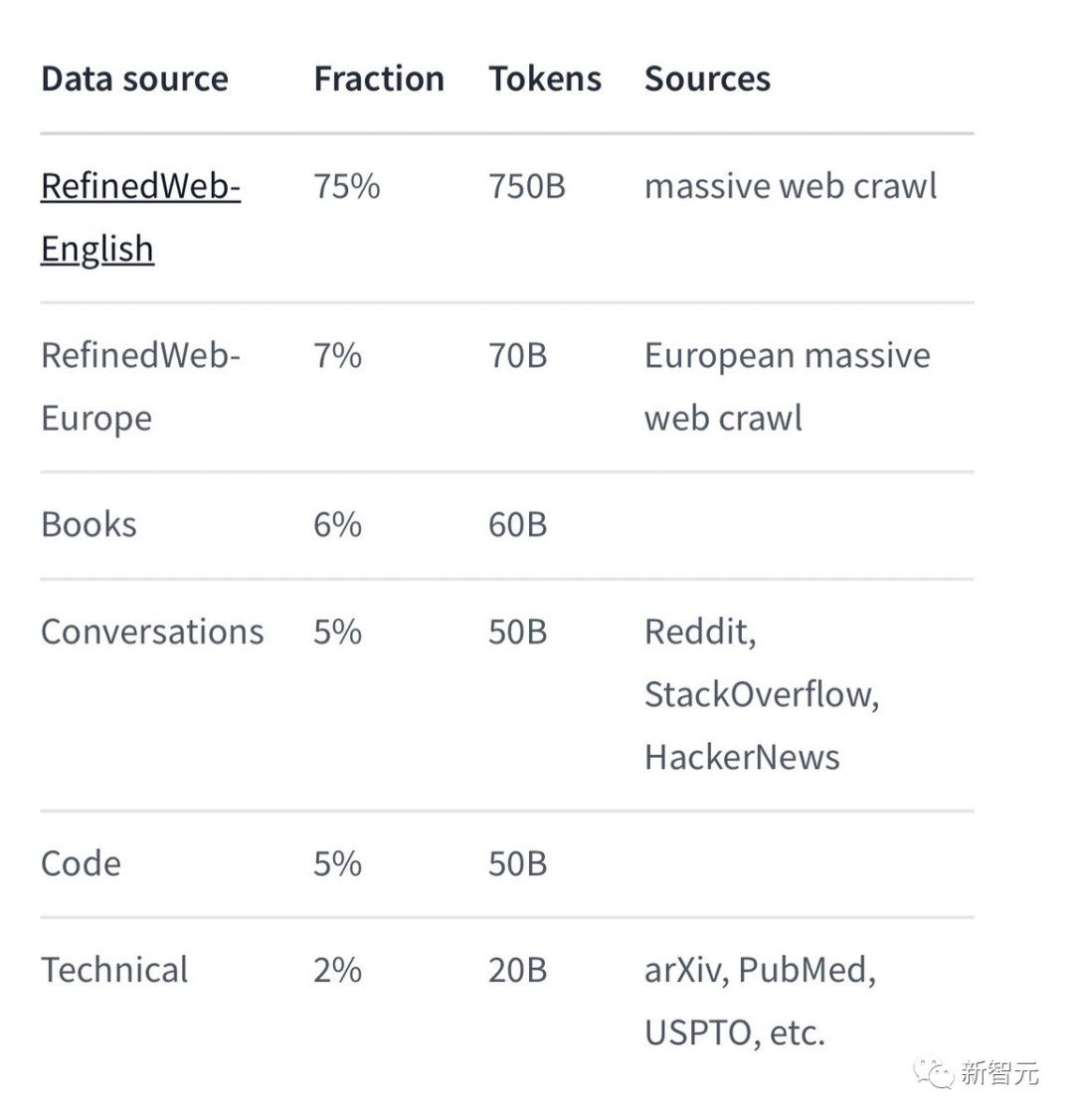
特定のトレーニング データのうち、Falcon 180B は主に RefinedWe データ セットです (約 85% を占めます)。
さらに、会話、技術文書、およびコードの一部を厳選して組み合わせてトレーニングされました。
この事前トレーニング データ セットは、3 兆 5000 億のトークンでも 1 エポック未満しか占有しないほど十分な大きさです。
Falcon 180B は現時点で「最高の」オープンソース大規模モデルであると公式に主張されており、具体的なパフォーマンスは次のとおりです:
MMLU ベンチマークでは、Falcon 180B は Llama 2 70B および GPT-3.5 よりも優れています。
HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC、ReCoRD における Google の PaLM 2-Large と同等。
また、現在、Hugging Face オープンソース大型モデル リストで最高スコア (68.74 ポイント) を獲得しており、LlaMA 2 (67.35) を上回っているオープン大型モデルです。
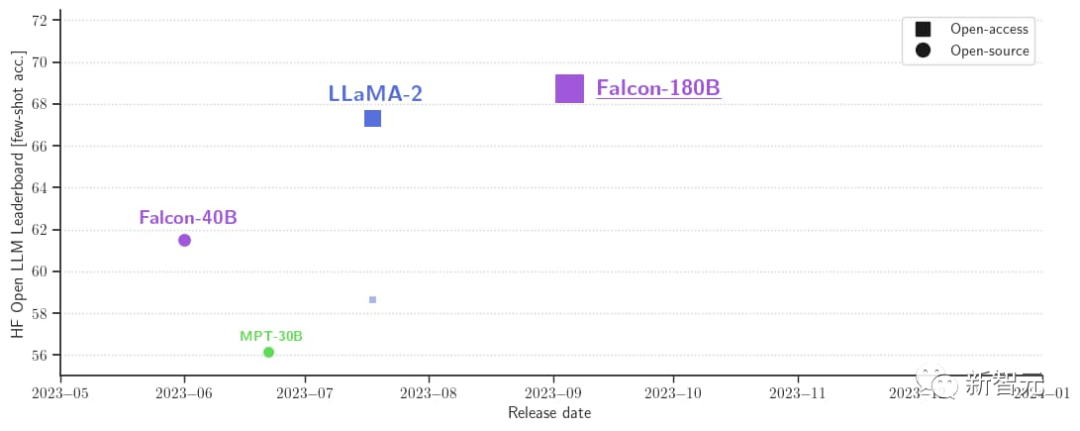
Falcon 180B を使用して開始できます
同時に、研究者はチャット対話モデル Falcon-180B もリリースしました。 -チャット。このモデルは、Open-Platypus、UltraChat、Airoboros をカバーする会話と指示のデータセットに基づいて微調整されています。

#誰でもデモ体験ができるようになりました。
アドレス: https://huggingface.co/tiiuae/falcon-180B-chat
プロンプト形式
基本モデルは大規模な会話モデルではなく、指示に従ってトレーニングされていないため、会話形式で応答しないため、プロンプト形式はありません。
事前トレーニングされたモデルは微調整に最適なプラットフォームですが、おそらく直接使用すべきではありません。対話モデルにはシンプルな対話モードがあります。
System: Add an optional system prompt hereUser: This is the user inputFalcon: This is what the model generatesUser: This might be a second turn inputFalcon: and so on
Transformers
Transformers 4.33 以降、Falcon 180B を Hugging Face エコシステムで使用およびダウンロードできるようになりました。
Hugging Face アカウントにログインし、最新バージョンのトランスフォーマーがインストールされていることを確認してください:
pip install --upgrade transformershuggingface-cli login
bfloat16
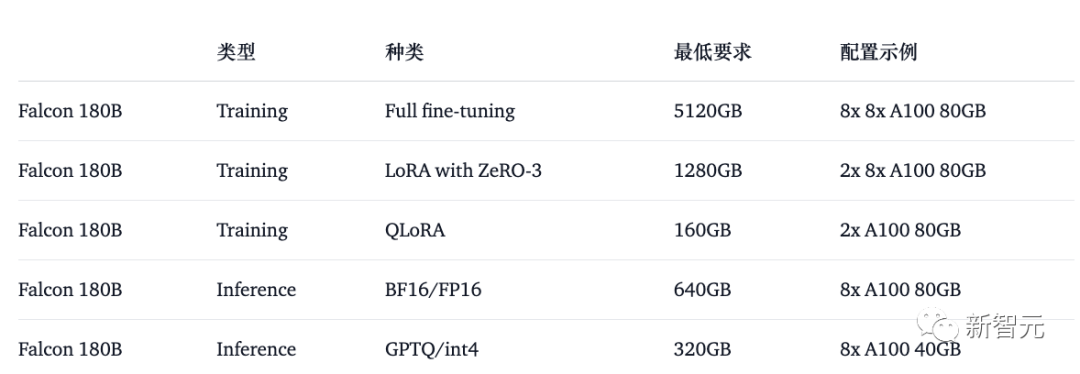
bfloat16 で基本モデルを使用する方法は次のとおりです。 Falcon 180B は大型モデルであるため、ハードウェア要件にご注意ください。
これに関して、ハードウェア要件は次のとおりです。
Falcon 180B を完全に微調整したい場合は、次のことがわかります。 、少なくとも 8X8X A100 80G が必要です。推論のみの場合は、8XA100 80G GPU も必要です。
from transformers import AutoTokenizer, AutoModelForCausalLMimport transformersimport torchmodel_id = "tiiuae/falcon-180B"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",)prompt = "My name is Pedro, I live in"inputs = tokenizer(prompt, return_tensors="pt").to("cuda")output = model.generate(input_ids=inputs["input_ids"],attention_mask=inputs["attention_mask"],do_sample=True,temperature=0.6,top_p=0.9,max_new_tokens=50,)output = output[0].to("cpu")print(tokenizer.decode(output)
は次の出力を生成します:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
8 ビットと 4 ビットサンドバイトを使用します。
# さらに、Falcon 180B の 8 ビットおよび 4 ビット量子化バージョンは、評価の点では bfloat16 とほとんど区別がつきません。
ユーザーは自信を持って量子化バージョンを使用してハードウェア要件を軽減できるため、これは推論にとって朗報です。
推論は、4 ビット バージョンより 8 ビット バージョンの方がはるかに高速であることに注意してください。量子化を使用するには、「bitsandbytes」ライブラリをインストールし、モデルをロードするときに対応するフラグを有効にする必要があります:
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,**load_in_8bit=True,**device_map="auto",)
Dialog Model
前述したように、会話を追跡するために微調整されたモデルのバージョンでは、非常に単純なトレーニング テンプレートが使用されます。チャット形式の推論を実行するには、同じパターンに従う必要があります。
参考までに、チャット デモの [format_prompt] 関数をご覧ください。
def format_prompt(message, history, system_prompt):prompt = ""if system_prompt:prompt += f"System: {system_prompt}\n"for user_prompt, bot_response in history:prompt += f"User: {user_prompt}\n"prompt += f"Falcon: {bot_response}\n"prompt += f"User: {message}\nFalcon:"return prompt
ご覧のとおり、上では、ユーザーの対話とモデル。応答の前に User: および Falcon: 区切り文字が続きます。それらを結合して、会話履歴全体を含むプロンプトを作成します。このようにして、ビルド スタイルを調整するためのシステム プロンプトを提供できます。
ネチズンからの熱いコメント多くのネチズンがファルコン 180B の真の強さについて熱い議論を交わしています。
まったく信じられない。 GPT-3.5 を上回り、Google の PaLM-2 Large と同等です。これはゲームチェンジャーです!

ある新興企業の CEO は、私が Falcon-180B 会話ロボットをテストしたところ、Llama2-70B チャット システムよりも優れていなかったと言っていました。 HF OpenLLM ランキングでもさまざまな結果が示されています。サイズとトレーニング セットが大きいことを考えると、これは驚くべきことです。
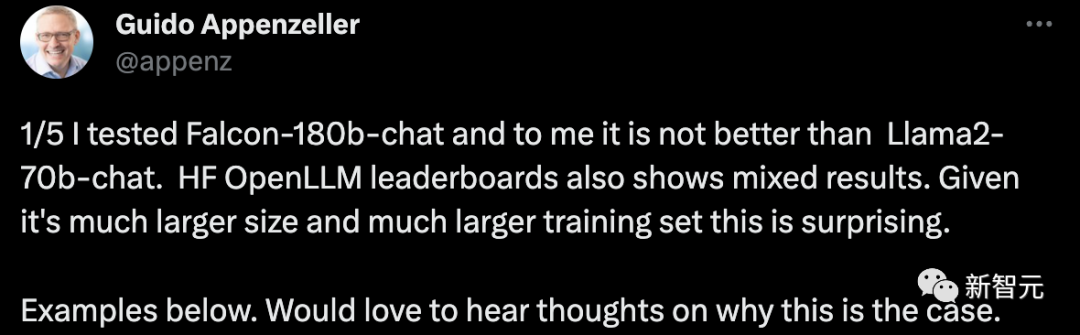
栗をあげましょう:
いくつかのエントリを与えて、Falcon-180B と Llama2-70B に答えてもらいましょうそれらを別々に試してみて、どのような効果があるか見てみましょう。
Falcon-180B は、サドルを誤って動物として数えます。 Llama2-70B は簡潔に答えて正解しました。


以上がパラメータ数1,800億、世界トップのオープンソース大型モデルFalconが正式発表! Crush LLaMA 2、パフォーマンスは GPT-4 に近いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。