
ホームページ >テクノロジー周辺機器 >AI >小規模なプロフェッショナル モデルをすばやくトレーニング: たった 1 つのコマンド、5 ドル、20 分で Prompt2Model をお試しください。
小規模なプロフェッショナル モデルをすばやくトレーニング: たった 1 つのコマンド、5 ドル、20 分で Prompt2Model をお試しください。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-09-11 16:33:021277ブラウズ
大規模言語モデル (LLM) を使用すると、ユーザーはヒントと文脈学習を通じて強力な自然言語処理システムを構築できます。ただし、別の観点から見ると、LLM は一部の特定の自然言語処理タスクにおいて一定の退行を示しており、これらのモデルの展開には大量のコンピューティング リソースが必要であり、API を介してモデルと対話すると、潜在的なプライバシー問題が発生する可能性があります。 ##これらの問題に対処するために、カーネギー メロン大学 (CMU) と清華大学の研究者は共同で Prompt2Model フレームワークを立ち上げました。このフレームワークの目標は、LLM ベースのデータ生成および取得方法を組み合わせて、上記の課題を克服することです。 Prompt2Model フレームワークを使用すると、ユーザーは LLM と同じプロンプトを提供するだけで、データを自動的に収集し、特定のタスクに適した小さな特殊なモデルを効率的にトレーニングできます。自然言語処理サブタスク。彼らは少数のサンプル プロンプトを入力として使用し、データの収集と 20 分のトレーニングに費やした費用はわずか 5 ドルでした。 Prompt2Model フレームワークを通じて生成されたモデルのパフォーマンスは、強力な LLM モデル gpt-3.5-turbo のパフォーマンスより 20% 高くなります。同時に、モデルのサイズは 700 分の 1 に縮小されました。研究者らはさらに、現実のシナリオにおけるモデルのパフォーマンスに対するこれらのデータの影響を検証し、モデル開発者が展開前にモデルの信頼性を推定できるようにしました。フレームワークはオープン ソース形式で提供されています:
## フレームワークの GitHub リポジトリ アドレス: https :/ /github.com/neulab/prompt2model
フレームワークのデモビデオリンク: youtu.be/LYYQ_EhGd-Q
- フレームワーク関連の論文リンク: https://arxiv.org/abs/2308.12261
- 背景
- 特定の自然言語処理タスク用のシステムを構築することは、多くの場合、かなり複雑です。システムの構築者は、タスクの範囲を明確に定義し、特定のデータ セットを取得し、適切なモデル アーキテクチャを選択し、モデルをトレーニングして評価し、それを実際のアプリケーションに展開する必要があります。 ## GPT-3 などの大規模言語モデル (LLM) は、このプロセスに対するより簡単なソリューションを提供します。ユーザーはタスクの指示といくつかの例を提供するだけで、LLM が対応するテキスト出力を生成できます。ただし、ヒントからテキストを生成すると計算量が多くなる可能性があり、ヒントの使用は特別にトレーニングされたモデルよりも安定性が低くなります。さらに、LLM の使いやすさは、コスト、速度、プライバシーによっても制限されます。
これらの問題を解決するために、研究者は Prompt2Model フレームワークを開発しました。このフレームワークは、LLM ベースのデータ生成と取得技術を組み合わせて、上記の制限を克服します。システムは最初にプロンプト情報から重要な情報を抽出し、次にトレーニング データを生成および取得し、最後に展開の準備ができた特殊なモデルを生成します。
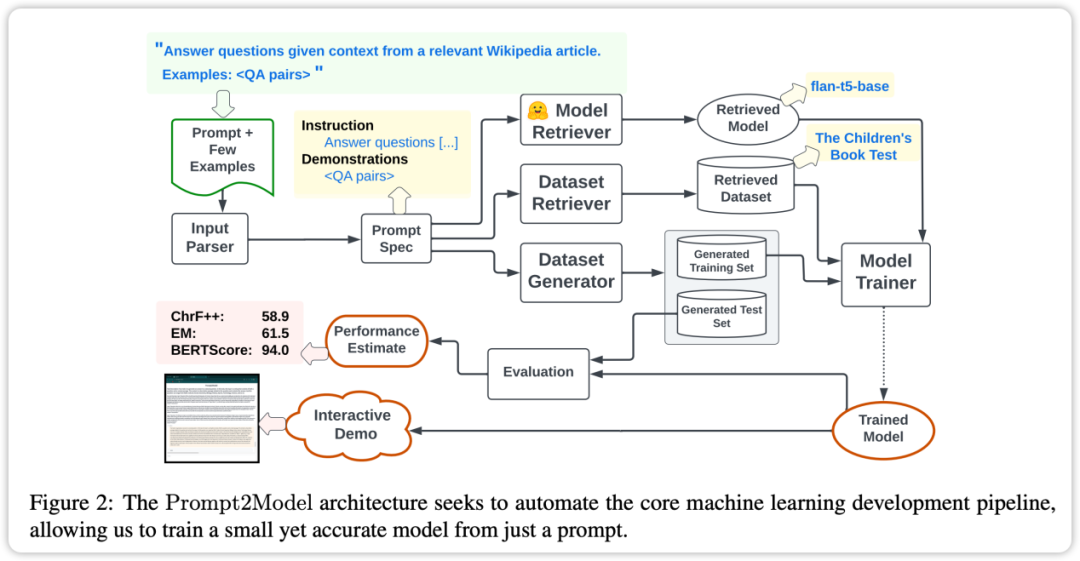
Prompt2Model フレームワークは、次の主要な手順を自動的に実行します。 1. データの前処理: 入力データをクリーンにして標準化し、モデルのトレーニングに適していることを確認します。 2. モデルの選択: タスクの要件に従って、適切なモデル アーキテクチャとパラメータを選択します。 3. モデルのトレーニング: 前処理されたデータを使用して選択したモデルをトレーニングし、モデルのパフォーマンスを最適化します。 4. モデル評価: 特定のタスクでのパフォーマンスを決定するための評価指標によるトレーニング済みモデルのパフォーマンス評価。 5. モデルのチューニング: 評価結果に基づいてモデルをチューニングし、パフォーマンスをさらに向上させます。 6. モデルのデプロイメント: トレーニングされたモデルを実際のアプリケーション環境にデプロイして、予測または推論機能を実現します。 これらのコアステップを自動化することで、Prompt2Model フレームワークは、ユーザーが高性能の自然言語処理モデルを迅速に構築して展開できるように支援します
データセットとモデルの取得: 関連するデータセットを収集し、事前トレーニングします。モデル。
データセットの生成: LLM を使用して、擬似ラベル付きデータセットを作成します。
モデルの微調整: 取得したデータと生成されたデータを混合してモデルを微調整します。
- モデルのテスト: ユーザーが提供したテスト データ セットと実際のデータ セットでモデルをテストします。
-
複数の異なるタスクでの経験的評価を通じて、Prompt2Model のコストが大幅に削減され、モデルのサイズも大幅に縮小されましたが、パフォーマンスは gpt を超えていることがわかりました。 -3.5ターボ。 Prompt2Model フレームワークは、自然言語処理システムを効率的に構築するためのツールとして使用できるだけでなく、モデル統合トレーニング テクノロジを探索するためのプラットフォームとしても使用できます。 #
フレームワーク

Prompt2Model フレームワークの中核機能は、高度な自動化です。上の図に示すように、そのプロセスにはデータ収集、モデルのトレーニング、評価、展開が含まれます。中でも自動データ収集システムは、データセットの検索とLLMベースのデータ生成を通じてユーザーのニーズに密接に関連したデータを取得することで重要な役割を果たします。次に、事前トレーニングされたモデルが取得され、取得されたデータセットで微調整されます。最後に、トレーニングされたモデルがテスト セットで評価され、モデルと対話するための Web ユーザー インターフェイス (UI) が作成されます。
Prompt2Model フレームワークの主な機能は次のとおりです。
- プロンプト ドライバー: Prompt2Model の中心的なアイデアは、プロンプトをドライバーとして使用することです。ユーザーは、機械学習の具体的な実装の詳細を深く理解していなくても、必要なタスクを直接記述することができます。
- 自動データ収集: このフレームワークは、データセットの取得および生成テクノロジーを使用して、ユーザーのタスクに高度に一致するデータを取得し、それによってトレーニングに必要なデータセットを確立します。
- 事前トレーニングされたモデル: フレームワークは事前トレーニングされたモデルを利用して微調整するため、トレーニングのコストと時間が大幅に節約されます。
- 有効性評価: Prompt2Model は、実際のデータセットでのモデルのテストと評価をサポートしており、モデルを展開する前に事前予測とパフォーマンス評価を行うことができるため、モデルの信頼性が向上します。
Prompt2Model フレームワークには次の機能があり、自然言語処理システムの構築プロセスを効率的に完了し、データの自動収集、モデルの評価とユーザー インタラクション インターフェイスの作成
実験と結果
Prompt2Model システムのパフォーマンスを評価するために、実験では
- 機械読み取り QA: 実際の評価データ セットとして SQuAD を使用する。
- 日本語 NL からコードへ: 実際の評価データセットとして MCoNaLa を使用します。
- 時間式正規化: 時間データ セットを実際の評価データ セットとして使用します。
さらに、研究者らは、比較のためのベースライン モデルとして GPT-3.5-turbo も使用しました。実験結果から次の結論が導き出されます:
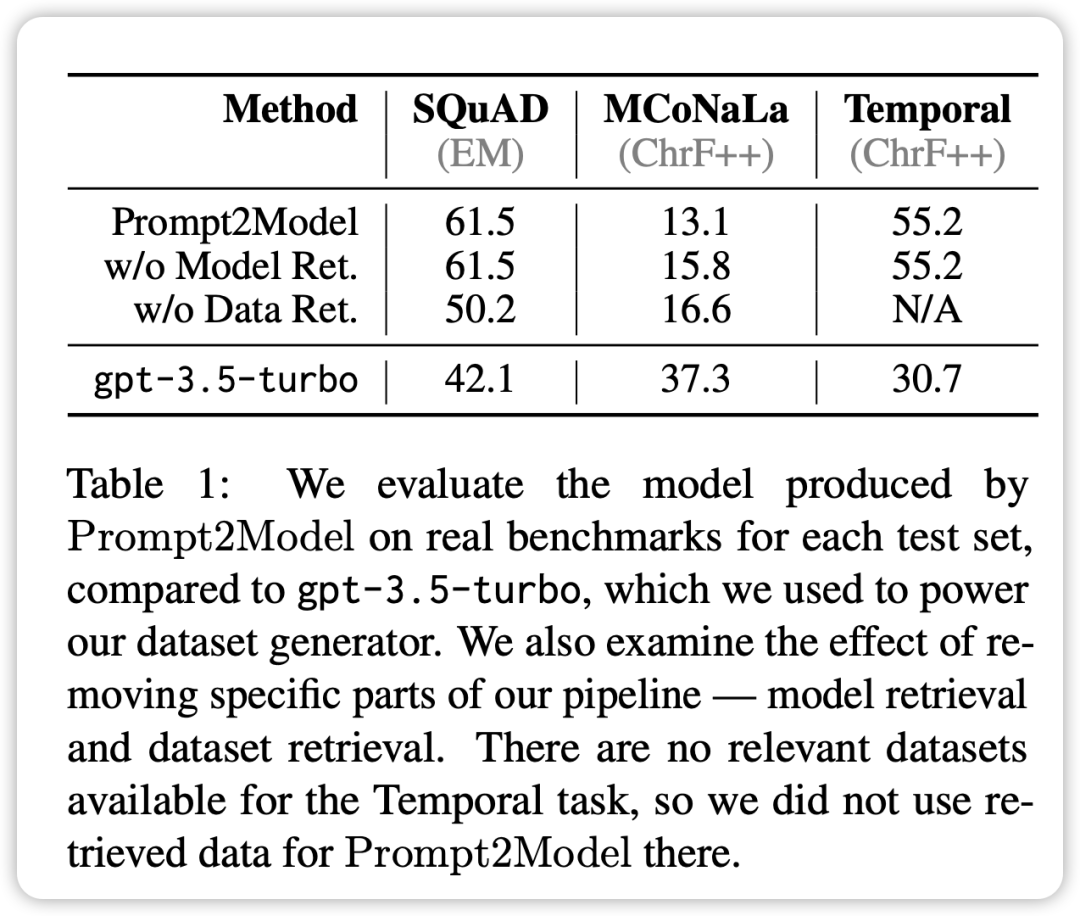
- コード生成タスクを除くすべてのタスクにおいて、Prompt2Model システムによって生成されたモデルはベンチマーク モデル GPT-3.5 よりも大幅に優れています。 - ターボ。ただし、生成されるモデル パラメーターのサイズは GPT-3.5-turbo よりもはるかに小さいです。
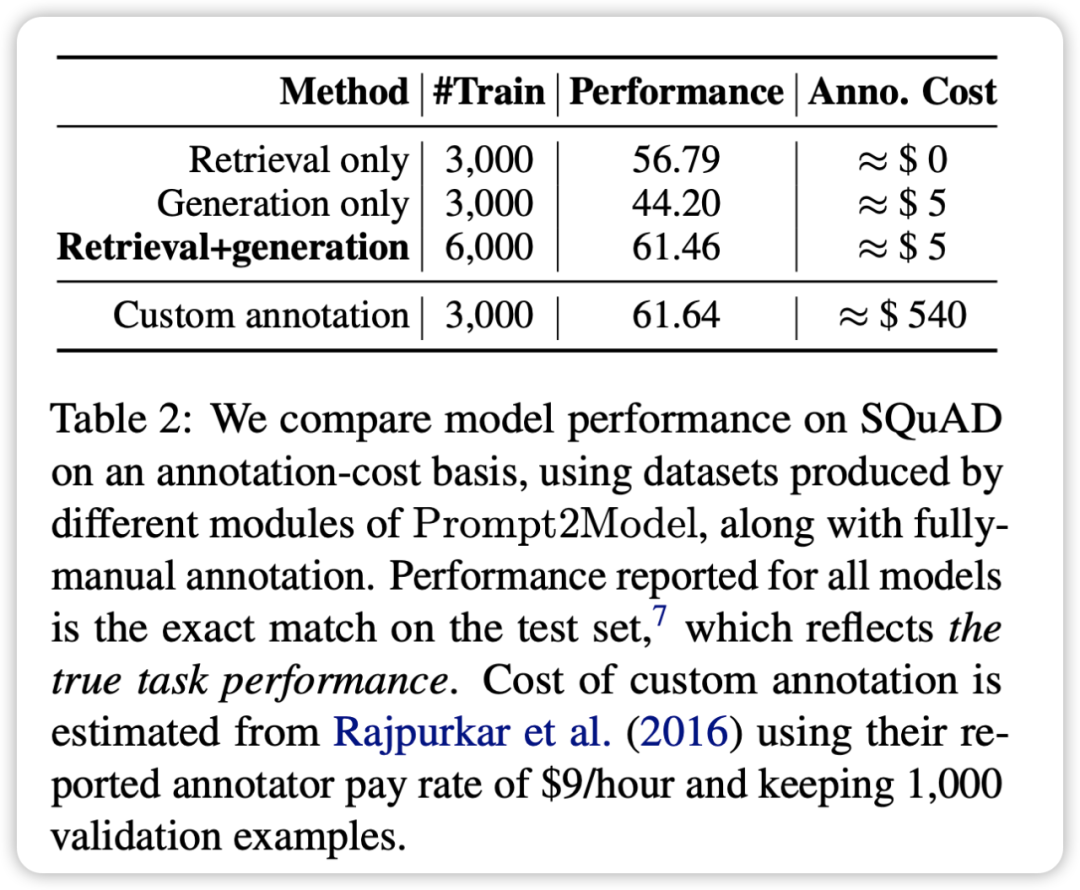
- 取得データ セットとトレーニング用に生成されたデータ セットを混合することで、実際のデータ セットをトレーニングに直接使用した場合と同等の結果を得ることができます。これにより、Prompt2Model フレームワークが手動アノテーションのコストを大幅に削減できることが検証されます。
- データ ジェネレーターによって生成されたテスト データ セットは、実際のデータ セットでのさまざまなモデルのパフォーマンスを効果的に区別できます。これは、生成されたデータが高品質であり、モデルのトレーニングに十分な効果があることを示しています。
- Prompt2Model システムは、日本語からコードへの変換タスクにおいて GPT-3.5-turbo よりもパフォーマンスが悪くなります。
生成されたデータセットの品質が低いことと、適切な事前トレーニング済みモデルがないことが原因である可能性があります
包括的一般に、Prompt2Model システムは複数のタスクで高品質の小さなモデルを正常に生成し、データに手動で注釈を付ける必要性を大幅に減らします。ただし、一部のタスクではまださらなる改善が必要です
##概要
Prompt2Model フレームワークは、自然言語プロンプトを通じてタスク固有のモデルを自動的に構築する、研究チームによって開発された革新的なテクノロジーです。このテクノロジーの導入により、カスタマイズされた自然言語処理モデルの構築の難しさが大幅に軽減され、NLP テクノロジーの適用範囲がさらに拡大されます
検証実験の結果は、Prompt2Model フレームワークによって生成されたモデルのサイズが、より大きな言語モデルと比較して大幅に削減され、複数のタスクにおいて GPT-3.5-turbo や他のモデルよりも優れたパフォーマンスを発揮することを示しています。同時に、このフレームワークによって生成された評価データ セットは、実際のデータ セットでのさまざまなモデルのパフォーマンスを評価するのに効果的であることも証明されています。これは、モデルの最終的な展開をガイドする上で重要な価値を提供します。
Prompt2Model フレームワークは、次の条件を満たす NLP モデルを取得するための低コストで使いやすい方法を業界とユーザーに提供します。特定のニーズ。これは、NLP テクノロジーの普及を促進する上で非常に重要です。今後の作業は、フレームワークのパフォーマンスをさらに最適化することに引き続き注力されます
記事の順序では、この記事の著者は次のとおりです。 書き直された内容: 記事の順序によると、この記事の著者は次のとおりです:
Vijay Viswanathan: http://www.cs.cmu.edu/~ vijayv/
チャオ・チェンヤン: https://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
アマンダ・バーチュ: https://www.cs 。 cmu.edu/~abertsch/ アマンダ・ベルシュ: https://www.cs.cmu.edu/~abertsch/
ウー・トンシュアン: https://www.cs.cmu.edu/~sherryw/
グラハム・ニュービッグ: http://www.phontron.com/
以上が小規模なプロフェッショナル モデルをすばやくトレーニング: たった 1 つのコマンド、5 ドル、20 分で Prompt2Model をお試しください。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。