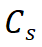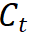マスク モデリング (MIM、MAE) は、非常に効果的な自己教師付きトレーニング方法であることが証明されています。ただし、図 1 に示すように、MIM は大規模なモデルで比較的良好に機能します。モデルが非常に小さい場合 (ViT-T 5M パラメーターなど、このようなモデルは現実世界にとって非常に重要です)、MIM はモデルの効果をある程度まで低減する場合もあります。たとえば、ImageNet 上の MAE でトレーニングされた ViT-L の分類効果は、通常の監視でトレーニングされたモデルより 3.3% 高くなりますが、ImageNet 上の MAE でトレーニングされた ViT-T の分類効果は 0.6% 低くなります。通常の監督下でトレーニングされたモデル。
この研究では、蒸留法を使用して大規模モデルから小規模モデルに知識を伝達する TinyMIM を提案しました。

紙のアドレス : https://arxiv.org/pdf/2301.01296.pdf コードアドレス: https://github.com/OliverRensu/TinyMIM
私たちは、蒸留目標、データ強化、正則化、補助損失関数などが蒸留に及ぼす影響を体系的に研究しました。厳密に ImageNet-1K のみをトレーニング データとして使用し (これも ImageNet-1K トレーニングのみを使用する Teacher モデルを含む)、ViT-B をモデルとして使用する場合、私たちの方法は現時点で最高のパフォーマンスを達成します。図に示すように: 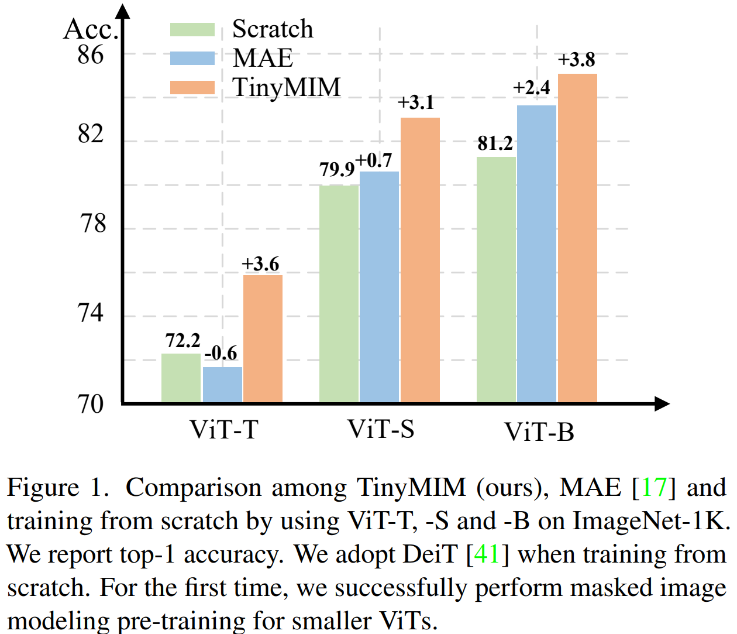
#メソッドを入力します。 (TinyMIM) は、マスク再構成ベースの手法 MAE およびゼロからトレーニングされた教師あり学習手法 DeiT と比較されます。モデルが比較的大きい場合、MAE はパフォーマンスを大幅に向上させますが、モデルが比較的小さい場合、向上は限定的であり、モデルの最終的な効果を損なう可能性さえあります。私たちの手法である TinyMIM は、さまざまなモデル サイズにわたって大幅な改善を実現します。
1. 蒸留ターゲット: 1) 蒸留トークン それらの間の関係は次のとおりです。クラストークンや特徴マップのみを抽出するよりも効果的; 2) 中間層を抽出のターゲットとして使用する方が効果的です。
2. データの強化とモデルの正則化 (データとネットワークの正則化): 1) マスクされた画像を使用すると、効果がさらに悪くなります; 2) 学生モデルにはドロップ パスが必要ですが、教師モデルには必要ありません。
3. 補助損失: MIM は補助損失関数としては無意味です。
4. マクロ蒸留戦略: 連続蒸留 (ViT-B -> ViT-S -> ViT-T) が最も効果的であることがわかりました。
# # 蒸留目標、入力画像、蒸留対象モジュールを体系的に調査しました。 1) 特徴: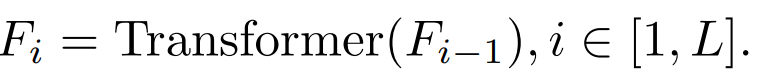
#i=L の場合、Transformer 出力層の特性を指します。 ib. アテンション (アテンション) 機能とフィードフォワード層 (FFN) 層の機能
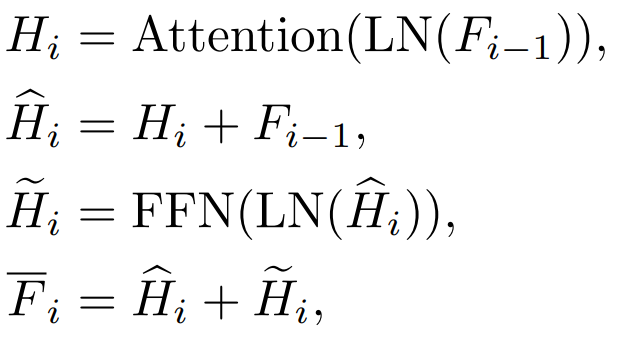
#Transformer 各ブロックにはアテンション レイヤーと FFN レイヤーがあり、蒸留レイヤーが異なれば効果も異なります。 c.QKV の機能 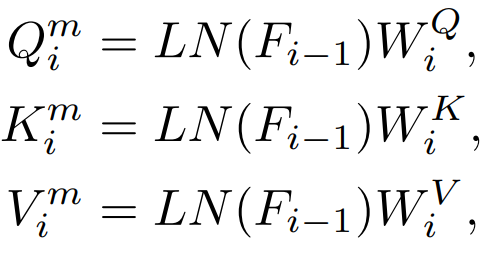
##注意層には Q、K、V 特徴量が含まれます。これらの特徴量は、注意メカニズムの計算に使用されます。また、これらの特徴量の直接抽出についても調査しました。
2) 関係
##Q、K、V はアテンション マップの計算に使用され、これらの特徴間の関係は知識の蒸留の対象としても使用できます。
従来の知識の蒸留では、完全な画像を直接入力します。私たちの方法は、蒸留マスク モデリング モデルを調査することであるため、マスクされた画像が知識蒸留の入力として適切かどうかも調査します。 2.2 知識抽出方法の比較
最も簡単な方法は、DeiT に似た MAE 事前トレーニング モデルのクラス トークンを直接抽出することです: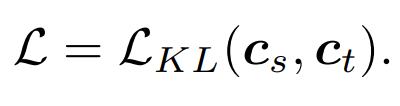 ## ここで、
## ここで、
は学生モデルのクラス トークンを指し、 は学生モデルのクラス トークンを指します。先生のモデル。
#2) 特徴抽出: 比較として特徴抽出 [1] を直接参照します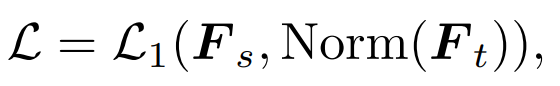
##3) リレーショナル蒸留: 私たちは次のことも提案しました。この記事のデフォルトの蒸留戦略
## 3. 実験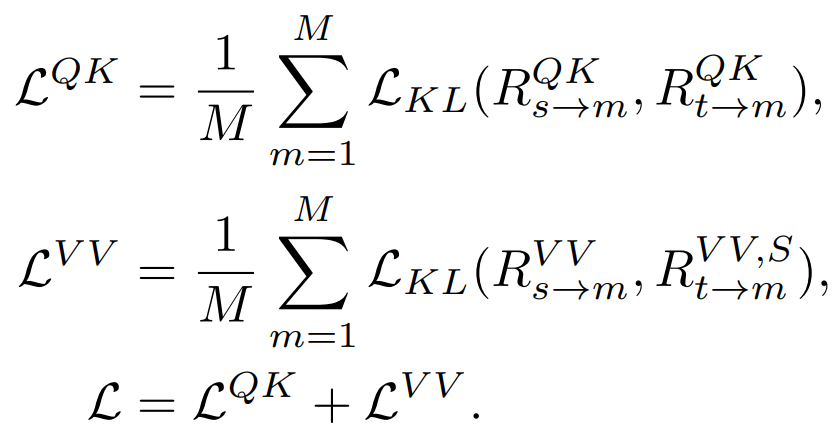
我々の方法はPreです。 -ImageNet-1K でトレーニングされており、教師モデルも ImageNet-1K で事前トレーニングされています。次に、下流のタスク (分類、セマンティック セグメンテーション) で事前トレーニングされたモデルを微調整しました。モデルのパフォーマンスは次の図に示されています:
# 私たちの方法は、特に小規模モデルの場合、以前の MAE ベースの方法よりも大幅に優れています。特に、超小型モデル ViT-T の場合、私たちの方法は 75.8% の分類精度を達成し、MAE ベースライン モデルと比較して 4.2 向上しました。小型モデル ViT-S では、83.0% の分類精度を達成し、これまでの最良の方法と比較して 1.4 向上しました。基本サイズのモデルの場合、私たちの方法は、それぞれ MAE ベースライン モデルと CAE 4.1 および 2.0 による以前の最高のモデルを上回っています。 同時に、図に示すように、モデルの堅牢性もテストしました。 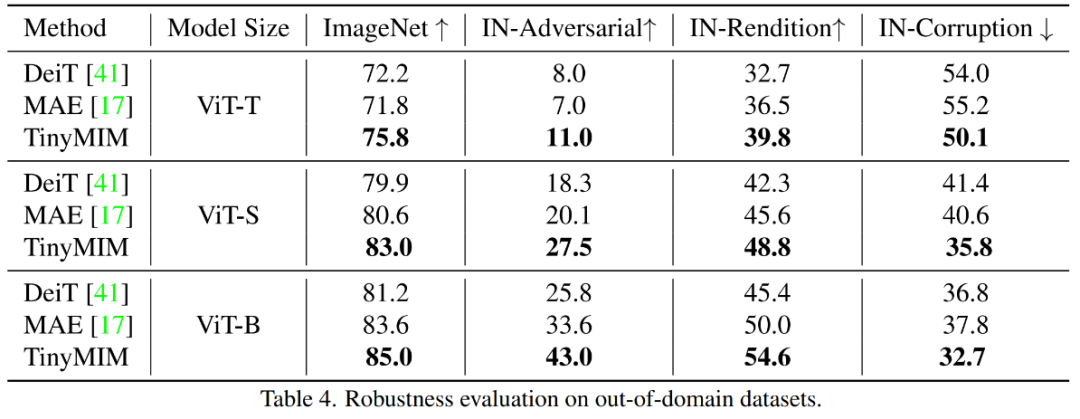
MAE-B と比較して、TinyMIM-B は ImageNet-A と ImageNet-R でそれぞれ 6.4 と 4.6 向上しました。 。 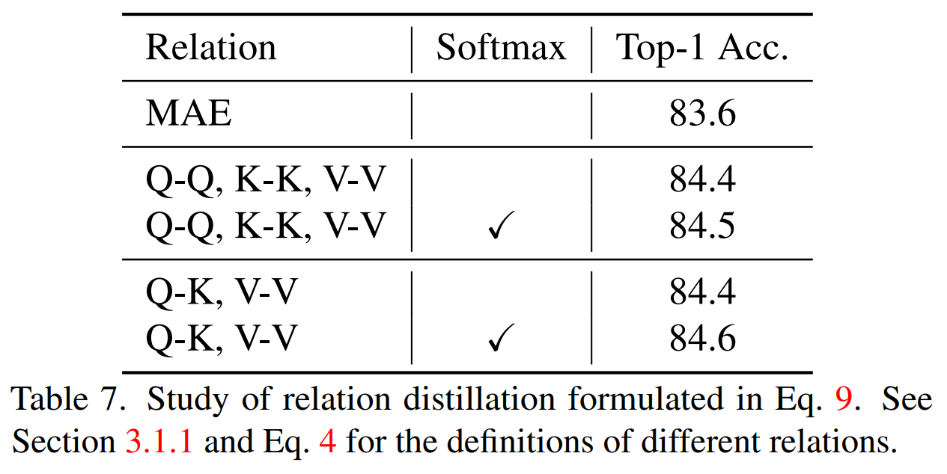
## QK、VV 関係を同時に抽出し、次の場合にソフトマックスを持ちます。関係を計算することで最良の結果が得られました。 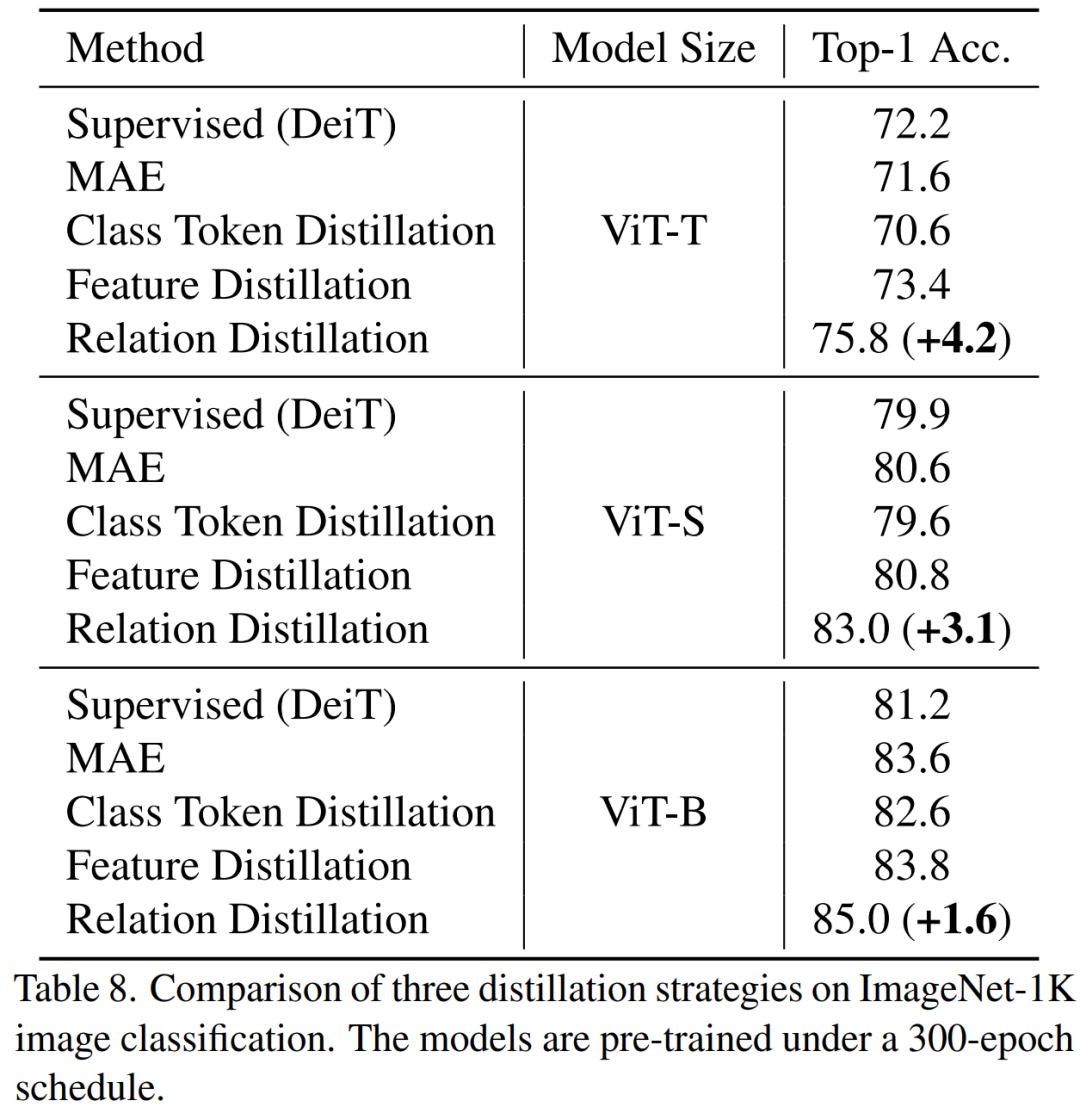
TinyMIM 関係を抽出するこの方法では、MAE ベースライン モデル、クラス トークンの抽出、および特徴マップの抽出よりも優れた結果が得られ、これはさまざまなサイズのモデルに当てはまります。 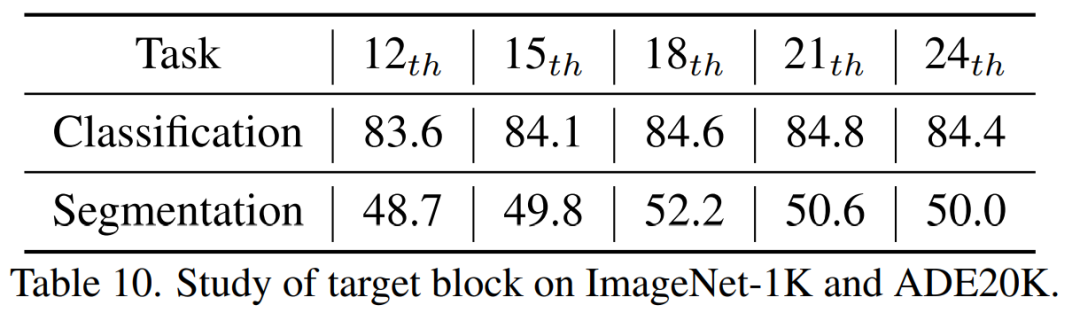
蒸留の 18 層目で最良の結果が得られることがわかりました。 4. 結論この記事では、TinyMIM を提案しました。小規模モデルがマスク再構成モデリング (MIM) 事前トレーニングの恩恵を受けることを可能にする最初のモデルです。タスクとしてマスク再構成を採用する代わりに、知識蒸留法で大きなモデルの関係をシミュレートするために小さなモデルをトレーニングすることによって、小さなモデルを事前にトレーニングします。 TinyMIM の成功は、蒸留ターゲット、蒸留入力、中間層など、TinyMIM の事前トレーニングに影響を与える可能性のあるさまざまな要因を包括的に調査したことに起因すると考えられます。広範な実験を通じて、私たちは関係蒸留が特徴蒸留やクラスラベル蒸留などより優れていると結論付けました。そのシンプルさと強力なパフォーマンスにより、私たちの方法が将来の研究のための強固な基盤となることを願っています。 [1] Wei, Y.、Hu, H.、Xie, Z.、Zhang, Z.、Cao, Y.、Bao, J. , ... & Guo, B. (2022). 特徴抽出による微調整において、対照学習はマスクされた画像モデリングに匹敵します。arXiv プレプリント arXiv:2205.14141.以上がMicrosoft Research Asia が TinyMIM を発表: 知識の蒸留により小型 ViT のパフォーマンスを向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。