
10分で解決 | 大規模分散型ECシステムのアーキテクチャ
- Java后端技术全栈転載
- 2023-08-23 15:03:021138ブラウズ
#この記事は、大規模な分散 Web サイト アーキテクチャの学習に関する技術的な概要です。 高性能、高可用性、スケーラブルで拡張可能な分散型 Web サイトのアーキテクチャについて簡単に説明し、アーキテクチャのリファレンスを提供します。 記事の一部は読書メモであり、一部は個人的な経験の要約であり、大規模な分散 Web サイトのアーキテクチャにとって優れた参考価値があります。
大規模分散型Webサイト構築技術
- 多数のユーザー、広範囲に分散
- 大規模なトラフィック、高い同時実行
- 大規模データ、サービスの可用性の高さ #セキュリティ環境が悪く、ネットワーク攻撃に対して脆弱である
- 多機能、迅速な変更、頻繁なリリース
- 小規模から大規模まで、進歩的な開発
- ユーザー中心
- ##無料サービス、有料エクスペリエンス
高パフォーマンス: 高速アクセス エクスペリエンスを提供します。
- 高可用性: Web サイト サービスには常に通常どおりアクセスできます。
- スケーラブル: ハードウェアの増減により処理能力を増減します。
- セキュリティ: 安全な Web サイトへのアクセス、データ暗号化、安全なストレージのための戦略を提供します。
- 拡張性: 新しい関数/モジュールを追加/削除することで簡単に追加/削除できます。
- 俊敏性: オンデマンド、迅速な対応;


- 分離: 一般に、ビジネス/モジュール/機能の特性に応じて分割されます。たとえば、アプリケーション層はホームページとユーザー センターに分割されます。
- 分散型: アプリケーションを個別に (複数の物理マシンなど) 展開し、リモート呼び出しを通じて連携します。
4. 高性能アーキテクチャ
はユーザー中心であり、高速な Web アクセス エクスペリエンスを提供します。主なパラメータは、短い応答時間、大きな同時処理能力、高いスループット、安定したパフォーマンス パラメータです。
フロントエンドの最適化、アプリケーション層の最適化、コード層の最適化、ストレージ層の最適化に分けることができます。
フロントエンドの最適化: Web サイトのビジネス ロジックの前の部分; ブラウザの最適化: HTTP リクエストの数を減らし、ブラウザのキャッシュを使用します。 、圧縮の有効化、CSS JS の場所、JS の非同期、Cookie 送信の削減、CDN アクセラレーション、リバース プロキシ、 アプリケーション層の最適化: Web サイトのビジネスを処理するサーバー。キャッシュ、非同期、クラスターの使用 - #コードの最適化: 合理的なアーキテクチャ、マルチスレッド、リソースの再利用 (オブジェクト プール、スレッド プールなど)、適切なデータ構造、JVM チューニング、単一の例、キャッシュなど;
- ストレージ最適化: キャッシュ、ソリッド ステート ドライブ、光ファイバー伝送、最適化された読み取りおよび書き込み、ディスク冗長性、分散ストレージ (HDFS)、NoSQL など。
大規模な Web サイトには常にアクセスでき、通常の外部サービスを提供する必要があります。 。大規模 Web サイトの複雑さ、分散、安価なサーバー、オープンソース データベース、オペレーティング システム、その他の特性により、高可用性を確保することは困難であり、Web サイトの障害は避けられません。 可用性を向上させる方法は、早急に解決する必要がある問題です。まず、アーキテクチャレベルから検討し、計画時に可用性を考慮する必要があります。業界では、可用性指標を表すために一般にフォー ナイン (99.99) などの 9 が使用され、年間に許容される非可用性時間は 53 分です。 さまざまな戦略がさまざまなレベルで使用され、高可用性の問題を解決するには、一般に冗長バックアップとフェイルオーバーが使用されます。
アプリケーション層: 通常はステートレスになるように設計されており、各リクエストの処理にどのサーバーが使用されるかは影響を受けません。一般に、高可用性を実現するには、負荷分散テクノロジ (セッション同期の問題を解決する必要がある) が使用されます。 サービス層: 負荷分散、階層管理、高速障害 (タイムアウト設定)、非同期呼び出し、サービス低下、冪等設計など。 データ層: 冗長バックアップ (コールド、ホット スタンバイ [同期、非同期]、ウォーム スタンバイ)、フェイルオーバー (確認、転送、回復)。高データ可用性の有名な理論的基礎は CAP 理論 (永続性、可用性、データ整合性 [強整合性、ユーザー整合性、結果整合性])
#6 、スケーラブルアーキテクチャ
スケーラビリティとは、元のアーキテクチャ設計を変更せずにハードウェア (サーバー) を追加/削減することによってシステムの処理能力を増加/削減することを指します。
- #アプリケーション層: アプリケーションを垂直または水平に分割します。次に、単一の機能 (DNS、HTTP [リバース プロキシ]、IP、リンク層) に対して負荷分散します。
- サービス層: アプリケーション層と同様;
- データ層: サブデータベース、サブテーブル、NoSQL など、一般的に使用されるアルゴリズム ハッシュ、整合性ハッシュ。
機能モジュールを簡単に追加/削除し、コードを提供できます/モジュール レベルでの優れた拡張性。
- モジュール化とコンポーネント化: 高い凝集性、低い結合性、再利用性と拡張性の向上。
- 安定したインターフェイス: 安定したインターフェイスを定義します。インターフェイスが変更されないままであれば、内部構造は「自由に」変更できます。
- デザイン パターン: オブジェクト指向のアイデアと原則を適用し、デザイン パターンを使用してコード レベルで設計します。
- メッセージ キュー: メッセージ キューを介して対話し、モジュール間の依存関係を分離するモジュール式システム。
- 分散サービス: パブリック モジュールは、再利用性と拡張性を向上させるために他のシステムによる使用を提供するサービス指向です。
#8. セキュリティ アーキテクチャ既知の問題に対する効果的な解決策を用意し、未知/潜在的な問題の発見と防御メカニズムを確立する。セキュリティ問題については、まずセキュリティに対する意識を高め、サーバーのパスワードは漏洩しない、パスワードは毎月更新する、3回以内は繰り返してはいけないなど、ポリシーレベルや組織レベルで効果的なセキュリティの仕組みを確立する必要があります。毎週のセキュリティスキャンなど。制度的な安全体制の構築を強化する。同時に、安全に関するあらゆる側面に注意を払う必要があります。インフラストラクチャのセキュリティ、アプリケーション システムのセキュリティ、データの機密性とセキュリティなど、セキュリティの問題を無視することはできません。
インフラストラクチャのセキュリティ: ハードウェアの調達、オペレーティング システム、およびネットワーク環境のセキュリティ。一般に、高品質の製品を購入し、安全なオペレーティング システムを選択し、タイムリーに脆弱性にパッチを当て、ウイルス対策ソフトウェアとファイアウォールをインストールするには、正規のチャネルを使用します。ウイルスやバックドアから保護します。ファイアウォール ポリシーを設定し、DDOS 防御システムを確立し、攻撃検出システムを使用し、サブネット分離を実行します。 アプリケーション システムのセキュリティ: プログラム開発中は、正しい方法を使用して既知の一般的な問題をコード レベルで解決します。クロスサイト スクリプティング攻撃 (XSS)、インジェクション攻撃、クロスサイト リクエスト フォージェリ (CSRF)、エラー メッセージ、HTML コメント、ファイル アップロード、パス トラバーサルなどを防止します。また、Web アプリケーション ファイアウォール (ModSecurity など) を使用して、セキュリティ脆弱性スキャンやその他の対策を実行して、アプリケーション レベルのセキュリティを強化することもできます。 データの機密性とセキュリティ: ストレージのセキュリティ (信頼性の高い機器に保存、リアルタイムのスケジュールされたバックアップ)、ストレージのセキュリティ (重要な情報は暗号化されて保存され、複雑なストレージと適切な担当者の選択)検出など)、送信セキュリティ (データ盗難やデータ改ざんの防止)、
一般的に使用される暗号化および復号化アルゴリズム (単一ハッシュ暗号化 [MD5、SHA]、対称暗号化 [DES、 3DES、RC])、非対称暗号化[RSA]など。
9. 俊敏性
ウェブサイトのアーキテクチャ設計と運用保守管理は、変化に適応し、高い拡張性と拡張性を提供する必要があります。急速なビジネスの発展、高トラフィックのアクセスの突然の増加、その他の要件に便利に対応します。
上で紹介したアーキテクチャ要素に加えて、アジャイル管理やアジャイル開発の考え方を導入することも必要です。ビジネス、製品、テクノロジー、運用保守を統合し、ニーズに適応し、迅速に対応します。
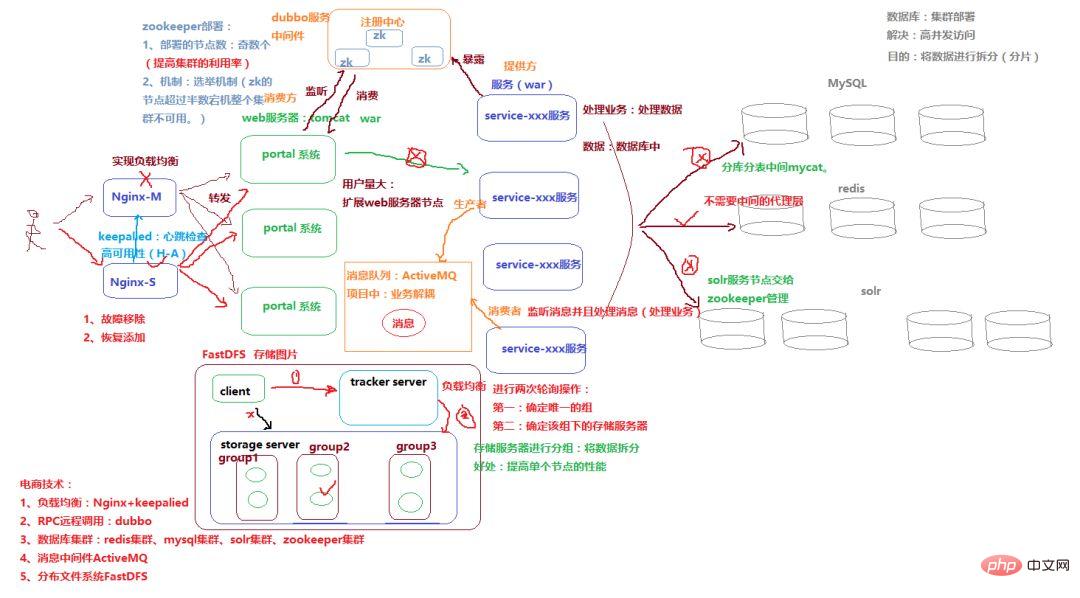
10. 大規模アーキテクチャの例
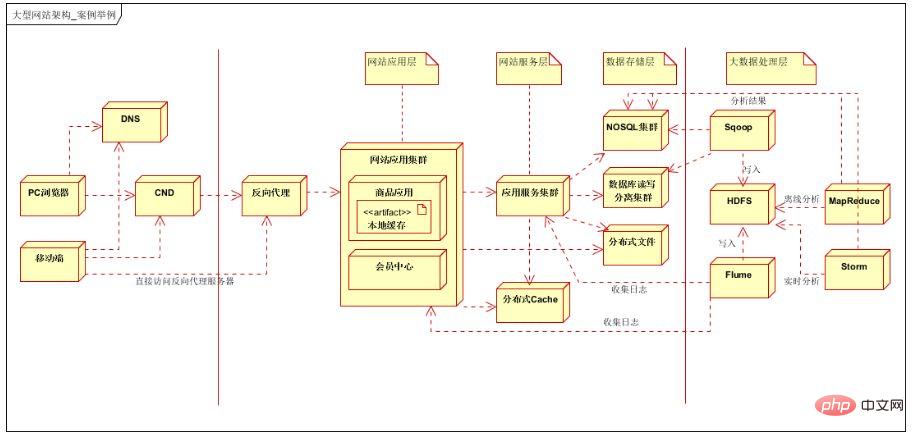
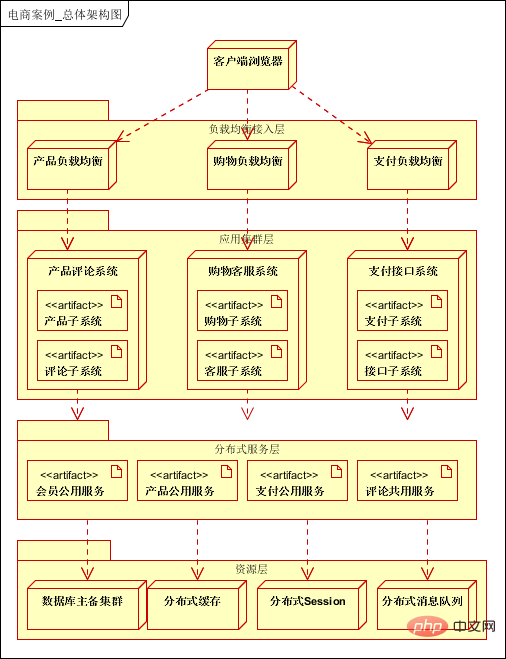
上記は 7 層の論理アーキテクチャを使用しています、最初の層は顧客層、2層目はフロントエンド最適化層、3層目はアプリケーション層、4層目はサービス層、5層目はデータストレージ層、6層目はビッグデータストレージ層、そしてビッグデータ処理層の第7層です。
顧客層: PC ブラウザとモバイル APP をサポートします。違いは、モバイル APP が IP およびリバース プロキシ サーバー経由で直接アクセスできることです。 フロントエンド層: DNS ロード バランシング、CDN ローカル アクセラレーション、およびリバース プロキシ サービスを使用; アプリケーション層: Web サイト アプリケーション クラスター。製品アプリケーション、メンバーセンターなどの垂直分割を実行します; サービス層: ユーザーサービス、注文サービス、支払いサービスなどの公共サービスを提供します。 データ層: リレーショナル データベース クラスター (読み取り/書き込み分離をサポート)、NOSQL クラスター、分散ファイル システム クラスター、および分散キャッシュをサポートします。 ビッグ データ ストレージ レイヤー: アプリケーション レイヤーとサービス レイヤーでのログ データ収集、リレーショナル データベースと NOSQL データベースでの構造化データおよび半構造化データの収集をサポート; ビッグ データ処理レイヤー: オフラインMapreduce または Storm リアルタイム データ分析によるデータ分析を行い、処理されたデータをリレーショナル データベースに保存します。 (実際の使用では、オフライン データとリアルタイム データはビジネス要件に従って分類および処理され、アプリケーション層またはサービス層で使用するために別のデータベースに保存されます)。
#大規模ECサイトのシステムアーキテクチャの進化過程
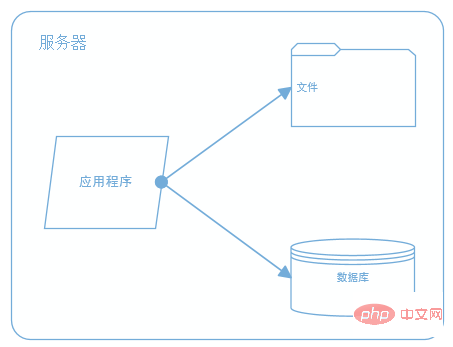
成熟した大規模ウェブサイト(タオバオ、天猫、テンセントなどのシステムアーキテクチャ)は、最初から高パフォーマンス、高可用性、高拡張性などの機能が完璧に設計されているわけではなく、数が増えるにつれて徐々に進化し、改善されます。ユーザーの増加とビジネス機能の拡大に伴い、開発モデル、技術アーキテクチャ、設計思想も大きく変化し、技術スタッフも数名から部門、製品ラインへと発展してきました。 したがって、成熟したシステム アーキテクチャはビジネスの拡大とともに徐々に改善され、一夜にして達成されるものではありません。さまざまなビジネス特性を持つシステムにはそれぞれ独自の焦点があります。たとえば、大量の検索を解決する必要があるタオバオなどです。製品情報。注文、支払い。たとえば、Tencent は数億人のユーザーに対するリアルタイムのメッセージ送信を処理する必要があり、Baidu は大量の検索リクエストを処理する必要があります。 それぞれに独自のビジネス特性があり、システム アーキテクチャも異なります。しかし、Webサイトの背景が異なる中でも共通する技術や手法は大規模Webサイトシステムの構築に広く使われており、大規模Webサイトシステムの進化の過程を紹介しながら理解していきましょう。手段。初期のアーキテクチャでは、図に示すように、アプリケーション、データベース、ファイルはすべて 1 つのサーバー上にデプロイされます。形: ###
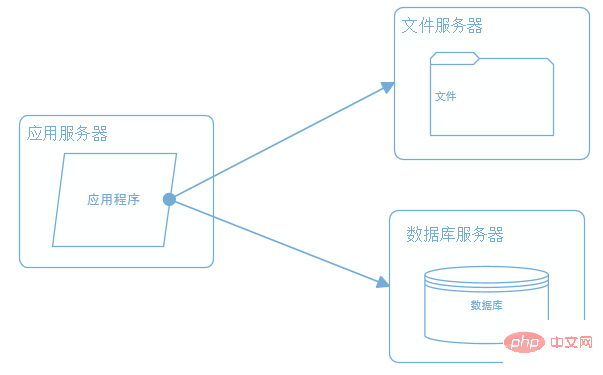
2. アプリケーション、データ、ファイルの分離
ビジネスの拡大に伴い、1 つのサーバーでは分離できなくなりました。パフォーマンス要件を満たすため、アプリケーション、データベース、およびファイルは別々のサーバーにデプロイされ、最高のパフォーマンス結果を達成するためにサーバーの目的に応じて異なるハードウェアが構成されます。
3. キャッシュを使用してウェブサイトのパフォーマンスを向上させる
ハードウェアを通じてパフォーマンスを最適化すると同時に、ソフトウェアも最適化します。パフォーマンスの最適化を実行します。ほとんどの Web サイト システムでは、システム パフォーマンスを向上させるためにキャッシュ テクノロジが使用されます。キャッシュの使用は主にホット データの存在によるものです。ほとんどの Web サイト訪問は 28 原則に従います (つまり、アクセス リクエストの 80% は最終的に満たされています)。データの 20% で)、ホットスポット データをキャッシュし、これらのデータのアクセス パスを削減し、ユーザー エクスペリエンスを向上させることができます。
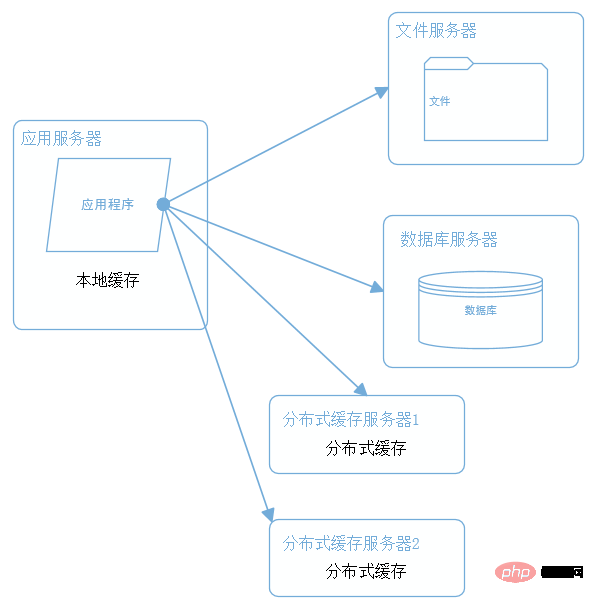
#キャッシュを実装する一般的な方法は、ローカル キャッシュと分散キャッシュです。もちろん、後で説明する CDN やリバース プロキシなどもあります。ローカル キャッシュは、名前が示すように、データをアプリケーション サーバー上でローカルにキャッシュします。データはメモリまたはファイルに保存できます。OSCache は、一般的に使用されるローカル キャッシュ コンポーネントです。ローカルキャッシュの特徴は高速であることですが、ローカルの空間には限りがあるため、キャッシュされるデータ量にも限界があります。分散キャッシュの特徴は、大量のデータをキャッシュでき、拡張が非常に簡単であることです。ポータル Web サイトでよく使用されますが、ローカル キャッシュほど高速ではありません。一般的に使用される分散キャッシュには、Memcached と Redis があります。
4. クラスターを使用してアプリケーション サーバーのパフォーマンスを向上させる
アプリケーション サーバーは、Web サイトへの入り口として、大量のリクエストの数を共有するために、アプリケーション サーバーをクラスタ化して使用することがよくあります。負荷分散サーバーはアプリケーション サーバーの前に展開され、ユーザーのリクエストをスケジュールし、分散ポリシーに従ってリクエストを複数のアプリケーション サーバー ノードに分散します。
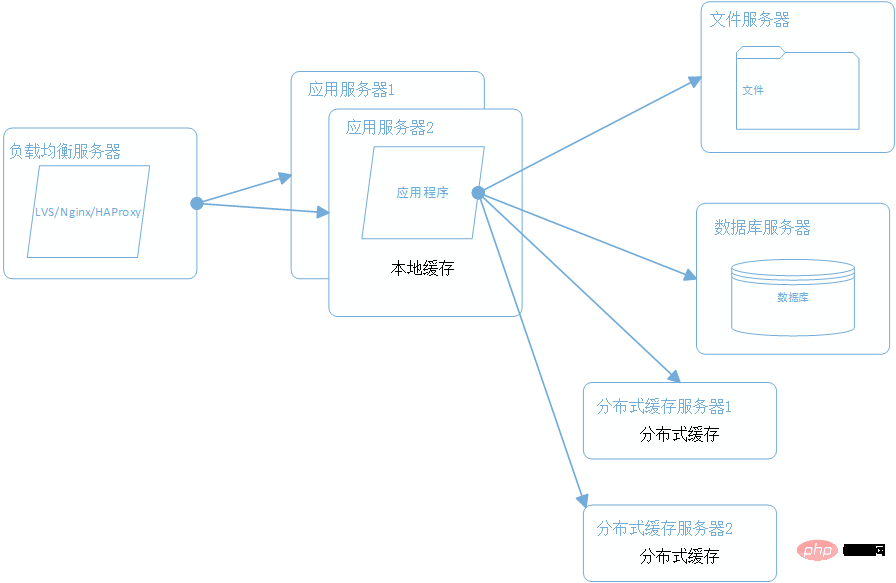
一般的に使用される負荷分散テクノロジのハードウェアには、比較的高価な F5 が含まれ、ソフトウェアには LVS、Nginx、HAProxy が含まれます。 LVS は、ターゲット アドレスとポートに基づいて内部サーバーを選択する 4 層の負荷分散であり、Nginx と HAProxy は、メッセージの内容に基づいて内部サーバーを選択できる 7 層の負荷分散です。 Nginx と HAProxy の方がパフォーマンスが高く、Nginx と HAProxy はより構成可能であり、動的と静的な分離に使用できます (リクエスト メッセージの特性に基づいて静的リソース サーバーまたはアプリケーション サーバーを選択します)。
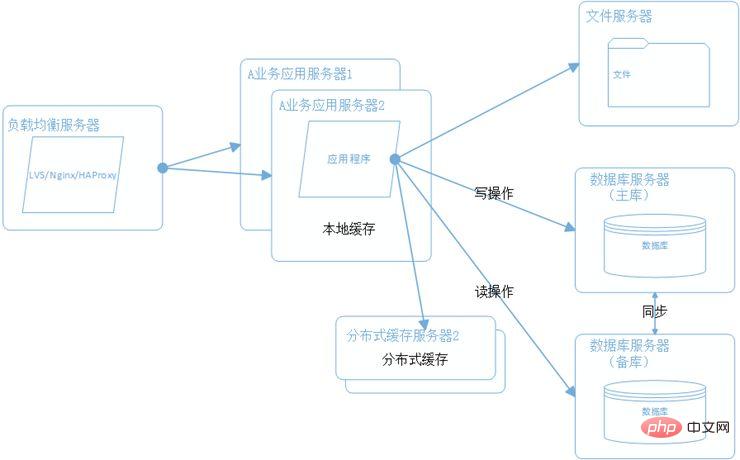
5. データベースの読み取り/書き込みの分離とデータベースとテーブルのシャーディング
ユーザー数の増加に伴い、データベースが最大のボトルネックになりました。データベースのパフォーマンスを向上させるために一般的に使用される方法は、読み取りと書き込み、サブデータベースとテーブルを分離する方法です。読み取り/書き込み分離とは、名前が示すように、データベースを読み取りデータベースと書き込みデータベースに分割し、メイン機能とバックアップ機能によるデータの同期。データベース シャーディングとテーブル シャーディングは、ユーザー テーブルなどのデータベース内の非常に大きなテーブルを分割する水平シャーディングと垂直シャーディングに分けられます。垂直セグメンテーションは、ビジネスごとに分かれており、たとえば、ユーザー ビジネスとプロダクト ビジネスに関連するテーブルは別のデータベースに配置されます。
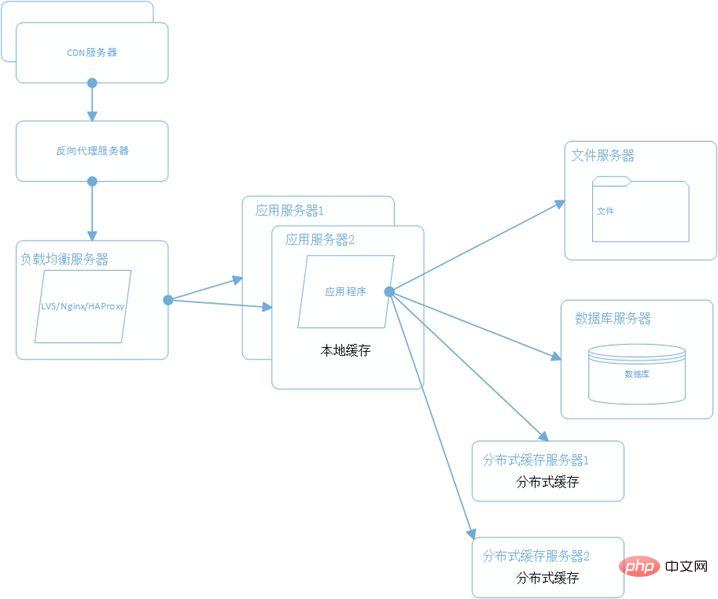
6. CDN とリバース プロキシを使用して Web サイトのパフォーマンスを向上させます
サーバーがデプロイされている場合成都のコンピュータ室では、四川省のユーザーのアクセスは速いですが、北京のユーザーのアクセスは遅くなります。これは、四川省と北京がそれぞれチャイナテレコムとチャイナユニコムの異なる発展地域に属しており、北京のユーザーはインターネットにアクセスする必要があるためです。ルーターは成都のサーバーにアクセスするために長い経路をたどりますが、戻り経路も同じであるため、データ送信時間は比較的長くなります。この問題を解決するために CDN がよく使われます。CDN はデータの内容をオペレーターのコンピューター室にキャッシュし、ユーザーがデータにアクセスするときは、最初に最寄りのオペレーターからデータを取得します。これにより、ネットワーク アクセス パスが大幅に削減されます。より専門的な CDN オペレーターには、Lanxun と Wangsu が含まれます。
リバースプロキシはWebサイトのコンピュータルームに設置されており、ユーザーからのリクエストが到着すると、まずリバースプロキシサーバーにアクセスし、リバースプロキシサーバーはキャッシュされたデータをユーザーに返します。アプリケーションサーバーにアクセスしてデータを取得することで、データ取得コストを削減します。リバース プロキシには、Squid と Nginx が含まれます。
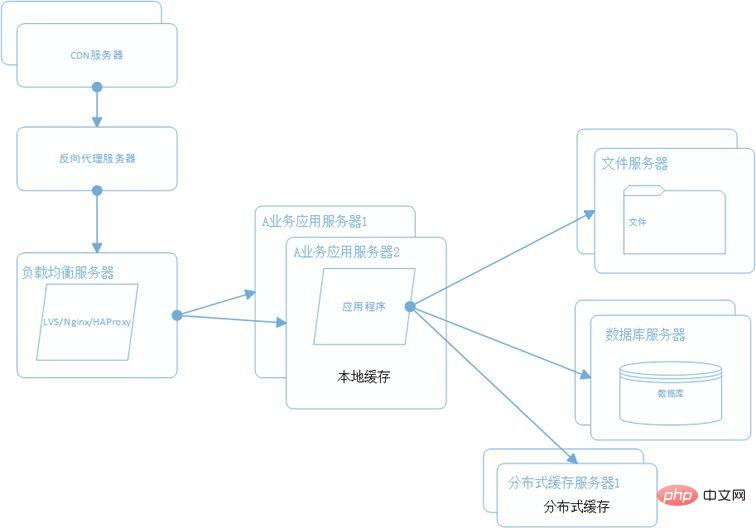
ユーザー数は日々増加しており、ビジネス量が増大し、生成されるファイルがますます増え、単一のファイル サーバーでは需要に対応できなくなり、分散ファイル システムのサポートが必要になります。一般的に使用される分散ファイル システムには、GFS、HDFS、TFS などがあります。
#8. NoSQL と検索エンジンを使用する大量のデータのクエリと分析には、 NoSQL データベースと検索エンジンを併用すると、より優れたパフォーマンスを実現できます。すべてのデータをリレーショナル データに配置する必要があるわけではありません。一般的に使用される NoSQL には MongoDB、HBase、Redis が含まれ、検索エンジンには Lucene、Solr、Elasticsearch が含まれます。
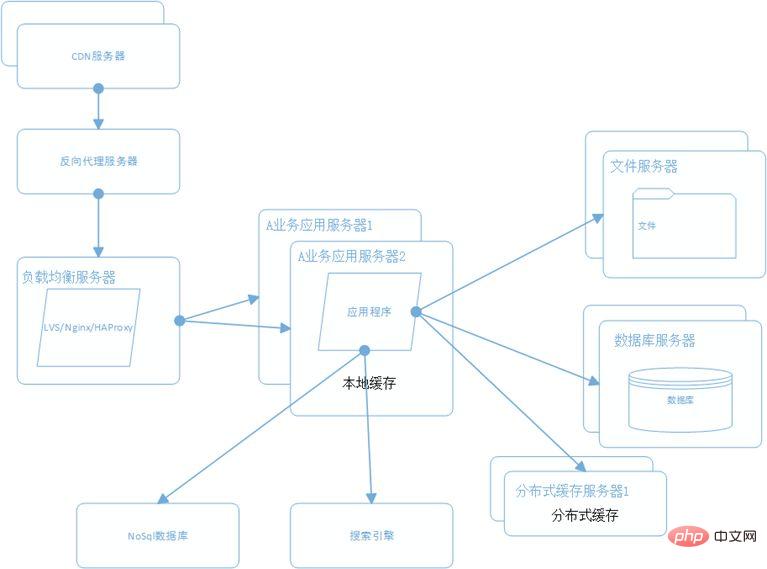
9. アプリケーション サーバー ビジネスを分割する
ビジネスがさらに拡大するにつれて、アプリケーションは非常に肥大化し、アプリケーションをサービスに分割する必要があります。たとえば、Baidu をニュース、Web ページ、写真、その他のサービスに分割する必要があります。各ビジネス アプリケーションは、比較的独立したビジネス操作を担当します。企業はメッセージを通じてコミュニケーションしたり、データベースを共有したりします。
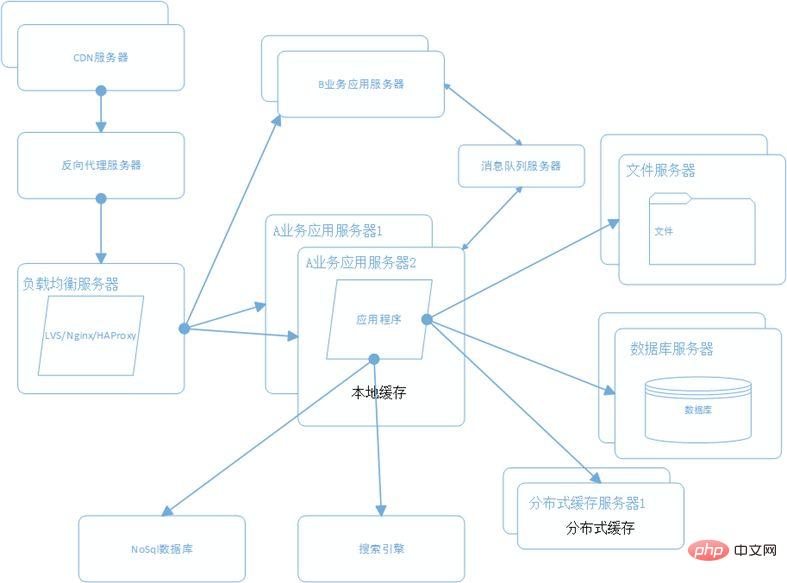
10. 分散サービスの構築
現時点では、各ビジネス アプリケーションがいくつかのサービスを使用することがわかりました。ユーザーサービス、注文サービス、決済サービス、セキュリティサービスなどの基本的なビジネスサービスは、さまざまなビジネスアプリケーションをサポートする基本要素です。これらのサービスを抽出し、分散サービス フレームワークを使用して分散サービスを構築します。アリのダボは良い選択です。
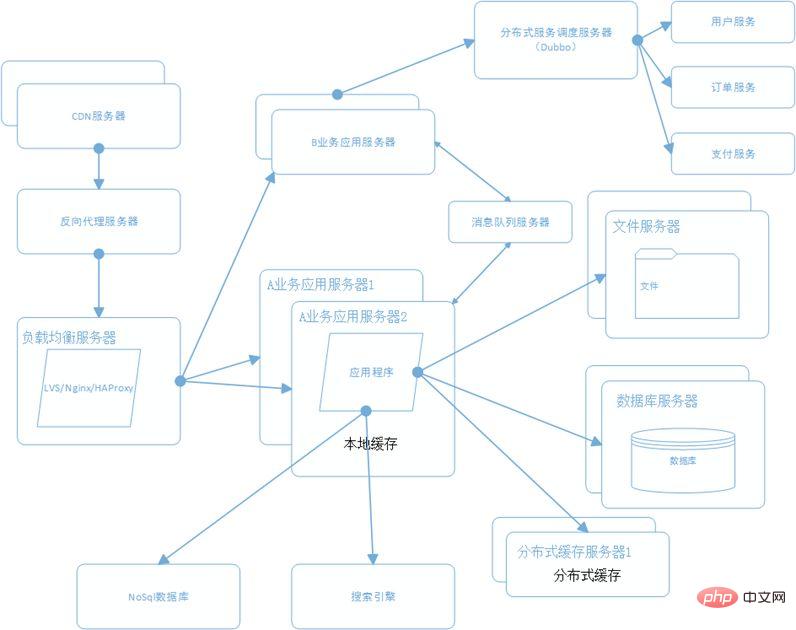
#e コマース アーキテクチャを図で説明します
1. 電子商取引の理由コマース ケース分散型大規模 Web サイトには現在、いくつかの主要なカテゴリがあります:
NetEase、Sina などの大規模ポータル、 -
キャンパス、Kaixin.com などの SNS Web サイト、 Alibaba、JD.com、Gome Online、Autohome などの電子商取引 Web サイト
大規模なポータルは一般にニュース情報であり、CDN、静的、その他の方法を使用して最適化できます。Kaixin.com やその他の Web サイトはよりインタラクティブであり、より多くの NoSQL や分散キャッシュが導入される可能性があります。高性能通信フレームワークなどECサイトは上記2つの特徴を持ち、例えば商品詳細はCDNを利用できる静的なもの、双方向性の高いものはNoSQLなどの技術を利用する必要があります。そこで、ECサイトを事例として分析します。
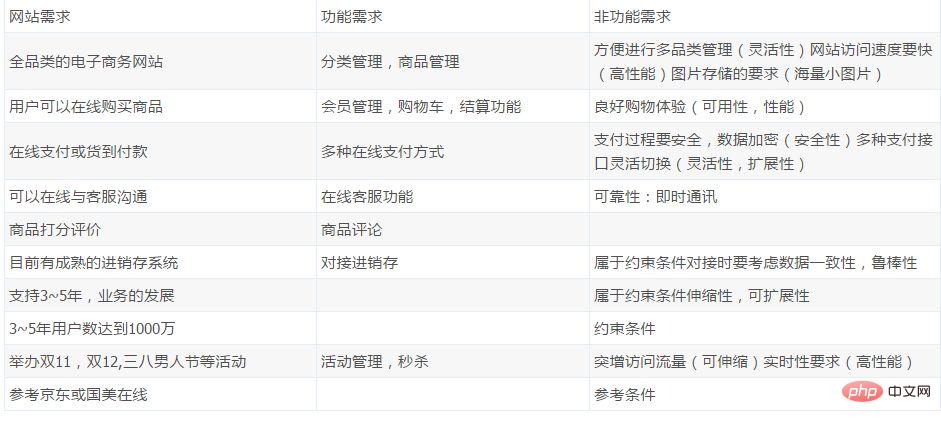
2. EC サイトのニーズ
顧客ニーズ:
完全なカテゴリを確立する電子商取引 Web サイト (B2C)、ユーザーはオンラインで商品を購入、オンラインで支払う、または代金引換で支払うことができます。 ユーザーは購入時にオンラインでカスタマー サービスと通信できます。 商品を受け取った後、ユーザーは商品を評価して評価することができます; 現在、成熟した購入、販売、在庫システムがあり、システムと接続する必要があります。ウェブサイト; 3 ~ 5 年以内にビジネス展開をサポートできるようになりたい; - #ユーザー数は に達すると予想されます3~5年で1,000万
- ダブル11、ダブル12、3月8日メンズデーなどを定期的に開催;
- その他機能については、JD.com や Gome Online などの Web サイトを参照してください。
要件関数マトリックス要件管理への従来のアプローチは、ユースケース図またはモジュール図 (要件リスト) を使用して要件を記述することです。そうすると、非常に重要な要件 (非機能要件) が見落とされることがよくあるため、要件関数マトリックスを使用して要件を記述することをお勧めします。この電子商取引 Web サイトの需要マトリックスは次のとおりです:
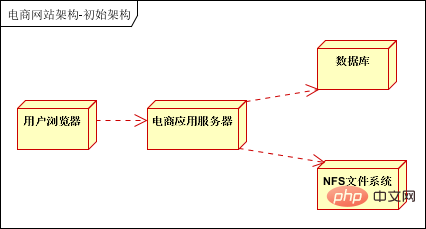
一般的な Web サイトの場合、最初のアプローチは 3 つのサーバーを使用し、1 つはアプリケーションの展開に、1 つはデータベースの展開に、もう 1 つは NFS ファイル システムの展開に使用します。 これは、ここ数年の比較的伝統的なアプローチであり、100,000 人を超えるメンバーがいる Web サイト、垂直型の衣類デザイン ポータル、および多数の写真を見てきました。サーバーは、アプリケーション、データベース、イメージ ストレージの展開に使用されます。パフォーマンス上の問題がたくさんありました。以下に示すように:
ただし、現在の主流の Web サイト アーキテクチャは、地球を揺るがす変化を遂げています。一般に、高可用性設計にはクラスターアプローチが使用されます。少なくとも次のようになります:
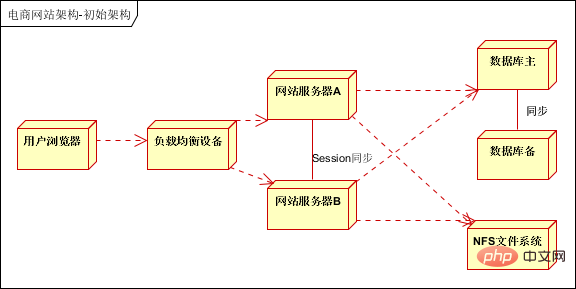
- ##クラスターの使用高可用性を実現する冗長アプリケーション サーバー (負荷分散装置をアプリケーションと一緒に展開できます)
- データベースのアクティブ モードとバックアップ モードを使用して、データ バックアップと高可用性を実現します;
見積り手順:
- 登録ユーザー数- 日平均UV量 - 日平均PV量 - 日平均同時量;
- ピーク推定値:通常量の2~3倍;
- 計算同時実行量 (同時実行数、トランザクション数) とストレージ容量に基づくシステム容量。
1 日の UV は 200 万 (28 原則); 1 日 30 回クリックして閲覧します; -
PV ボリューム: 200*30=6,000 万; 集中訪問: 24 0.2=4.8 時間で 6,000 万 0.8=4,800 万 (2 つの 8 原則) ; 1 分あたりの同時実行数: 4.8*60=288 分、1 分あたり 4800/288=167,000 訪問数 (ほぼ等しい); 1 秒あたりの同時実行数: 167,000/60=2780 (ほぼ等しい); 仮定: ピーク期間が通常値の 3 倍である場合、1 秒あたりの同時実行数は 8340 に達します。回。 1 ミリ秒 = 1.3 訪問;
数学をよく勉強しなかったことを後悔していますか? ! (上記の計算が間違っているかどうかはわかりませんが、はは~~) サーバーの見積もり: (Tomcat サーバーを例として取り上げます) Web サーバーによると、1 秒あたり 300 の同時計算をサポートします。通常は 10 台のサーバーが必要です (ほぼ等しい)。[Tomcat のデフォルト構成は 150]、ピーク時には 30 台のサーバーが必要です。容量の見積もり: 70/90 の原則 システムの CPU 使用率は通常 70% 程度に維持され、ピーク時には 90% に達し、リソースを無駄にせず、比較的安定しています。メモリとIOは似ています。サーバー構成、ビジネス ロジックの複雑さなどがすべて影響するため、上記の見積もりは参考値です。ここでは、CPU、ハードディスク、ネットワークなどは評価されなくなります。 5. ウェブサイトのアーキテクチャ分析
多数のサーバーを導入する必要があり、ピーク時には 30 台の Web サーバーが導入される可能性があります。さらに、この 30 台のサーバーはフラッシュセールやイベントのときにのみ使用されるため、非常に無駄になります。 すべてのアプリケーションは同じサーバー上にデプロイされており、アプリケーション間の結合は深刻です。垂直方向と水平方向のスライスが必要です。 - #多数のアプリケーションに冗長コードが存在します #サーバー セッションの同期は大量のメモリとネットワーク帯域幅を消費します
- データはデータベースへの頻繁なアクセスを必要とし、データベースへのアクセスのプレッシャーは非常に大きくなります。
- 大規模な Web サイトでは、通常、次のアーキテクチャの最適化を行う必要があります (最適化は、アーキテクチャを設計するときに考慮する必要があります。通常、アーキテクチャ/コード レベルで解決されます。チューニングは主にJVM チューニングなどの単純なパラメータの調整。チューニングに多くのコード変更が含まれる場合、それはチューニングではなくリファクタリングです):
ビジネス分割 アプリケーション クラスターの展開 (分散展開、クラスター展開、負荷分散) マルチレベル キャッシュ シングル サインオン (分散セッション) -
データベース クラスター (読み取り/書き込み分離、サブデータベースおよびサブテーブル) サービスベース メッセージキュー その他のテクノロジー
6. ウェブサイト構造の最適化
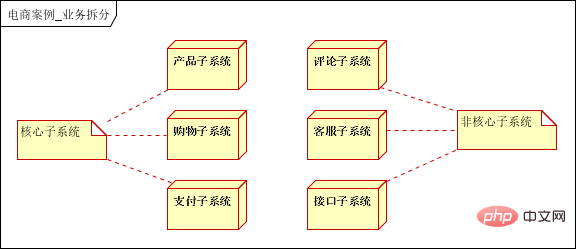
6.1 事業分割
ベースビジネス属性に基づく垂直セグメンテーションは、製品サブシステム、ショッピング サブシステム、支払いサブシステム、レビュー サブシステム、顧客サービス サブシステム、およびインターフェイス サブシステム (購買、販売、在庫、SMS などの外部システムとの相互接続) に分割されます。業務サブシステムのレベル定義に基づいて、基幹システムと非基幹システムに分類できます。コア システム: 製品サブシステム、ショッピング サブシステム、支払いサブシステム、非コア システム: レビュー サブシステム、顧客サービス サブシステム、インターフェイス サブシステム。
ビジネス分割の役割: サブシステムへのアップグレードは、専門のチームと部門によって処理できます。専門家が専門的なことを行い、モジュール間の結合とスケーラビリティの問題を解決します。各サブシステムは、回避するために個別に導入されます。集中展開の問題により、1 つのアプリケーションがハングし、すべてのアプリケーションが使用できなくなる。 レベル定義機能: トラフィック バースト中に主要なアプリケーションを保護し、適切な機能低下を実現するために使用され、主要なアプリケーションが影響を受けないように保護します。
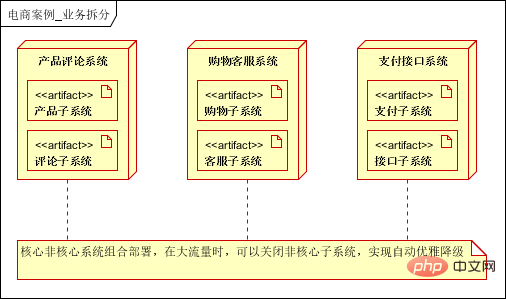
6.2 アプリケーション クラスターの展開 (分散、クラスター化、負荷分散)
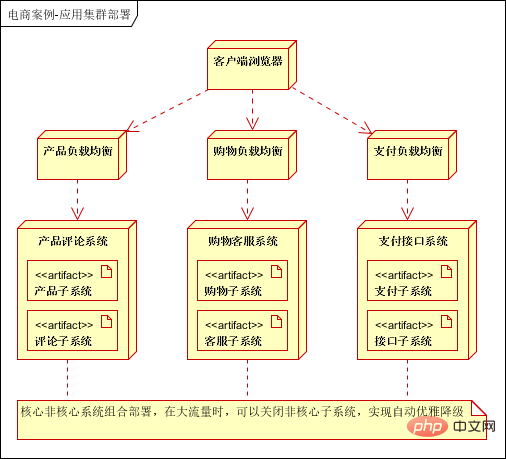
分散展開: ビジネスを分割した後、アプリケーションは個別に展開されます。 、アプリケーションは RPC を介して直接リモート通信します。 クラスター展開: 電子商取引 Web サイトの高可用性要件のため、各アプリケーションはクラスター展開用に少なくとも 2 台のサーバーを展開する必要があります。 ## 負荷分散: 高可用性システムに必要です。一般的なアプリケーションは負荷分散を通じて高可用性を実現し、分散サービスは組み込みの負荷分散を通じて高可用性を実現し、リレーショナル データベースはアクティブとバックアップを通じて高可用性を実現します。メソッド。 - # クラスター展開後のアーキテクチャ図:
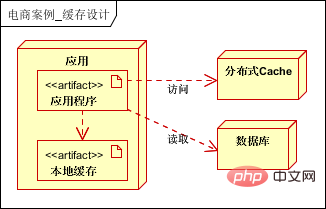
#6.3 詳細レベルキャッシュキャッシュは一般に、保存場所に応じてローカル キャッシュと分散キャッシュの 2 種類に分類できます。このケースでは、2次キャッシュ方式を使用してキャッシュを設計します。一次キャッシュはローカル キャッシュ、二次キャッシュは分散キャッシュです。 (さらに細分化されたページ キャッシュ、フラグメント キャッシュなどもあります) 1 次キャッシュ、キャッシュ データ ディクショナリ、一般的に使用されるホットスポット データやその他の基本的に不変/定期的に変化する情報、2 次キャッシュは必要なすべてのキャッシュをキャッシュします。 1 次キャッシュの有効期限が切れたり、使用できなくなったりすると、2 次キャッシュ内のデータがアクセスされます。 2 次キャッシュがない場合は、データベースにアクセスします。キャッシュ比率は通常 1:4 であるため、キャッシュの使用を検討できます。 (理論的には 1:2 で十分です)。
- キャッシュ自動的に期限切れ;
- #キャッシュ トリガーの期限切れ;
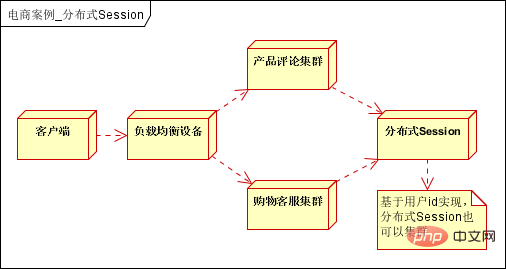
ユーザーが初めてログインすると、ユーザー ID をキーとしてセッション情報 (ユーザー ID とユーザー情報) が分散セッションに書き込まれます。 - ユーザーが再度ログインしたときに、配布されたセッションを取得してセッション情報があるかどうかを確認し、ない場合はログイン ページに移動します。一般的にはキャッシュミドルウェアを使用して実装され、Redis の使用が推奨されるため、分散セッションがダウンした後に永続ストレージからセッション情報をロードすることを容易にする永続化機能があります。 ##セッションを保存するときに、セッション保持時間を 15 分などに設定できますが、それを超えると自動的にタイムアウトになります;
- キャッシュ ミドルウェアと組み合わせると、実装された分散セッションは、セッションセッションはとてもうまくいきました。
- 6.5 データベース クラスター (読み取りと書き込み、サブデータベースとサブテーブルの分離)
#事業分割後: 各サブシステムには個別のライブラリが必要です。
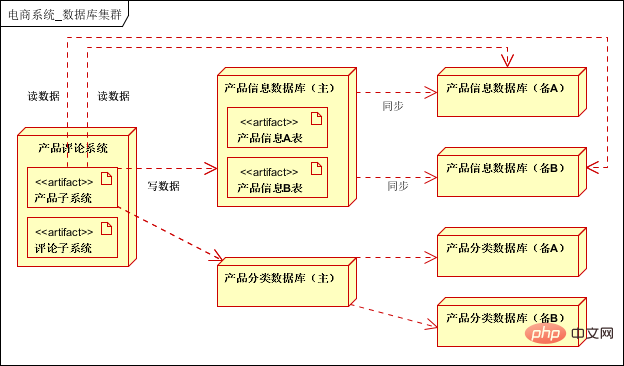
- サブデータベースでは、別のテーブルに基づいて読み取りと書き込みが分離されており、
- 関連ミドルウェアは Cobar (現在 Alibaba) を参照できます。メンテナンスされなくなりました)、TDDL (Alibaba)、Atlas (Qihoo 360)、MyCat。データベースとテーブルをシャーディングした後のシーケンス、JOIN、トランザクションの問題は、データベースとテーブルのシャーディングの共有のテーマで紹介されます。
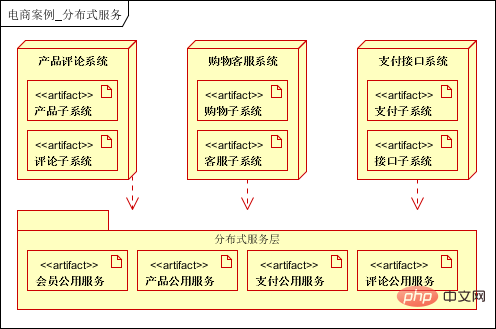
- 6.6 サービス化
- 複数のサブシステムに共通する機能/モジュールを抽出し、パブリックサービスとして利用します。たとえば、この場合のメンバーシップ サブシステムは、公共サービスとして抽出できます。
-

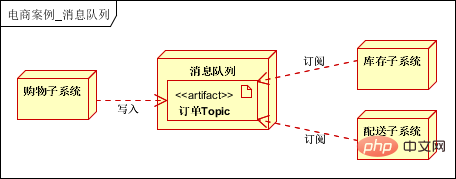
メッセージ キューはサブシステム/モジュールを解決できます。それらを結合することで、非同期、高可用性、高性能のシステムが実現します。これは分散システムの標準構成です。この場合、メッセージ キューは主にショッピングと配送のリンクで使用されます。- ユーザーが注文すると、注文はメッセージ キューに書き込まれ、クライアントに直接返されます。
- 在庫サブシステム: 読み取りメッセージキュー情報、在庫削減の完了;
- 配布サブシステム: メッセージキュー情報を読み取り、配布を実行;
上で紹介した事業分割に加えて、アプリケーション クラスター、マルチレベル キャッシュ、シングル サインデータベースのクラスタリング、サービス化、およびメッセージ キュー。 CDN、リバースプロキシ、分散ファイルシステム、ビッグデータ処理などのシステムもあります。ここでは詳しく紹介しませんが、Du Niang/Google に聞いてもいいですし、機会があれば皆さんにシェアしてもいいでしょう。
##大規模な Web サイトのアーキテクチャはビジネス ニーズに基づいて常に改善されており、さまざまなビジネス特性に基づいて具体的な設計や検討が行われますが、この記事では従来の大規模な Web サイトに含まれる技術や手法の一部を説明するだけですが、皆様のインスピレーションになれば幸いです。
以上が10分で解決 | 大規模分散型ECシステムのアーキテクチャの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。