
ホームページ >テクノロジー周辺機器 >AI >OpenMLDB 研究開発リーダー、Lu Mian、第 4 パラダイム システム アーキテクト: オープンソースの機械学習データベース OpenMLDB: オンラインとオフラインで一貫した運用レベルの機能プラットフォーム
OpenMLDB 研究開発リーダー、Lu Mian、第 4 パラダイム システム アーキテクト: オープンソースの機械学習データベース OpenMLDB: オンラインとオフラインで一貫した運用レベルの機能プラットフォーム

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-08 21:41:071016ブラウズ

ゲスト: Lu Mian
主催: Mo Se
皆さんにインスピレーションを与えることを願い、スピーチの内容を以下のように構成しました。 人工知能エンジニアリングの実装におけるデータと機能の課題 現在、統計によると、人工知能の実装時間の 95% がデータに費やされています。市場には MySQL などのさまざまなデータ ツールがありますが、人工知能の実装の問題を解決するには程遠いです。そこで、まずデータの問題を見てみましょう。 機械学習アプリケーションの開発に参加したことがある方は、次の図に示すように、MLOps に深い感銘を受けるはずです。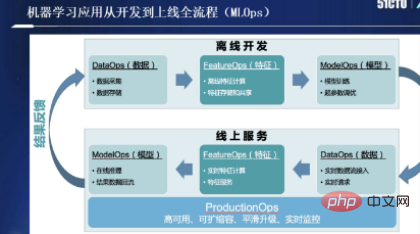
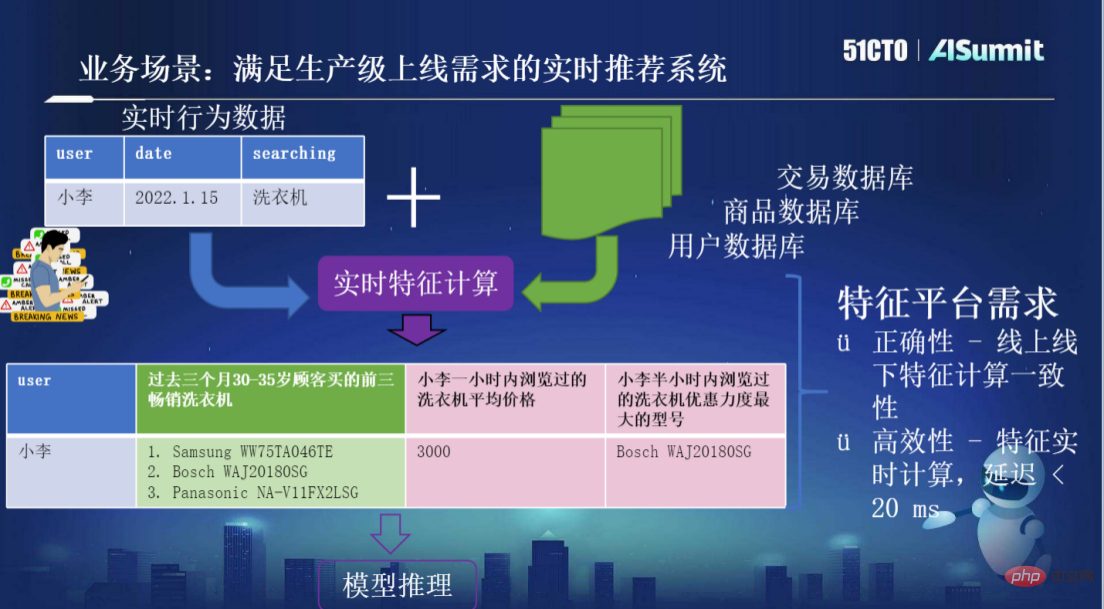
たとえば、次の図に示すように、本番レベルのオンライン要件を満たすリアルタイム レコメンデーション システムが構築されています。ユーザー Xiao Li はキーワード「洗濯機」で検索を実行します。システム内のリクエスト データ、ユーザー、製品、トランザクションなどの情報データがリアルタイムの特徴計算のために結合され、その後、より意味のある特徴が生成されます。これが、いわゆる特徴エンジニアリング、特徴を生成するプロセスです。 。たとえば、このシステムは「過去 3 か月間に特定の年齢層の顧客が購入した洗濯機の売れ筋トップ 3」を生成しますが、このタイプの機能は強いタイムリー性を必要とせず、より長い履歴データに基づいて計算されます。ただし、システムは「過去 1 時間/30 分以内のレコードの閲覧」など、時間に敏感なデータも必要とする場合があります。システムは新しく計算された特徴を取得した後、推論用のモデルを提供します。このようなシステム機能プラットフォームには主に 2 つの要件があり、1 つは正確性、つまりオンラインとオフラインの特徴計算の一貫性、もう 1 つは効率、つまりリアルタイムの特徴計算、遅延です。
 ##特徴量計算の開発から発売までの全ライフサイクル
##特徴量計算の開発から発売までの全ライフサイクル
OpenMLDB 手法が導入される前は、主に特徴量計算に次の図に示すプロセスを使用していました。発達。
#まず、データ サイエンティストが Python/SparkSQL ツールを使用してオフライン特徴抽出を行うシナリオを作成する必要があります。データサイエンティストの KPI は、精度を満たすビジネス要件モデルを構築することであり、モデルの品質が基準に達するとタスクは完了します。機能スクリプトがオンラインになった後に直面するエンジニアリング上の課題 (低遅延、高同時実行性、高可用性など) は、科学者の管轄外です。
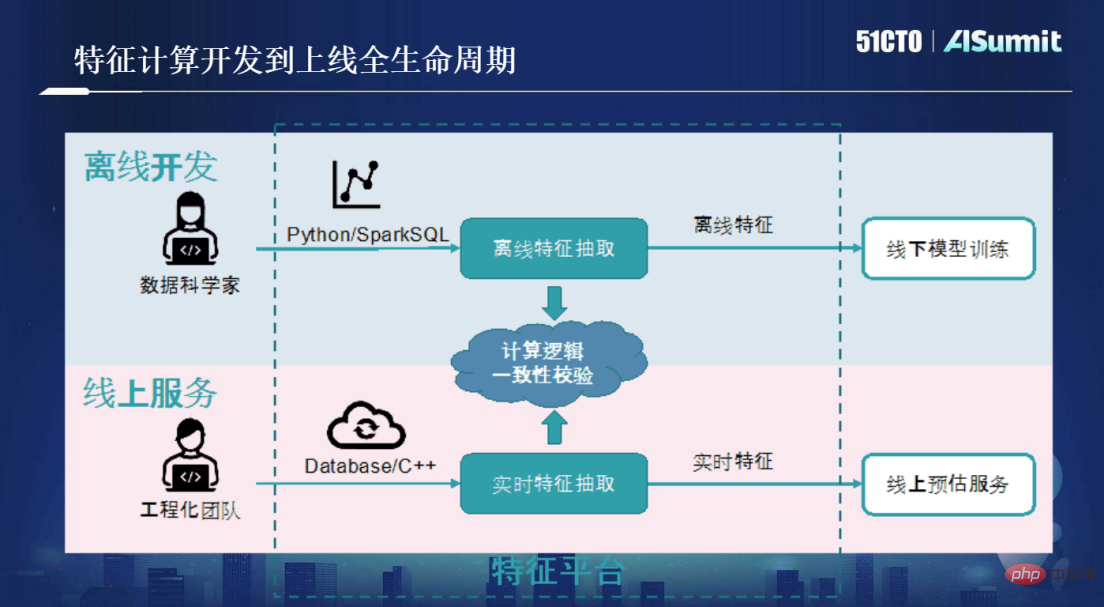 ##データ サイエンティストが作成した Python スクリプトをオンラインに公開するには、エンジニアリング チームが介入する必要があります。科学者によって作成されたオフライン スクリプトは再構築および最適化され、リアルタイムの特徴抽出サービスには C/Database が使用されました。これにより、低遅延、高同時実行性、高可用性に関する一連のエンジニアリング要件が満たされ、機能スクリプトをオンライン サービス用に真にオンライン化できるようになります。
##データ サイエンティストが作成した Python スクリプトをオンラインに公開するには、エンジニアリング チームが介入する必要があります。科学者によって作成されたオフライン スクリプトは再構築および最適化され、リアルタイムの特徴抽出サービスには C/Database が使用されました。これにより、低遅延、高同時実行性、高可用性に関する一連のエンジニアリング要件が満たされ、機能スクリプトをオンライン サービス用に真にオンライン化できるようになります。
#このプロセスは非常に費用がかかり、2 組のスキル チームの介入が必要であり、異なるツールを使用します。 2 つのプロセスが完了したら、計算ロジックの一貫性をチェックする必要があります。つまり、データ サイエンティストが開発した特徴スクリプトの計算ロジックと、最終的なリアルタイム特徴抽出のロジックが完全に一致している必要があります。 。この要件は明確かつ単純に見えますが、一貫性検証プロセス中に多大な通信コスト、テスト コスト、反復開発コストが発生します。過去の経験によれば、プロジェクトが大規模になればなるほど、整合性検証に時間がかかり、コストが非常に高くなります。
一般的に、整合性検証プロセス中にオンラインとオフラインの間で不一致が発生する主な理由は、開発ツールが不一致であることです。たとえば、科学者は Python を使用します。 、エンジニアリング チーム データベースが使用されており、ツールの機能の違いにより機能の妥協や不一致が生じる可能性があり、データ、アルゴリズム、認識の定義にもギャップが存在します。
#つまり、従来の 2 セットのプロセスに基づく開発コストは非常に高く、異なるスキル ステーションからの 2 セットの開発者と開発が必要になります。 2台のシステムの運用や、積み上げ検証、検証なども追加する必要があります。
#OpenMLDB は、低コストのオープンソース ソリューションを提供します。
OpenMLDB: オンラインとオフラインで一貫した運用レベルの特徴計算プラットフォーム
昨年 6 月、OpenMLDB は正式にオープンソース化され、は、オープン ソース コミュニティ プロジェクトの若いプレーヤーですが、100 を超えるシナリオで実装され、300 を超えるノードをカバーしています。
OpenMLDB は、オープン ソースの機械学習データベースであり、その主な機能は、一貫したオンラインおよびオフラインの機能プラットフォームを提供することです。では、OpenMLDB はどのようにして高いパフォーマンスと正確さのニーズを満たすのでしょうか?
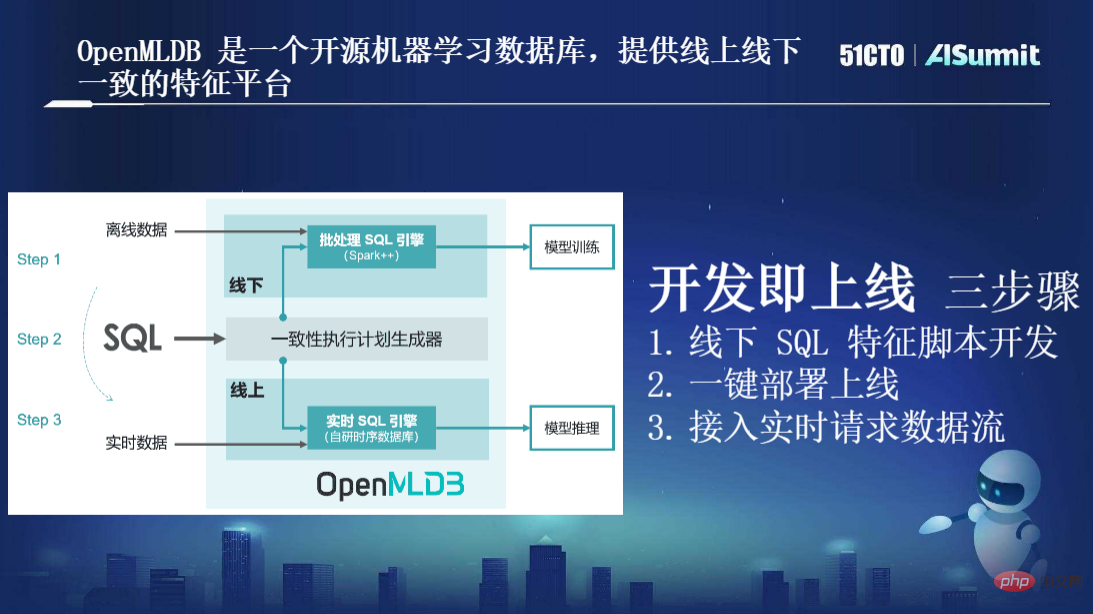 上の図に示すように、まず、OpenMLDB で使用されるプログラミング言語は SQL だけです。データ サイエンティストと開発者の両方が SQL を使用して機能を表現します。
上の図に示すように、まず、OpenMLDB で使用されるプログラミング言語は SQL だけです。データ サイエンティストと開発者の両方が SQL を使用して機能を表現します。
2 つ目は、OpenMLDB 内で 2 つのエンジンが分離されており、1 つは Spark に基づいてソース コード レベルの最適化を実行し、より高性能なコンピューティング手法を提供し、構文拡張を行う「バッチ SQL エンジン」です。もう 1 つのセットは「リアルタイム SQL エンジン」で、これは私たちのチームが自社開発したリソース時系列データベースであり、デフォルトはメモリ ストレージ エンジンに基づく時系列データベースです。 「リアルタイム SQL エンジン」に基づいて、高可用性、低遅延、高同時実行性を確保しながら、オンラインで効率的なミリ秒レベルのリアルタイム計算を実現します。
これら 2 つのエンジンの間には、オンラインとオフラインの実行プラン ロジックの一貫性を確保することを目的とした重要な「一貫性実行プラン ジェネレーター」もあります。これにより、手動校正を必要とせずに、オンラインとオフラインの一貫性が自然に保証されます。
つまり、このアーキテクチャに基づいて、私たちの最終目標は「開発とオンライン」の最適化目標を達成することであり、これには主に 3 つのステップが含まれます: オフライン SQL 機能スクリプト開発。 [展開とオンライン] をクリックし、リアルタイムのリクエスト データ ストリームにアクセスします。
前の 2 セットのプロセス、2 セットのツール チェーン、および 2 セットの開発者投資と比較すると、このエンジン セットの最大の利点は次のとおりであることがわかります。エンジニアリング コストが大幅に節約されます。つまり、データ サイエンティストが SQL を使用して機能スクリプトを開発している限り、エンジニアリング チームが 2 回目の最適化を行う必要はなくなり、直接オンラインに移行できるようになります。オンラインとオフラインの一貫性検証の中間手動操作により、時間とコストが大幅に節約されます。
次の図は、オフライン開発からオンライン サービスまでの OpenMLDB の完全なプロセスを示しています:
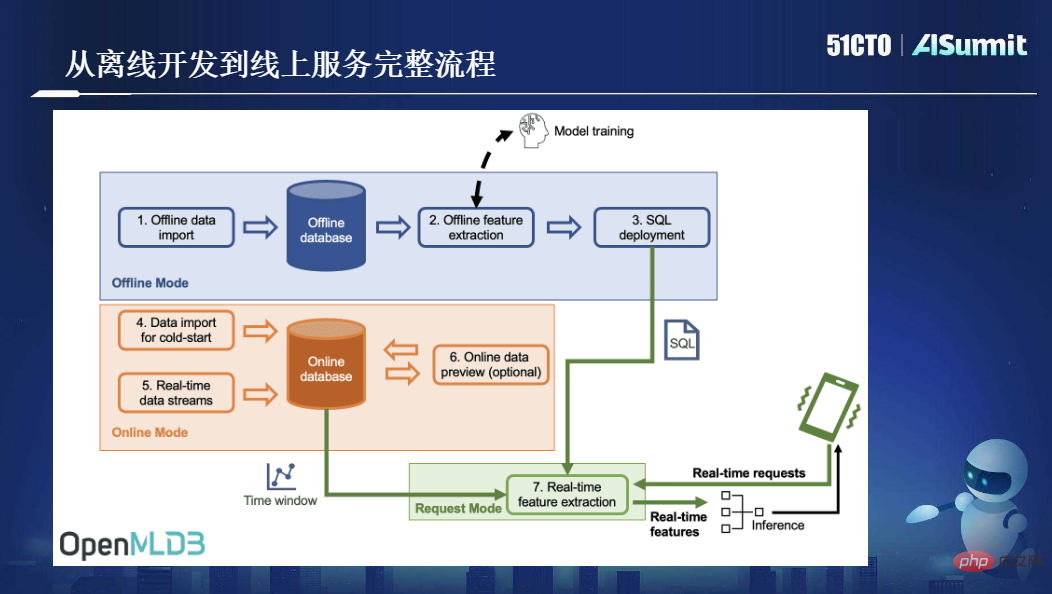
全体として、OpenMLDB は、機械学習のオンラインとオフラインの一貫性という中核的な問題を解決し、中核となる機能であるミリ秒レベルのリアルタイム特徴計算を提供します。この 2 点が OpenMLDB が提供する核となる価値です。
OpenMLDB にはオンラインとオフラインの 2 つのエンジン セットがあるため、アプリケーション方法も異なります。次の図は、参考として推奨される方法を示しています。

次に、OpenMLDB のいくつかのコア コンポーネントや機能を紹介します。
特徴 1、オンラインとオフラインの一貫した実行エンジン。統合された基盤となるコンピューティング機能に基づいて、論理プランから物理プランまでオンラインとオフラインの実行モードを適応的に調整し、オンラインとオフラインを実現します。一貫性は当然保証されます。
特徴 2 つの高性能オンライン特徴計算エンジン (高性能 2 層ジャンプ テーブル メモリ インデックス データ構造を含む)、リアルタイム コンピューティング事前集計テクノロジ、ハイブリッド最適化戦略を提供します。メモリ/ディスクの両方のストレージ エンジンにより、さまざまなパフォーマンスとコストの要件を満たします。
機能 3 は、マルチウィンドウ並列コンピューティングの最適化、データ スキュー計算の最適化、SQL 構文拡張、特徴計算用に最適化された Spark ディストリビューションなど、特徴計算用に最適化されたオフライン コンピューティング エンジンです。これらすべてにより、コミュニティ バージョンと比較してパフォーマンスが大幅に向上します。
機能 4、特徴エンジニアリングのための SQL 拡張機能。前述したように特徴定義にはSQLを使用しますが、実際にはSQLは特徴計算を目的として設計されたものではないため、多くの事例を検討し、使用経験を蓄積した結果、SQL構文をいくつか拡張する必要があることがわかりました。特徴計算の処理を改善するため。ここには 2 つの重要な拡張機能があります。1 つは LAST JOIN で、もう 1 つはより一般的に使用される WINDOW UNION です (次の図に示すように)。
機能 5、エンタープライズ レベルの機能サポート。 OpenMLDBは分散データベースとして、高可用性、シームレスな拡張・縮小、スムーズなアップグレードなどの特徴を持ち、多くの企業で導入されています。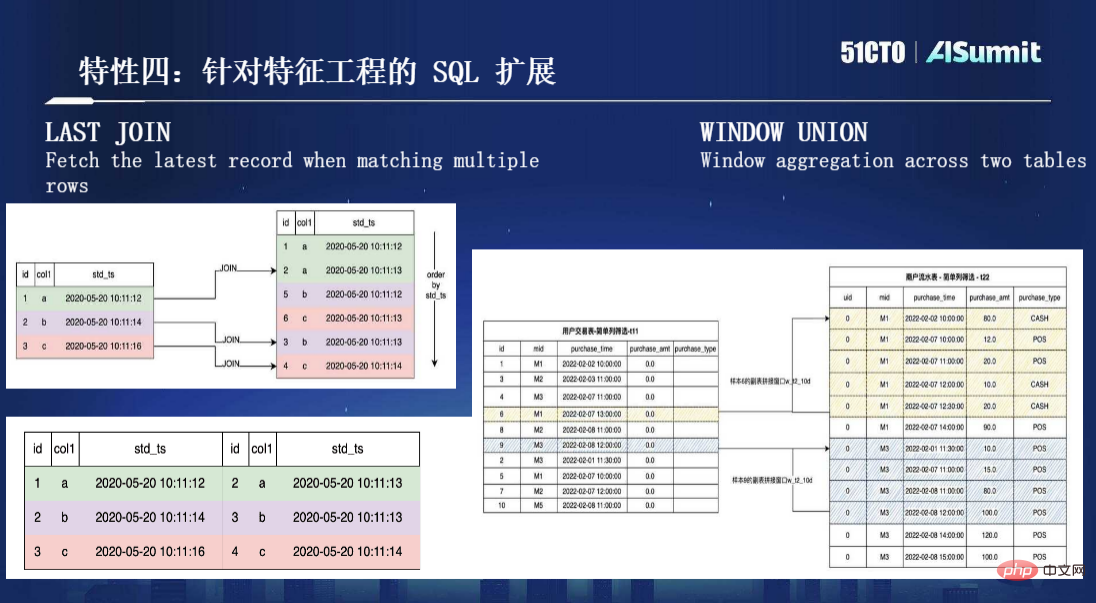 特徴 6: SQL を中心とした開発と管理 OpenMLDB もデータベース管理です。従来のデータベースに似ています。たとえば、CLI が提供されていれば、OpenMLDB は次のことができます。オフライン特徴量計算、オンライン SQL ソリューション、オンライン リクエストなどのプロセス全体が CLI に実装されており、SQL と CLI に基づいたフルプロセスの開発エクスペリエンスを提供できます。
特徴 6: SQL を中心とした開発と管理 OpenMLDB もデータベース管理です。従来のデータベースに似ています。たとえば、CLI が提供されていれば、OpenMLDB は次のことができます。オフライン特徴量計算、オンライン SQL ソリューション、オンライン リクエストなどのプロセス全体が CLI に実装されており、SQL と CLI に基づいたフルプロセスの開発エクスペリエンスを提供できます。
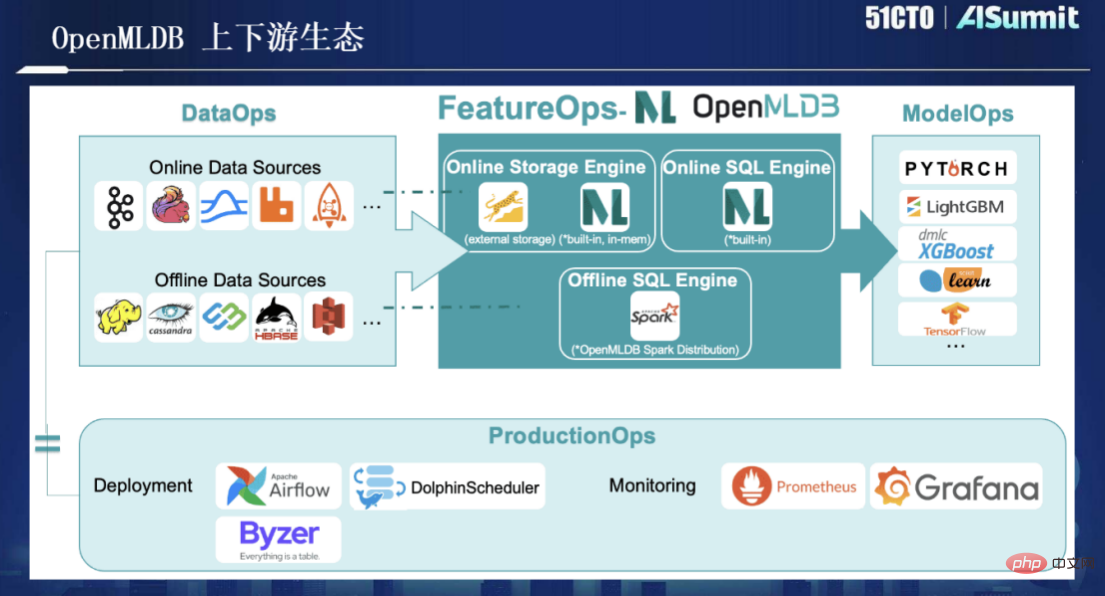
さらに、OpenMLDB は現在オープンソースであり、その上流と下流のエコロジーの拡大は次の図に示すとおりです。
OpenMLDB v0.5.0: パフォーマンス、コスト、使いやすさの強化
次に、## を紹介します。 #OpenMLDB v0.5 の新しいバージョンでは、3 つの側面でいくつかの機能強化が行われました。
まず、OpenMLDB の開発の歴史を見てみましょう。 OpenMLDBは2021年6月にオープンソース化されましたが、実はそれ以前から多くの顧客を抱えており、2017年には最初のコードの開発を開始していました。
オープンソースになってから 1 周年で、私たちは約 5 つのバージョンを繰り返しました。以前のバージョンと比較して、v0.5.0 には次の重要な機能があります。
パフォーマンス アップグレード、集約テクノロジにより、ロング ウィンドウのパフォーマンスが大幅に向上します。事前集計の最適化により、長いウィンドウのクエリにおけるレイテンシーとスループットの両方の点でパフォーマンスが 2 桁向上します。
コスト削減、バージョン v0.5.0 以降、オンライン エンジンにはメモリと外部メモリに基づく 2 つのエンジン オプションが提供されます。メモリ、低遅延、高同時実行性に基づいており、より高い使用コストでミリ秒レベルの遅延応答を提供します。外部メモリをベースとしているため、パフォーマンスの影響を受けにくく、SSD をベースとした低コストの使用と一般的な構成でコストを 75% 削減できます。 2 つのエンジンの上位層のビジネス コードは認識されず、コストをかけずに切り替えることができます。
使いやすさの向上。バージョン v0.5.0 ではユーザー定義関数 (UDF) を導入しました。つまり、SQL が特徴抽出論理式を満たすことができない場合でも、C/C UDF、UDF 動的登録などのユーザー定義関数がサポートされています。コンピューティング ロジックを拡張し、アプリケーションの適用範囲を向上させます。
最後に、すべての OpenMLDB 開発者に感謝します。オープン ソースが始まって以来、100 人近くの貢献者が私たちのコミュニティにコードを貢献してきました。同時に、より多くの開発者の参加も歓迎します。コミュニティに参加し、自分の力を出し合って、より有意義なことを一緒に行いましょう。
#カンファレンスのスピーチ リプレイと PPT がオンラインになりました。 公式 Web サイト# にアクセスしてください。 ##エキサイティングなコンテンツをご覧ください。
以上がOpenMLDB 研究開発リーダー、Lu Mian、第 4 パラダイム システム アーキテクト: オープンソースの機械学習データベース OpenMLDB: オンラインとオフラインで一貫した運用レベルの機能プラットフォームの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。