


arXiv 論文「Unifying Voxel-based Representation with Transformer for 3D Object Detection」、6 月 22 日、香港中文大学、香港大学、Megvii Technology (孫建博士を追悼)、および Simou Technology、等

この論文では、UVTR と呼ばれる統合マルチモーダル 3D ターゲット検出フレームワークを提案します。この方法は、ボクセル空間のマルチモーダル表現を統合し、正確かつ堅牢なシングルモーダルまたはクロスモーダル 3D 検出を可能にすることを目的としています。この目的を達成するために、まずモダリティ固有の空間が、ボクセル特徴空間へのさまざまな入力を表すように設計されます。高さを圧縮せずにボクセル空間を維持し、意味上のあいまいさを軽減し、空間相互作用を可能にします。この統一されたアプローチに基づいて、知識伝達やモーダル融合など、さまざまなセンサーの固有の特性を十分に活用するためのクロスモーダルインタラクションが提案されています。このようにして、点群のジオメトリを意識した表現と画像内のコンテキストに富んだ特徴をうまく活用することができ、その結果、パフォーマンスと堅牢性が向上します。
トランスフォーマー デコーダは、学習可能な位置を持つ統一空間から特徴を効率的にサンプリングするために使用され、オブジェクト レベルの対話が容易になります。一般的に言えば、UVTR は、統一されたフレームワークでさまざまなモダリティを表現する初期の試みを表しており、シングルモーダルおよびマルチモーダル入力に関する以前の研究を上回り、nuScenes テスト セット、LIDAR、カメラ、およびマルチモーダル出力の NDS で優れたパフォーマンスを達成しています。はそれぞれ69.7%、55.1%、71.1%です。
コード:https://github.com/dvlab-research/UVTR.
図に示すように:
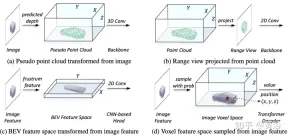
#表現統一プロセスでは、入力レベルのフローと特徴レベルのフローの表現に大別できます。最初のアプローチでは、マルチモーダル データがネットワークの先頭で調整されます。特に、(a) の疑似点群は予測深度支援画像から変換され、(b) のレンジビュー画像は点群から投影されます。擬似点群の深度の不正確さとレンジビュー画像の 3D 幾何学的崩壊により、データの空間構造が破壊され、結果が悪くなります。特徴レベルの方法の場合、図 (c) に示すように、画像特徴を錐台に変換し、BEV 空間に圧縮するのが一般的な方法です。ただし、光線のような軌道のため、各位置での高さ情報 (高さ) の圧縮によりさまざまなターゲットの特徴が集約され、意味上の曖昧さが生じます。同時に、その暗黙的なアプローチでは、3 次元空間での明示的なフィーチャの相互作用をサポートすることが難しく、さらなる知識の伝達が制限されます。したがって、モーダルギャップを埋め、多面的な相互作用を促進するには、より統一された表現が必要です。
この記事で提案するフレームワークは、ボクセルベースの表現とトランスフォーマーを統合します。特に、ボクセルベースの明示的な空間における画像と点群の特徴表現と相互作用。画像の場合、図 (d) に示すように、予測された深さと幾何学的制約に従って画像平面から特徴をサンプリングすることによってボクセル空間が構築されます。点群の場合、位置が正確であれば、自然にフィーチャをボクセルに関連付けることができます。次に、空間相互作用のためにボクセル エンコーダーが導入され、隣接するフィーチャ間の関係が確立されます。このようにして、クロスモーダル インタラクションは各ボクセル空間内のフィーチャで自然に進行します。ターゲット レベルのインタラクションの場合、図 (d) に示すように、デコーダとして変形可能トランスが使用され、統合ボクセル空間内の各位置 (x、y、z) でターゲット クエリ固有の特徴がサンプリングされます。同時に、3D クエリ位置の導入により、BEV 空間の高さ情報 (高さ) 圧縮によって引き起こされる意味上の曖昧さが効果的に軽減されます。
図に示すように、マルチモーダル入力の UVTR アーキテクチャです。単一フレームまたはマルチフレームのイメージと点群が与えられると、まず単一のバックボーンで処理され、モダリティ固有の空間 VI に変換されます。 VP では、画像に対してビュー変換が使用されます。ボクセル エンコーダーでは、特徴が空間的に相互作用するため、トレーニング中に知識の伝達を簡単にサポートできます。設定に応じて、モーダル スイッチを使用してシングルモーダル機能またはマルチモーダル機能を選択します。最後に、学習可能な位置を含む統合空間 VU から特徴がサンプリングされ、トランスフォーマー デコーダーを使用して予測されます。
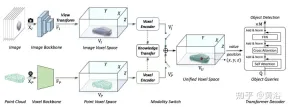
図は、ビュー変換の詳細を示しています。

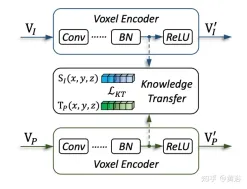
図は、ナレッジ移行の詳細を示しています。
実験結果は次のとおりです:


以上がTransformer は 3D オブジェクト検出のためにボクセルベースの表現を統合しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PM
ほとんどが使用されています10 Power BIチャート - 分析VidhyaApr 16, 2025 pm 12:05 PMMicrosoft PowerBIチャートでデータ視覚化の力を活用する 今日のデータ駆動型の世界では、複雑な情報を非技術的な視聴者に効果的に伝えることが重要です。 データの視覚化は、このギャップを橋渡しし、生データを変換するi
 AIのエキスパートシステムApr 16, 2025 pm 12:00 PM
AIのエキスパートシステムApr 16, 2025 pm 12:00 PMエキスパートシステム:AIの意思決定力に深く飛び込みます 医療診断から財務計画まで、あらゆることに関する専門家のアドバイスにアクセスできることを想像してください。 それが人工知能の専門家システムの力です。 これらのシステムはプロを模倣します
 3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AM
3人の最高の雰囲気コーダーがこのAI革命をコードで分解するApr 16, 2025 am 11:58 AMまず第一に、これがすぐに起こっていることは明らかです。さまざまな企業が、現在AIによって書かれているコードの割合について話しており、これらは迅速なクリップで増加しています。すでに多くの仕事の移動があります
 滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM
滑走路AIのGen-4:AIモンタージュはどのように不条理を超えることができますかApr 16, 2025 am 11:45 AM映画業界は、デジタルマーケティングからソーシャルメディアまで、すべてのクリエイティブセクターとともに、技術的な岐路に立っています。人工知能が視覚的なストーリーテリングのあらゆる側面を再構築し始め、エンターテイメントの風景を変え始めたとき
 5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AM
5日間のISRO AI無料コースを登録する方法は? - 分析VidhyaApr 16, 2025 am 11:43 AMISROの無料AI/MLオンラインコース:地理空間技術の革新へのゲートウェイ インド宇宙研究機関(ISRO)は、インドのリモートセンシング研究所(IIRS)を通じて、学生と専門家に素晴らしい機会を提供しています。
 AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AM
AIのローカル検索アルゴリズムApr 16, 2025 am 11:40 AMローカル検索アルゴリズム:包括的なガイド 大規模なイベントを計画するには、効率的なワークロード分布が必要です。 従来のアプローチが失敗すると、ローカル検索アルゴリズムは強力なソリューションを提供します。 この記事では、Hill ClimbingとSimulについて説明します
 OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AM
OpenaiはGPT-4.1でフォーカスをシフトし、コーディングとコスト効率を優先しますApr 16, 2025 am 11:37 AMこのリリースには、GPT-4.1、GPT-4.1 MINI、およびGPT-4.1 NANOの3つの異なるモデルが含まれており、大規模な言語モデルのランドスケープ内のタスク固有の最適化への動きを示しています。これらのモデルは、ようなユーザー向けインターフェイスをすぐに置き換えません
 プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AM
プロンプト:ChatGptは偽のパスポートを生成しますApr 16, 2025 am 11:35 AMChip Giant Nvidiaは、月曜日に、AI Supercomputersの製造を開始すると述べました。これは、大量のデータを処理して複雑なアルゴリズムを実行できるマシンを初めて初めて米国内で実行します。発表は、トランプSI大統領の後に行われます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

