
ホームページ >バックエンド開発 >Python チュートリアル >ヒント | Python は PDF 請求書をバッチで自動的に抽出して整理します
ヒント | Python は PDF 請求書をバッチで自動的に抽出して整理します

- Python当打之年転載
- 2023-08-10 15:58:202223ブラウズ
要件の説明
特定のフォルダーに複数の PDF 形式の請求書が存在します
純粋な画像 タイプであり、以下に示すように、内部のテキスト情報を手動でコピーすることはできません (実際、ほとんどの請求書はテキストの一部をコピーできますが、ここでは画像の形式で説明します)。 : 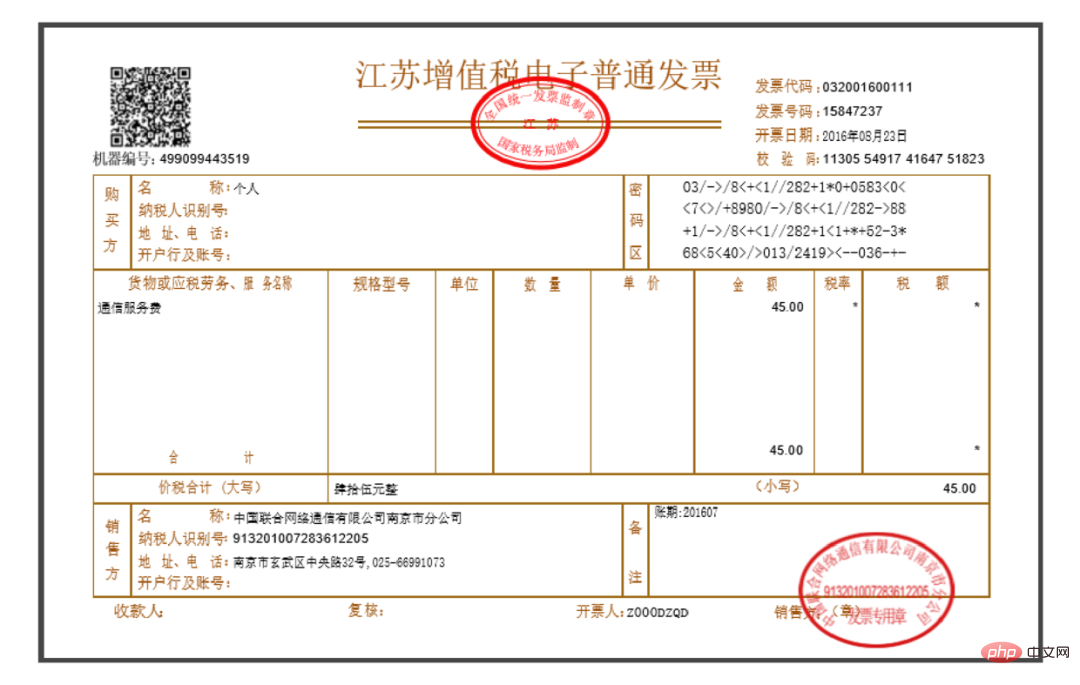
、納税者番号、および発行者 の合計金額、つまり次の 3 つのボックスの位置を取得することです。  最後にバッチ操作と組み合わせ、上記の情報を取得したらExcelに保存します。
最後にバッチ操作と組み合わせ、上記の情報を取得したらExcelに保存します。
PDF の内容は次のとおりであるため、要件の本質は画像認識の問題です。画像タイプなので押せません 従来の方法ではテキストを直接抽出していました。解決策は、光学式文字認識 (OCR) を使用して画像内のテキストを認識することです。ただし、同時に、PDF は結局のところ画像ではないことに注意する必要があります。OCR を完了するには、OCR 自体に加えて、
Ghostscript と ImageMagick をダウンロードする必要があります。完全な型変換。 Windows システムを例に挙げると、次の 3 つのソフトウェアをコンピュータにインストールする必要があります。
ゴーストスクリプト32 ビットImageMagick32 ビット-
tesseract-OCR32 ビット
3 つのソフトウェアをダウンロードしてインストールするための特別な場所はありません (tesseract の設定は少し複雑ですが、多くのソフトウェアがあります)チュートリアルはインターネット上にあるので、ここでは詳しく説明しません。)、読者は自分でダウンロードと設定を検索できます。コードは以下で説明されています。まず必要なモジュールをインポートします。
from wand.image import Image from PIL import Image as PI import pyocr import pyocr.builders import io import re import os import shutil
特定のモジュールの使用については、以下の特定のコードを参照してください。このうち、wand と pyocr は非標準ライブラリのため、別途インストールする必要があります。コマンド ラインを開いて次のように入力します:
pip install wand pip install pyocr
この要件には Excel のドッキングも含まれます。openpyxl ライブラリの Workbook を使用して新しい Excel ファイルを作成することを検討できます。
from openpyxl import Workbook
要件にある invoice.pdf をデスクトップに配置します。デスクトップ パスは、os モジュールに基づく次のコードを通じて取得できます:
# 获取桌面路径包装成一个函数
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
path = GetDesktopPath() + r'\发票.pdf'後で呼び出すために構成された tesseract を取得します:
tool = pyocr.get_available_tools()[0]
通过 wand 模块将 PDF 文件转化为分辨率为 300 的 jpeg 图片形式:
image_pdf = Image(filename=path, resolution=300) image_jpeg = image_pdf.convert('jpeg')
将图片解析为二进制矩阵:
image_lst = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
image_lst.append(img_page.make_blob('jpeg'))用 io 模块的 BytesIO 方法读取二进制内容为图片形式:
new_img = PI.open(io.BytesIO(image_lst[0])) new_img.show()
接下来分别截取需要提取部位字符串的图片了,尽量让图片中只有需要识别的部分,获取识别出来容易简单处理获得需要的内容。
首先以总金额为例,截取图片用 image.crop((left, top, right, bottom)) 四个参数需要反复调试才能确定。经确定四个参数分别是 1600 760 1830 900,尝试截取和预览图片:
### 解析1Z开头码 left = 350 top = 600 right = 1300 bottom = 730 image_obj1 = new_img.crop((left, top, right, bottom)) image_obj1.show()
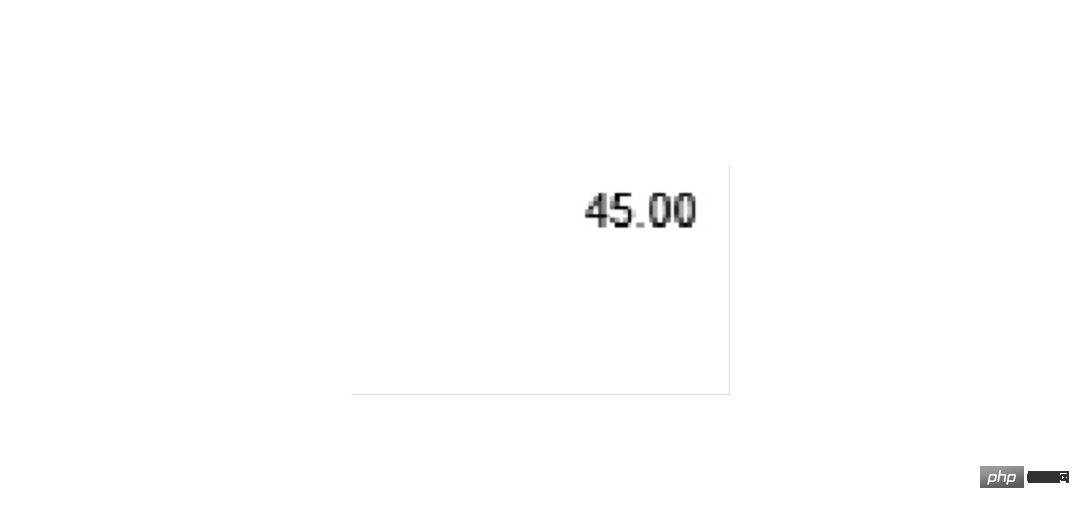
截取成功后可以交给 OCR 了,代码为 tool.image_to_string()
txt1= tool.image_to_string(image_obj1) print(txt1)

同样,通过方位的调试就可以准确切割到需要的部分进行识别:
left = 560 top = 1260 right = 900 bottom = 1320 image_obj2 = new_img.crop((left, top, right, bottom)) # image_obj2.show() txt2 = tool.image_to_string(image_obj2) # print(txt2)
最后是开票人的识别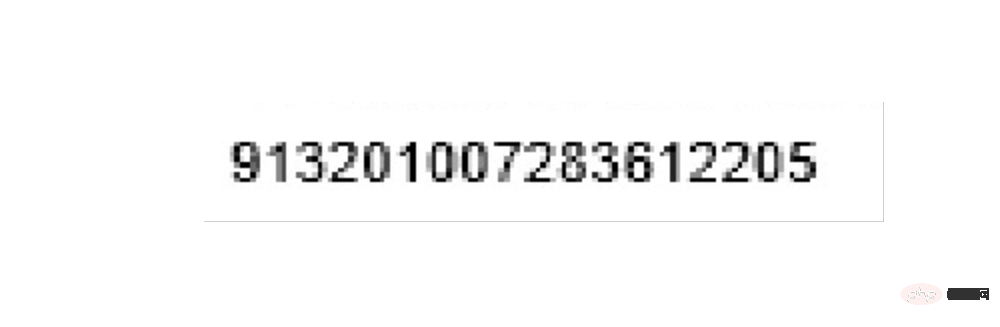
left = 1420 top = 1420 right = 1700 bottom = 1500 image_obj3 = new_img.crop((left, top, right, bottom)) # image_obj3.show() txt3 = tool.image_to_string(image_obj3) # print(txt3)
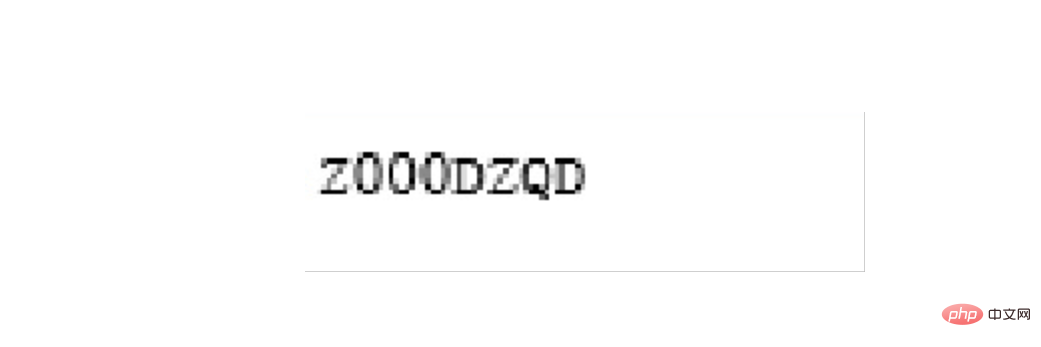
需要确认识别的内容是否正确,如果识别正确率欠佳可以考虑通过图片处理技术消除噪声,也可以去官网下载更高精度的训练包提高识别的正确性
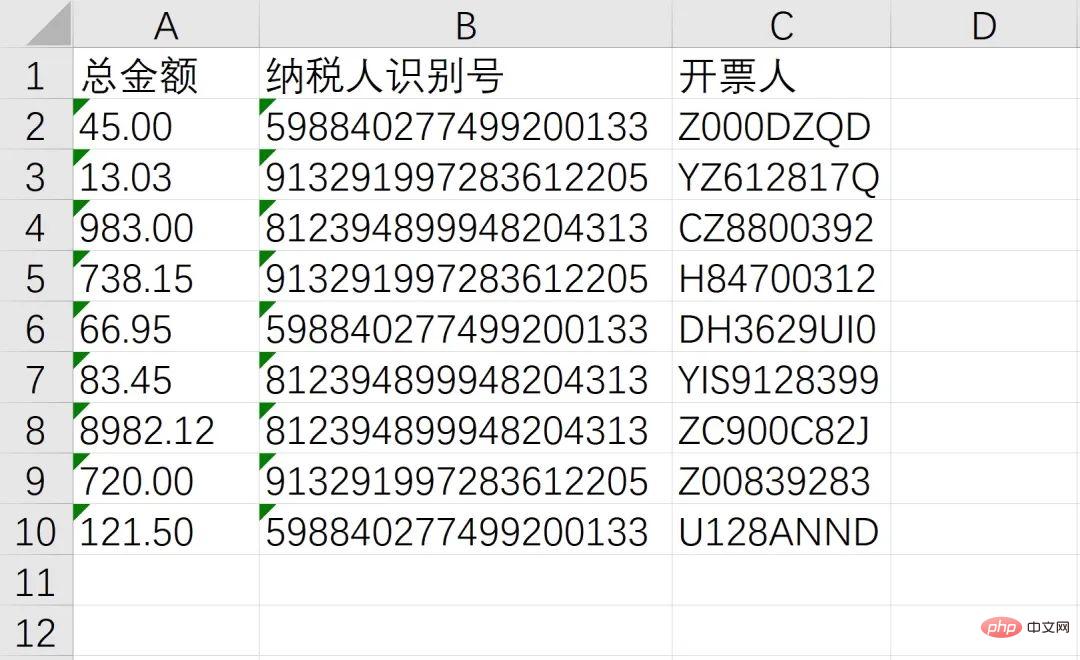
至此,我们成功的识别了总金额、纳税人识别号、开票人三个消息,接下来就通过非常熟悉的 openpyxl 写入Excel,并使用 os 模块实现批量操作即可
workbook = Workbook() sheet = workbook.active header = ['总金额', '纳税人识别号', '开票人'] sheet.append(header) sheet.append([txt1, txt2, txt3]) workbook.save(GetDesktopPath() + r'\汇总.xlsx')
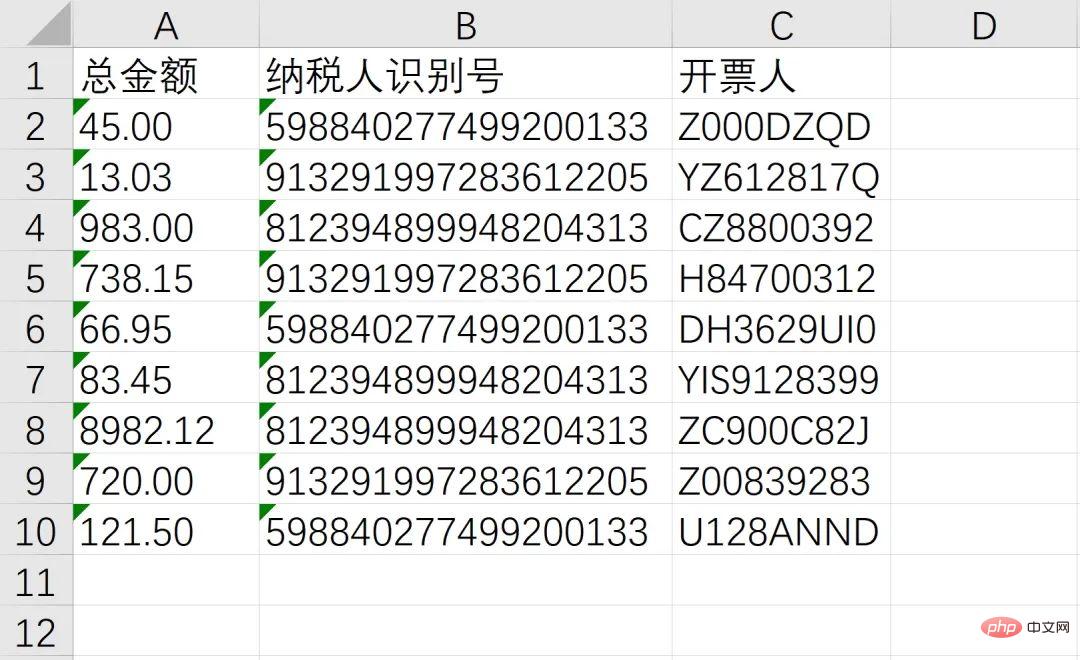
综上,整个需求就成功实现,从效果来看还是非常不错的!完整源码可由文中代码组合而成(已全部分享在文中),感兴趣的读者可以自己尝试!
最后想说的是,其实本文的案例可以衍生出很多实用的办公自动化脚本,例如
批量计算发票金额并重命名文件夹 根据发票类型批量分类 根据发票批量制作报销单 ··· ···
以上がヒント | Python は PDF 請求書をバッチで自動的に抽出して整理しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。