
ホームページ >バックエンド開発 >Python チュートリアル >Python Web クローラーを使用して、King of Glory ヒーローの装備説明書を取得し、マークダウン ファイルを自動的に生成する方法を段階的に説明します。
Python Web クローラーを使用して、King of Glory ヒーローの装備説明書を取得し、マークダウン ファイルを自動的に生成する方法を段階的に説明します。
- Go语言进阶学习転載
- 2023-07-24 14:55:561072ブラウズ
#1. はじめに
友達ごっこHonor of Kings ゲームをプレイする人は皆、ヒーローの装備が非常に重要であることを知っています。適切な装備と碑文を組み合わせることで、King の戦場であなたを止められないほど強力にすることができます。
数日前、私は彼が [Minglao] グループで Python Web クローラーを共有して、キング オブ グローリー ヒーローの装備の説明書を入手し、スレッド プールを使用して装備の写真をダウンロードしているのを見かけました。 Markdown ファイルには便利なコンテンツがたくさんありますので、ここで共有しますので、ぜひ試してみてください。
2. データの取得
ここでの対象 Web サイトは、下図に示す King of Glory の公式 Web サイトです。 
次に、ホームページの右側にある [ヒーロー/スキン] の [詳細] ボタンをクリックして、下図に示す詳細ページに入り、 [ゲーム内プロップ] をクリックして、出力を参照してください。情報がインストールされています。これには、必要なターゲット情報が含まれています。 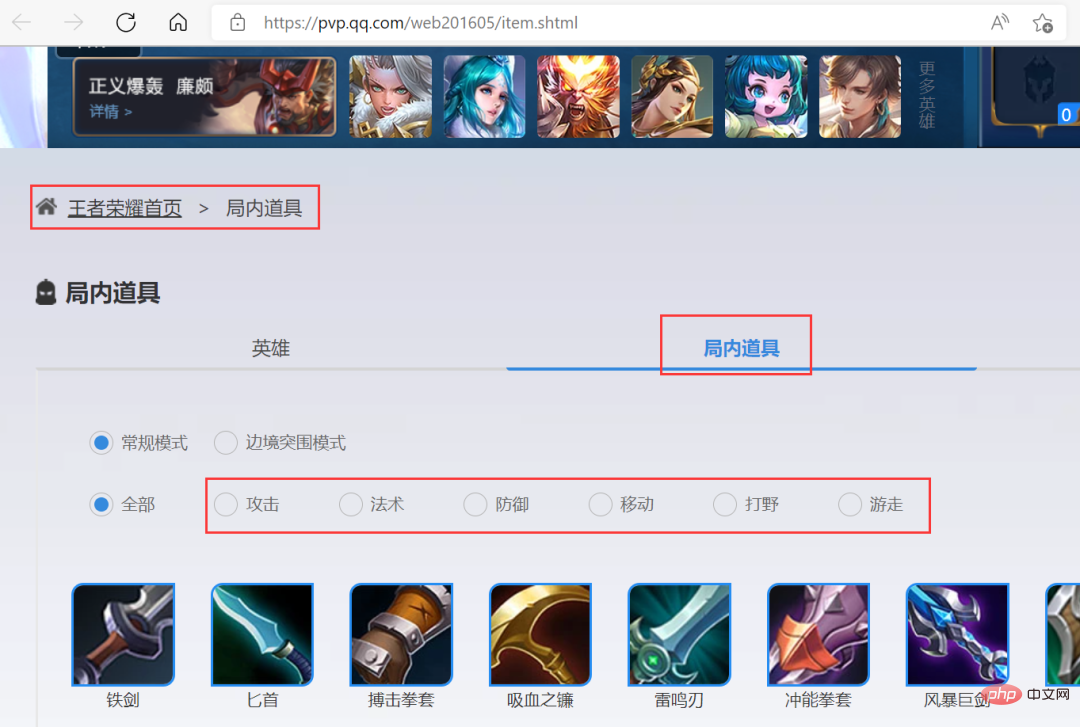
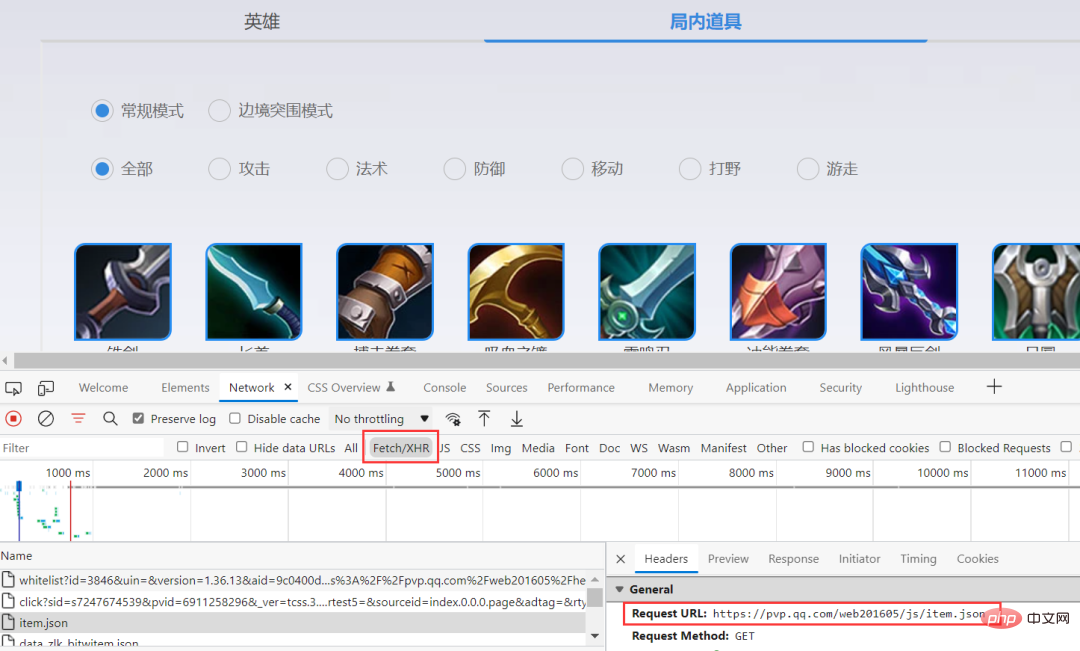
ブラウザを通じてパケットをキャプチャすると、json 形式で保存された特定の情報を取得できます。
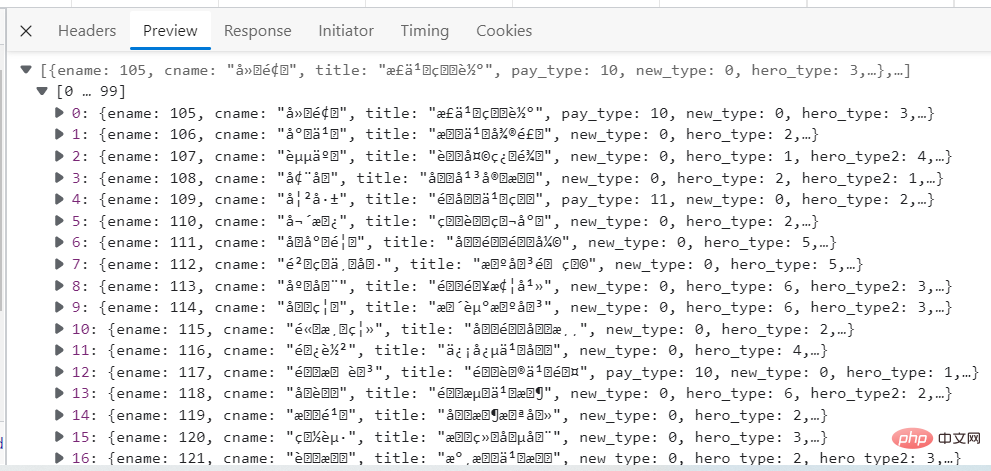
 下の画像はデータ詳細のスクリーンショットです。中国語の文字化けが確認できますが、影響はありません。少なくともデータは取得できます。
下の画像はデータ詳細のスクリーンショットです。中国語の文字化けが確認できますが、影響はありません。少なくともデータは取得できます。
コード実装プロセス
データ ソースを見つけたら、次のステップはコードを実装することです。ここでは [Minglao] コードが直接適用されており、jupyter Notebook で実行されています。
設備データの取得
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36 '
}
target = 'https://pvp.qq.com/web201605/js/item.json'
item_list = requests.get(target, headers=headers).json()
item_df = pd.DataFrame(item_list)
item_df.sort_values(["item_type", "price", "item_id"], inplace=True)
item_df.fillna("", inplace=True)
item_df.des1 = item_df.des1.str.replace("</?p>", "", regex=True)
item_df.des2 = item_df.des2.str.replace("</?p>", "", regex=True)
item_df結果は以下のようになります:
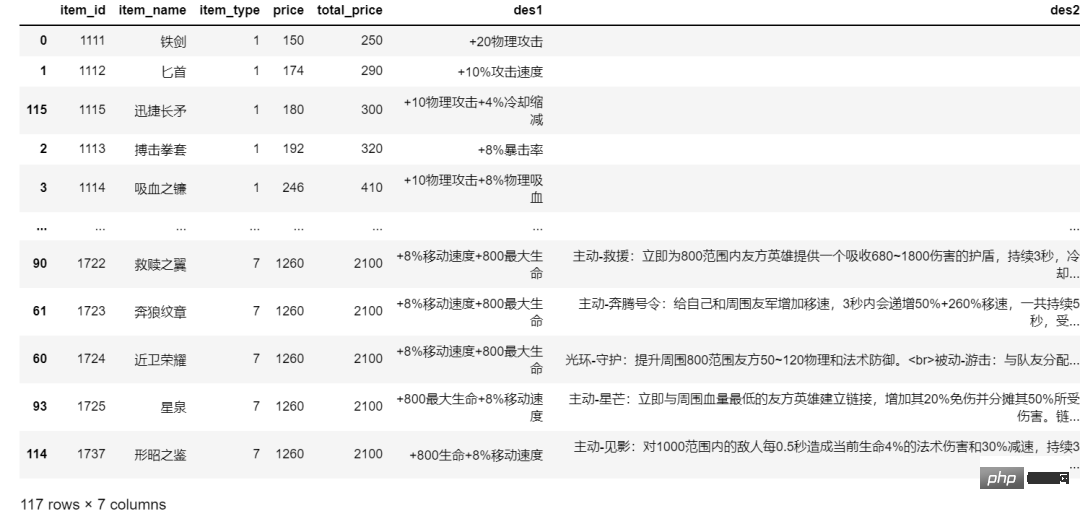
##次に、スレッドプール方式で画像をダウンロードします。画像の結合方法も非常に簡単です。一目でわかります。下の写真を見てください。
#コードの実装は次のとおりです:
import os
from concurrent.futures import ThreadPoolExecutor
def download_img(item_id):
if os.path.exists(f"imgs/{item_id}.jpg"):
return
imgurl = f"http://game.gtimg.cn/images/yxzj/img201606/itemimg/{item_id}.jpg"
res = requests.get(imgurl)
with open(f"imgs/{item_id}.jpg", "wb") as f:
f.write(res.content)
os.makedirs("imgs", exist_ok=True)
with ThreadPoolExecutor(max_workers=8) as executor:
nums = executor.map(download_img, item_df.item_id)ダウンロード速度は非常に速く、わずか数秒です。結果は次の図に示されています。 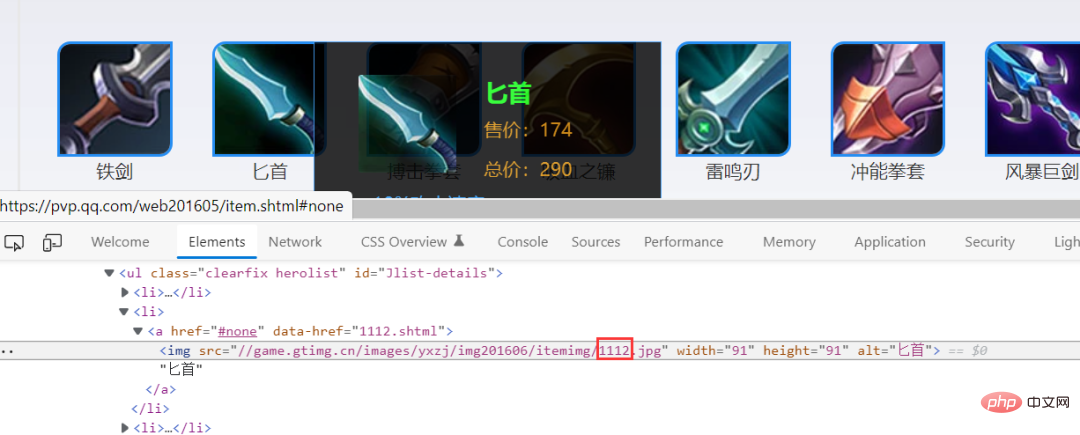
item_type_dict = {1: '攻击', 2: '法术', 3: '防御', 4: '移动', 5: '打野', 7: '游走'}
item_ids = item_df.item_id.values
item_df.item_id = item_df.item_id.apply(
lambda item_id: f"")
item_df.item_type = item_df.item_type.map(item_type_dict)
item_df.columns = ["图片", "装备名称", "类型", "售价", "总价", "基础描述", "扩展描述"]
item_df
コードをファイルに書き込み、Markdown ドキュメントを生成します: with open("王者装备说明.md", "w") as f:
for item_type, item_split in item_df.groupby("类型", sort=False):
f.write(f"# {item_type}\n")
item_split.drop(columns="类型", inplace=True)
f.write(item_split.to_markdown(index=False))
f.write("\n\n")結果は以下のようになります:
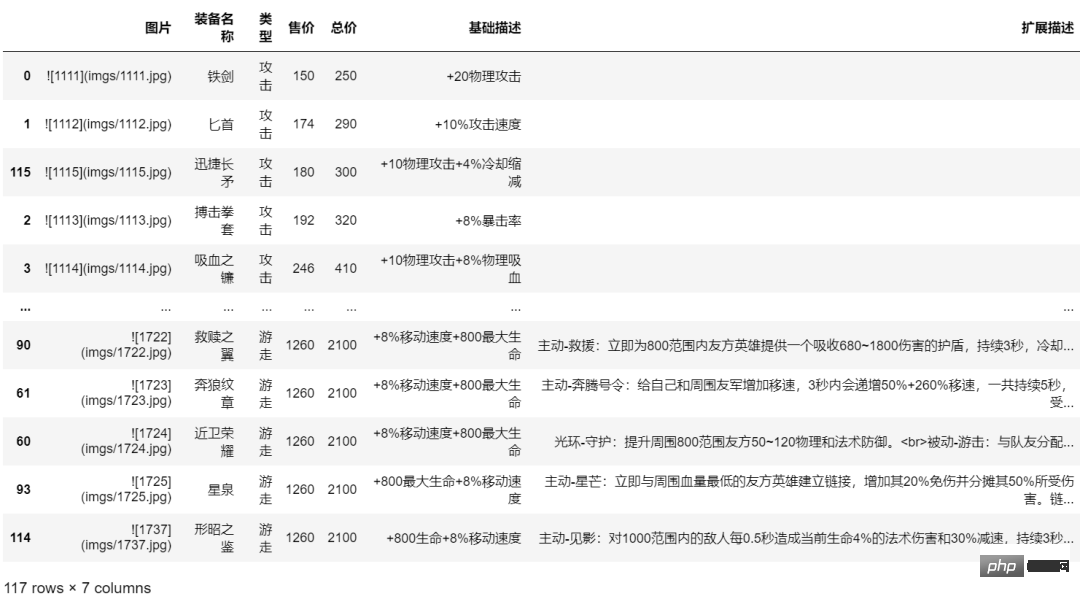
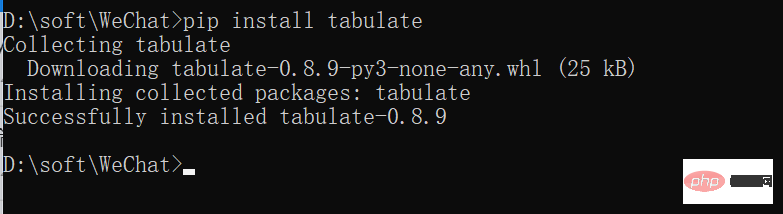
Missing optional dependency 'tabulate'. Use pip or conda to install tabulate.
提示却少依赖库,只需要在cmd下进行安装即可pip install tabulate,之后就可以正常运行了。
生成Excel表格
不过Markdown的表格无法任意调整,图片需要点击后才会放大,下面我们考虑生成Excel表格:首先需要整理数据,代码如下:
item_df.图片 = ""
item_df.基础描述 = item_df.基础描述.str.replace("<br>", "\n")
item_df.扩展描述 = item_df.扩展描述.str.replace("<br>", "\n")
item_df生成结果如下图所示:
 之后将结果写入到
之后将结果写入到Excel中去,代码如下所示:
# 写入Excel表格
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
with pd.ExcelWriter("王者装备说明.xlsx", engine='openpyxl') as writer:
item_df.to_excel(writer, sheet_name='装备说明', index=False)
worksheet = writer.sheets['装备说明']
worksheet.column_dimensions["A"].width = 11
for item_id, (cell,) in zip(item_ids, worksheet.iter_rows(2, None, 1, 1)):
worksheet.row_dimensions[cell.row].height = 67
worksheet.add_image(Image(f"imgs/{item_id}.jpg"), f'A{cell.row}')
worksheet.column_dimensions["F"].width = 15
worksheet.column_dimensions["G"].width = 35
writer.save()打开文件,效果图如下图所示:

当然了,大家也可以根据自己想要的效果生成HTML和Word等等。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个使用Python网络爬虫获取王者荣耀英雄出装说明,并使用线程池的方式下载了出装图片,之后还自动化生成了markdown文件,干货内容很多,欢迎大家积极尝试,如果有遇到问题,请添加我好友,我帮助解决。
最后感谢粉丝【明佬】分享的代码喝王者荣耀出装攻略,真是太强了,上王者指日可待!
最后放上【明佬】的csdn链接:https://xxmdmst.blog.csdn.net/article/details/124035041,点击阅读原文可以直达噢!
以上がPython Web クローラーを使用して、King of Glory ヒーローの装備説明書を取得し、マークダウン ファイルを自動的に生成する方法を段階的に説明します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。