
Python Web クローラーを使用してファンド情報を取得する方法を段階的に説明します。
- Go语言进阶学习転載
- 2023-07-24 14:53:20893ブラウズ
1. はじめに
最初のいくつかの A先日ファンの方がファンド情報を聞きに来てくれたのでここで共有したいと思います、興味のあるお友達も積極的に試してみてください。
2. データ取得
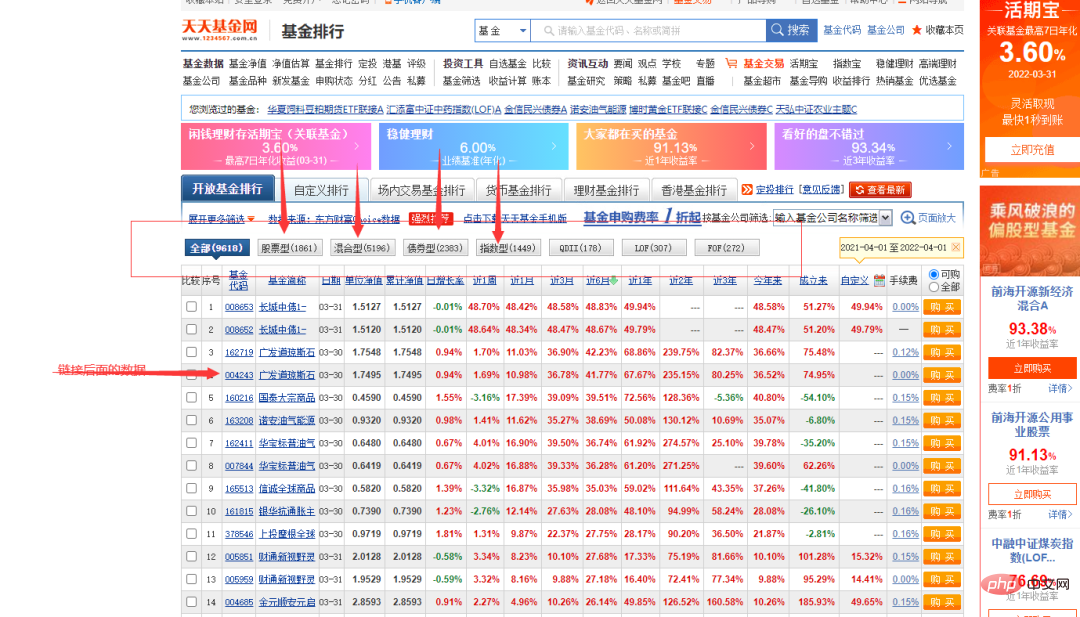
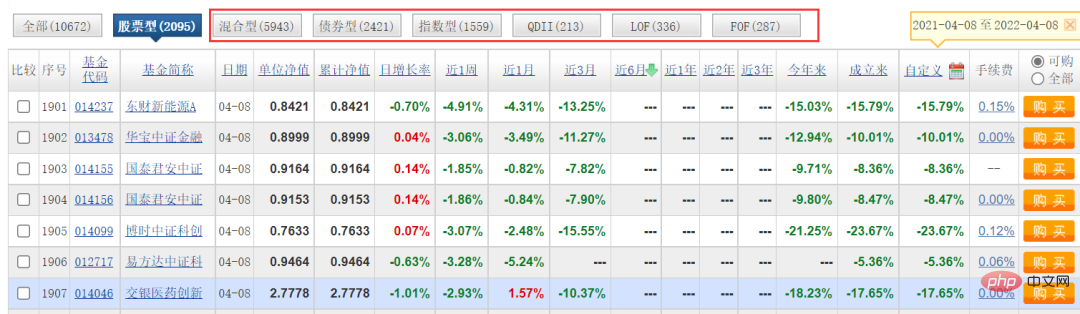
今回の対象となるWebサイトは、某ファンドの公式Webサイトです。クロールする必要があるデータは次の図に示されています。
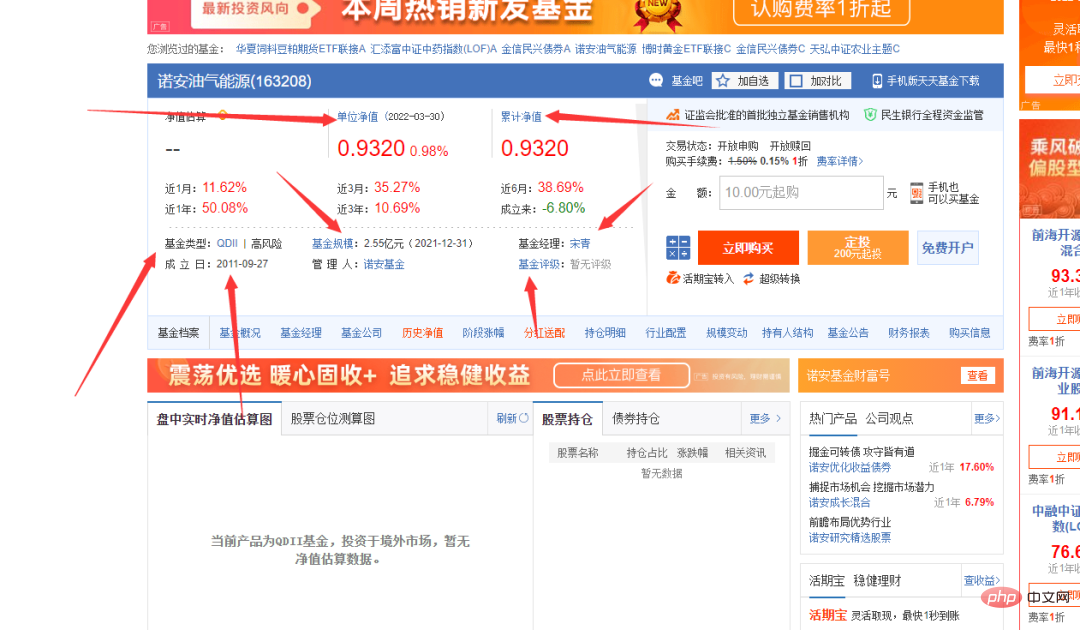 上の図では、ファンド コードの列にさまざまな番号が付いていることがわかります。ランダムに 1 つをクリックすると、ファンドの詳細ページにアクセスできます。リンクも非常に規則的で、ファンド コードがシンボルになっています。 。
上の図では、ファンド コードの列にさまざまな番号が付いていることがわかります。ランダムに 1 つをクリックすると、ファンドの詳細ページにアクセスできます。リンクも非常に規則的で、ファンド コードがシンボルになっています。 。
実は、この Web サイトは難しいものではありません。データは暗号化されておらず、Web ページ上の情報はソース コードで直接見ることができます。 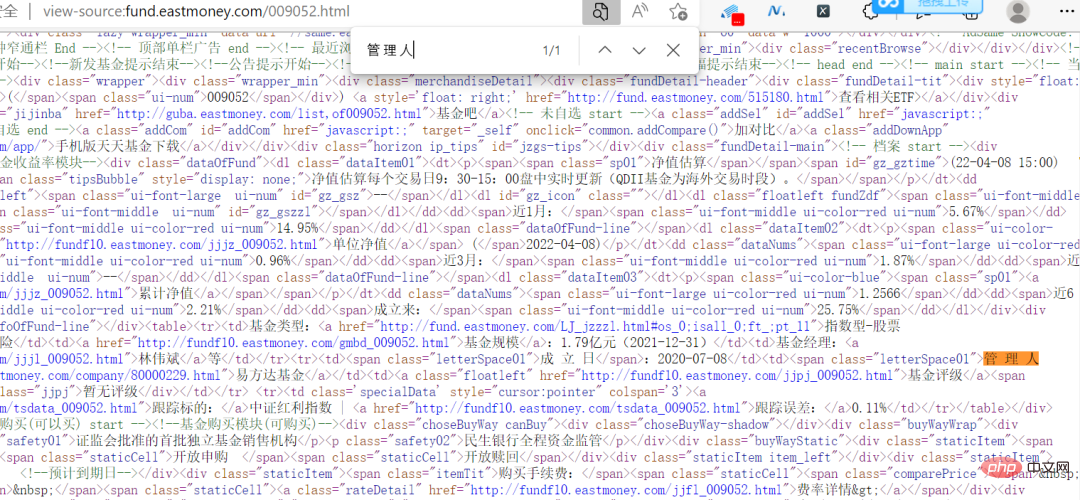
これにより、クロールの困難さが軽減されます。ブラウザーのパケット キャプチャ メソッドを通じて、特定のリクエスト パラメーターを確認できます。リクエスト パラメーター内で pi のみが変更されていることがわかります。この値はたまたまページに対応しているため、直接構築できます。リクエストパラメータ。 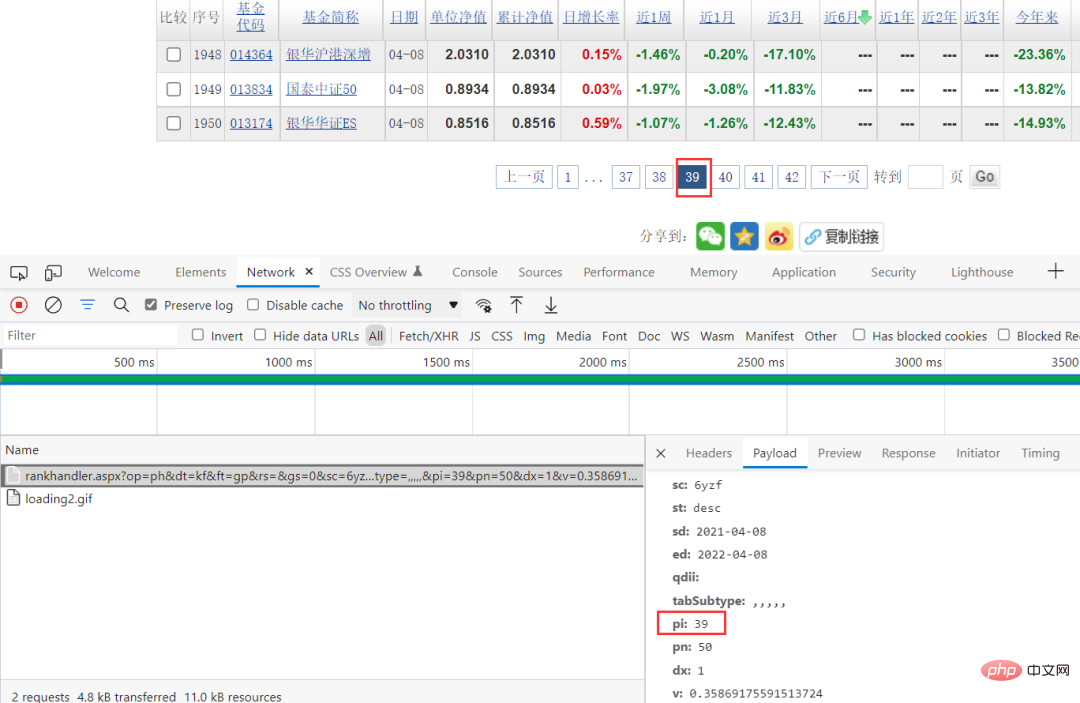
コード実装プロセス
データ ソースを見つけたら、次のステップはコードを実装することです。いくつかのキーコードを出力します。
株式 ID データを取得します
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
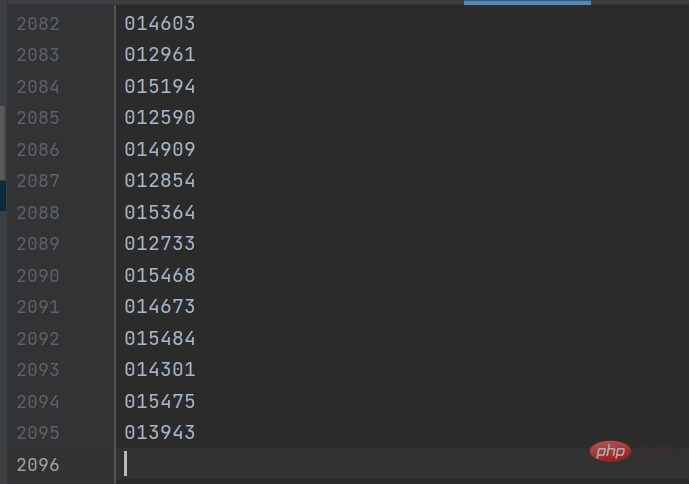
gp_id = item.group('items').split(',')[0]結果は以下のようになります:
詳細ページのファンド情報を取得するための詳細ページリンクが後で作成されます。キーコードは次のとおりです。
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
結果は次の図に示すとおりです。特定の情報を対応する文字列に処理し、
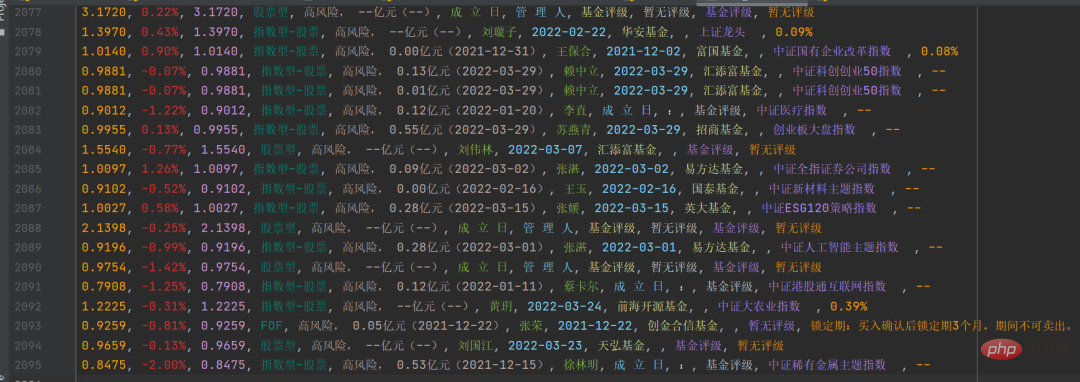
csv ファイルに保存すると、結果は次のようになります。 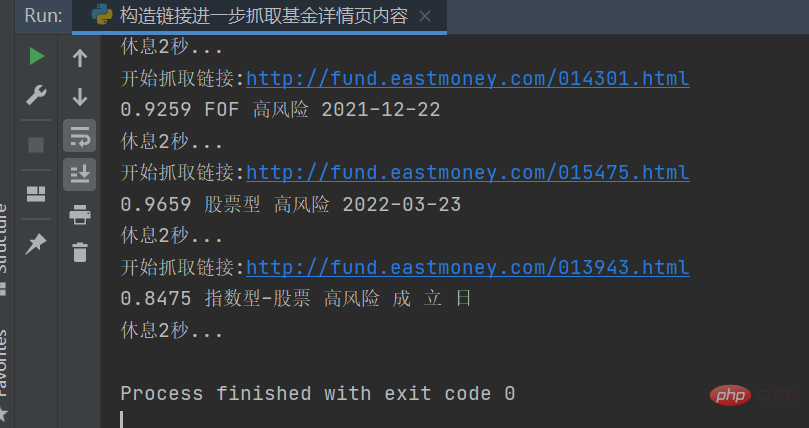
これにより、さらに統計とデータ分析を行うことができます。
この記事は主に [ストック タイプ] の分類に基づいています。他のタイプはやったことがありません。ぜひ試してみてください。実際、ロジックは同じで、パラメーターを変更するだけです。
以上がPython Web クローラーを使用してファンド情報を取得する方法を段階的に説明します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。