
コンピュータのビットに関する問題を Go 言語の観点から分析する
- Go语言进阶学习転載
- 2023-07-21 11:52:271263ブラウズ
コードの一部
今回は Go 言語を例に説明します。Go 言語は C に似た言語であり、基礎となる層は非常によく似ています。
#コード
package main
import (
"fmt"
"unsafe"
)
func main() {
//定义一个 字符a
var a = 'a'
//定义一个 正 整数3
var b uint8 = 3
var c uint8 = 98
fmt.Printf("值:%c,十进制:%d,类型:%T,二进制:%b,大小%v字节\n", a, a, a, a, unsafe.Sizeof(a)) // 4个字节
fmt.Printf("值%d,十进制:%d,类型:%T,二进制%b,大小%v字节\n", b, b, b, b, unsafe.Sizeof(b)) //一个字节
fmt.Printf("值%c,十进制,%d,类型:%T,二进制%b,大小%v字节\n", c, c, c, c,unsafe.Sizeof(c)) //一个字节
}実行結果

#いくつか質問があります
##変数に名前を付けるとき文字 a は、なぜ 10 進数では 97、2 進数では
1100001 なのでしょうか? 変数 c の名前は 98 ですが、b は出力できるのはなぜですか?
ビットとバイト
上記の問題を理解するには、本質的な問題を理解する必要があります。
私たちのプログラムは結局のところメモリ内で実行されます。
そして、メモリモジュールはおそらく次のようになります。
#メモリースティックの本質は、各 電子コンポーネント、結局のところ、状態は 2 つだけです。、電源オン (1)、電源オンなし (0)## #####。 #bit
a
電子部品、それはちょっと。 #バイト
および
単語 セクション
#、8 ビット #、1 バイト = 8 ビット に等しい。
1 ビットは 0 または 1 は バイナリ #、 は 0 または 1 です。
#1 バイトは 8 つの 0 または 1 # のようになります。 #00000000,表示される 0 または 1 が 8 個未満の場合は、先頭の 0 をすべて 0 で埋めて 8 桁にします 。
言語はバイト 上でのみ動作し、その場で動作することはほとんどありません。 #なぜ a が 97 であるのか
上記のことはわかっていますが、
# ビット は、 電源が入っている または 電源が入っていない # を意味します。 #####電子部品#########。 1 バイト # は、8 乗 または ## を表します。 # は、電源が入っていない 電子コンポーネントの組み合わせです。 しかし、これでは実際の問題は解決されません。10 を保存し、20 を足して足し算をしたいのですが、どうすればよいでしょうか? ? ? つまり、このとき、点灯しているか点灯していない方が何を意味するかというルールがあるはずです。 つまり、 ASCII というものがあります。この仕様の最小単位はバイト、つまり # です。 00000000 です。 ## など、ビットはバイトごとに編成されており、各 8 ビットは異なります記号、数字、文字などの組み合わせ。 特定のバイナリ対応記号または数字:https://baike.baidu.com/item/ASCII/309296?fromtitle=ASCII エンコード&fromid =3712529&fr =aladdin ASCII 文字 a のバイナリ バージョンは 0110 0001 それでは、まず始めに見てみましょう! なぜ 98 は b を出力できるのでしょうか? 出力方法が違うだけです。 実際には、すべて 1 バイト、8 ビットです。ライトをつけます。#11111111 しかし、現在ではコンピューターはすでに大木となり、中国も使用し、日本も使用し、棒も使用しており、各国の文字数の合計は 255 文字という単純なものではなくなりました。 そのため、中国の #ASCII #GBK は他のエンコーディングと互換性がないため、現在は この記事は主にコンピュータの性質を理解することを目的としています。 #1 バイト = 8 ビット ##8 つの 0 または 1 を同時に管理##。 たとえば、1 バイト目は最初の 8 桁で、すべて 0 の場合は 10 進数の 0 を意味します。 は、端から数えて、端が点灯し、他の 7 つが点灯していない場合は、10 進数の 1 を意味することも規定しています。 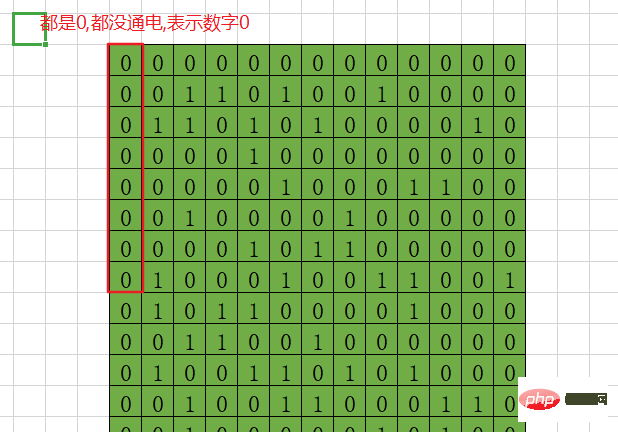
00000001
をクエリすることで知ることができます。 、10 進バージョンは 97 、表されるシンボルは a です。 
ASCII 98 は文字 b を表すためです。これはバイナリ 0110 0010 です。 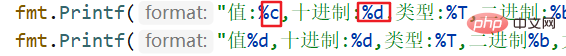
#現在のエンコード方向
です。その 10 進数値は 255 です。 , 理論上は255個のシンボルをサポートできると言われています。 GBK のようないくつかのコードが派生し、さまざまなコードが ## に基づいています。 #ASCII拡張。 は 1 バイト、8 ビットを占有し、その後 IGBK これでは十分ではありません。中国語の文字は数万個あります。つまり、2 バイト、16 ビット、16 個の 0 または 1 があれば十分です。そうでない場合は、3 バイト、24 個の 0 または 1、3 バイトで十分です。 10 進法は 16777215 に達しており、これはさまざまな国の記号や文字を保存するのに十分な数千万です。 #ただし、## から派生しています。 #utf-8 などのコードには、さまざまな国のコードが含まれています。 <p cid="n59" mdtype="paragraph" style="box-sizing: border-box;line-height: inherit;orphans: 4;margin-top: 0.8em;margin-bottom: 0.8em;white-space: pre-wrap;font-family: 'Open Sans', 'Clear Sans', 'Helvetica Neue', Helvetica, Arial, sans-serif;font-size: 16px;text-align: start;"><span md-inline="plain" style="box-sizing: border-box;">現在</span><span md-inline="code" spellcheck="false" style="box-sizing: border-box;"><code style="box-sizing: border-box;font-family: var(--monospace);vertical-align: initial;border-width: 1px;border-style: solid;border-color: rgb(231, 234, 237);background-color: rgb(243, 244, 244);border-radius: 3px;padding-right: 2px;padding-left: 2px;font-size: 0.9em;">utf-8は最良のエンコーディングであり、基本的にすべてのコンピュータでサポートされています。 #概要
#,1 ビット = 電力が供給されているまたは供給されていない電子コンポーネント 、異なるシンボルは異なる 00101010 で表されます。
以上がコンピュータのビットに関する問題を Go 言語の観点から分析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。