
ホームページ >テクノロジー周辺機器 >AI >アルパカファミリーの大型モデルが一斉に進化! 32k コンテキストは GPT-4 に相当し、Tian Yuandong のチームによって作成されました
アルパカファミリーの大型モデルが一斉に進化! 32k コンテキストは GPT-4 に相当し、Tian Yuandong のチームによって作成されました

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-28 22:06:521833ブラウズ
オープンソース アルパカ ラージ モデル LLaMA コンテキストは GPT-4 と同等ですが、簡単な変更が 1 つだけあります。
Meta AI によって提出されたばかりのこの論文は、LLaMA コンテキスト ウィンドウが 2k から 32k に拡張された後、必要な微調整ステップは 1000 未満のみであることを示しています。
コストは、事前トレーニングに比べてごくわずかです。

コンテキスト ウィンドウを拡大するということは、AI の「作業記憶」容量が増加することを意味します。具体的には、次のことが可能になります。
- より多くの対話をサポートします。 、より安定したロールプレイングなど、忘れ物を減らします。
- 長い文書や複数の文書を一度に処理するなど、より複雑なタスクを完了するには、より多くの情報を入力します。
さらに重要な意味問題は、LLaMA に基づくすべての大規模なアルパカ モデル ファミリがこの方法を低コストで採用し、集合的に進化できるかということです。
Yangtuo は現在最も包括的なオープンソースの基本モデルであり、完全にオープンソースの商用利用可能な大規模モデルや垂直産業モデルを多数派生させています。
# この論文の責任著者である Tian Yuandong 氏も、友人の輪の中でこの新たな展開を興奮して共有しました。
RoPE に基づく大規模モデルは
新しい方法は位置補間 (Position Interpolation) と呼ばれ、RoPE を使用する大規模モデルに適しています (回転位置エンコーディング)全モデルに適用。
RoPE は、2021 年には Zhuiyi Technology チームによって提案され、現在では大規模モデルで最も一般的な位置エンコード方式の 1 つになりました。

しかし、このアーキテクチャ下で外挿を直接使用してコンテキスト ウィンドウを拡張すると、セルフ アテンション メカニズムが完全に破壊されます。
具体的には、事前トレーニングされたコンテキストの長さを超える部分により、モデルの複雑さがトレーニングされていないモデルと同じレベルまで上昇します。
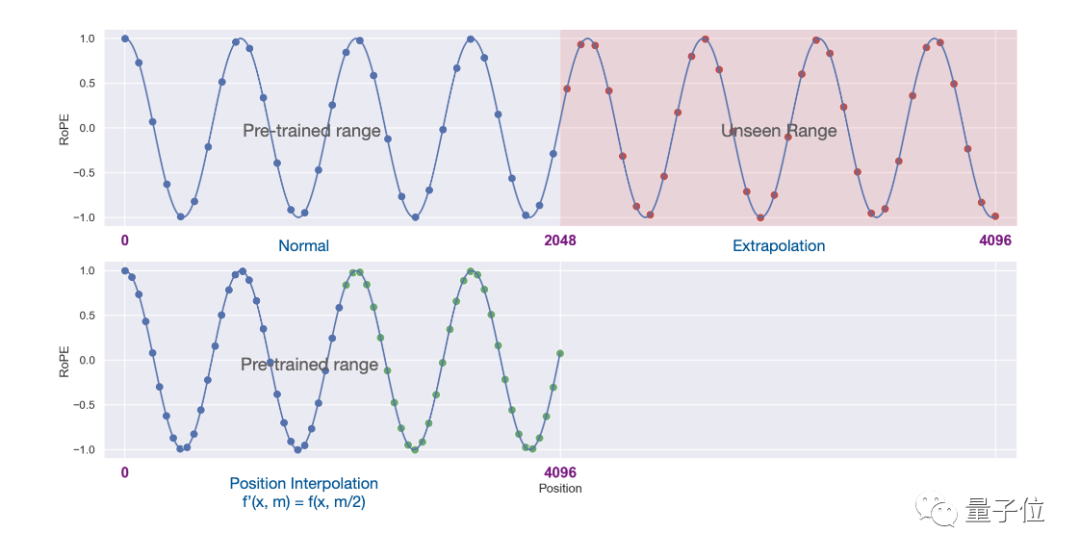
新しい方法は、位置インデックスを線形に減少させ、前後の位置インデックスと相対距離の範囲の調整を拡大するように変更されました。

# 2 つの違いを表現するには、画像を使用する方が直感的です。
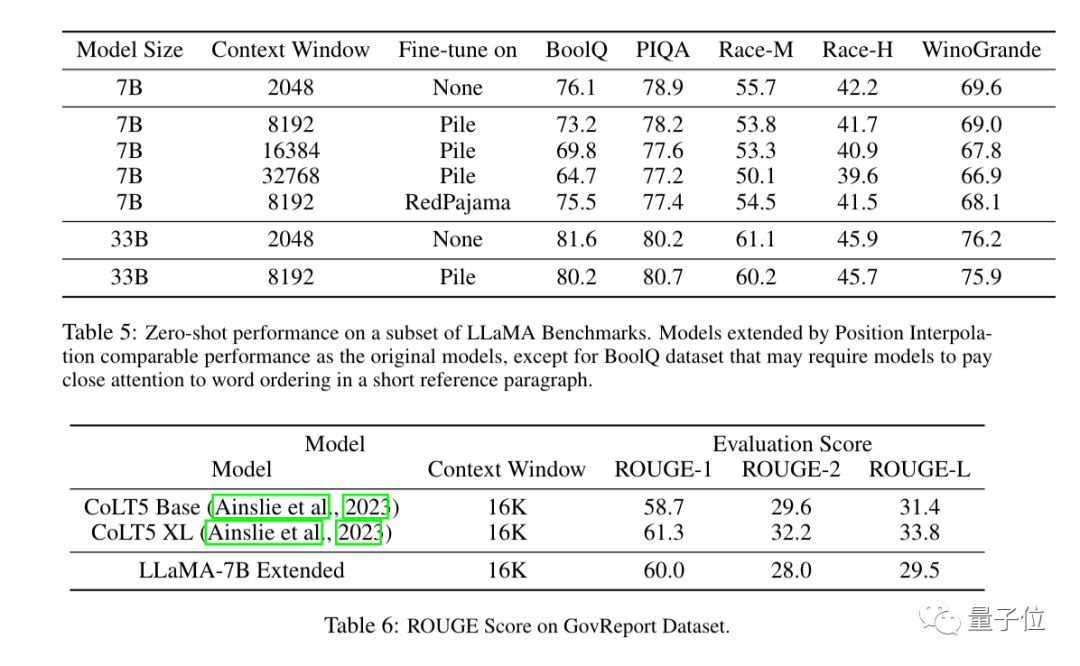
実験結果は、新しい方法が 7B から 65B までの LLaMA 大型モデルに有効であることを示しています。
ロング シーケンス言語モデリング、パスキーの取得、および長いドキュメントの要約では、大幅なパフォーマンスの低下はありません。
#実験に加えて、新しい方法の詳細な証明も論文の付録に記載されています。
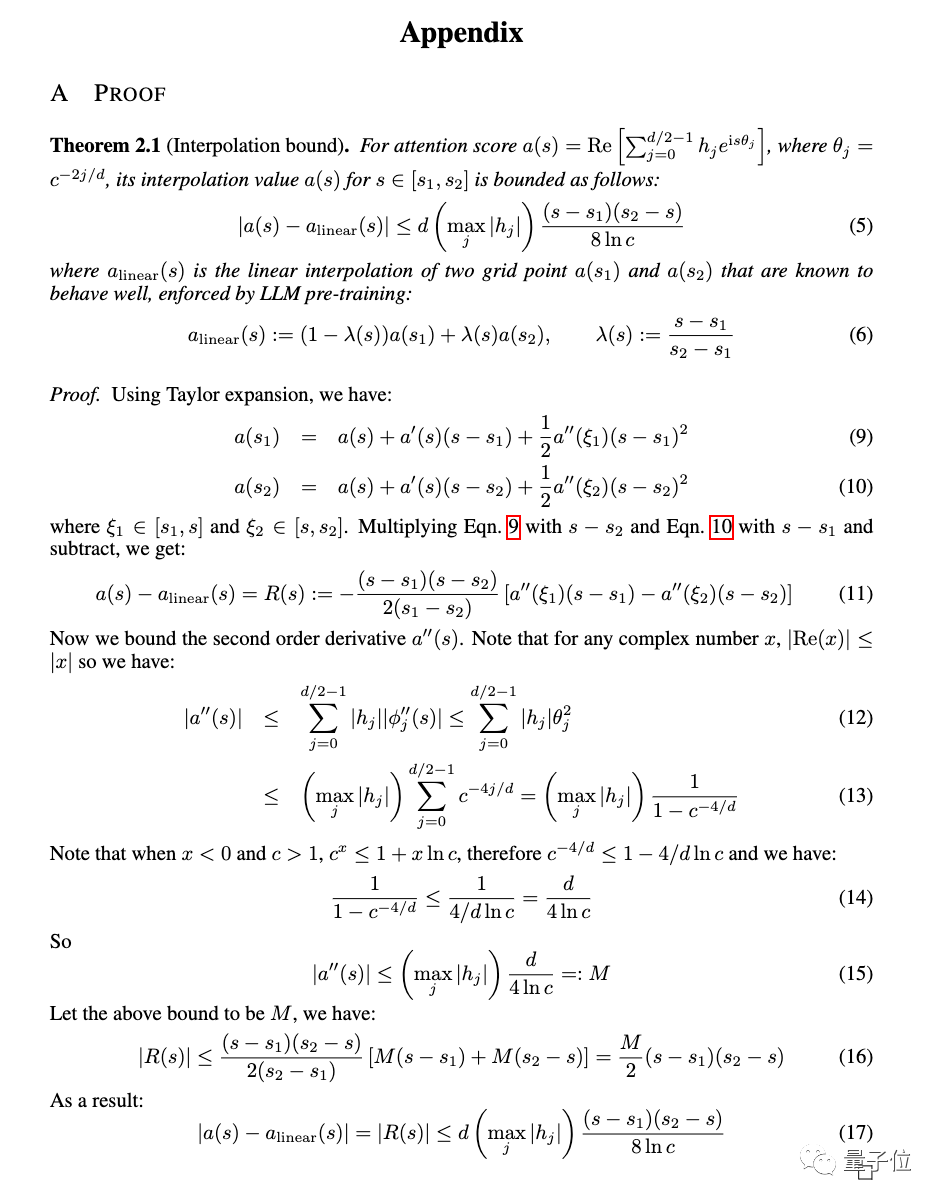
あと 3 つ
コンテキスト ウィンドウは、オープン ソースの大規模モデルと商用の大規模モデルとの間の重要なギャップでした。
たとえば、OpenAI の GPT-3.5 は最大 16k、GPT-4 は 32k、AnthropicAI の Claude は最大 100k をサポートします。
同時に、LLaMA や Falcon などの多くの大規模なオープンソース モデルは依然として 2k で止まっています。
今、Meta AI の新しい成果は、このギャップを直接埋めました。
コンテキスト ウィンドウの拡張も、最近の大規模モデル研究の焦点の 1 つであり、位置補間手法に加えて、業界の注目を集めるための多くの試みが行われています。
1. 開発者 kaiokendev は、技術ブログで LLaMa コンテキスト ウィンドウを 8K に拡張する方法を検討しました。
2. データ セキュリティ会社 Soveren の機械学習責任者である Galina Alperovich 氏は、コンテキスト ウィンドウを拡張するための 6 つのヒントを記事にまとめました。

3. Mila、IBM、およびその他の機関のチームも、論文の中で Transformer の位置エンコーディングを完全に削除しようとしました。

必要な友人は、下のリンクをクリックして表示できます~
メタ ペーパー: https://www.php.cn/link / 0bdf2c1f053650715e1f0c725d754b96
コンテキストの拡張は困難ですが、不可能ではありませんhttps://www.php.cn/link/9659078925b57e621eb3f9ef19773ac3
背後にある Secret Sauce コンテキスト ウィンドウLLM で 100K https://www.php.cn/link/09a630e07af043e4cae879dd60db1cac
ポジションレス コーディング ペーパーhttps://www.php.cn/link/fb6c84779f12283a81d739d8f088fc12
以上がアルパカファミリーの大型モデルが一斉に進化! 32k コンテキストは GPT-4 に相当し、Tian Yuandong のチームによって作成されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。