
ホームページ >テクノロジー周辺機器 >AI >大規模な AI モデルに関して、Tencent Cloud は自社開発の Xingmai 高性能コンピューティング ネットワークを初めて完全に公開しました
大規模な AI モデルに関して、Tencent Cloud は自社開発の Xingmai 高性能コンピューティング ネットワークを初めて完全に公開しました

- 王林転載
- 2023-06-28 14:19:591622ブラウズ
AIGC の発生は、コンピューティング能力の課題をもたらすだけでなく、ネットワークに前例のない要求を課します。
6 月 26 日、Tencent Cloud は自社開発の Xingmai 高性能コンピューティング ネットワークを初めて完全に公開しました。Xingmai ネットワークは業界最高の 3.2T 通信帯域幅を備えており、GPU 使用率を 40% 増加させ、30% を節約できます~ 60%: モデルのトレーニング コストにより、大規模な AI モデルの通信パフォーマンスが 10 倍向上します。 Tencent Cloud の新世代コンピューティング クラスター HCC は、100,000 枚を超えるカードという巨大なコンピューティング規模をサポートできます。
Tencent Cloud のバイスプレジデントであるWang Yachen 氏は次のように述べています。「Xingmai Network は大規模モデルのために生まれました。それが提供する、広い帯域幅、高い使用率、ゼロのパケット損失を備えた高性能ネットワーク サービスは、コンピューティング能力のボトルネックを打破し、 AI の可能性をさらに解放し、エンタープライズの大規模モデルのトレーニング効率を包括的に向上させ、クラウド上での大規模モデル テクノロジーの反復的なアップグレードと実装を加速します。」
大規模モデル専用の高性能ネットワークを構築し、GPU 使用率を 40% 向上させます
AIGC の人気により、大規模な AI モデルのパラメーターの数が数億から数兆に急増しました。大量のデータの大規模トレーニングをサポートするために、多数のサーバーが高速ネットワークを介してコンピューティング クラスターを形成し、相互接続されてトレーニング タスクを一緒に完了します。逆に、GPU クラスターが大きくなるほど、追加の通信損失も大きくなります。クラスターが大きいからといって、計算能力が高いわけではありません。 AI ラージ モデルの時代は、高帯域幅の要件、高い使用率、情報のロスレス性など、ネットワークに重大な課題をもたらしました。
従来の低速ネットワーク帯域幅では、数千億または数兆のパラメータを持つ大規模モデルを満足させることができず、トレーニング プロセス中の通信の割合が 50% に達する場合があります。同時に、従来のネットワーク プロトコルは、ネットワークの輻輳、高遅延、パケット損失を容易に引き起こす可能性があり、わずか 0.1% のネットワーク パケット損失がコンピューティング パワーの 50% の損失につながる可能性があり、最終的にはコンピューティング パワー リソースの深刻な浪費につながります。
Tencent Cloud は、包括的な自己研究能力に基づいて、ソフトウェアとハードウェアのアップグレードと、スイッチ、通信プロトコル、通信ライブラリ、およびオペレーティング システムの革新を実行し、業界をリードする大型モデルの専用ハイエンド プラットフォームを初めて発売しました。パフォーマンス ネットワーク - Xingmai ネットワーク。
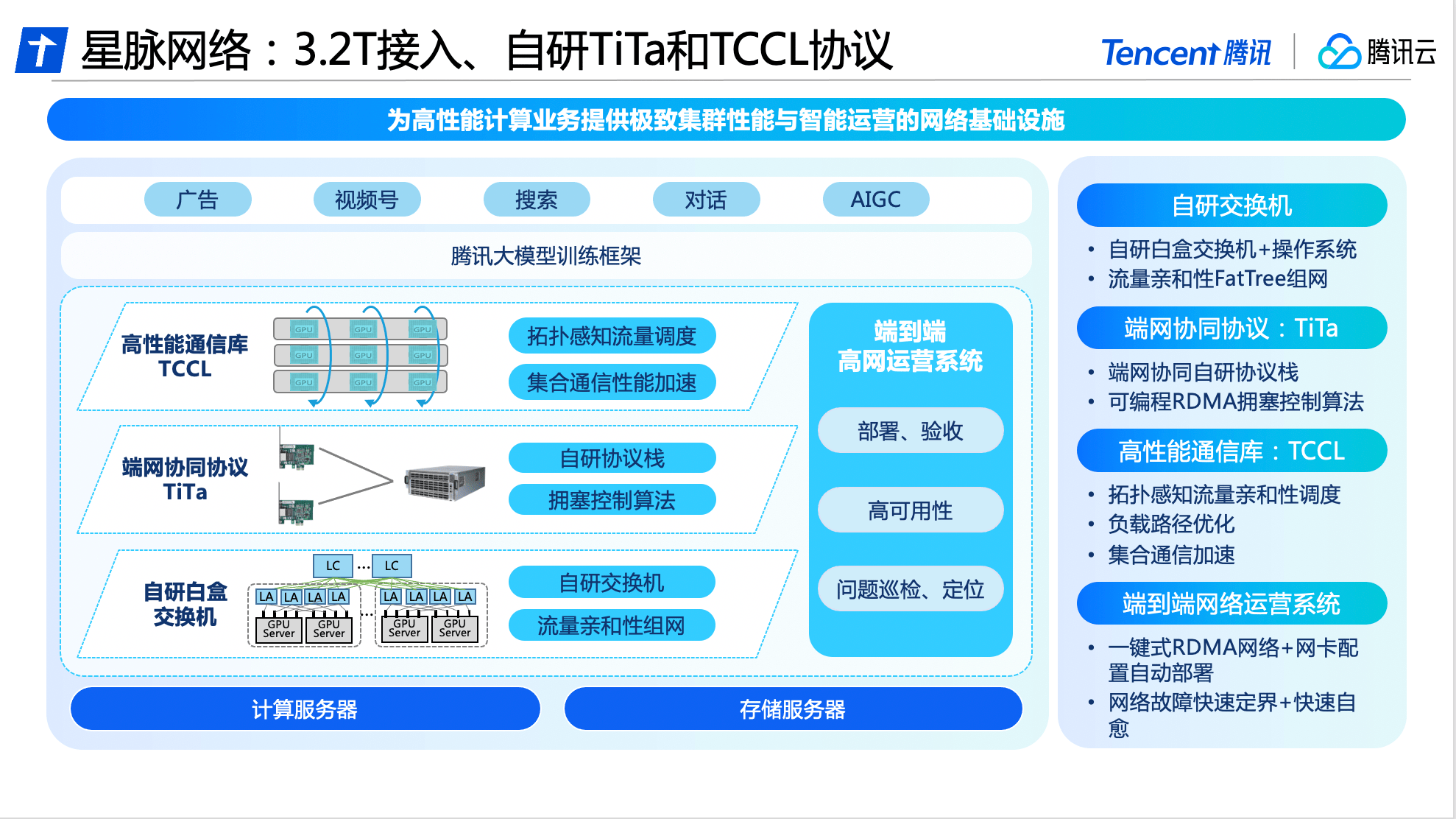
ソフトウェアの面では、Tencent Cloud が自社開発した TiTa ネットワーク プロトコルは高度な輻輳制御および管理テクノロジーを採用しており、ネットワークの輻輳をリアルタイムで監視および調整し、多数のサーバー ノード間の通信ニーズを満たし、スムーズな通信を保証します。データ交換や遅延が少なく、高負荷時でもパケットロスゼロを実現し、クラスタの通信効率を90%以上に高めます。
さらに、Tencent Cloud は、Xingmai Network 用の高性能集合通信ライブラリ TCCL も設計し、カスタマイズされたソリューションに統合して、システムがマイクロ秒レベルのネットワーク品質認識を実現できるようにしました。動的スケジューリング メカニズムを使用して通信チャネルを合理的に割り当てることにより、ネットワークの問題によるトレーニングの中断を効果的に回避でき、通信遅延を 40% 削減できます。
ネットワークの可用性によって、クラスター全体のコンピューティングの安定性も決まります。 Xingmai ネットワークの高可用性を確保するために、Tencent Cloud はエンドツーエンドのフルスタック ネットワーク オペレーション システムを開発し、エンド ネットワークの 3 次元監視とインテリジェント測位システムを通じて、エンド ネットワークの問題を自動的に境界設定し、日レベルから分レベルまで削減され、全体的な障害のトラブルシューティング時間が短縮されます。改善後、大規模モデル トレーニング システムの全体的な展開時間は 4.5 日に短縮され、基本構成の 100% の精度が保証されました。
3世代にわたる技術進化を経て、当社はソフトウェアとハードウェアの統合を深く培い、研究してきました
Xingmai Network の全面的なアップグレードの背後には、Tencent のデータセンター ネットワークの 3 世代にわたる技術進化の結果があります。
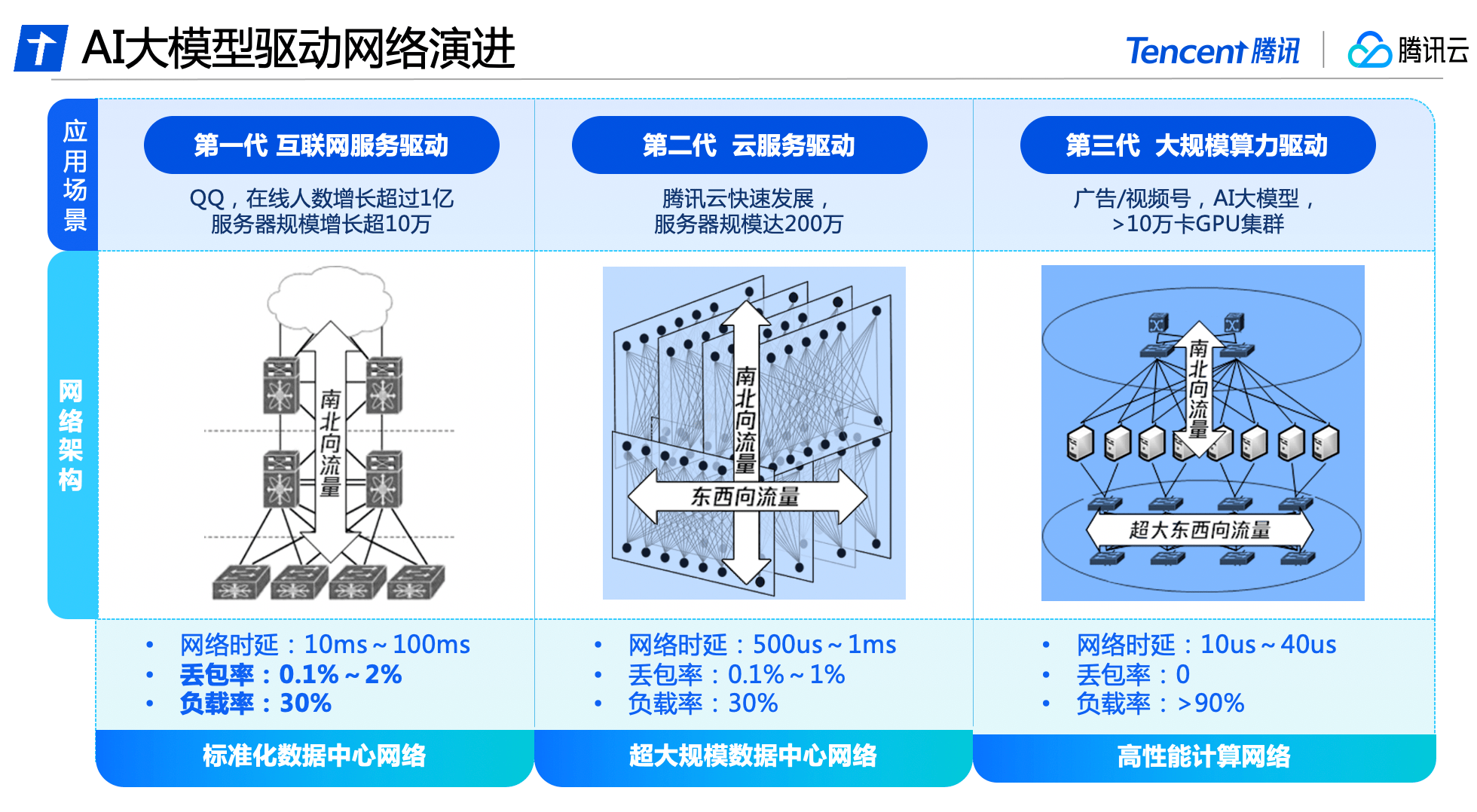
ビッグ データとクラウド コンピューティングの台頭により、サーバー間の東西トラフィックが徐々に増加し、クラウド テナントによってネットワークの仮想化と分離の要件が作成されました。データセンターのネットワーク アーキテクチャは、南北と東西の両方のトラフィックを伝送するクラウド ネットワーク アーキテクチャに徐々に進化しており、テンセント クラウドは完全に自社開発のネットワーク機器と管理システムを構築して、超大規模なデータセンター ネットワークを構築しています。約 200 万台のサーバーを備えています。
Tencent Cloud は、大規模な AI モデルのニーズを満たすために中国で初めて高性能コンピューティング ネットワークを立ち上げ、東西および南北のトラフィックに分離アーキテクチャを採用しました。 AIトレーニングトラフィックの特性を満たす超大帯域幅を備えた独立したネットワークアーキテクチャを構築し、自社開発のソフトウェアおよびハードウェア設備と連携してシステム全体の独立した制御性を実現し、ネットワークのスーパーコンピューティング能力の新たなニーズに対応します。パフォーマンス。
最近、Tencent Cloud は、Xingmai 高性能ネットワークをベースにした新世代の HCC 高性能コンピューティング クラスターをリリースしました。これは 3.2T の超高相互接続帯域幅を実現でき、コンピューティング パフォーマンスは従来の 3 倍です。前世代の大規模AIモデルであり、信頼性が高く高性能なネットワーク基盤を構築するためのトレーニングです。
将来的にも、Tencent Cloud は基礎技術の研究開発への投資を継続し、あらゆる分野のデジタル化とインテリジェント化に強力な技術サポートを提供していきます。
以上が大規模な AI モデルに関して、Tencent Cloud は自社開発の Xingmai 高性能コンピューティング ネットワークを初めて完全に公開しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。