
ホームページ >テクノロジー周辺機器 >AI >テンセントのロボット犬が進化:深層学習を通じて自律的な意思決定能力を習得
テンセントのロボット犬が進化:深層学習を通じて自律的な意思決定能力を習得

- 王林転載
- 2023-06-16 17:01:40916ブラウズ
6 月 14 日、Tencent Robotics の意思決定能力が大幅に向上しました。
ロボット犬を人間や動物と同じように柔軟かつ安定して動かせるようにすることは、ロボット研究分野における長期的な目標です。ディープラーニング技術の継続的な進歩により、機械は「学習」を通じて関連する能力を習得し、さまざまな問題に対処する方法を学ぶことができます。複雑な変化を伴う環境が可能になります。
事前トレーニングと強化学習の紹介: ロボット犬の機敏性を高める
Tencent Robotics は、事前学習モデルと強化学習技術を導入することで、再学習する代わりに、学習した姿勢、環境認識、戦略計画に関する多層的な知識を再利用し、他のケースについて推論することができます。 1 つのインスタンスから複雑な環境に柔軟に対応する


この一連の学習は 3 つの段階に分かれています:
最初の段階では、研究者は、ゲーム テクノロジーで一般的に使用されるモーション キャプチャ システムを通じて、歩く、走る、ジャンプする、立つなどの動作を含む本物の犬の動作姿勢データを収集し、これらのデータを使用して模倣を構築しました。シミュレータで学習タスクを実行し、これらのデータ内の情報を抽象化してディープ ニューラル ネットワーク モデルに圧縮します。これらのモデルは、収集された動物の動作姿勢情報を正確にカバーできるだけでなく、高い解釈性も備えています。
テンセントロボティクスこれらのテクノロジーとデータは、物理シミュレーションベースのエージェントトレーニングと現実世界のロボット戦略の展開において一定の補助的な役割を果たします。
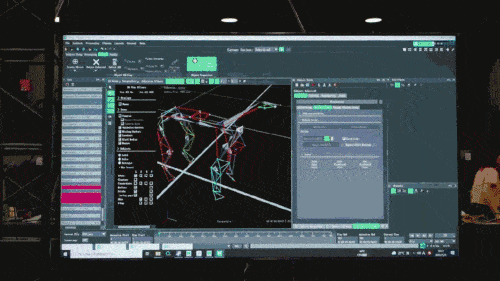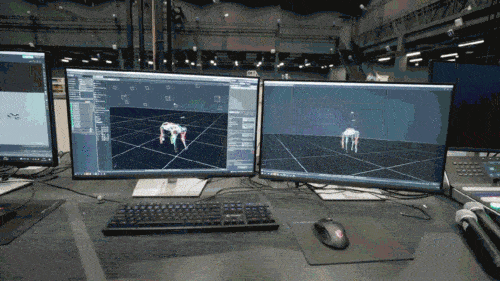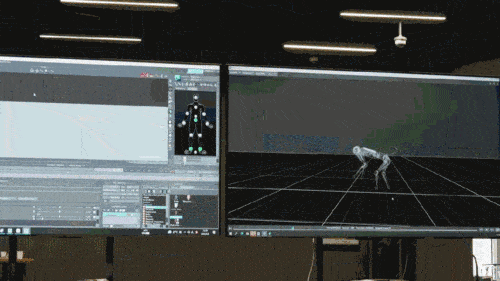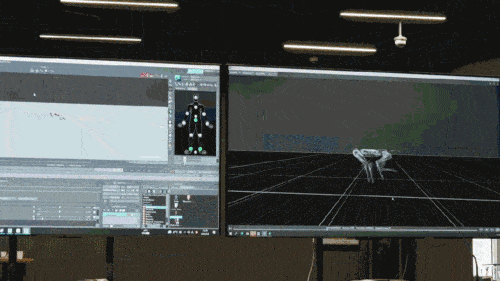

ニューラル ネットワーク モデルは、ロボット犬の固有受容情報 (運動状態など) のみを入力として受け入れ、模倣学習方法でトレーニングされます。次のステップでは、他のセンサーを使用して足元の障害物を検出するなど、周囲環境からの感覚データがモデルに組み込まれます。
第 2 段階では、追加のネットワーク パラメーターを使用して、第 1 段階で習得したロボット犬の賢い姿勢を外部の知覚と結び付け、ロボット犬が学習した賢い姿勢を通じて外部環境に反応できるようにします。 。ロボット犬がさまざまな複雑な環境に適応すると、スマートな姿勢と外部の知覚を結びつける知識も固定化され、ニューラルネットワーク構造に保存されます。



第 3 段階では、上記の 2 つの事前トレーニング段階で得られたニューラル ネットワークを使用して、ロボット犬はトップレベルのポリシー学習問題の解決に集中するための前提条件と機会を獲得し、最終的に複雑な問題を解決する能力を獲得します。エンドツーエンドのタスク。第 3 フェーズでは、ゲーム内の対戦相手や旗に関する情報の取得など、複雑なタスクに関連するデータを収集するためにネットワークが追加されます。さらに、戦略学習を担うニューラルネットワークは、あらゆる情報を総合的に分析することで、どの方向に走るか、相手の行動を予測して追いかけ続けるかどうかなど、タスクに対する高度な戦略を学習します。
上記の各段階で学習した知識は、再学習することなく拡張・調整できるため、継続的に蓄積し、継続的に学習することができます。
ロボット犬障害物追跡競技: 自律的な意思決定と制御機能を備えています
マックスが習得したこれらの新しいスキルをテストするために、研究者たちは障害物追跡ゲーム「ワールド チェイス タグ」からインスピレーションを得て、2 頭の犬による障害物追跡ゲームを設計しました。ワールド チェイス タグは、2014 年にイギリスで設立された障害物追跡競技団体です。民間の子供向けの追いかけっこを標準化したものです。一般的に、障害物追跡競技の各ラウンドでは、2 人の選手が互いに競い合います。1 人は追跡者 (アタッカーと呼ばれます)、もう 1 人は回避者 (ディフェンダーと呼ばれます) です。追跡ラウンド (つまり 20 秒) 中に相手を回避することに成功した場合 (つまり、接触が発生しなかった場合) に 1 ポイント。規定の追跡ラウンド数で最も多くのポイントを獲得したチームがゲームに勝利します。
ロボット犬障害物追いかけ競技の会場サイズは4.5メートル×4.5メートルで、その中にいくつかの障害物が点在しています。ゲーム開始時にフィールド内のランダムな位置に2匹のMAXロボット犬が配置され、1匹のロボット犬は追跡者、もう1匹は回避者の役割をランダムに割り当てられ、同時に旗が設置されます。フィールド内のランダムな場所にあります。
回避者の目標は、追跡者に捕まらずにできるだけ旗に近づくことです。追跡者の任務は回避者を捕まえることです。回避者が捕まる前に旗に触れることに成功すると、2 匹のロボット犬の役割が即座に切り替わり、旗は別のランダムな場所に再び表示されます。回避者が現在の追跡者に捕まり、追跡者の役割を果たしたロボット犬が勝利すると、ゲームは終了します。すべてのゲームにおいて、2 匹のロボット犬の平均前進速度は 0.5m/s に制限されています。
このゲームから判断すると、事前トレーニングされたモデルに基づいて、ロボット犬はすでに深層強化学習を通じて一定の推論能力と意思決定能力を備えています。
たとえば、追跡者が、旗に触れる前に回避者に追いつけないと悟った場合、追跡者は追跡を諦め、代わりに次の重要なステップを待つために回避者から離れます。設定されているフラグが表示されます。さらに、追跡者は、土壇場で回避者を捕まえようとしているとき、飛び上がって回避者に向かって「飛びかかる」動作をすることを好みます。これは、動物が獲物を捕まえるときの行動と非常によく似ています。回避者が旗に触れようとしているとき、時々同じ動作を示します。これらはすべて、ロボット犬が勝利を確実にするために講じる積極的な加速手段です。
報告によると、ゲーム内のロボット犬の制御戦略はすべてニューラル ネットワーク戦略であり、シミュレーションとゼロショット転送 (ゼロ調整転送) を通じて学習され、ニューラル ネットワークが人間の推論方法をシミュレートして識別できるようになります。新しいものを見て、その知識を実際のロボット犬に応用してください。たとえば、下の図に示すように、追跡タグ ゲームの仮想世界で障害物のあるシーンが訓練されていないにもかかわらず、ロボット犬が事前訓練モデルで学習した障害物を回避する知識がゲームで使用されます (仮想世界のみ(平地でのゲームシーンで訓練した後)、ロボット犬もタスクを正常に完了できます。
Tencent Robotics 学習テクノロジーは、ロボットの制御能力を向上させ、より柔軟にするためにロボットの分野に導入され、ロボットが現実の生活に参入して人間に奉仕するための強固な基盤を築きます。
以上がテンセントのロボット犬が進化:深層学習を通じて自律的な意思決定能力を習得の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。