
ホームページ >テクノロジー周辺機器 >AI >手書きを模倣してあなた専用のフォントを作成できるAI
手書きを模倣してあなた専用のフォントを作成できるAI

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-16 15:30:182147ブラウズ
手書き模倣AIの研究背景
ことわざにあるように、言葉は顔のようなもの、言葉は人のようなものです。堅固な印刷フォントと比較して、手書きは書き手の個人的な特徴をよりよく反映することができます。多くの人は、独自の手書きフォントのセットを持ち、それをソーシャル ソフトウェアで使用して、自分のスタイルをよりよく表現することを想像したことがあると思います。
しかし、英語の文字と違って漢字は文字数が非常に多く、専用のフォントを作成するには非常にコストがかかります。たとえば、新しくリリースされた国家標準 GB18030-2022 の漢字セットには、80,000 を超える漢字が含まれています。あるビデオ ウェブサイトのブロガーが 18 時間かけて 7,000 文字以上の漢字を書き、その過程で 13 本のペンを使用し、執筆で手がしびれてしまったという報告があります。
#上記の質問は、論文の著者がそれについて考えるきっかけとなりました。自動テキスト生成モデルは、高コストの問題を解決するのに役立つように設計できますか?専用のフォントを作成しますか?この問題を解決するために、研究者らは、ユーザーが少数(十数個)の筆跡サンプルを提供するだけで、筆跡に含まれる書体(筆跡の大きさなど)を抽出できる手書き模倣AIを構想した。文字、傾きの度合い、アスペクト比、ストロークの長さと曲率など)を選択し、そのスタイルをコピーしてさらに多くのテキストを合成することで、ユーザー向けの手書きフォントの完全なセットを効率的に合成できます。

さらに、論文の著者は、アプリケーションの価値とユーザーの観点からモデルの入出力を分析しました。 1. シーケンス モードのオンライン手書きには、オフラインの画像の手書きよりも豊富な情報 (下図に示すトラック ポイントの詳細な位置と書き順) が含まれていることを考慮してください。モード (図示) では、モデルの出力モードをオンライン テキストに設定すると、ロボットによるライティングや書道の教育など、より幅広い用途が期待できます。 2. 日常生活においては、タブレットやタッチペンなどの収集機器を介してオンラインテキストを取得するよりも、携帯電話を使用して写真を撮ってオフラインテキストを取得する方が便利です。したがって、生成されたモデルの入力モードをオフライン テキストに設定すると、ユーザーがより使いやすくなります。
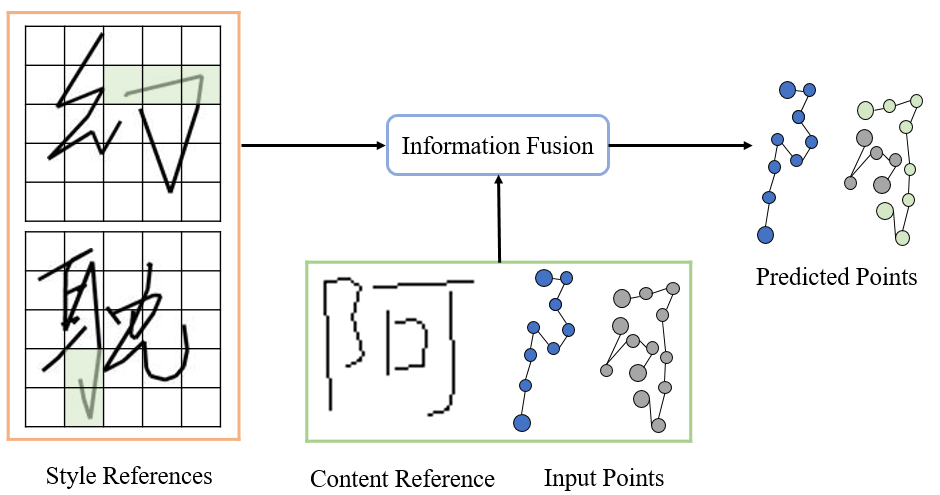
要約すると、この記事の研究目標は、定型化されたオンライン手書き文字を提案することです。テキスト生成モデル (様式化されたオンライン手書き生成方法)。このモデルは、ユーザーが提供したオフライン テキストに含まれる書体をコピーするだけでなく、ユーザーのニーズに応じてコンテンツ制御可能な手書き文字をオンラインで生成することもできます。

- 紙のアドレス: https://arxiv.org/abs/2303.14736
- #オープンソース コード: https://github.com/dailenson/SDT 主な課題
研究動機 研究者らは、個人の手書き文字には通常 2 つの書き方があることを発見しました。個々の文字が同様の傾きとアスペクト比を示しているなど、同じ作家の手書きにおける全体的な文体の共通性、および異なる作家の文体の共通性は異なります。この特徴はさまざまな作家を区別するために使用できるため、研究者はそれを作家のスタイルと呼んでいます。 2. 全体的な文体の共通性に加えて、同じ作家の異なるキャラクターの間には詳細な文体の不一致があります。たとえば、「黑」と「杰」という 2 つの文字は、同じ 4 つの点の水部首を文字構造として持ちますが、この部首を別の文字で書く際には若干の書き方の違いがあり、それが図に反映されています。ストロークの長さ、位置、曲率。研究者は、この微妙なスタイル パターンをグリフ グリフ スタイルと呼んでいます。上記の観察に触発されて、SDT は、ユーザーの手書きスタイルを模倣する機能を向上させることを期待して、ライターとグリフ スタイルを個人の手書きから切り離すことを目指しています。 #スタイル情報を学習した後、スタイルとコンテンツの特徴を単純に結合する以前の手書きテキスト生成方法とは異なり、SDT ではコンテンツの特徴がクエリ ベクトルとして使用されます。スタイル情報を適応的に取得することで、スタイルとコンテンツの効率的な統合を実現し、ユーザーの期待に応える手書き文字を生成します。 解決策

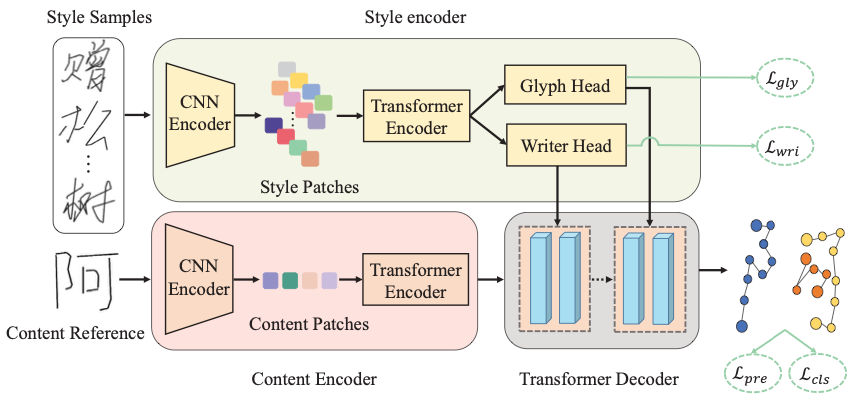
メソッド フレームワーク SDT の全体的なフレームワークは次の図に示されており、デュアル ブランチ スタイル エンコーダー、コンテンツ エンコーダー、トランスフォーマー デコーダーの 3 つの部分で構成されます。まず、この論文では、スタイル エンコーダのライター ブランチとグリフ ブランチがそれぞれ対応するスタイル抽出を学習するようにガイドする 2 つの相補的な対照的な学習目標を提案します。次に、SDT は、トランスフォーマーのアテンション メカニズム (マルチヘッド アテンション) を使用して、スタイル特徴とコンテンツ エンコーダーによって抽出されたコンテンツ特徴を動的に融合し、オンライン手書きテキストを段階的に合成します。
作家の比較研究スタイル SDT は、作家スタイル抽出のための教師あり比較学習目標 (WriterNCE) を提案します。これは、同じ作家に属する文字サンプルを集め、異なる作家に属する手書きサンプルを押しのけ、作家を明示的にガイドします。個々の手書き文字の文体の共通点。
(b)
文字スタイルの対照学習 より詳細なグリフ スタイルを学習するために、SDT は教師なし比較学習目標を提案します。 (GlyphNCE) は、同じ文字の異なるビュー間の相互情報を最大化するために使用され、グリフ ブランチが文字の詳細なパターンの学習に集中するように促します。以下の図に示すように、最初に同じ手書き文字の 2 つの独立したサンプルを実行して、詳細なストローク情報
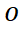 ## と # を含む 1 対の肯定的なサンプルを取得します。
## と # を含む 1 対の肯定的なサンプルを取得します。
## 次に、他の文字からサンプリングして負のサンプルを取得します 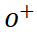
##。サンプルが採取されるたびに、元のサンプルの詳細を含む新しい視点として、少数のサンプル ブロックがランダムに選択されます。サンプル ブロックのサンプリングは、文字の特定の領域のオーバーサンプリングを避けるために均一な分布に従います。グリフ ブランチをより適切にガイドするために、サンプリング プロセスはグリフ ブランチによって出力された特徴シーケンスに直接作用します。
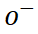
(c) スタイルとコンテンツ情報の統合戦略 2 つのスタイル機能を取得した後、コンテンツ エンコーダーによって学習されたコンテンツ エンコーディングとそれを効率的に統合するにはどうすればよいでしょうか?この問題を解決するために、SDT は、任意のデコード時間 t において、コンテンツ特徴を初期点とみなし、q 時間および t 時間前に出力された軌跡点を結合します。
新しいコンテンツ コンテキストを形成します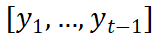
。次に、コンテンツ コンテキストがクエリ ベクトルとして扱われ、スタイル情報がキーと値のベクトルとして扱われます。クロスアテンション メカニズムの統合により、コンテンツ コンテキストと 2 つのスタイル情報が順番に動的に集約されます。
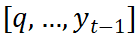
実験
定量的評価
SDT は中国語、日本語、インド、英語のデータセットで、特にスタイルスコアインデックスで最高のパフォーマンスが達成され、以前の SOTA メソッドと比較して、SDT は大きな進歩を遂げました。
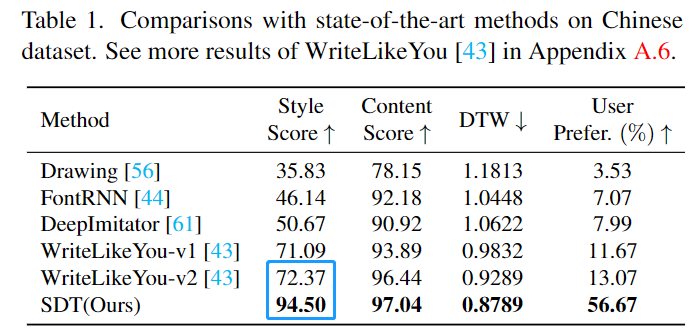
##定性的評価 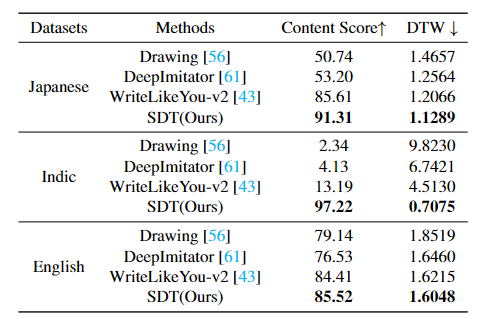
#中国語生成に関しては、従来の方法と比較して、SDT で生成された手書き文字は文字崩れを回避でき、コピーも可能です。ユーザーの書き方がとても上手です。グリフ スタイル学習のおかげで、SDT は文字のストロークの詳細を生成する際にも適切に機能します。
SDT は他の言語でも適切に機能します。特にインドのテキスト生成に関しては、既存の主流の方法では簡単に崩れた文字を生成できますが、当社の SDT は文字コンテンツの正確さを維持できます。
#さまざまなモジュールがアルゴリズムのパフォーマンスに与える影響を示します。
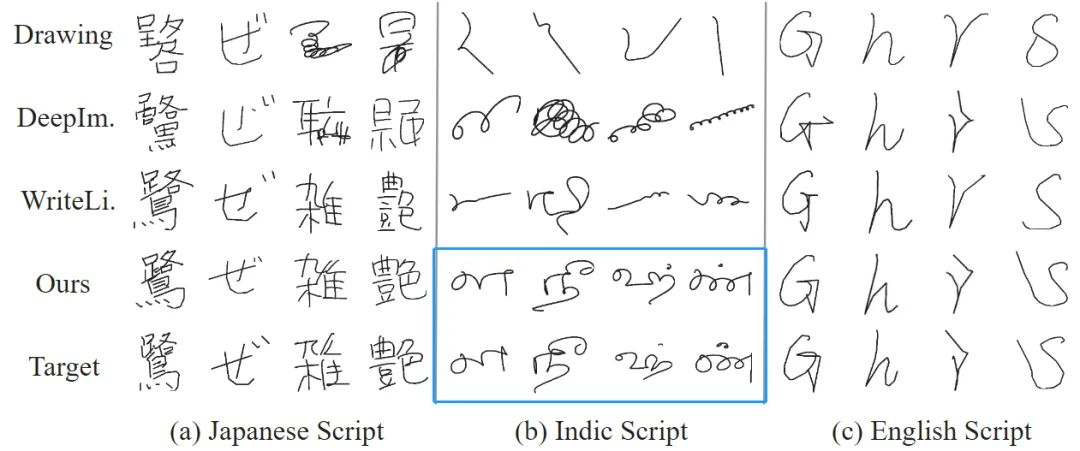 次の表に示すように、この記事で提案されているさまざまなモジュールは相乗効果をもたらし、ユーザーの手書きコピーのパフォーマンスを効果的に向上させます。具体的には、ライターのスタイルの追加により、SDT による文字の傾きや縦横比などの全体的な文字スタイルの模倣が向上し、グリフ スタイルの追加により、生成された文字のストロークの詳細が向上します。既存の手法の単純な融合戦略と比較して、SDT の適応動的融合戦略は、さまざまな指標におけるキャラクター生成パフォーマンスを包括的に強化します。
次の表に示すように、この記事で提案されているさまざまなモジュールは相乗効果をもたらし、ユーザーの手書きコピーのパフォーマンスを効果的に向上させます。具体的には、ライターのスタイルの追加により、SDT による文字の傾きや縦横比などの全体的な文字スタイルの模倣が向上し、グリフ スタイルの追加により、生成された文字のストロークの詳細が向上します。既存の手法の単純な融合戦略と比較して、SDT の適応動的融合戦略は、さまざまな指標におけるキャラクター生成パフォーマンスを包括的に強化します。
2 つのスタイル特徴に対してフーリエ変換を実行して、次のスペクトログラムを取得します。図から、ライターのスタイルにはより低周波成分が含まれているのに対し、グリフ スタイルは主に高周波成分に焦点を当てていることがわかります。周波数成分です。実際、低周波成分にはターゲットの全体的な輪郭が含まれていますが、高周波成分にはオブジェクトの詳細がより注目されています。この発見は、分離された書き方の有効性をさらに検証し、説明します。 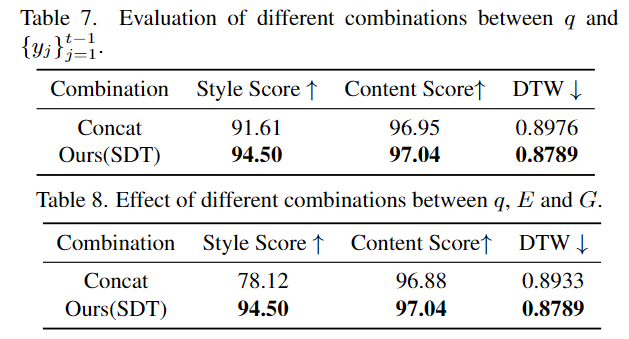
誰もが手書き AI を通じて独自のフォントを作成し、ソーシャル プラットフォームで自分自身をより良く表現できるようになります。 今後の展望
以上が手書きを模倣してあなた専用のフォントを作成できるAIの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。