
ホームページ >テクノロジー周辺機器 >AI >マルチモーダルな制御可能な画像生成のための統合モデルがここにあり、すべてのモデルパラメータと推論コードはオープンソースです
マルチモーダルな制御可能な画像生成のための統合モデルがここにあり、すべてのモデルパラメータと推論コードはオープンソースです

- WBOY転載
- 2023-06-06 17:12:041280ブラウズ

- 紙のアドレス: https://arxiv.org/abs/2305.11147
- #コード アドレス: https://github.com/salesforce/UniControl ##プロジェクト ホームページ: https://github.com/salesforce/UniControl shorturl.at/lmMX6
Stable Diffusion は、強力なビジュアル生成機能を示します。ただし、空間的、構造的、または幾何学的に制御された画像を生成するには不十分なことがよくあります。 ControlNet [1] や T2I アダプター [2] などの作品は、さまざまなモダリティに合わせて制御可能な画像生成を実現していますが、単一の統一モデルでさまざまな視覚条件に適応できるようにすることは未解決の課題のままです。 UniControl は、単一のフレームワーク内にさまざまな制御可能な条件から画像への (C2I) タスクを組み込みます。 UniControl が多様な視覚条件を処理できるようにするために、著者らはタスク認識 HyperNet を導入して、ダウンストリームの条件付き拡散モデルを調整し、さまざまな C2I タスクに同時に適応できるようにしました。 UniControl は 9 つの異なる C2I タスクでトレーニングされ、強力なビジュアル生成機能とゼロショット汎化機能を実証します。作者はモデルパラメータと推論コードをオープンソース化していますが、データセットとトレーニングコードもできるだけ早くオープンソース化する予定ですので、どなたでも自由に交換してご利用いただけます。

動機:
既存の制御可能な画像生成モデルは、単一のモダリティ向けに設計されていますが、Taskonomy [3] らの研究により、特徴と情報は異なる視覚モダリティ間で共有されるため、この論文では、統合されたマルチモーダル モデルには大きな可能性があると考えています。解決策:
この記事では、UniControl にマルチモーダル条件生成機能を実装するための MOE スタイルのアダプターとタスク認識ハイパーネットを提案します。そして著者は、9 つの主要なタスク、2,000 万以上の画像条件プロンプト トリプル、画像サイズ ≥ 512 を含む新しいデータセット MultiGen-20M を作成しました。利点:
1) よりコンパクトなモデル (1.4B #params、5.78GB チェックポイント)、複数のタスクを達成するためのパラメータが少なくなります。 2) より強力なビジュアル生成機能と制御精度。 3) これまでに見たことのないモダリティに関するゼロショット一般化能力。 1. はじめに
生成基本モデルは、自然言語処理、コンピューター ビジョン、音声処理、ロボット制御などの分野で人工知能が対話する方法を変えています。自然言語処理では、InstructGPT や GPT-4 などの生成基本モデルはさまざまなタスクで適切に実行され、このマルチタスク機能は最も魅力的な機能の 1 つです。さらに、ゼロショットまたは少数ショット学習を実行して、目に見えないタスクを処理することもできます。しかし、視覚分野の生成モデルでは、このマルチタスク能力は顕著ではありません。テキストによる説明は、生成された画像の内容を制御する柔軟な方法を提供しますが、多くの場合、ピクセル レベルの空間的、構造的、または幾何学的制御を提供するには不十分です。 ControlNet や T2I アダプターなどの最近の人気の研究では、安定拡散モデル (SDM) を強化して正確な制御を実現できます。ただし、CLIP などの統合モジュールで処理できる言語キューとは異なり、各 ControlNet モデルはトレーニングされた特定のモダリティのみを処理できます。
以前の研究の制限を克服するために、この論文では、言語とさまざまな視覚条件の両方を処理できる統合拡散モデルである UniControl を提案します。 UniControl の統合設計により、トレーニングと推論の効率が向上し、制御可能な生成が強化されます。一方、UniControl は、さまざまな視覚条件間の固有のつながりを利用して、各条件の生成効果を強化します。
UniControl の統合された制御可能な生成機能は、2 つの部分に依存しています。1 つは「MOE スタイル アダプター」、もう 1 つは「タスク認識ハイパーネット」です。 MOE スタイルのアダプターには約 70,000 のパラメーターがあり、さまざまなモダリティから低レベルの特徴マップを学習できます。タスク認識型 HyperNet は、タスク指示を自然言語プロンプトとして入力し、下流のネットワークに埋め込まれるタスクの埋め込みを出力して、下流のモデルを調整できます。さまざまなモーダル入力に適応します。
この研究では、UniControl を事前トレーニングして、エッジ (キャニー、HED、スケッチ)、エリアの 5 つのカテゴリの 9 つの異なるタスクを含む、マルチタスクおよびゼロショット学習の機能を取得しました。マッピング (セグメンテーション、オブジェクト バインド ボックス)、スケルトン (人間の骨格)、ジオメトリ (深さ、法線表面)、および画像編集 (画像アウトペイント)。この調査では、NVIDIA A100 ハードウェア上で 5,000 GPU 時間以上にわたって UniControl をトレーニングしました (新しいモデルは現在もトレーニング中です)。また、UniControl は、新しいタスクに対するゼロショットの適応性を示します。
この研究の貢献は次のように要約できます:
- この研究は、さまざまな処理を実行できる統合コントローラである UniControl を提案します。制御可能なビジュアル生成のためのビジュアル条件モデル (1.4B #params、5.78GB チェックポイント)。
- この研究では、5 つのカテゴリの 9 つの異なるタスクをカバーする 2,000 万を超える画像、テキスト、条件のトリプルを含む新しい複数条件のビジュアル生成データセットを収集しました。
- この研究では、統合モデル UniControl が、異なる視覚条件間の固有の関係を学習することにより、単一タスクごとの制御された画像生成よりも優れたパフォーマンスを発揮することを実証するために実験を実施しました。
- UniControl は、目に見えないタスクにゼロショットで適応する能力を実証し、オープン環境で広く使用される可能性と可能性を実証します。
2. モデル設計
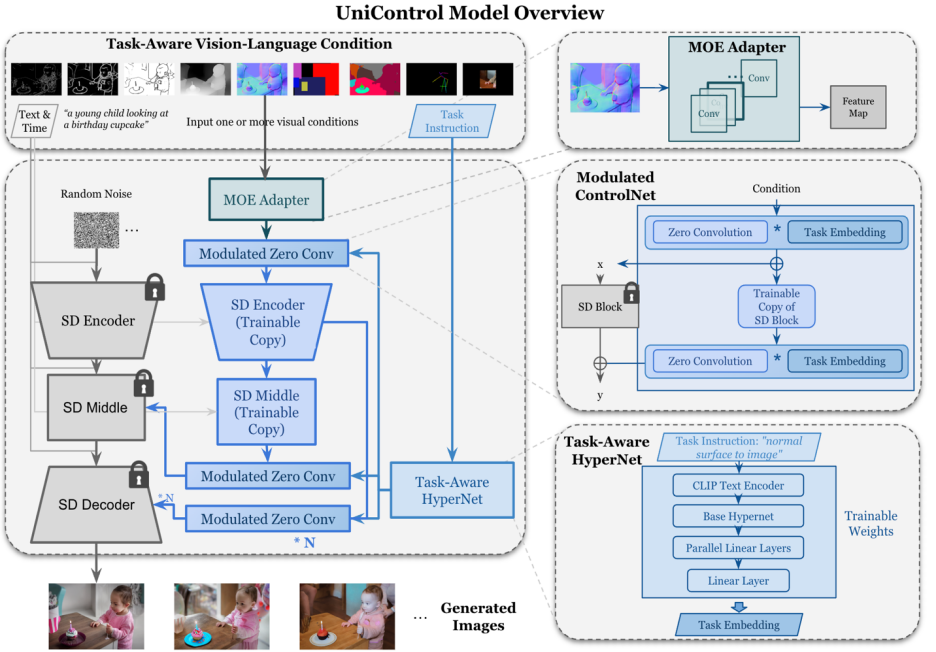
##図 2: モデルの構造。複数のタスクに対応するために、この研究では、タスクあたり約 70,000 のパラメーターを備えた MOE スタイルのアダプターと、7 つのゼロ畳み込み層を変調するためのタスク対応の HyperNet (約 1,200 万のパラメーター) を設計しました。この構造により、単一モデルでのマルチタスク機能の実装が可能になり、マルチタスクの多様性が保証されるだけでなく、基礎となるパラメーターの共有も維持されます。同等のスタック型シングルタスク モデルと比較して、モデル サイズが大幅に縮小されます (モデルあたり約 14 億のパラメーター)。
UniControl モデル設計では、次の 2 つの特性が保証されます。
#1) さまざまなモダリティの不整合による低レベルの機能の克服。これは、UniControl がすべてのタスクから必要な固有の情報を学習するのに役立ちます。たとえば、モデルが視覚条件としてセグメンテーション マップに依存している場合、3D 情報は無視される可能性があります。
2) タスク全体にわたるメタ知識を学習できる。これにより、モデルはタスク間の共有知識とタスク間の差異を理解できるようになります。
これらのプロパティを提供するために、モデルには MOE スタイルのアダプターとタスク認識ハイパーネットという 2 つの新しいモジュールが導入されています。
MOE スタイルのアダプターは、畳み込みモジュールのセットです。各アダプターは、個別のモダリティに対応します。これは、専門家の混合モデル (MOE) からインスピレーションを得ており、UniControl として使用され、さまざまな低レベルのビジョンをキャプチャします。条件の特徴。このアダプター モジュールには約 70K のパラメーターがあり、計算効率が非常に優れています。視覚的特徴は、処理のために統合ネットワークに供給されます。
タスク認識 HyperNet は、タスクの命令条件を通じて ControlNet のゼロ畳み込みモジュールを調整します。 HyperNet はまずタスク命令をタスク埋め込みに投影し、次に研究者はタスク埋め込みを ControlNet のゼロ畳み込み層に注入します。ここで、タスクの埋め込みは、ゼロ畳み込み層の畳み込みカーネル行列サイズに対応します。 StyleGAN [4] と同様に、この研究では 2 つを直接乗算して畳み込みパラメータを変調し、変調された畳み込みパラメータが最終的な畳み込みパラメータとして使用されます。したがって、各タスクの変調されたゼロ畳み込みパラメーターは異なります。これにより、モデルの各モダリティへの適応性が保証され、さらに、すべての重みが共有されます。
3. モデルのトレーニング
SDM や ControlNet とは異なり、これらのモデルの画像生成条件は単一の言語キュー、またはキャニーなどの単一タイプの視覚条件です。 UniControl は、言語による合図だけでなく、さまざまなタスクからのさまざまな視覚的条件を処理する必要があります。したがって、UniControl の入力は、ノイズ、テキスト プロンプト、視覚条件、タスク指示の 4 つの部分で構成されます。その中で、視覚状態のモダリティに応じた作業指示が自然に得られる。

このように生成されたトレーニング ペアを使用して、この研究では DDPM [5] を使用してモデルをトレーニングします。
4. 実験結果

##図 6: テスト セットの視覚的な比較結果。テスト データは MSCOCO [6] および Laion [7]
から取得したものです。この研究で再現された公式または ControlNet との比較結果を図 6 に示します。詳細 結果については論文を参照してください。 #5.ゼロショット タスクの一般化
#モデルは、次の 2 つのシナリオでゼロショット能力をテストします。 #混合タスクの一般化: この研究では、UniControl への入力として 2 つの異なる視覚条件を考慮します。1 つはセグメンテーション マップと人間の骨格の混合であり、テキスト プロンプトに特定のキーワード「背景」と「前景」を追加します。さらに、この研究では、ハイブリッドタスクの命令を、「セグメンテーションマップと人間の骨格を画像に変換する」など、2つのタスクを組み合わせる命令のハイブリッドとして書き換えています。新しいタスクの一般化: UniControl は、新しい目に見えない視覚条件で制御可能な画像を生成するために必要です。これを達成するには、目に見えない事前トレーニング タスクと目に見える事前トレーニング タスクの関係に基づいてタスクの重みを推定することが重要です。タスクの重みは、埋め込み空間内のタスク命令の類似性スコアを手動で割り当てるか計算することによって推定できます。 MOE スタイルのアダプターは、推定されたタスクの重みを使用して線形に組み立てられ、新しい目に見えない視覚条件から浅い特徴を抽出できます。
視覚化した結果を図 7 に示します。結果の詳細については、論文を参照してください。
#図 7: ゼロショット タスクにおける UniControl の視覚化結果
6. 概要一般に、UniControl モデルは、制御の多様性を通じて制御可能なビジュアル生成のための新しい基本モデルを提供します。このようなモデルは、画像生成タスクのより高いレベルの自律性と人間による制御を達成する可能性を提供する可能性があります。この研究は、この分野の発展をさらに促進するために、より多くの研究者と議論し、協力することを楽しみにしています。
#その他のビジュアル
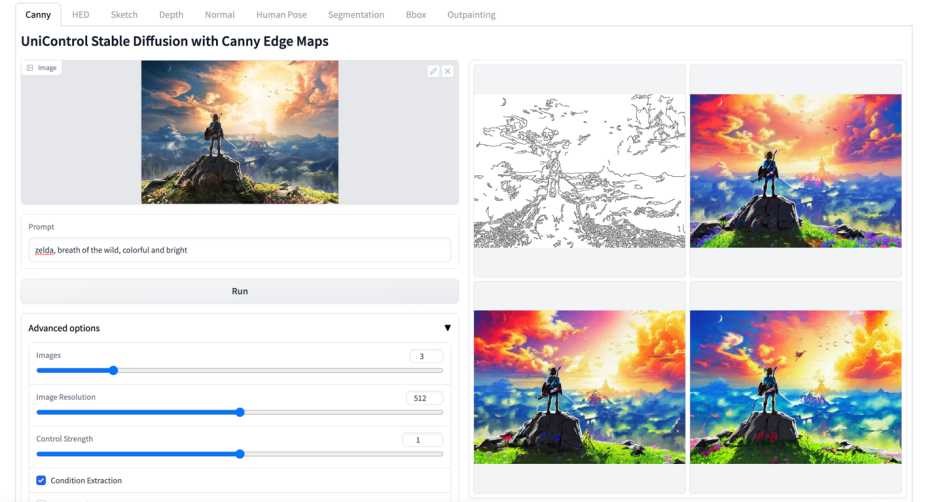
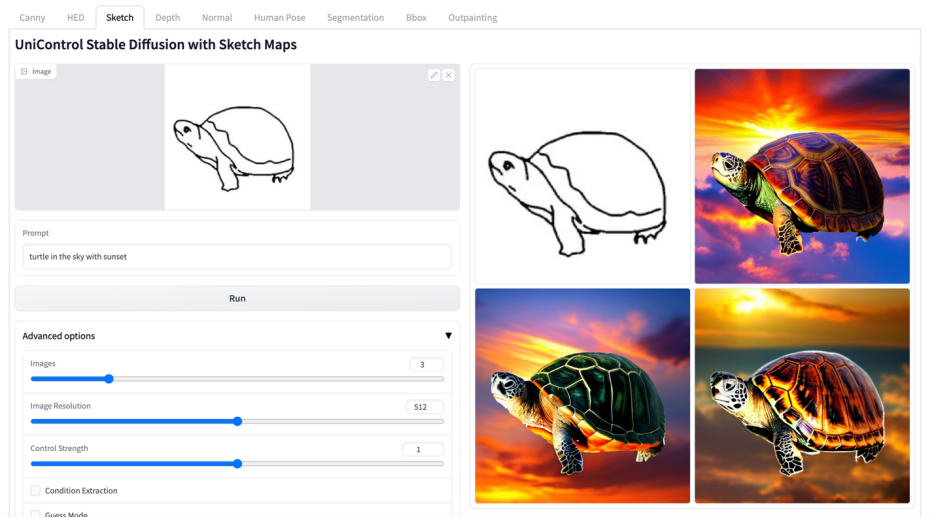
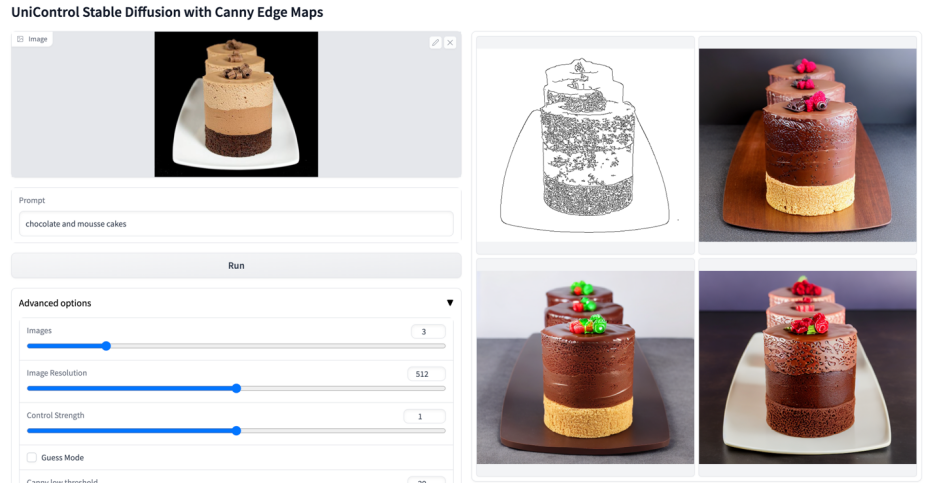
#
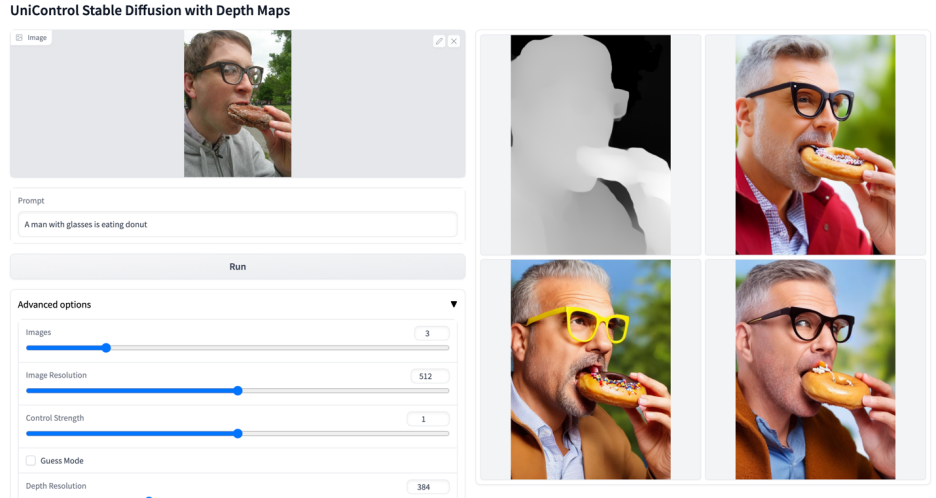
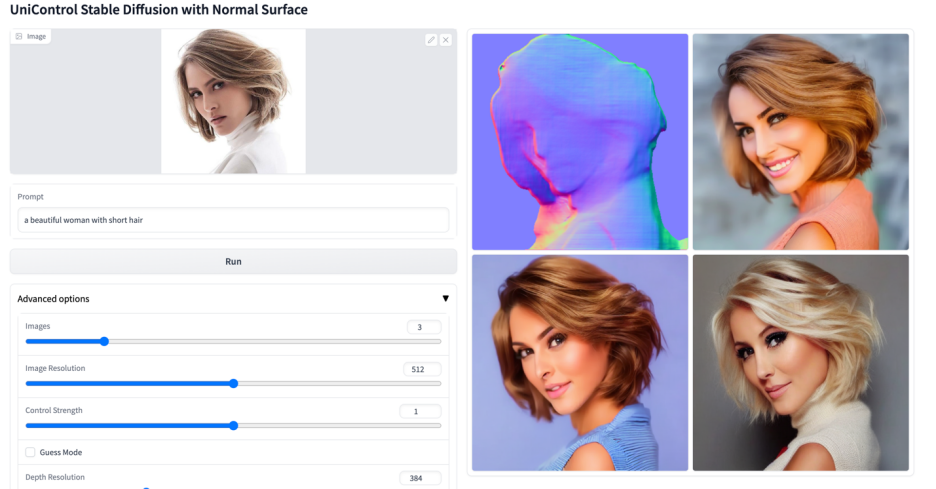
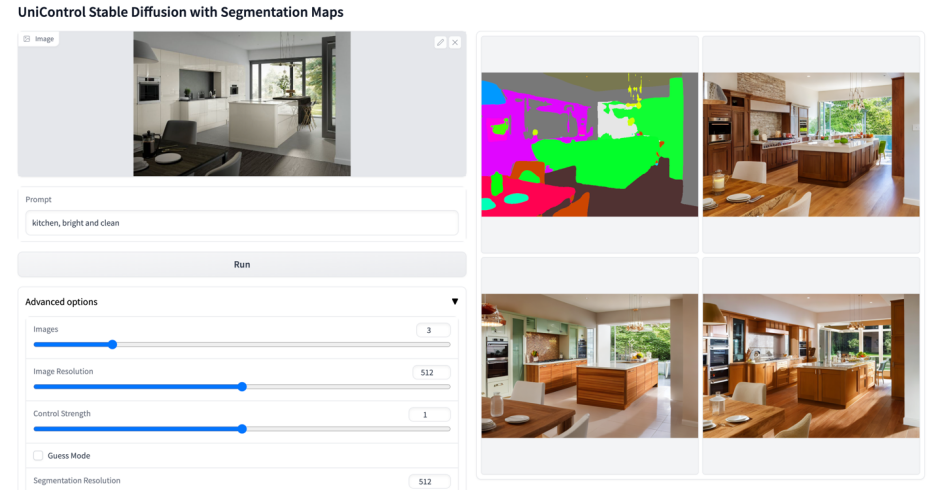
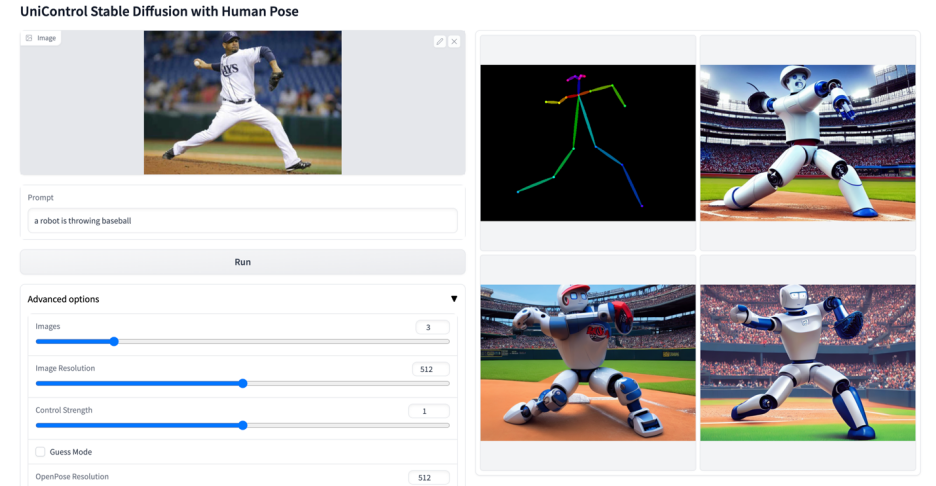
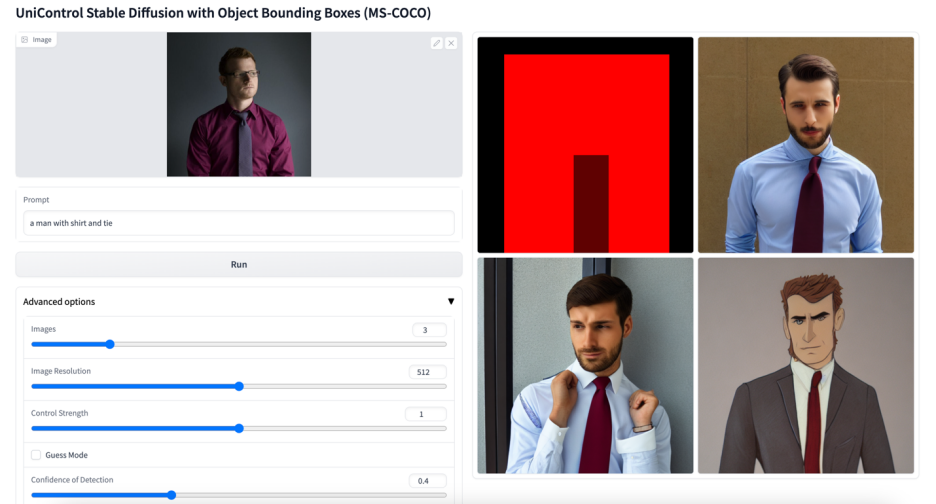
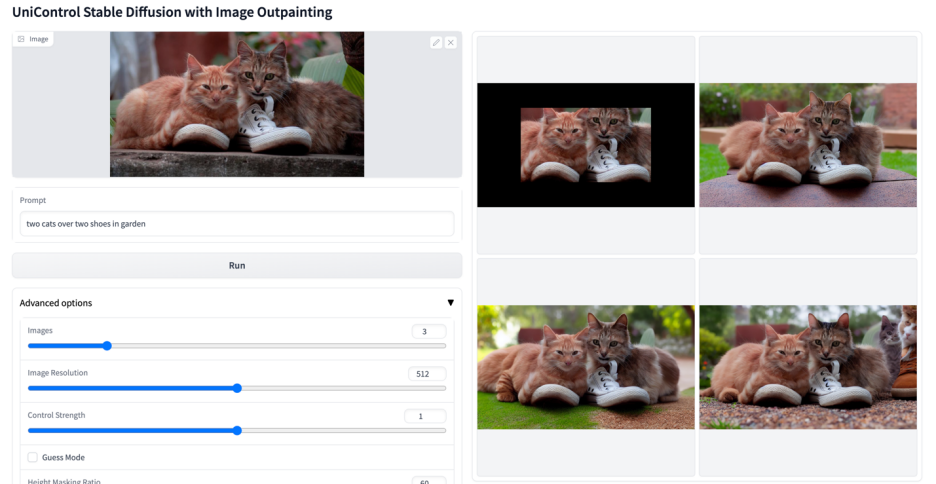
以上がマルチモーダルな制御可能な画像生成のための統合モデルがここにあり、すべてのモデルパラメータと推論コードはオープンソースですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。