
ホームページ >データベース >mysql チュートリアル >MySQL の 3 層論理アーキテクチャとは何ですか?
MySQL の 3 層論理アーキテクチャとは何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-03 12:46:121600ブラウズ
MySQL の 3 層論理アーキテクチャ
MySQL のストレージ エンジン アーキテクチャは、クエリ処理をデータの保存/取得から分離します。以下は MySQL の論理アーキテクチャ図です:
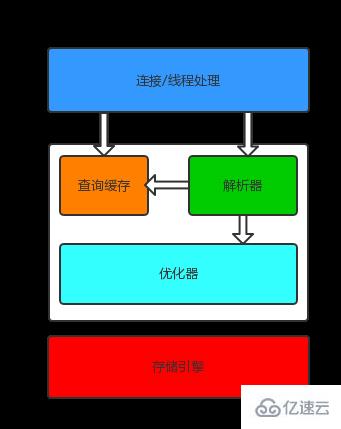
#1. 最初の層は接続管理、認可認証、セキュリティなどを担当します。
各クライアント接続はサーバー上のスレッドに対応します。スレッド プールは、接続ごとにスレッドが作成および破棄されることを避けるために、サーバー上で維持されます。クライアントが MySQL サーバーに接続すると、サーバーはクライアントを認証します。認証は、ユーザー名とパスワード、または SSL 証明書を通じて実行できます。ログイン認証に合格した後、サーバーはクライアントに特定のクエリを実行する権限があるかどうかも検証します。
2. 2 番目の層は、クエリの解析を担当します。
SQL のコンパイルと最適化 (テーブルの読み取り順序の調整、適切なインデックスの選択など) 。)。 SELECT ステートメントの場合、クエリを解析する前に、サーバーはまずクエリ キャッシュをチェックします。対応するクエリ結果がその中に見つかった場合は、クエリの解析や最適化などを必要とせずに、クエリ結果が直接返されます。ストアド プロシージャ、トリガー、ビューなどはすべてこの層に実装されます。
3. 3 番目の層はストレージ エンジンです。
ストレージ エンジンは、MySQL へのデータの保存、データの抽出、トランザクションの開始などを担当します。ストレージ エンジンは API を介して上位層と通信し、これらの API は異なるストレージ エンジン間の差異を保護し、上位層のクエリ プロセスに対してこれらの差異を透過的にします。ストレージ エンジンは SQL を解析しません。
以上がMySQL の 3 層論理アーキテクチャとは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。