
ホームページ >データベース >mysql チュートリアル >Mysql Innodb ストレージ エンジンのインデックスとアルゴリズムの分析例
Mysql Innodb ストレージ エンジンのインデックスとアルゴリズムの分析例

- 王林転載
- 2023-06-03 12:44:13978ブラウズ
1. 概要
インデックスが少なすぎるとクエリ効率が低くなり、インデックスが多すぎるとプログラムのパフォーマンスに影響が出るため、インデックスの使用は実際のパフォーマンスと一致する必要があります。状況。
Innodb は次のようなインデックスをサポートします:
逆インデックスを使用した全文検索
ハッシュ インデックス、適応型、人的介入なし、ベースで作成バッファー プール内のクラスター化インデックス ページ上で実行され、テーブル全体がハッシュされないため、インデックスの作成が非常に高速になります。
B ツリー インデックス (従来の意味でのインデックス) は、現在、リレーショナル データベースで最も効果的で一般的に使用されているインデックスです。
B ツリーはテーブル上の特定の行レコードを見つけることができませんが、行レコードが配置されているページを返します。最終的に、行レコードはスロット情報に基づいてメモリに保存され、行レコードヘッダー、正確な位置決めのための次のレコード情報。
2. データ構造とアルゴリズム
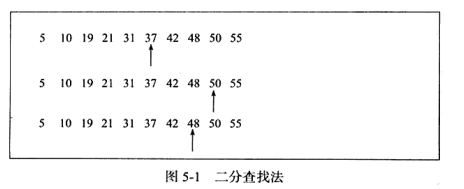
1. 二分検索
二分検索は順序付けられた線形データのセットを検索する場合にのみ使用でき、それぞれの中央値が取得されます。時間、小さく前進、大きく後退。以下の図に示すように、順序付けされた配列で数値 48 を見つける時間計算量は log N です。
2. 二分探索木と平衡二分木
1) 二分探索木
二分探索木とは、二分探索木を指します。二分探索木では、任意のノードの左の子ノードがそれ自体より小さく、任意のノードの右の子ノードがそれ自体より大きいという条件が満たされます。
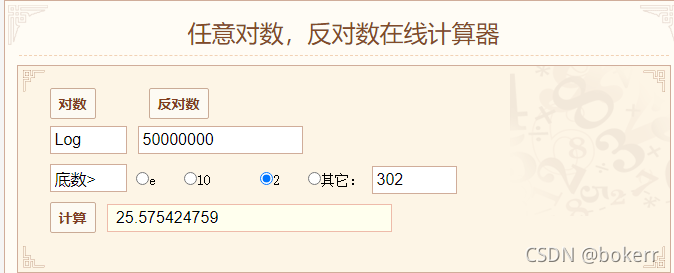
通常のバイナリ ツリーでは、O(logN) アクセス時間を保証できません。これは、極端な場合にはリンク リストにまで縮退する可能性があるためです。
二分木を構築するために順序付けされたデータの集合を構築すると、リンク リストが得られますが、このときの時間計算量は次のようになります。
#2) バランス型バイナリ ツリー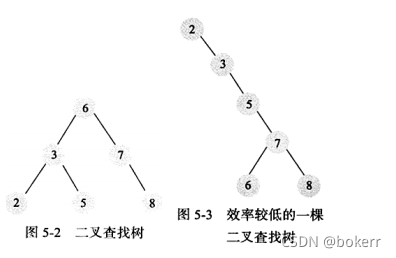
O(logN) のアクセス時間を保証できますが、データベースのインデックス作成には適していません: 
[木の高さは切り上げられた対数値です。例: log3 = 1.58、木の高さは 2;]
バランスの取れたバイナリ ツリーには制限があるため、B ツリーを導入する必要があります。
B ツリーは、ディスクやその他の直接アクセス補助デバイス用に特別に設計されたバランス型検索ツリーです。B ツリーでは、すべてのレコード ノードが、レコードのサイズに応じて同じ層のリーフに順番に格納されます。キーの値 ノードは各リーフ ノード ポインタによってリンクされます。
M 次の B ツリーは次の特性を満たす必要があります:除算に関する以下のすべての定義2 つの数値のうち、割り切れない場合は、小数点以下を切り捨てずに切り上げます。 (この場合の不等式の推定を除く)1) データ項目はリーフ ノードに存在する必要があります2) 非リーフ ノードには、検索方向を示す M-1 個のキーワードが格納されます。キーワード i は を表します。非リーフ ノードの i 番目のサブツリー内の最小のキーワード。5 次の B ツリーを想定すると、5 - 1 = 4 つのキーワードがあります。 3) B ツリーには、ルート ノードとしてリーフ ノードが 1 つだけあります (子ノードはありません)。子ノードがある場合、そのノードの数はセットに属している必要があります: {2~M}。 4) ルートを除き、すべての非リーフ ノードの子ノードの数は、セットに属することを満たさなければなりません: { M/2, M }; 5) すべて葉は同じ深さにあり、葉ノードのデータ項目は次のとおりです。番号はセットに属している必要があります: { L/2, L }; 2. M と L1. B ツリーの完全な定義
# の選択されたケース## すべてのフィールドの合計長が 500 バイトを超えず、主キーが 50 バイトであると仮定します。たとえば、行レコード自体が占めるスペースを含む B ツリーをシミュレートして導出します。
すべての行レコードは、可変長フィールド、行レコード ヘッダー、トランザクション ID、ロールバック ポインターなどの行情報を記録するためにいくつかのバイトを消費することが知られています。
create table context( id varchar(50) primary key, name varchar(50) not null, description varchar(360) );
A リーフ ノードはデータ ページを表し、M 値と L 値の選択はそれに密接に関連しています。データ ページ サイズが P/バイトであると仮定します (この記事で説明した MySQL を使用します)。例として、データ ページのサイズは 16K、つまり 16384 バイトです。)
非リーフ ノード: B ツリーのキーが主キーです。この例では、次のように仮定されています。主キーは 50 バイトで、M 次 B ツリーのキーは M -1 で、占有量: 50 * (M - 1) バイトのスペース;
と M を指すその分岐ポインタ子ノードの場合、各ブランチ ポインターが 4 バイトのストレージを占有すると仮定すると、非 In リーフ ノードの合計スペース消費量は、50 * (M - 1) 4 * M = 54M - 50 バイトとなります。
MySQL を使用し、主キーが 50 バイトであると仮定すると、不等式が成立します: 54M - 50
リーフノードでは、既知のテーブルに定義されている各行の最大容量は500バイトであり、このときL * 500
以下に示すように、現時点では 5000 W のデータがあり、ツリーの高さは 3 より大きいため、データを見つけるために必要なディスク IO は最大 4 つだけであることを意味します。
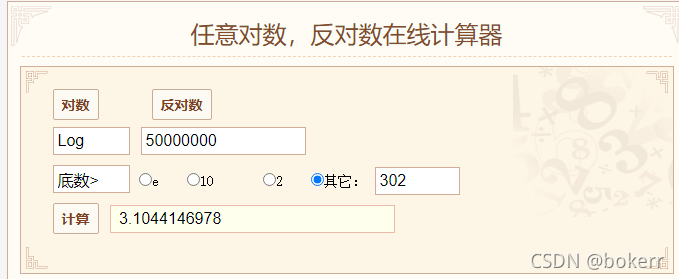
以下の図を参照してください。バランスの取れたバイナリ ツリーの最悪の時間限界は、1.44 * logN = 25.58 * 1.44 = 36.83、つまり、5000W データの場合です。バランスのとれたバイナリ ツリーを使用します。ツリーの最悪の制限時間です。最悪の場合、ディスク IO 時間は 36 回を超え、少なくとも 26 回になります。
図は 5 次の通常の B ツリー (M = 5) を示しており、各ノードは最大 5 つの値 (L = 5) を持ちます。上記の分析のように、等しくなければなりません。M と L は実際の状況によって異なります。
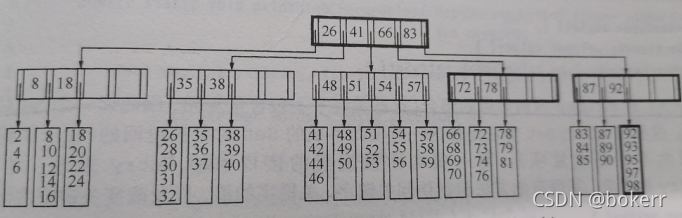
#あはは、絵を描くのは面倒ですね。写真は『データ構造とアルゴリズム分析』という本から撮ったのですが、私と同じくらい機知に富んでいます。
ここでは、B ツリーの定義とパラメータ選択の詳細についてのみ説明し、B ツリーの挿入と削除については詳しく説明しません。
4. B ツリー インデックス
通常、B ツリーの高さは 2 ~ 4 レベル、つまり、行レコードを検索する場合、通常 2 ~ 4 のディスク IO しかかかりません。行レコードが配置されている場所を見つけるのに何回もかかります。クラスター化インデックス、非クラスター化インデックスに関係なく、内部は高度にバランスが取れており、インデックス データはリーフ ノードに格納されますが、クラスター化インデックスのリーフ ノードには行レコード データ全体が格納される点が異なります。
1. クラスター化インデックス
クラスター化インデックスのリーフ ノードにはデータの行全体が格納され、各テーブルにはクラスター化インデックスを 1 つだけ含めることができます。
2. 補助インデックス
補助インデックスのリーフ ノードには、キー値とブックマークが格納され、これにより、Innodb ストレージ エンジンに、対応する行レコードの完全なデータを検索する場所が指示されます。索引。
各テーブルには複数の補助インデックスを持つことができます
補助インデックスの 1 つの欠点インデックスは離散的である必要があるため、セカンダリ インデックスに格納されているブックマークが見つかった場合でも、クラスター化インデックスは完全な行データを取得します。
5. カーディナリティ値について
カーディナリティの説明は非クラスター化インデックスに基づいており、各非クラスター化インデックスにはカーディナリティ値があります。
1. カーディナリティの定義
クエリ条件内のすべての列にインデックスを付ける必要があるわけではないことに注意してください。たとえば、値の範囲が小さく、性別、年齢、性別などの分布が密な辞書などです。索引付けは必要ありません。
カーディナリティは、インデックス内の一意のレコードの推定数を表します。一般的に: カーディナリティ / テーブル内のレコード行数は、できる限り 1 に近い値である必要があります。これが非常に小さい場合は、インデックスを次のようにする必要があるかどうかを検討する必要があります。削除されました。 (この値はクラスター化インデックスでは 1 に近い必要があり、議論の値はありません)。
2. カーディナリティの更新
MySQL では、各ストレージ エンジンが異なる方法で B ツリー インデックスを実装するため、カーディナリティ統計はストレージ エンジン層で実装されます。
テーブル内のデータ量が非常に大きい場合、カーディナリティの統計を実行するのは非常に時間がかかり、その統計は一般的にサンプリング手法を使用して実行されます。
カーディナリティの存在は、インデックスに意味があるかどうかを分析するのに役立ちます。
6. B ツリー インデックスの使用
[このセクションで説明するインデックスは主に補助インデックスを指し、クラスター化インデックスに対するクエリは一般にフル テーブル スキャンと呼ばれます。 。 】
1. ジョイント インデックス
ジョイント インデックスは、テーブル上の複数の列に基づいて構築されるインデックスであり、B ツリー構造でもあります。単一のインデックスとの唯一の違いは、には複数の列があります。
create table t ( a int, b int, primary key (a), key idx_ab (a, b) )engine=innodb;
上の表では、結合主キー idx_ab を設定し、その格納構造は次のとおりです。
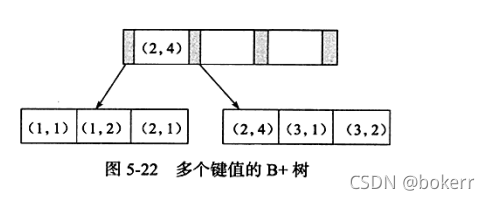
如上图所述,键值有序,需要注意的是,如下SQL可以使用该索引:
select * from t where a = ? and b = ? select * from t where a = ?
如下sql 不能使用该索引;查看示例图中联合索引叶子节点存放的数据我们可以发现:两个叶子节点上,关于字段b的存放显然不是有序的。
select * from t where b = ?
联合索引本身还有一个好处,辅助索引本身已经对第二个键值进行了排序,如下语句可以避免多一次的排序。
select b from t where a = ? order by b desc
辅助索引中已经对 b 列进行了排序,所以此时使用辅助索引更高效。
2、覆盖索引
Innodb 支持覆盖索引(covering index,或称为索引覆盖),即从辅助索引中就可以得到结果,而不需要查询聚集索引中的记录。由于辅助索引不包含完整的行记录,从而比聚集索引小很多,可以极大地减少IO操作。
再形如:select count(*) from table name where b = ? 的sql,如果有满足条件的辅助索引,它会优先使用辅助索引因为辅助索引体积远远小于聚集索引。
3、优化器选择不使用索引的情况
某些情况下,通过EXPLAIN指令会发现一些SQL,并没有选择使用满足条件的辅助索引去查数据,而是直接选择了全表扫描(聚集索引),这种情况一般发生于 范围查找、join链接操作等情况下。
当发生此类查找时,一般是查找一个较大范围内的数据,当范围较大时同样意味着大量的数据需要再进行一次书签访问去获取完整数据,已知顺序读取速度大于离散读取速度,所以此时不会使用辅助索引,而是直接查聚集索引(整表扫描)。一般情况下,当访问数据超过表中数据总数的20%时,索引覆盖不再适用,而需要进行全表扫描。)
create table t ( a int, b int, primary key (a,b), key idx_a (a) )engine=innodb;
如上定义表,a和b两列构成联合索引,列a上有独立的辅助索引,对于语句:
select * from t where a >= 3 and a<= 1000000;
按理说,该语句是可以选择使用辅助索引 idx_a 进行查找的,但是通过执行 explain 发现该语句发生了全表扫描(聚集索引),而不是使用辅助索引: idx_a。
4、索引提示
索引提示指MySQL支持在SQL中显式的告诉优化器使用哪个索引。
当优化器选择索引错误,可以手动指定索引。[极小概率事件]
当索引太多时,优化器选择索引的操作时间开销大,此时可以手动指定索引。
使用索引提示的前提是我们自己要对sql的执行非常了解,非常明确该操作能带来更好的效率。
5、Multi-Range Read 优化 (MRR)
MySQL5.6版本开始支持Multi-Range Read (MRR) 优化,它的目的是减少磁盘的离散读,将离散的访问优化为相对有序的访问,它使用于 range ref eq_ref 类型的查询。
1).MRR优化有如下好处:
它使得数据访问变得较为顺序,当根据辅助索引查询时,会将查询结果按照主键排序后,再去聚集索引进行书签查询。
减少缓冲池中页被替换的次数;
批量处理对键值的查询操作;
2).对于 JOIN 和 范围查询,Innodb 中MRR的工作方式为:
将通过辅助索引查询到的数据放到一个缓存中,此时这些数据是按照辅助索引键值排序的;
将缓存中的数据按照主键顺序排序;
根据主键顺序访问实际数据文件;
想象一下,在缓冲池不够大的情况下进行大范围数据查询,会导致数据页频繁被从LRU列表中移除。如果被查询的辅助索引不是按主键排序的,可能会多次发生如下的情况:一个页在同一次查询中被剔出LRU列表后又再次被加载出来。
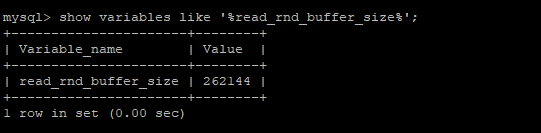
配置项:read_rnd_buffer_size 用来配置上述描述的键值缓冲区大小,默认为256K;当发生溢出时,执行器只对已经缓存的数据进行排序。
3).对于范围查询:MMR还支持对键值的拆分,将范围查询拆分为键值对进行批量的数据查询.
create table t ( a integer, b integer, primary key (a), key idx_ab (a, b) )engine=innodb;
select * from t where a = 50 and b>= 100 and b<= 20000
由于存在辅助索引 idx_ab,上述sql语句的条件可以拆分为键值对集合:{( 50 , 100 ),( 50 , 101 ),......,( 50 , 20000 )},这样就将范围查询优化为对键值对的查询;否则会进行范围查询,将 b ∈ {100,20000} 的所有数据都取出。
Multi-Range Read 是否启用,由如下参数中的,mrr 和 mrr_cost_based 标记进行控制,mrr标记是 MRR优化的开关。若前者设置为on,后者设置为off表示当满足条件时总是使用MRR优化;若前者设置为 on,后者也设置 on 表示通过 cost base 方式判断是否需要 MRR优化。

6. インデックス条件プッシュダウン最適化 (ICP)
ICP 最適化は、MySQL 5.6 以降でもサポートされており、インデックスに基づいてクエリを実行するための最適化方法です。 range、ref、eq_ref、ref_or_null タイプの最適化クエリをサポートします。
ICP が無効になっている場合、ストレージ エンジン層はインデックスを走査して完全な行レコードを見つけ、それをデータベース層 (サーバー層) に返して、次の where 条件を実行します。これらのデータ行はフィルタリングされます。
ICP が有効になっている場合、Where 条件でインデックスを使用できる場合、MySQL はフィルタリング操作のこの部分をストレージ エンジン層に配置します。ストレージ エンジンはインデックスをフィルタリングして、 where 条件を満たすデータ全体を取り出し、データをロウにして返します。 ICP を使用すると、ストレージ エンジン層が行レコードにアクセスする頻度を減らすことができ、同時にデータベース層 (サーバー層) がストレージ エンジンにアクセスする必要がある回数も減らすことができます。
[このフィルターを使用するための前提条件: フィルター条件はインデックスがカバーできる範囲である必要があります]
インデックス条件プッシュダウン動作原理は次のとおりです:
1) ICP が使用されない場合
(1) ストレージ エンジンは次の行を読み取るときに、補助インデックスのリーフ ノードから関連する行レコードを読み取ります。 、完全な行レコードをクエリするために、ブックマーク内の主キー参照がデータベース層 (サーバー層) に返されます。
(2) データベース層は、完全な行レコードに対して where 条件フィルタリングを実行します。行データが where 条件を満たす場合は使用され、そうでない場合は破棄されます。
(3) 条件を満たすデータを全て読み込むまで手順1を実行します。
2) ICP 使用時のインデックス スキャンの実行方法
(1) ストレージ エンジンはインデックスからデータを 1 つずつ読み取ります...
(2) ストレージエンジンがインデックスからデータを読み取るとき、where 条件を使用してインデックスのキーに基づいてフィルタリングします。行レコードが条件を満たさない場合、ストレージ エンジンは次のデータを処理します (前のステップに戻ります) )。クエリ条件が満たされた場合にのみ、完全なデータがクラスター化インデックスから読み取られます。
(3) 最後に、ストレージ エンジン層は、クエリ条件を満たすすべての完全な行レコードをデータベース層に返します。
(4) データベース層を使用し続けると、インデックスの対象外となる以降のクエリ条件がフィルタリングされます。
以上がMysql Innodb ストレージ エンジンのインデックスとアルゴリズムの分析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。