
ホームページ >データベース >mysql チュートリアル >MySQLデータベースでのインデックスの使用法は何ですか
MySQLデータベースでのインデックスの使用法は何ですか

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-03 11:18:572681ブラウズ
1. MySQL インデックスの概要
インデックスは、MySQL データベースがデータ クエリを高速化するためにテーブル内の 1 つまたは複数の列に追加する「ディレクトリ」です。 MySQL のインデックスは特殊なファイルですが、InnoDB 型エンジン (MySQL エンジンについては今後の記事で説明します) のテーブルのインデックスはテーブル空間の不可欠な部分です。
MySQL データベースでは、通常のインデックス、一意のインデックス、主キー インデックス、複合インデックス、全文インデックスの合計 5 種類のインデックスがサポートされていますが、以下ではこれら 4 種類のインデックスを 1 つずつ紹介します。
2. MySQL インデックス 5 種類の詳細説明
(1) Ordinary Index
Ordinary Index は、MySQL データベースの通常のインデックスです。通常のインデックス。データに特別な要件はありません。通常のインデックスの役割は、貧弱なクエリを高速化することです。
データ テーブルの作成時に共通インデックス SQL ステートメントを追加する例は次のとおりです。
create table exp(id int , name varchar(20),index exp_name(name));
または、次のようにインデックスをキーに置き換えます。
create table exp (id ,int , name varahcr (20) , key exp_name(name));
上記の SQL コマンドでは、キーまたはインデックスは、インデックスを追加することを意味し、その後にインデックス名が続き、その後にインデックスを追加するかっこ内の列が続きます。
この記事で紹介するインデックス関連の SQL 文はすべて、特別な指示がなければインデックスをキーに置き換えることができますが、記事の長さを節約するため、この点については今後繰り返しません。
また、インデックス名を指定せずにインデックスを追加することもできます。この場合、MySQL はフィールドと同じ名前のインデックス名を自動的にインデックスに追加します。
実行結果は以下の通りです:
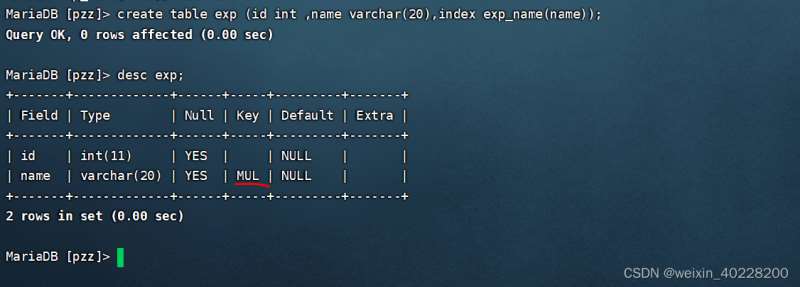
データテーブル作成後、テーブルに通常のインデックスを新規追加します SQL文の例は以下の通りです:
alter table exp add index exp_id(id);
実行結果は以下のとおりです。
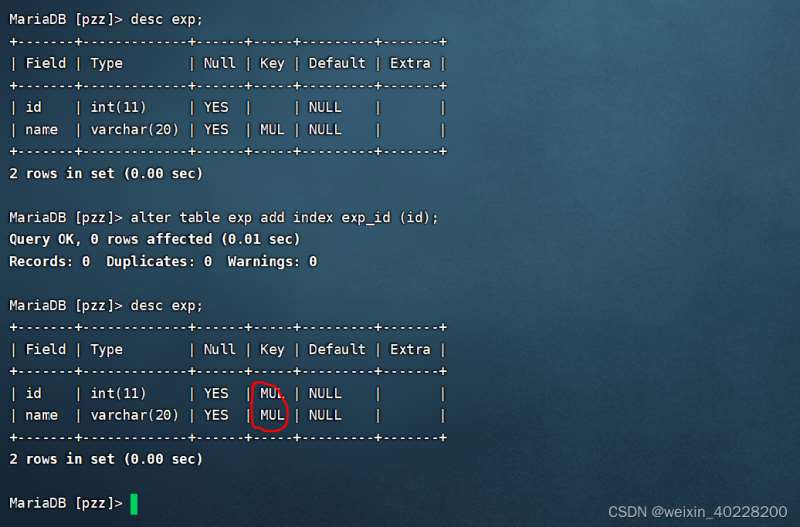
データテーブル作成後に共通インデックスを削除するSQL文の例は以下のとおりです。
alter table drop index exp_name;実行結果は次のとおりです:
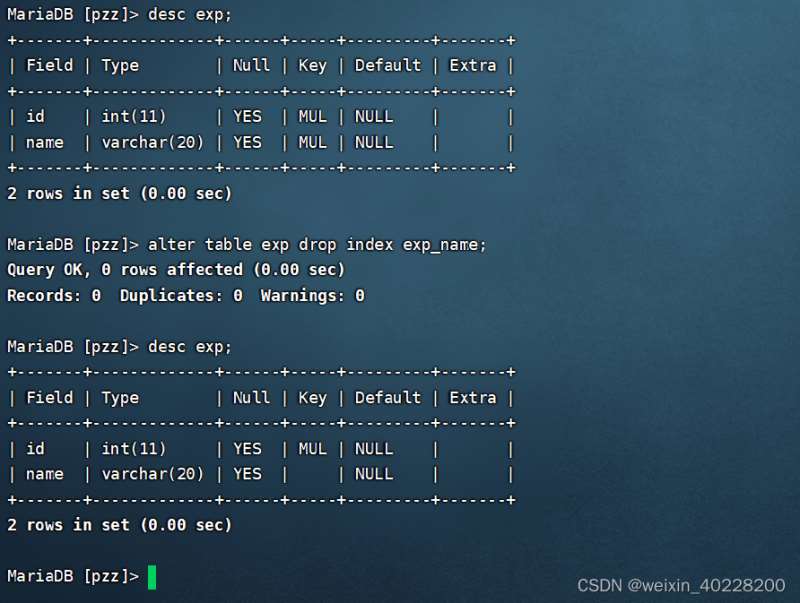
show index from exp;このうち、exp はテーブル名です。このコマンドの実行結果は次のとおりです:

一意のインデックスの追加は、通常のインデックスの追加とほぼ同じですが、通常のインデックスのキーワード キーとインデックスを一意のキーと一意のインデックスに置き換える必要がある点が異なります。
データテーブル作成時にユニークインデックスを追加するSQL文の例は以下のとおりです。
create table exp (id int, name varchar(20), unique key (name));上記コマンドの実行結果は以下のとおりです。
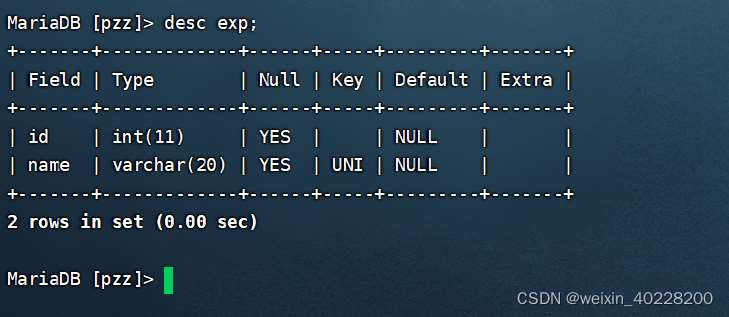
データテーブル作成後に一意のインデックスを追加するSQL文の例は次のとおりです。
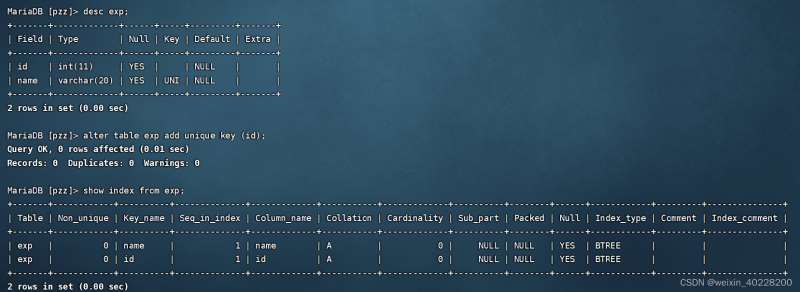
alter table exp drop index name;
実行結果は以下の通りです。
 (3) 主キーインデックス
(3) 主キーインデックス
主キーインデックスはクエリの中で最も高速です。データベース内のインデックスと各データ テーブルの主キー インデックス列は 1 つだけです。主キーによってインデックス付けされた列では、重複データや NULL 値は許可されません。
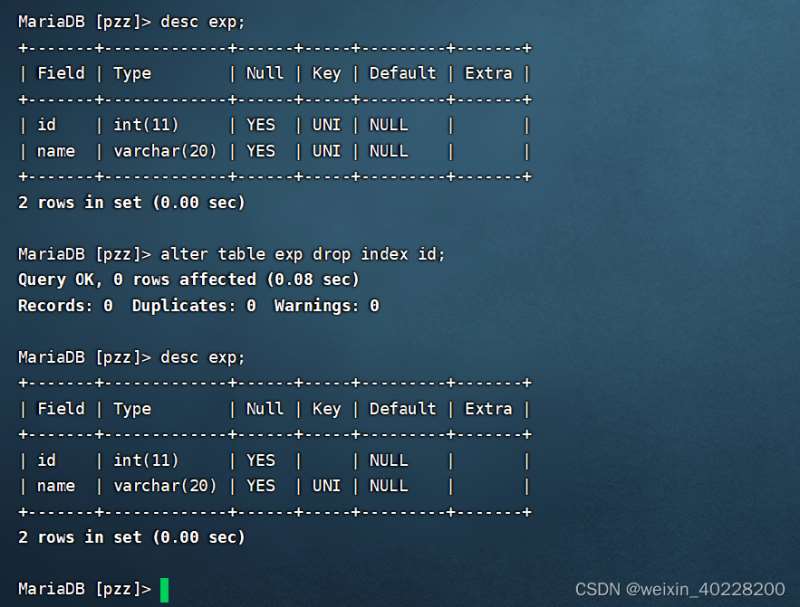
主キー インデックスの追加と削除は、キーが主キーに置き換えられる点を除けば、通常のインデックスや一意のインデックスと非常に似ています。関連する SQL コマンドは次のとおりです。create table exp(id int ,name varchar(20), primary key (id));alter table exp add primary key (id);
主キー インデックスの列を追加しました。次のように、desc でテーブル構造を表示すると、PRI がキー列に表示されます。
# #主キー インデックスを削除するには、次のコマンドを実行します。
alter table exp drop primary key;
この SQL ステートメントでは、キーをインデックスに置き換えることはできないことに注意してください。 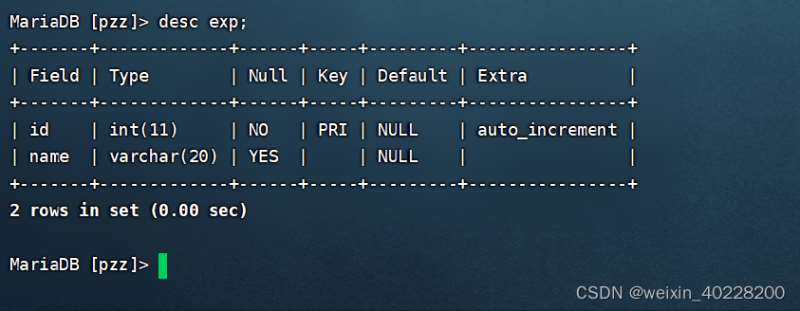 主キー インデックスを削除しようとすると、MySQL がそれを拒否する場合があります。これは、フィールドに auto_increment 属性が追加されていることが原因である可能性があります。次のように、フィールド修飾子を削除し、フィールドの主キー インデックスを削除できます。表示:
主キー インデックスを削除しようとすると、MySQL がそれを拒否する場合があります。これは、フィールドに auto_increment 属性が追加されていることが原因である可能性があります。次のように、フィールド修飾子を削除し、フィールドの主キー インデックスを削除できます。表示:
(四)复合索引
如果想要创建一个包含不同的列的索引,我们就可以创建符合索引。其实,复合索引在业务场景中应用的非常频繁,比如,如果我们想要记录数据包的内容,则需要将IP和端口号作为标识数据包的依据,这时就可以把IP地址的列和端口号的列创建为复合索引。复合、添加和删除索引创建SQL语句示例如下:
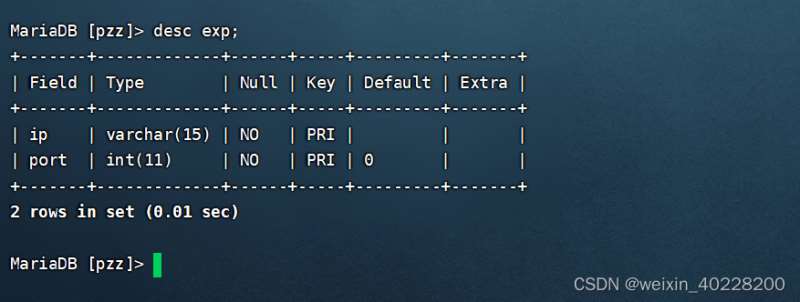
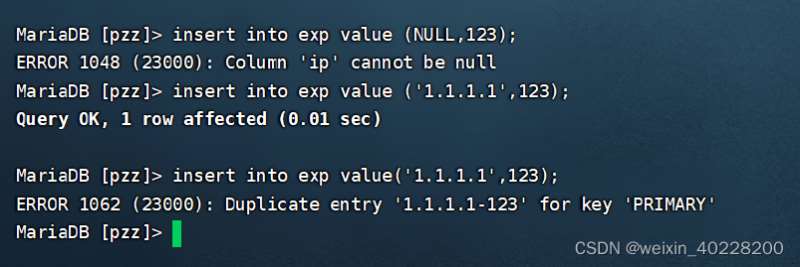
create table exp (ip varchar(15),port int ,primary key (ip,port)); alter table exp add pirmary key(ip ,port); alter table exp dorp priamary key;
复合索引在创建后,在使用desc查看数据表结构时,会在Key列中发现多个PRI,这就表示这些含有PRI的列就是复合索引的列了。如下所示:
注意,复合索引相当于一个多列的主键索引,因此,添加复合索引的任何一个列都不允许数据为空,并且这些列不允许数据完全相同,否则MySQL数据库会报错。如下所示:
(五)全文索引
全文索引主要是用于解决大数据量的情况下模糊匹配的问题。如果数据库中某个字段的数据量非常大,那么如果我们想要使用like+通配符的方式进行查找,速度就会变得非常慢。针对这种情况,我们就可以使用全文索引的方式,来加快模糊查询的速度。全文索引的原理便是通过分词技术,分析处文本中关键字及其出现的频率,并依次建立索引。全文索引的使用,与数据库版本、数据表引擎乃至字段类型息息相关,主要限制如下:
1、MySQL3.2版本以后才支持全文索引。
2、MySQL5.7版本以后MySQL才内置ngram插件,全文索引才开始支持中文。
3、MySQL5.6之前的版本,只有MyISAM引擎才支持全文索引。
4、MySQL5.6以后的版本,MyISAM引擎和InnoDB引擎都支持全文索引。
5、只有字段数据类型为char、varchar、以及text的字段才支持添加全文索引。
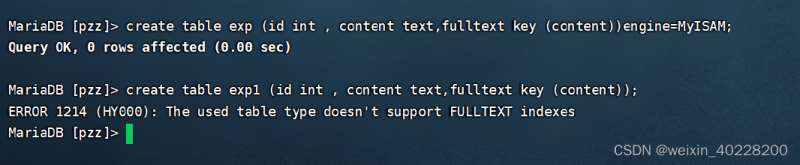
创建、添加以及删除全文索引SQL命令如下:
create table exp (id int ,content text ,filltext key (content))engine=MyISAM; alter table exp add fulltext index (content); alter table exp drop index content;
部分执行结果如下:
在创建了全文索引后,也不能够使用like+通配符的方式进行模糊查询,全文索引的使用有其特定的语法,如下所示:
select * from exp where match(content) against ('a');
其中,match后面的括号里是含有全文索引的字段,against后面的括号里是要模糊匹配的内容。
此外,全文索引的作用并不是唯一的,在很多场景下,我们并不会使用MySQL数据库内置的全文索引,而是使用第三方类似的索引以实现相同的功能。
三、MySQL索引使用原则
1、索引是典型的“以空间换时间”的策略,它会消耗计算机存储空间,但是会加快查询速度。
2、索引的添加,尽管加快了在查询时的查询速度,但是会减慢在插入、删除时的速度。因为在插入、删除数据时需要进行额外的索引操作。
3、索引并非越多越好,数据量不大时不需要添加索引。
4、如果一个表的值需要频繁的插入和修改,则不适合建立索引,反制,如果一个表中某个字段的值要经常进行查询、排序和分组的字段则需要建立索引。
5、如果一个字段满足建立唯一性索引的条件,就不要建立普通索引。
以上がMySQLデータベースでのインデックスの使用法は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。