
ホームページ >データベース >mysql チュートリアル >MySQL における一般的な高可用性アーキテクチャ導入ソリューションは何ですか?
MySQL における一般的な高可用性アーキテクチャ導入ソリューションは何ですか?

- 王林転載
- 2023-06-03 11:05:552392ブラウズ
MySQL のクラスター デプロイメント ソリューション
序文
MySQL で一般的に使用されるデプロイメント ソリューションについて話しましょう。
MySQL Replication
MySQL Replication は、公式に提供されているマスター/スレーブ同期ソリューションであり、ある MySQL インスタンスを別のインスタンスに同期するために使用されます。レプリケーションはデータのセキュリティを確保するための重要な保証を提供し、現在最も広く使用されている MySQL 災害復旧ソリューションです。レプリケーションでは、2 つ以上のインスタンスを使用して MySQL マスター/スレーブ レプリケーション クラスターを構築し、シングルポイント書き込みサービスとマルチポイント読み取りサービスを提供して、読み取りの スケールアウト を実現します。
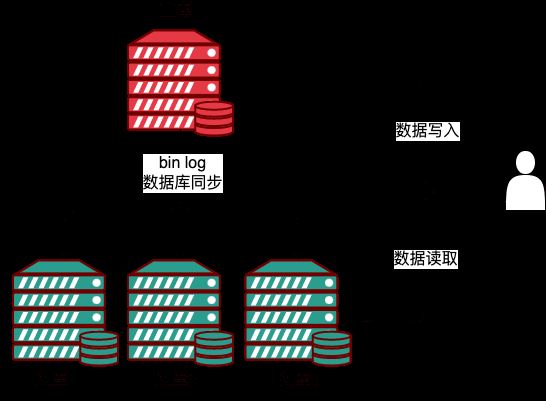
上記の図では、1 つのマスター ライブラリ (M) と 3 つのスレーブ ライブラリ (S) があり、マスターはレプリケーションを通じてイベントのバイナリログを生成し、送信します。スレーブは、イベントをリレーログに書き込んだ後、独自のデータベースに送信して、マスターとスレーブのデータ同期を実現します。
データベース上のビジネス レイヤーの場合、MySQL に基づくマスター/スレーブ レプリケーション クラスターには、マスターへの単一の書き込みポイントがあります。イベントがスレーブに同期された後、読み取りロジックは、どのサーバーからでもデータを読み取ることができます。スレーブから読み取り書き込み分離方式により、マスターの動作負荷が大幅に軽減され、スレーブのリソース使用率が向上します。
利点:
1. 読み取りと書き込みの分離による水平拡張を実現する機能。書き込みおよび更新操作はソース サーバーで実行され、データの読み取り操作はサーバーから実行されます。スレーブ サーバーの数を増やすと、データベースの読み取り能力が大幅に向上します。
2. データ セキュリティ。レプリカはレプリケーション プロセスを一時停止できるため、対応するソースを破壊することなくバックアップ サービスをレプリカ上で実行できます。データ;
3. データ分析に便利で、書き込みデータベースでリアルタイム データを作成でき、ソース データベースのパフォーマンスに影響を与えることなく、データ分析操作がスレーブ データベースで実行されます。
実装原理
マスター/スレーブ レプリケーションでは、スレーブ ライブラリはマスター ライブラリの binlog を使用して再生し、マスターとスレーブの同期を実現します。レプリケーション プロセス中、ダンプ スレッド、I/O スレッド、SQL スレッドが主に使用されます。 この 3 つのスレッドです。
IO スレッド: スレーブ ライブラリが start smile ステートメントを実行すると作成され、メイン ライブラリへの接続、バイナリ ログの要求、バイナリ ログの受信、およびリレーへの書き込みを担当します。 log;
dump thread: メイン ライブラリが binlog をスレーブ ライブラリに同期するために使用され、IO スレッドからのリクエストに応答する役割を果たします。メイン ライブラリは、スレーブ ライブラリ接続ごとに ダンプ スレッド を作成し、バイナリログをスレーブ ライブラリに同期します;
sql thread: read relay log コマンドを実行してスレーブデータを更新します。
レプリケーション プロセスを見てみましょう:
1. マスター ライブラリは更新コマンドを受け取り、更新操作を実行し、バイナリ ログを生成します;
2.スレーブ ライブラリはマスターとスレーブの間にあります長い接続を確立します;
3. メイン ライブラリ dump_thread はローカルからバイナリを読み取り、それをスレーブ ライブラリに転送します;
4. スレーブ ライブラリメイン ライブラリからバイナリ ログを取得してローカルに保存し、relay log (リレー ログ);
5 になります。sql_thread スレッドは relay log を読み取り、解析して実行しますデータを更新するコマンド。
ただし、MySQL レプリケーションには、マスターとスレーブの同期遅延という重大な欠点があります。
データはマスターとスレーブの間で同期されるため、マスターとスレーブの同期遅延が発生します。
マスター/スレーブ遅延はなぜ発生しますか?
1. スレーブ データベース マシンのパフォーマンスはメイン データベースのパフォーマンスより悪い;
2. スレーブ データベースは大きなプレッシャーにさらされている;
クエリがスレーブ データベースに配置されるため、スレーブ データベースが停止する可能性があります。ライブラリは大量の CPU リソースを消費し、同期速度に影響を及ぼし、マスターとスレーブの遅延を引き起こします。
3. 大規模なトランザクションの実行;
トランザクションが発生すると、メイン ライブラリはトランザクションが完了するまで待ってから、トランザクションをバイナログに書き込む必要があります。実行されるのは非常に大きなデータ挿入であり、これらのデータはスレーブ データベースに送信され、スレーブ データベースからこれらのデータを同期するには一定の時間がかかり、スレーブ ノードでデータ遅延が発生します。
4. スレーブ ライブラリのレプリケーション能力が低い;
スレーブ ライブラリのレプリケーション能力がマスター ライブラリのレプリケーション能力よりも低い場合、マスター ライブラリの書き込み圧力が高くなる可能性があります。スレーブ ライブラリに長時間のデータ遅延が発生する原因となります。 ######の解き方?
1. ビジネス ロジックを最適化して、マルチスレッドの大規模トランザクションによる同時実行シナリオを回避します。
2. スレーブ ライブラリのマシン パフォーマンスを向上させ、バイナリを書き込むメイン ライブラリとバイナリ ライブラリの効率の差を削減します。スレーブ ライブラリはバイナリを読み取ります。;
3. ネットワーク遅延によるバイナリ送信遅延を避けるために、メイン ライブラリとスレーブ ライブラリ間のネットワーク接続を確認します。;
4. メイン ライブラリを強制的に読み取ります。 ;
5. 半同期半同期レプリケーションと連携する;
半同期半同期レプリケーション
MySQL には 3 つの同期モードがあります。
1. 非同期レプリケーション: MySQL レプリケーションのデフォルトは非同期です. マスター ライブラリは、クライアントによって送信されたトランザクションの実行直後に結果をクライアントに返し、スレーブ ライブラリがそれを受信して処理したかどうかは気にしません。問題は、マスター データベースのログが時間内にスレーブ データベースに同期されず、マスター データベースがダウンすると、フェイルオーバーが実行され、スレーブ データベースからマスターが選択されることです。選択されたマスター データベースのデータは、不完全な可能性があります;2. 完全同期レプリケーション: メイン ライブラリがトランザクションを完了し、すべてのスレーブ ライブラリもトランザクションを完了するまで待機すると、メイン ライブラリがトランザクションを送信してデータをクライアントに返すことを意味します。データを返す前に、すべてのスレーブ データベースがマスター データベースのデータと同期されるまで待つ必要があるため、マスターとスレーブのデータの整合性は保証されますが、データベースのパフォーマンスは必然的に影響を受けます。
3. 半同期レプリケーション: 完全同期および完全非同期同期の 1 つであり、メイン ライブラリは、少なくとも 1 つのスレーブ ライブラリが受信してリレー ログに書き込むまで待機する必要があります file. メイン ライブラリは、すべてのスレーブ ライブラリがメイン ライブラリに ACK を返すのを待つ必要はありません。メイン ライブラリはトランザクションが完了したことを示す ACK を受信し、データをクライアントに返します。
MySQL 5.5 以降、MySQL はプラグインの形式で準同期準同期レプリケーションをサポートします。
リレー ログ を書き込んだ後、データをディスクに書き込み、マスター ライブラリに ACK を返します。マスター ライブラリがこの ACK を受信した場合にのみ、スレーブ ライブラリへのトランザクションの完了を確認できます。クライアント。
MySQL 5.7 では強化された半同期レプリケーションが導入されました。マスター ライブラリは、binlog にデータを書き込んだ後、少なくとも 1 つのスレーブ ライブラリが Relay Log を書き込み、データをディスクに書き込んでから ACK を返すまで、スレーブ ライブラリからの応答 ACK を待ち始めます。マスター ライブラリに送信してマスターに通知します。ライブラリはコミット操作を実行でき、メイン ライブラリはトランザクション エンジンにトランザクションを送信します。その後、アプリケーションはデータの変更を確認できます。
MySQL グループ レプリケーション グループ レプリケーション。MGR とも呼ばれます。これは、2016 年 12 月に Oracle MySQL によって開始された新しい高可用性および高スケーラビリティのソリューション MySQL 5.7.17 です。
(N / 2 1) によって解決および承認される必要があります。提出することができます。
write set を調べて比較することによって検証されます。これは認証と呼ばれるプロセスです。認証中、競合検出は行レベルで実行されます。異なるグループ メンバーで実行された 2 つの同時トランザクションが同じデータ行を更新すると、競合が存在します。競合認証検出メカニズムに従って、最初に送信されたトランザクションは通常どおり実行され、2 番目に送信されたトランザクションはトランザクションが開始された元のグループ メンバーでロールバックされ、グループ内の他のメンバーがトランザクションを削除します。 2 つのトランザクションが頻繁に競合する場合は、ローカル ロック マネージャーの調整の下で正常にコミットできるチャンスが得られるように、同じグループ メンバーで 2 つのトランザクションを実行することが最善です。異なるグループ メンバー間で認証が競合するため、頻繁にロールバックされます。
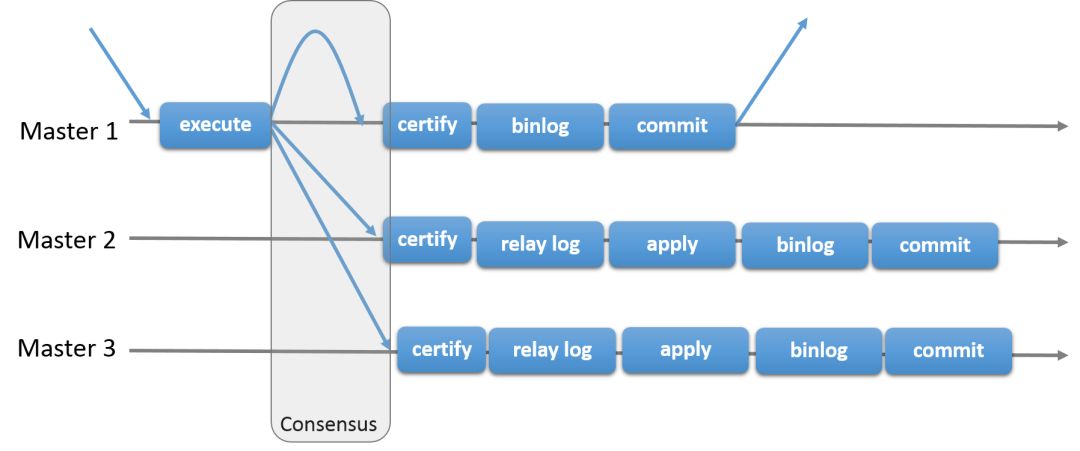
2. データの一貫性の保証: MGR には非常に優れた冗長機能があり、Binlog Event が少なくとも半数を超えるメンバーにレプリケートされることを保証できます。同時にダウンすると、このようなことは起こらず、データが失われます。また、MGR は、Binlog イベント がメンバーの半数以上に送信されない限り、ローカル メンバーがトランザクションの Binlog イベント を Binlog ファイルに書き込まないようにします。トランザクションをコミットすることで、ダウンしたサーバーにはオンライン メンバーに存在しないデータがグループ上に存在しないことが保証されます。したがって、ダウンしたサーバーが再起動された後、グループに参加するための特別な処理は必要なくなります;
3. マルチノード書き込みサポート: マルチ書き込みモードでは、クラスター内のすべてのノードに書き込みできます。
グループ レプリケーションのアプリケーション シナリオ
1. エラスティック レプリケーション: MySQL サーバーの数を動的に増減する必要がある、非常に柔軟なレプリケーション インフラストラクチャを必要とする環境。サーバーは動的に増減する必要があり、その過程でのビジネスへの副作用はできるだけ少なくする必要があります。例: クラウド データベース サービス;
2. 高可用性シャーディング: シャーディングは、書き込み拡張を実現する一般的な方法です。グループ レプリケーションに基づく高可用性シャーディング。各シャードはレプリケーション グループにマッピングされます (論理的には 1 対 1 の対応が必要ですが、物理的には、レプリケーション グループは複数のシャードをホストできます)。
3.マスター/スレーブ レプリケーション: マスター データベースを使用すると、単一競合が発生する場合があります。一部のシナリオでは、グループの複数のメンバーに同時にデータを書き込むことで、アプリケーションのスケーラビリティを向上させることができます
4. 自律システム: グループ レプリケーション、データ アトミック ブロードキャストの組み込みの自動フェイルオーバーを使用できます。運用の自動化を実現するための、異なるグループ メンバー間の最終的なデータ整合性機能。
InnoDB Cluster
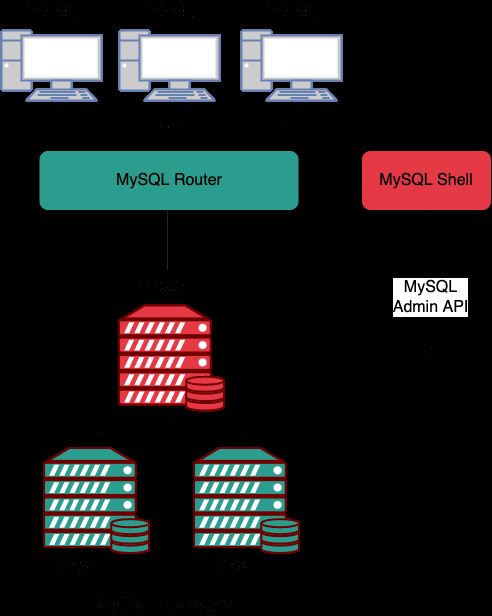
InnoDB Cluster は、公式の高可用性ソリューションであり、MySQL 用の高可用性 (HA) ソリューションです。MySQL グループ レプリケーション# を使用します。 ## 自動レプリケーションとデータの高可用性を実現するために、InnoDB Cluster には通常、次の 3 つの主要なコンポーネントが含まれています:
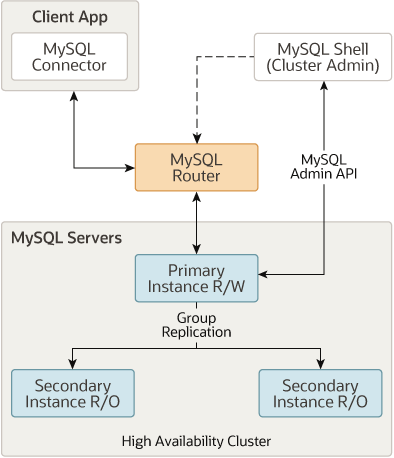 ##1、
##1、
: MySQL の高度な管理クライアントです。2、
、および MGR で MySQL## のセットを作成します # インスタンスMGR の場合、Innodb Cluster は MGR を処理するためのよりプログラム可能な方法を提供し、3、MySQL Router
MySQL Server
MySQL グループ レプリケーション 上に構築されており、自動メンバー管理、フォールト トレランス、自動フェイルオーバー機能などを提供します。 InnoDB Cluster 通常は、1 つの読み取り/書き込みインスタンスと複数の読み取り専用インスタンスを備えたシングルマスター モードで実行されます。ただし、マルチマスター モードを選択することもできます。 利点:
MySQL グループ レプリケーション
を通じて、InnoDB Cluster はクラスター内のデータの自動レプリケーションを実現できるため、データの可用性; 2. シンプルで使いやすい: InnoDB Cluster
3. 完全自動フェイルオーバー: InnoDB Cluster
欠点:
InnoDB Cluster
のデプロイと管理は比較的複雑で、MySQL の動作原理をある程度理解する必要があります;2. パフォーマンスへの影響: 自動レプリケーションと高可用性の要件により、InnoDB Cluster
3. 制限事項: InnoDB Cluster
InnoDB ClusterSet
MySQL InnoDB ClusterSet
プライマリInnoDB Cluster をバックアップ場所 (別のデータなど) にある 1 つ以上のレプリカに接続することによってcenter) 相互にリンクされて、InnoDB Cluster デプロイメントに災害復旧機能を提供します。 InnoDB ClusterSet
InnoDB ClusterSet の機能: 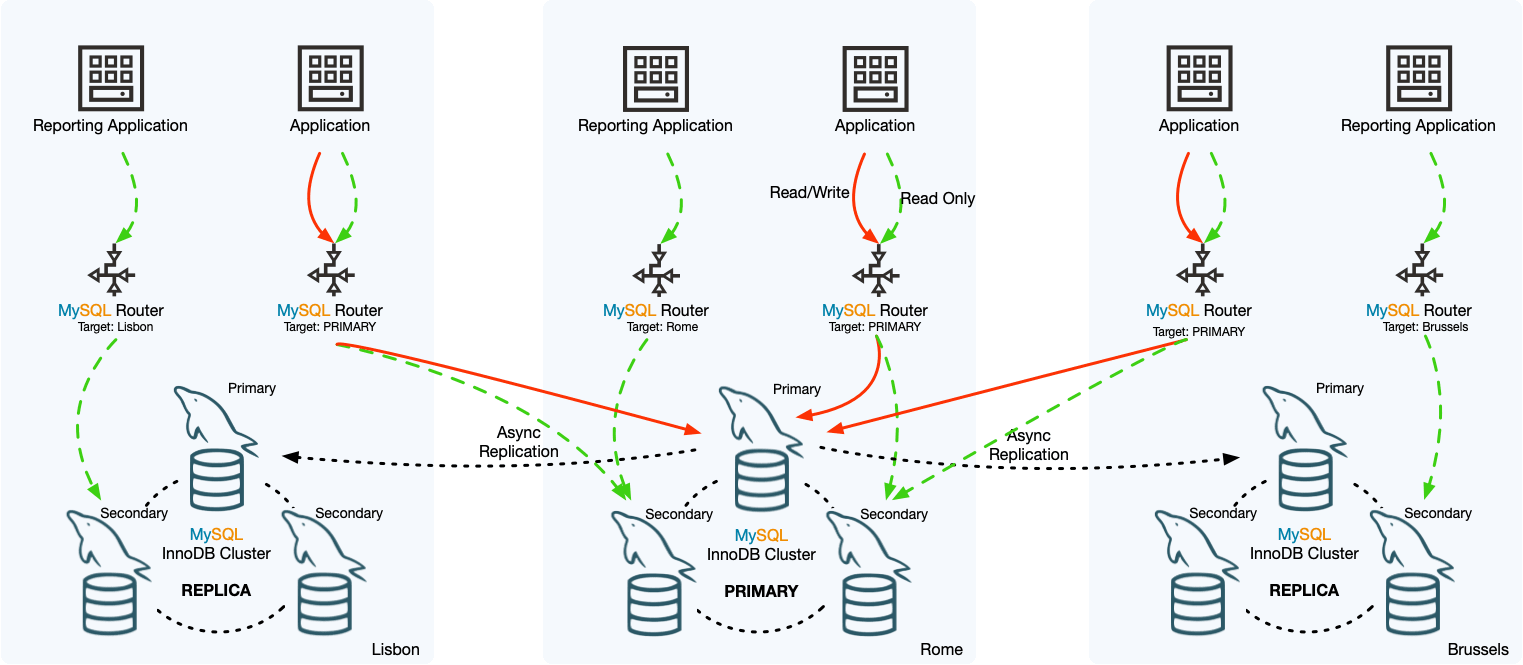
MySQL Shell を通じて実行できます。
、操作には AdminAPI を使用します;2. InnoDB ClusterSet デプロイメントで所有できるレプリカ クラスターの数に定義された制限はありません;
3. 非同期レプリケーション チャネルは、プライマリ クラスターからレプリカ クラスターにトランザクションをレプリケートします。 clusterset_replication InnoDB ClusterSet 作成プロセス中に、ClusterSet という名前のレプリケーション チャネルが各クラスタにセットアップされ、クラスタがレプリカの場合は、このチャネルを使用してプライマリからトランザクションをレプリケートします。集まる 。基盤となるグループ レプリケーション テクノロジはチャネルを管理し、レプリケーションが常にマスター クラスターのマスター サーバー (送信者として) とレプリカ クラスターのマスター サーバー (受信者として) の間で行われるようにします。
クラスター、メイン クラスターのみが書き込みリクエストを受信でき、ほとんどの読み取りリクエスト トラフィックもメイン クラスターにルーティングされますが、他のクラスターへの読み取りリクエストを指定することもできます; 制限事項InnoDB ClusterSet の:
1. InnoDB ClusterSet は非同期レプリケーションのみをサポートし、半同期レプリケーションは使用できず、非同期レプリケーションの欠点 (データ遅延、データ整合性など) は回避できません。
2. InnoDB Cluster Set はメイン モードの単一クラスタ インスタンスのみをサポートし、マルチマスター モードはサポートしません。つまり、含めることができるのは 1 つの読み取り/書き込みマスター クラスターのみであり、すべてのレプリカ クラスターは読み取り専用です。クラスターに障害が発生した場合にデータの整合性が保証されないため、複数のマスター クラスターを使用したアクティブ/アクティブ設定は許可されません。
3 、既存の InnoDB クラスターを InnoDB ClusterSet デプロイメントのレプリカ クラスターとして使用することはできません。新しい InnoDB クラスターを作成するには、レプリカ クラスターを単一のサーバー インスタンスから開始する必要があります
4。MySQL 8.0 のみをサポートします。
InnoDB ReplicaSet
InnoDB ReplicaSet は、ユーザーがマスター/スレーブ レプリケーションを迅速に展開および管理できるようにするために、2020 年に MySQL チームによって発売された製品です。 . マスタースレーブレプリケーション技術を採用しています。
単一のプライマリ ノードと複数のセカンダリ ノード (従来は MySQL レプリケーション ソースおよびレプリカと呼ばれていました) で構成されます。 InnoDB クラスター
MySQL Router は InnoDB ReplicaSet の起動をサポートしています。つまり、MySQL Router# は自動的に構成できます # # 手動構成ファイルを必要とせずに InnoDB ReplicaSet を使用します。これにより、InnoDB ReplicaSet は、MySQL レプリケーションを迅速かつ簡単に起動し、MySQL Router# で実行できるようになります ## 、InnoDB クラスターによって提供される高可用性を必要としないユースケースで読み取りをスケーリングし、手動フェイルオーバー機能を提供するのに最適です。
: 
#2. 予期せぬ停止または利用不能による部分的なデータ損失は防ぐことができません: 予期せぬ停止が発生した場合、未完了のトランザクションが失われる可能性があります;3 、予期しない終了または使用不能後の不整合を防ぐことができません。たとえば、ネットワークのパーティションが原因で、前のプライマリ インスタンスがまだ利用可能であるにもかかわらず、手動フェイルオーバーによってセカンダリ インスタンスが昇格される場合、スプリット ブレイン状況によりデータの不整合が発生する可能性があります;
4. InnoDB ReplicaSet はマルチをサポートしません。 -マスターモード。すべてのメンバーへの書き込みを許可する従来のレプリケーション トポロジでは、データの一貫性を保証できません;
5. 読み取りの水平方向の拡張は制限されています。
InnoDB ReplicaSetは非同期レプリケーションに基づいているため、
グループ レプリケーション;
6 のようにフロー制御を調整することはできません。ReplicaSet は最大 1 つのマスター インスタンスで構成されます。 1 つ以上の補助装置をサポートします。 ReplicaSet に追加できるセカンダリ ノードの数に制限はありませんが、ReplicaSet に接続されている各 MySQL Router は各インスタンスを監視する必要があります。したがって、ReplicaSet に追加されるインスタンスが増えるほど、より多くの監視が必要になります。 InnoDB ReplicaSets を使用する主な理由は、書き込みパフォーマンスが向上することです。 InnoDB ReplicaSets
InnoDB Cluster
ではできない、不安定または遅いネットワーク上でのデプロイメントが可能になることです。MMMMMM (MySQL 用マスター-マスター レプリケーション マネージャー) は、デュアルマスター フェイルオーバーとデュアルマスターの日常管理をサポートするスクリプト プログラムのセットです。 MMM は Perl 言語を使用して開発されており、主に MySQL Master-Master (デュアルマスター) レプリケーションの監視と管理に使用され、MySQL のマスター-マスター レプリケーション マネージャーと言えます。
#MMM はデータの一貫性を完全には保証できないため、データの一貫性要件がそれほど高くないシナリオに適しています。 (プライマリ サーバーとセカンダリ サーバー上のデータは必ずしも最新であるとは限らないため、スレーブ データベースよりも新しくない可能性があります。解決策: 準同期を有効にします)。
MMM の長所と短所
長所: 高可用性、優れたスケーラビリティ、障害時の自動切り替え、マスター間同期の場合、データの一貫性を確保するために同時に提供されるデータベース書き込み操作は 1 つだけです。
欠点: データの一貫性を完全に保証することはできません。障害の可能性を減らすために、半同期レプリケーションを使用することをお勧めします。現在、MMM コミュニティはメンテナンスが不足しており、GTID ベースのレプリケーションをサポートしていません。
適用可能なシナリオ:
MMM の適用可能なシナリオは、データベースのアクセス量が多く、ビジネスの成長が早く、読み取りと書き込みの分離が実現できるシナリオです。
MHA
MySQL 用のマスター高可用性マネージャーおよびツール (MHA と呼ばれます)。これは、MySQL 高可用性環境でのフェイルオーバーとマスター/スレーブの昇格のための優れた高可用性ソフトウェア セットです。
このツールは、メイン ライブラリのステータスを監視するために特別に使用されます。マスター ノードに障害があることが判明すると、新しいデータを持つスレーブ ノードが新しいマスター ノードになるように自動的に昇格します。この期間中、 、MHA は他のスレーブを渡します。ノードはデータの一貫性の問題を回避するために追加情報を取得します。 MHAはオンラインでMaster-Slaveノードを切り替える機能も提供しており、必要に応じて切り替えることができます。 MHA は、データの一貫性を最大限に確保しながら、30 秒以内にフェイルオーバーを実装できます。
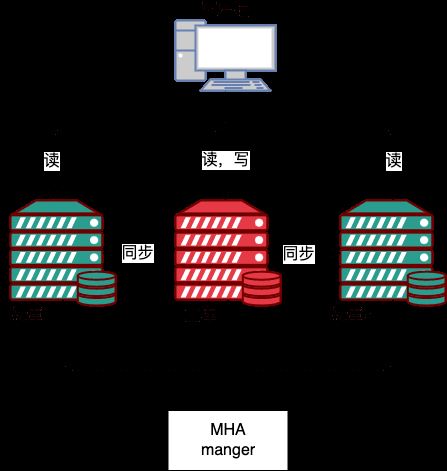
MHA は、
MHA Manager (管理ノード) と MHA Node (データ ノード) の 2 つの部分で構成されます。
MHA マネージャー は、独立したマシンにデプロイして複数のマスター/スレーブ クラスターを管理することも、スレーブ ノードにデプロイすることもできます。 MHA ノード 各 MySQL サーバー上で実行されている MHA マネージャー は、クラスター内のマスター ノードを定期的に検出します。マスターに障害が発生した場合、最新のデータを持つスレーブを新しいノードに自動的に昇格できます。 1. マスターに設定し、他のすべてのスレーブを新しいマスターにリダイレクトします。
フェイルオーバー プロセス全体は、アプリケーションに対して完全に透過的です。
MHA 自動フェイルオーバー プロセス中、MHA は、データが最大限失われないように、ダウンしたメイン サーバーからバイナリ ログを最大限に保存しようとしますが、これは常に実現できるわけではありません。たとえば、マスター サーバーのハードウェアに障害が発生した場合、または ssh 経由でアクセスできない場合、MHA はバイナリ ログを保存できず、フェイルオーバーのみが行われ、最新のデータが失われます。
MySQL 5.5 を使用する データ損失のリスクを大幅に軽減できる、サポートされている半同期レプリケーションを探し始めます。 MHA は準同期レプリケーションと組み合わせることができます。 1 つのスレーブのみが最新のバイナリ ログを受信した場合、MHA は最新のバイナリ ログを他のすべてのスレーブ サーバーに適用できるため、すべてのノードでデータの一貫性が確保されます。
Galera Cluster は、Codership によって開発された MySQL マルチマスター クラスターであり、MariaDB に含まれており、Percona xtradb、MySQL、これは、データの整合性、スケーラビリティ、および高いパフォーマンスの点で許容可能なパフォーマンスを備えた、使いやすい高可用性ソリューションです。 #Galera Cluster
主な機能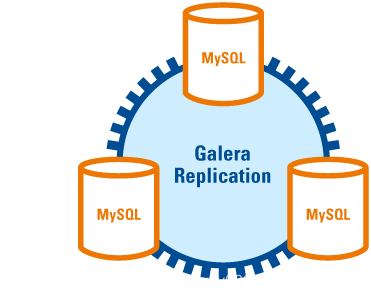
1. データの一貫性: 同期レプリケーションにより、クラスター全体のデータの一貫性が保証されます。どのノードでも同じ選択クエリが実行されるたびに、結果は同じになります。
2. 高可用性:すべてのノード上のデータに一貫性があり、単一ノードのクラッシュでは複雑で時間のかかるフェイルオーバーが必要なく、データ損失やサービス停止も引き起こされません;
3. パフォーマンスの向上: 同期レプリケーションによりトランザクションを実行できます。クラスター内のすべてのノードで並列処理が行われるため、読み取りおよび書き込みのパフォーマンスが向上します。
4、クライアントの遅延が小さくなります。
5、読み取りと書き込みの両方の拡張機能が備わります。
原理の分析
同期レプリケーションは主に Galera Cluster で使用されます. メイン データベースの 1 つの更新トランザクションは、すべてのスレーブ データベースで同期的に更新される必要があります。メイン データベースがトランザクションをコミットすると、クラスター内のすべてのノードのデータは一貫したままになります。
非同期レプリケーションでは、スレーブ データベースがデータ変更を正常に読み取るか再生するかどうかに関係なく、マスター データベースがデータの更新をスレーブ データベースに伝播し、すぐにトランザクションをコミットします。そのため、非同期レプリケーションでは、短期的にマスター データベースが保持されます。スレーブデータの同期に不整合が発生する状況が発生します。
ただし、同期レプリケーションの欠点も非常に明白です。同期レプリケーション プロトコルは、通常、2 フェーズ コミットまたは分散ロックを使用して、異なるノードの操作を調整します。また、ノードの数が増えると、より多くのノードを調整する必要があるため、トランザクションの競合やデッドロックが発生する可能性も高くなります。
MGR グループ レプリケーションの導入は、従来の非同期レプリケーションや準同期レプリケーションで発生する可能性があるデータの不整合の問題を解決するためでもあることはわかっています。MGR のグループ レプリケーションは Paxos プロトコルに基づいています。原則として、トランザクションの送信は主にほとんどのノードに対して行われ、ACK を送信できます。
Galera Cluster での同期 では、すべてのノードが確実に成功するように、すべてのノードにデータを同期する必要があります。独自の通信グループシステム GCommon に基づいて、すべてのノードが ACK を持っている必要があります。
Galera レプリケーションは、検証ベースのレプリケーションの一種です。検証ベースのレプリケーションでは、通信およびソート テクノロジを使用して同期レプリケーションを実現し、同時トランザクション間で確立されたグローバルな合計順序をブロードキャストすることでトランザクションの送信を調整します。簡単に言えば、トランザクションはすべてのインスタンスに同じ順序で適用される必要があります。
トランザクションはローカルで実行され、競合検証のために他のノードに送信されます。競合がない場合は、すべてのノードがトランザクションを送信します。競合がない場合、トランザクションはすべてのノードでロールバックされます。
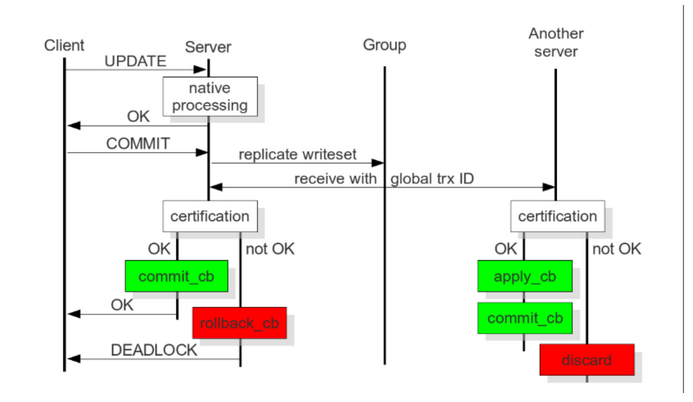
クライアントが commit コマンドを発行すると、実際のコミットの前に、データに加えられた変更が書き込みコレクションに収集されます。書き込みコレクションには、トランザクション情報とすべての変更が含まれます。行の主キーを取得すると、データベースは書き込みセットを他のノードに送信します。
ノードは、書き込みセット内の主キーと、現在のノード内の未完了のトランザクションのすべての書き込みセット内の主キーを比較して、ノードがトランザクションを送信できるかどうかを判断します。
1. 2 つのトランザクションは異なるノードから発生しています;
2. 2 つのトランザクションには同じ主キーが含まれています;
3. 古いトランザクションは新しいトランザクションからは見えません。つまり、古いトランザクションは完了まで送信されません。新しいトランザクションと古いトランザクションの区別は、グローバル トランザクションの合計順序、つまり GTID によって異なります。
各ノードは検証を独立して実行します。検証が失敗した場合、ノードは書き込みセットを削除し、元のトランザクションをロールバックします。すべてのノードが同じ操作を実行します。すべてのノードはトランザクションを同じ順序で受信するため、すべてのノードが同じ結果、つまりすべてが成功するかすべてが失敗するかの決定を下します。成功すると、それは自然に送信され、すべてのノードは再びデータの一貫性のある状態に達します。 「競合」に関する情報はノード間で交換されず、各ノードはトランザクションを独立かつ非同期に処理します。
MySQL Cluster
MySQL Cluster は、単一障害点のない分散アーキテクチャに基づいた、拡張性の高い ACID トランザクション互換のリアルタイム データベース MySQL Cluster は自動水平拡張をサポートし、自動読み取りおよび書き込みロード バランシングを実行できます。
MySQL Cluster は、NDB と呼ばれるインメモリ ストレージ エンジンを使用して、複数の MySQL インスタンスを統合し、統合されたサービス クラスターを提供します。
NDB は、Sharding-Nothing アーキテクチャを採用したメモリ ストレージ エンジンです。 Sarding-Nothing は、各ノードが独立したプロセッサ、ディスク、メモリを備えていることを意味します。ノード間に共有リソースはなく、完全に独立しており、相互に干渉しません。ノードはネットワークを通じてグループ化されています。各ノードは以下と同等です。小さなデータベース。何らかのデータを保存します。このアーキテクチャの利点は、ノードを分散してデータを並列処理することで全体のパフォーマンスが向上すること、水平拡張性能が高いことなどで、ノードを追加するだけでデータ処理能力を向上させることができます。
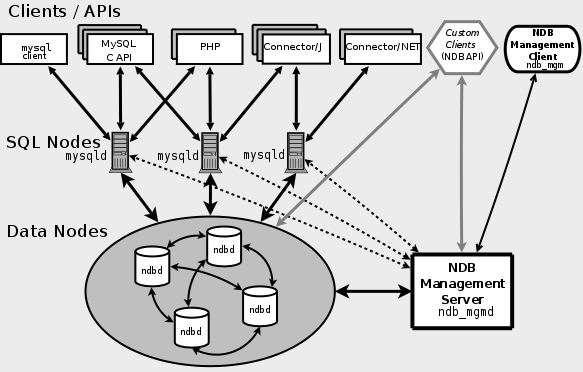
MySql Cluster には、管理ノード (NDB 管理サーバー)、データ ノード (データ ノード)、SQL クエリ ノード (SQL) という 3 種類のノードが含まれています。ノード)。
SQL ノード はアプリケーション プログラムのインターフェイスであり、通常の mysqld サービスと同様に、ユーザーの SQL 入力を受け入れ、実行して結果を返します。 データ ノードはデータ ストレージ ノードであり、NDB 管理サーバーはクラスター内の各ノードを管理するために使用されます。
データ ノードは、クラスター内のデータ パーティションとパーティションのコピーを保存します。MySql クラスター がデータに対してシャーディング操作を実行する方法を見てみましょう。まず、次の概念を理解しましょう
ノード グループ: データ ノードのコレクション。ノード グループの数 =ノード数/レプリカの数;
たとえば、クラスター内に 4 つのノードがあり、レプリカの数が 2 の場合 ( NoOfReplicas) の場合、ノード グループの数は 2 です。
さらに、可用性の観点から、データのコピーはグループ内で相互に分散されており、クラスター全体のデータの整合性を確保し、全体的なサービスの可用性を実現するために、ノード グループ内の 1 台のマシンのみが使用可能です。
パーティション: MySql Cluster は分散ストレージ システムです。データはパーティションに従って複数の部分に分割され、各データ ノードに保存されます。パーティションの数はシステムによって自動的に計算されます。パーティションの数 = データ ノードの数/LDM スレッドの数;
コピー (レプリカ): パーティション データのバックアップ。単一点を避けるために、複数のパーティションに複数のコピーが存在します。 、ensureMySql Cluster クラスターの高可用性を実現するために、元のデータに対応するパーティションとコピーは通常、異なるホストに保存され、ノード グループ内で相互バックアップされます。
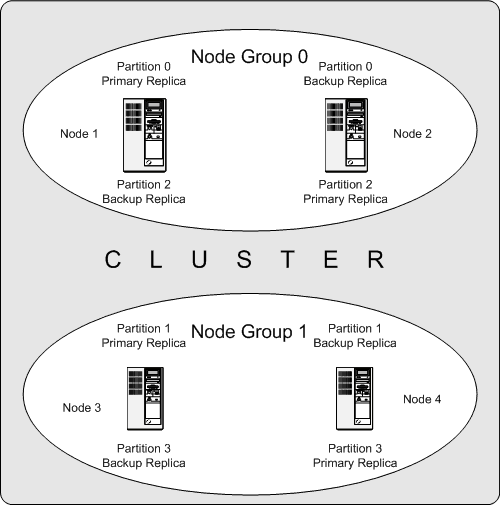
Li Ru、上記の例では、4 つのデータ ノード (ndbd を使用)、コピー数 2 のクラスターがあり、ノード グループは 2 つに分割されています。グループ (4/2) の場合、データは 4 つのパーティションに分割されます。 データの分散状況は次のとおりです:
パーティション 0 (パーティション 0) はノード グループ 0 (ノード グループ 0) に保存され、パーティションデータ (プライマリ レプリカ - プライマリ レプリカ) がノード 1 (node 1) に保存され、バックアップ データ (バックアップ レプリカ、バックアップ レプリカ) がノード 2 (node 2) に保存されます;
パーティション 1 (パーティション1)はノードグループ1(Node Group 1)に保存され、パーティションデータ(プライマリレプリカ - Primary Replica)はノード3(node3)に保存され、バックアップデータ(バックアップレプリカ、Backup Replica)はノード 4 (ノード 4) に保存;
パーティション 2 (パーティション 2) はノード グループ 0 に保存され、パーティション データ (プライマリ レプリカ - プライマリ レプリカ) はノード 2 (ノード 2) に保存されます)、バックアップ データ (バックアップ レプリカ、バックアップ レプリカ) はノード 1 (ノード 1) に保存されます。中;
パーティション 3 (パーティション 2) はノード グループ 1 (ノード グループ 1) に保存され、パーティション データ(プライマリレプリカ - Primary Replica) はノード 4 (node 4) に保存され、バックアップデータ (Backup Replica) はノード 3 (node 3) に保存されます;
このように、パーティションに対してテーブルの場合、クラスター全体にデータのコピーが 2 つあり、それらは 2 つの独立したノードに分散され、データのディザスター リカバリーが実装されます。同時に、パーティションへのすべての書き込み操作は 2 つのレプリカで実行されます。プライマリ レプリカが異常な場合、バックアップ レプリカがすぐにサービスを提供し、高データ可用性を実現します。
mysql クラスター 利点
1. 99.999% の高可用性;
2. 高速自動フェイルオーバー;
3. 柔軟な分散アーキテクチャ、単一障害点なし;
4. 高スループットと低遅延;
5. 強力なスケーラビリティ、オンライン拡張のサポート。
mysql クラスター 欠点
1. 外部キーはサポートされておらず、データ行は 8K を超えることはできません (BLOB とテキストのデータを除く) など、多くの制限があります。 ) ;
2. 導入、管理、構成は複雑です;
3. 多くのディスク領域とメモリを消費します;
4. バックアップとリカバリは、不便;
5. 再起動時、データノードがメモリにデータをロードするのに時間がかかります。
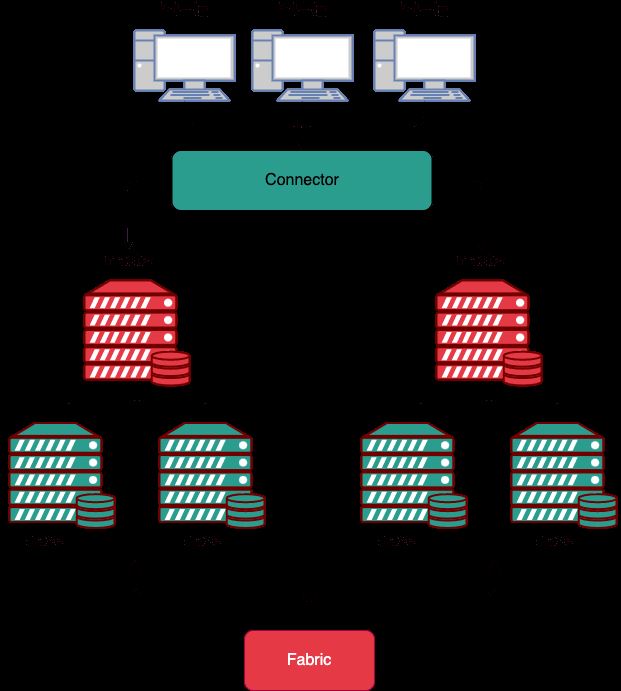
MySQL Fabric
MySQL Fabric は、複数の MySQL データベースを編成し、大規模なデータを複数のデータベースに分散します。つまり、データ シャーディング(データ シャード) , 同時に、同じシャード データベース内にマスターとスレーブの構造があり、ファブリックは適切なライブラリをマスター ライブラリとして選択します。マスター ライブラリに障害が発生した場合は、スレーブ ライブラリからマスター ライブラリを再選択します。
MySQL Fabric 機能:
1. 高可用性;
2. データ シャーディングを使用した水平機能。
MySQL ファブリック対応 コネクタは、MySQL ファブリック から取得したルーティング情報をキャッシュに保存し、この情報を使用してトランザクションまたはクエリを正しい MySQL に送信します。サーバ。
同時に、各シャーディング グループは複数のサーバーで構成され、マスター/スレーブ構造を形成することができます。マスター データベースがハングアップした場合、スレーブ データベースからマスター データベースが再度選択されます。ノードの高可用性を確保します。
HA グループは、指定された HA グループのデータに常にアクセスできるようにし、その基本的なデータ レプリケーションは MySQL レプリケーション## に基づいています。 # 。
以上がMySQL における一般的な高可用性アーキテクチャ導入ソリューションは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。