
サーバー障害インスタンスの分析

- 王林転載
- 2023-06-02 15:12:051340ブラウズ
1. 問題が発生しました
私たちはIT業界にいるので、毎日障害や問題に対処する必要があり、問題解決のために走り回っている消防士とも言えます。ただし、今回の障害の範囲は少し広く、ホストマシンを開くことができません。
幸いなことに、監視システムはいくつかの証拠を残しました。
マシンの CPU、メモリ、およびファイル ハンドルがビジネスの成長に伴って増加し続け、監視が情報を収集できなくなるまで増加し続けたという証拠が見つかりました。
恐ろしいのは、これらのホストに多数の Java プロセスがデプロイされていることです。コスト削減以外の理由で、アプリケーションは混在していました。ホストに全体的な異常が見られる場合、原因を見つけるのが難しい場合があります。
リモート ログインの有効期限が切れているため、せっかちな運用および保守担当者は、マシンを再起動し、再起動後にアプリケーションを再起動することしか選択できません。長い待機の後、すべてのプロセスは通常の動作に戻りましたが、ほんの短い時間の後、ホスト マシンが突然クラッシュしました。
ビジネスは衰退傾向にあり、本当に迷惑です。それは人々を不安にもさせます。数回の試行の後、運用と保守が崩壊し、緊急計画が開始されました。ロールバック!
最近のオンライン記録が大量にあり、一部の開発者がオンラインになって非公開でデプロイしたため、運用と保守が混乱しました。幸いなことに、誰かが素晴らしいアイデアを思いつき、 find コマンドがあることを思い出し、最近更新されたすべての jar パッケージを見つけてロールバックしました。
find /apps/deploy -mtime +3 | grep jar$
find コマンドを知らないと、本当に大変なことになります。幸いにも誰かが知っています。
十数個の jar パッケージをロールバックしましたが、幸いなことにデータベース スキーマの変更は発生せず、最終的にシステムは正常に動作しました。
2. 理由を見つけます
他に方法はなく、ログを確認してコード レビューを実施します。
コードの品質を確保するには、コード レビューの範囲を過去 1 週間または 2 週間のコード変更に限定する必要があります。これは、一部の機能コードは完成するまでにある程度の時間を必要とするためです。オンラインで輝きます。
画面いっぱいに表示された提出記録「OK」を見て、技術部長の顔が青くなった。
「xjjdog さんは、「プログラマーの 80% はコミット レコードを書けない」と言っていますが、皆さんの 100% はコミット レコードを書けないと思います。」
誰もが静かに痛みに耐えながら歴史の変遷を確認していました。全員のたゆまぬ努力の結果、ついにたわごとの山の中から問題のあるコードがいくつか見つかりました。 CxO 自身が作ったグループで、問題を引き起こす可能性のあるコードを全員がそこに投げ込みます。
「システム サービスは 1 時間近く中断され、影響は非常に悪かった。」CxO は、「問題は完全に解決する必要があります。投資家はこの問題を非常に懸念しています。」!
okokok, with Nail ネイルのおかげで、みんなのしぐさが均一になりました。
3. スレッド プールのパラメーター
コードはたくさんあり、問題のあるコードについてみんなで長い間議論しています。この文は次のように書き換えることができます。 スレッド プールの使用に特に注意を払い、並列ストリームを使用し、ラムダ式内でネストされたいくつかの複雑なコードを調べました。
最終的に、全員がスレッド プールのコードをもう一度検討することにしました。その一節にこんなことが書かれています。
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10), handler);
言うまでもなく、パラメータはまともであり、拒否戦略も考慮されています。
Java のスレッド プールを使用すると、プログラミングが非常に簡単になります。上の図に示すように、これらのパラメーターを 1 つずつ確認しないと確認できません。
corePoolSize: コア スレッドの数。コア スレッドは作成後も存続します。
maxPoolSize: スレッドの最大数
keepAliveTime: スレッドのアイドル時間
workQueue: ブロックキュー
threadFactory: スレッド作成ファクトリー
ハンドラー: 拒否戦略
両者の関係を以下に紹介します。
スレッドの数がコア スレッドの数より少なく、新しいタスクが到着した場合、システムはタスクを処理するための新しいスレッドを作成します。現在のスレッド数がコア スレッドの数を超えており、ブロッキング キューがいっぱいでない場合、タスクはブロッキング キューに配置されます。スレッドの数がコア スレッドの数より大きく、ブロッキング キューがいっぱいの場合、スレッドの数が maxPoolSize サイズに達するまで、新しいスレッドが作成されて処理されます。この時点で、新しいタスクがある場合、拒否ポリシーがトリガーされます。
拒否戦略について話しましょう。 JDK には 4 つの組み込みポリシーがあり、そのデフォルトは AbortPolicy で、直接例外をスローします。他にもいくつか紹介します。
DiscardPolicy は、abort よりも根本的なものです。例外情報も含めずにタスクを直接破棄します。
タスクの処理は、呼び出し元のスレッドによって実行されます。これが CallerRunsPolicy の実装方法です。 Web アプリケーションのスレッド プール リソースがいっぱいになると、新しいタスクが Tomcat スレッドに割り当てられて実行されます。場合によっては、このメソッドは一部のタスクの実行圧力を軽減できますが、多くの場合はメイン スレッドの実行を直接ブロックします
DiscardOldestPolicy はキューの先頭のタスクを破棄しますを実行してから、再度タスクを実行してみてください。
このスレッド プールのコードは新たに追加されたもので、パラメーターの設定も適切で、大きな問題はありません。 DiscardOldestPolicy 拒否ポリシーを使用することが唯一の可能性のあるリスクです。タスクが大量にある場合、この拒否ポリシーによりタスクがキューに入れられ、リクエストがタイムアウトになります。
もちろん、このリスクを手放すことはできませんが、正直に言うと、これはこれまでに見つかった中で最も可能性の高いリスク コードです。
"把DiscardOldestPolicy 改成預設的AbortPolicy吧,重新打包上線一下試試「。技術大牛在群組裡說。
4. 問題在哪裡?
結果,服務灰度上線之後,宿主機不多時,就死掉了。是它的原因沒跑了,但是why?
線程池的大小 ,最小100,最大200,說什麼也不過分。阻塞隊列的容量只有10,說什麼也不會造成問題。你要說是這個線程池造成的原因,打死我都不信。
但是業務部門回饋,這段程式碼加上就死,不加就沒事。技術大牛抓耳撓腮百思不得其姐。
到最後,終於有人忍不住了,下載下業務的程式碼打算調試一下。
當他打開Idea的時候,瞬間懵逼了,又瞬間領悟了。他終於明白這段程式碼為什麼會產生問題了。
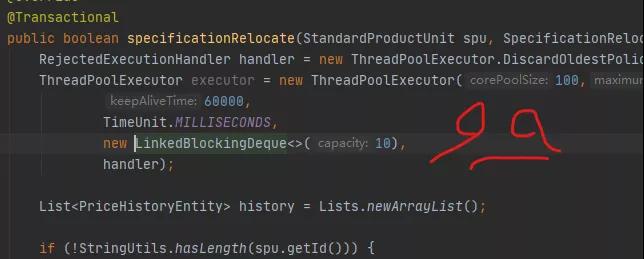
執行緒池,竟然是在方法裡創建的!
#當每一個請求到來的時候,它都會建立一個執行緒池,直到系統再也無法分配資源為止。
可真是霸道啊。
所有人都在關注線程池的參數是怎麼設定的,但從來沒有人懷疑這段程式碼的位置。
以上がサーバー障害インスタンスの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。