
ホームページ >データベース >mysql チュートリアル >MySQL がインデックスの構築に適さない状況やインデックスの失敗はどのような状況ですか?
MySQL がインデックスの構築に適さない状況やインデックスの失敗はどのような状況ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-02 13:28:121915ブラウズ
結論
特定のケースについては、以下で詳しく説明します
インデックスの作成に適さないシナリオ:
インデックスの作成は推奨されません。比較的少量のデータを含むテーブル インデックス
大量の重複データを含むフィールド (性別フィールドなど) にインデックスを作成することはお勧めできません
頻繁に更新が必要なテーブルには推奨されません。インデックスの作成
- ##where、group by、order by の背後にある未使用のフィールドにはインデックスが作成されません
- 冗長なインデックスを定義しないでください
- (! と等しくないフィルター条件を使用してください) =, )
- 使用するフィルター条件が null ではありません
- インデックス フィールドで関数または計算を使用してください
- 結合インデックスを使用する場合は、「最も左のプレフィックス ルール」を満たす必要があります。満たさないと無効になります。
- 型変換が使用される場合、インデックスも無効になります
- 範囲クエリを使用すると、ジョイント インデックスの一部のフィールドが無効になる場合があります (年齢 > 18 の場合)
- 次のようにフィールドが % で始まる場合、インデックスは無効になります (‘�c’ のような名前)
- or を使用してクエリを実行する場合、or の前後に非インデックス フィールドが表示されます。インデックスが無効です
- テーブルとライブラリの文字セットが一致していないため、戻り値がインデックスの失敗の原因
- #各テーブルに 6 つを超えるインデックスを作成することはお勧めできません (領域が占有され、テーブルの更新速度が低下します)
- ##最終的な決定は、インデックスを使用するかオプティマイザーを使用するかです。
- オプティマイザーは、データ量、データベース バージョン、およびデータ選択の読み取り比較に基づいてクエリ コストを決定し、使用するかどうかを決定します。インデックス
- インデックスを作成するときは、失敗を避けるためにインデックスの最後に範囲一致が必要なフィールドを設定します。
- テーブルでは、フィールドを null 以外に設定し、デフォルト値を設定します。値のないレコードを検索する必要がある場合は、where xxx = デフォルト値を使用できます。is not null を使用すると、インデックスが失敗します #ページ上で検索するときは、左側または全文あいまい一致 ('�c' など) を使用してください。
- よりフィルタリングしやすいフィールドについては、前に作成してください。この方法では、より多くのデータを最初にフィルタリングできます
- #インデックス作成が推奨されないシナリオ
where/group by/order by の後のフィールドのインデックスは使用されないため、インデックスを作成する必要はありませんシナリオ 5: 冗長なインデックスを定義しない
create index username_password_address on xiao(username,password,address); -- 如果建立了第一个索引,那么就没有必要建立第二个索引 create index username on xiao (username); --第二个索引就是冗余索引,因为第一个已经是先根据username排序的索引 --也就是第二个索引的功能完全可以由第一个索引实现ここでは、ユーザー名を最初の結合インデックスの最初のフィールドとしてユーザー名でソートし、ユーザー名が同じ場合はパスワードとアドレスでソートするため、ユーザー名カラムのみをインデックスとして使用する機能が実現されています。つまり、2 番目のインデックスは冗長です。インデックス障害のシナリオシナリオ 1: インデックス付きフィールドに対して操作 (関数など) を実行すると、インデックス障害が発生しますここが age の最初のステップですインデックスが作成され、最初のクエリ プロセスで age インデックスが使用されましたが、2 番目のキー値が null (インデックスの失敗)。インデックスの失敗の理由は、age が where の後に計算されたためです。 2 番目のクエリ中。コンピュータはどのような計算が実行されているかわからないため、年齢 1 を計算し、それを 1 と比較します。インデックスは無効になります。関数 concat() をクエリで使用する場合と同様です。
シナリオ 2: 等しくない (年齢 != 18) を使用する 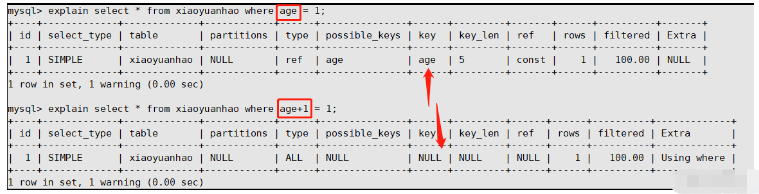
explain select * from xiaoyuanhao where age = 18; explain select * from xiaoyuanhao where age != 18; --这里是在age字段上建立了普通索引,第二个查询时候索引失效シナリオ 3: is not null を使用したインデックスの失敗 は、等しくないことと同じです。 is not null が使用されている場合、すべてのデータを処理する必要があります トラバーサル操作では、インデックスは無効ですが、is null を使用した場合でもインデックスを使用できます
--这里是在age字段上建立了普通索引,第二个查询时候索引失效 explain select * from xiaoyuanhao where age is null; --可以正常使用索引 explain select * from xiaoyuanhao where age is not null; --索引失效シナリオ 4: を使用する場合ジョイント インデックス、最適左プレフィックス ルールに従っていません。
CREATE INDEX age_classid_name ON student(age,classId,NAME); EXPLAIN SELECT * FROM student WHERE classId = 30 AND NAME = 'xiaoyuanhao'; -- 因为没有使用age字段,所以没有准许最佳左前缀原则,索引失效
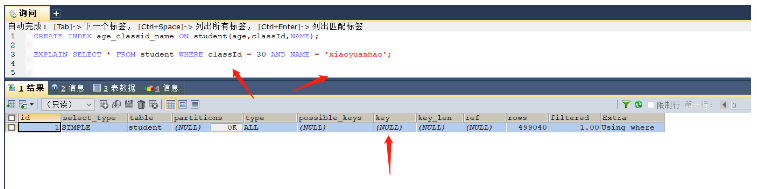
从这里可以看出是没有使用索引的(key = null),因为创建的索引是先按照age进行排序,在age相同的情况下按照classId和name排序,如果在查询的时候需要直接按照classId进行排序查找,那么就无法使用该索引,即索引失效。
如果需要使用使用索引,那么就一定需要到联合索引的第一个字段age,案例如下
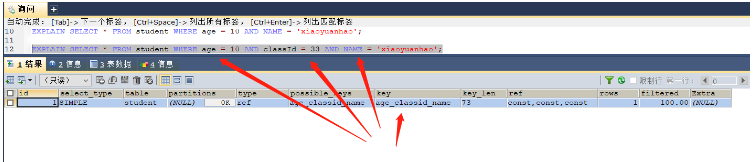
EXPLAIN SELECT * FROM student WHERE age = 10 AND NAME = 'xiaoyuanhao'; EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 33 AND NAME = 'xiaoyuanhao'; --两者都是使用age字段索引,所以索引有效

场景五:类型转换导致索引失效
CREATE INDEX NAME ON student(NAME); -- 这里的name字段是varchar类型 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 本次查询是可以使用索引的,因为类型都是一致的,都是字符串 EXPLAIN SELECT * FROM student WHERE NAME = 123; -- 本次查询则无法使用索引,因为是将数字类型123转换为字符类型
没有发生类型转换,使用索引key = name
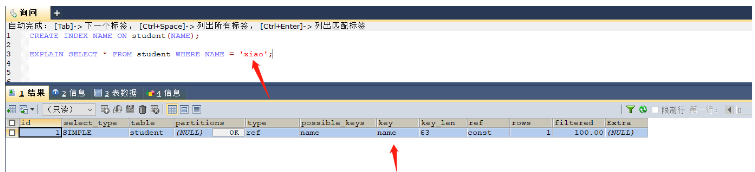
发生了类型转换,无法使用索引kye = null,索引失效
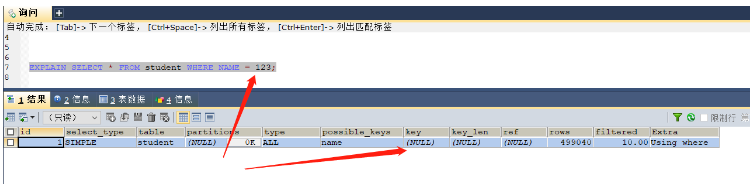
使用索引的时候一定需要保证数据类型是一致的,否则系统就需要进行转换,那么就无法使用索引
场景六:使用范围查询导致联合索引其他字段失效
create index age_classId_name on student (age,classId,name); EXPLAIN SELECT * FROM student WHERE age = 10 AND classId > 20 AND NAME = 'xiaoyuanhao'; -- 这里只能使用age,classId,索引的前两个字段 EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 20 AND NAME = 'xiaoyuanhao'; -- 这里可以使用完整的索引,因为都是等值连接
在classId字段上使用范围查询,导致name字段失效,有效索引长度为63

使用的都是等值匹配,整个索引皆可用,有效索引长度为73

也就是在对于联合索引来说,如果在使用的时候是等值匹配,那么就可以重复的利用索引,如果不是等值匹配,那么该字段也是可以使用索引的,但是该字段右边的字段就将失效
建议在建立索引的时候将需要范围匹配的字段建立在索引的最后面
场景七:在使用like的时候,如果以%开头导致索引失效
EXPLAIN SELECT * FROM student WHERE NAME LIKE 'abc%'; -- 可以正常使用索引 EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc'; -- 这里在like中,%在前面无法使用索引
key = name,使用了该索引,索引有效
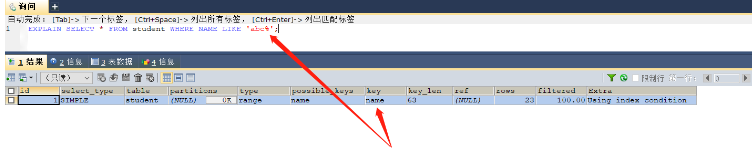
key = null,索引失效

因为建立的索引实际上是按照整个字符串的从第一个开始进行比较排序的,所以在使用like的时候,也只能够重现进行比较,如果使用的是’%abc’,那么查询的就是以abc结尾的数据,无法使用索引
场景八:or前后出现非索引字段,索引失效
-- 该表中只有name字段上的索引 CREATE INDEX NAME ON student(NAME); EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 这里是可以使用name索引的 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao' OR classId = 1001; -- 这个则无法使用索引,进行的是全表扫描
key = null,无法使用索引,or条件中出现非索引字段
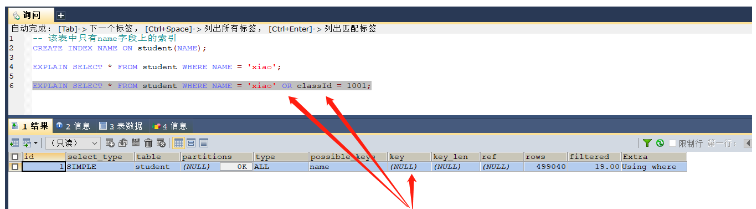
因为如果name不等于’xiao’的时候那么就会继续判断classId是否等于1001,那么实际上还是会进行全表扫描,所以索引失效(也就是进行name判断的时候可以使用索引,但是在判断classId的时候又要全表扫描,那么优化器就直接进行全表扫描),但是如果or前后的字段都有索引了,那么就就会使用索引
以上がMySQL がインデックスの構築に適さない状況やインデックスの失敗はどのような状況ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。