
ホームページ >データベース >mysql チュートリアル >左結合接続を使用して mysql の重複問題を解決する方法
左結合接続を使用して mysql の重複問題を解決する方法

- 王林転載
- 2023-06-02 13:13:413076ブラウズ
Mysql は左結合を使用して繰り返し接続します。
問題の説明
結合クエリを使用する場合、たとえばテーブル A がメインです。 table 、テーブル B への接続を残します。クエリ結果にはテーブル A と同じ数のレコードが含まれることが期待されます。ただし、クエリされたレコードの総数がレコードの総数よりも多くなる結果が生じる可能性があります。テーブル A. で、クエリ結果が表示されると、いくつかの列が繰り返され、簡単に言えば、デカルト積が生成されます。
質問例
テーブル A はユーザー テーブル (ユーザー) で、フィールドは次のとおりです:
ID name userid
1 aaaa 10001
2 bbbb 10002
3 ccccc 10003
B テーブルは最初のタイプの製品テーブル (product) であり、フィールドは次のとおりです:
ID title time userid
1 タイトル 1 2014-01-01 10002
2 タイトル 2 2014-01-01 10002
3 タイトル 3 2014-01-01 10001
4 タイトル 4 2018-03-20 10002
5 Title 5 2018-03-20 10003
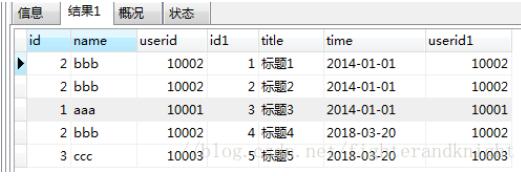
このとき、以下のSQLを使用して実行したところ、
selecct * from user left join product on user.userid=product.userid;
前面脑补 LEFT JOIN (SELECT MODEL_CODE,MODEL_NAME from tm_model GROUP BY MODEL_CODE) tm on tav.model_code = tm.MODEL_CODE 后面脑补
以上が左結合接続を使用して mysql の重複問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はyisu.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。
前の記事:MySQLで更新および削除する方法次の記事:MySQLで更新および削除する方法