
ホームページ >データベース >mysql チュートリアル >MySQL データを Elasticsearch と同期するためのソリューションは何ですか?
MySQL データを Elasticsearch と同期するためのソリューションは何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-01 18:37:281766ブラウズ
商品検索
誰もがさまざまなECサイトで商品を探したことがあると思いますが、普段どのようにして商品を探していますか?検索エンジン Elasticsearch。
そこで質問になります。商品が店頭に並べられると、通常、データは MySQL データベースに書き込まれます。では、検索に使用されるデータはどのようにして Elasticsearch に同期されるのでしょうか?
MySQL 同期 ES
1. 同期二重書き込み
これは考えられる限り最も直接的な方法です。MySQL に直接書き込む場合、データのコピーを ES に同期的に書き込みます。
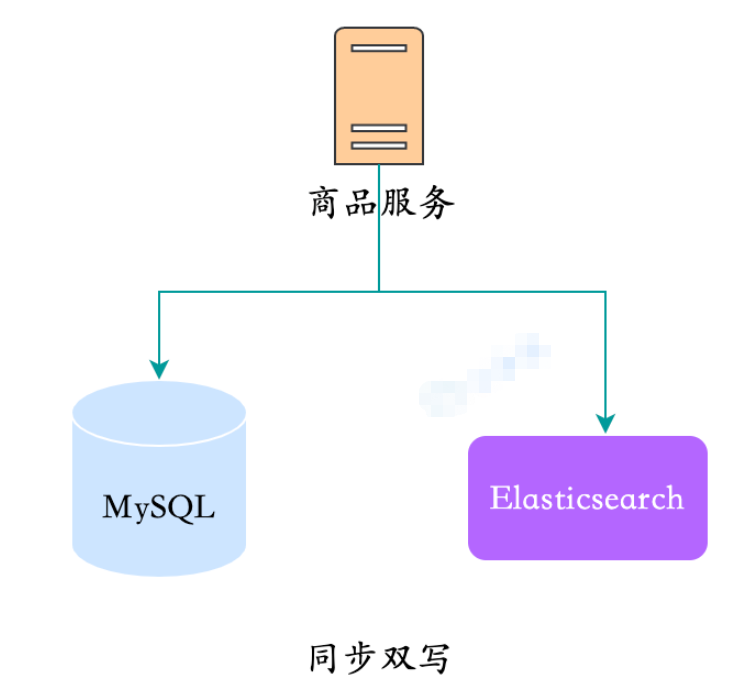
同期二重書き込み
この方法の場合:
利点:実装が簡単
欠点:
ビジネス結合、製品管理での大量のデータ同期コードの結合
- ## パフォーマンスに影響し、2 つのストレージに書き込み、応答時間が長くなります
- 拡張するのが不便: 検索には、データの集約が必要なパーソナライズされた要件がある場合があります。この方法は実装するのが不便です ##2. 非同期二重書き込み
非同期二重書き込みという手法も思いつきやすく、商品を出品する際には、まず商品データをMQに投げ込みますが、その結合を理解するために通常は検索サービスを分割し、検索サービスは製品変更のニュースを購読し、同期を完了します。
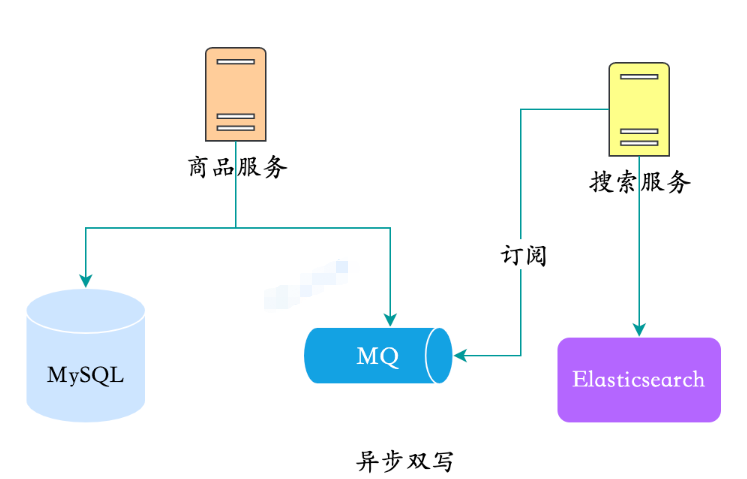 非同期二重書き込み
非同期二重書き込み
前述したように、一部のデータを幅の広いテーブルのような構造に集約する必要がある場合はどうすればよいでしょうか?たとえば、製品ライブラリの製品カテゴリ、spu、sku テーブルは分離されていますが、クエリは次元を超えています。ES で再度集計するのは効率が悪くなります。製品データを集計して、 ES と同様の大規模な手法であり、広いテーブル形式で格納されるため、クエリ効率が高くなります。
多次元複数条件クエリ
これを行う良い方法は実際にはありません。基本的には、サービスを検索してデータベースを直接チェックするか、リモートで呼び出す必要があります。その後、製品データベースに再度クエリを実行します。これは、いわゆるバックチェックです。
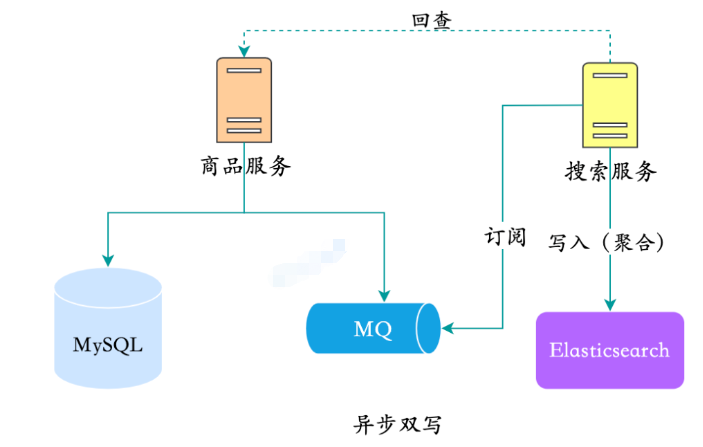 完全な集計を振り返る
完全な集計を振り返る
この方法:
利点:
- ソリューション結合すると、製品サービスはデータの同期に注意を払う必要がなくなります。
- MQ を使用すると、リアルタイムのパフォーマンスが向上します。通常の状況では、同期は数秒で完了します
- 欠点 :
- 新しいコンポーネントとサービスが導入され、複雑さが増します
- 3. スケジュールされたタスク
すぐに確認したい場合は、データ量はそれほど大きくありませんが、どうすればよいですか?スケジュールされたタスクも利用できます。
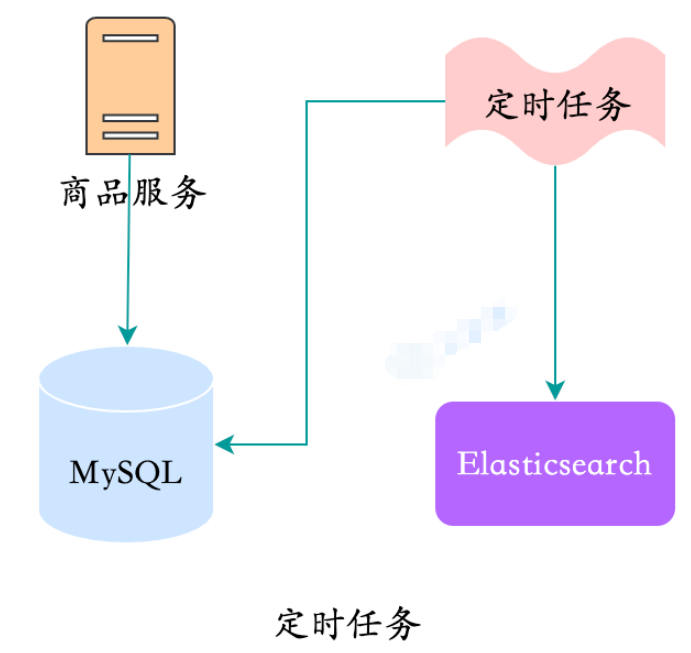 スケジュールされたタスク
スケジュールされたタスク
#スケジュールされたタスクの最も厄介な点は、頻度を選択するのが難しいことです。頻度が高いと、不自然にビジネスが形成されてしまいます。ストレージの CPU とメモリの使用量はピーク時に増加します。周波数が低いとリアルタイム性が低下し、ピークも発生します。
この方法:
利点:実装が比較的簡単
欠点:
- リアルタイムのパフォーマンスを保証するのが難しい
- ストレージへの高い負荷
- 4. データ サブスクリプション
別の方法があり、それが最も一般的なデータ サブスクリプションです。
MySQL は、binlog サブスクリプションを通じてマスターとスレーブの同期を実現します。canal などのさまざまなデータ サブスクリプション フレームワークは、この原理を使用して、クライアント コンポーネントをスレーブ ライブラリとして偽装し、データ サブスクリプションを実装します。
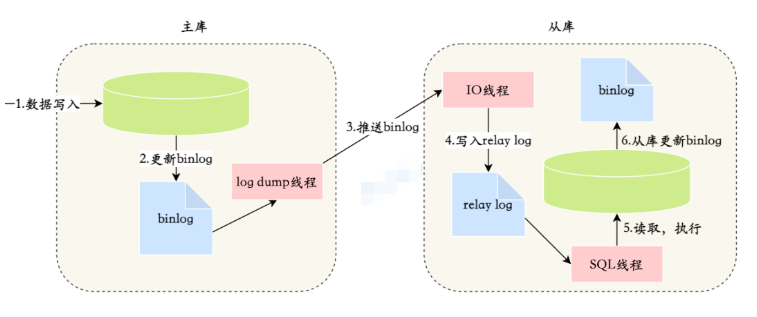 MySQL マスター/スレーブ同期
MySQL マスター/スレーブ同期
最も広く使用されている canal を例として取り上げます。canal は
canal-adapter を通じてさまざまな機能をサポートしています ES アダプターを含むアダプターは、一部の構成を開始した後、MySQL データを ES に直接同期できます。このプロセスはゼロコードです。
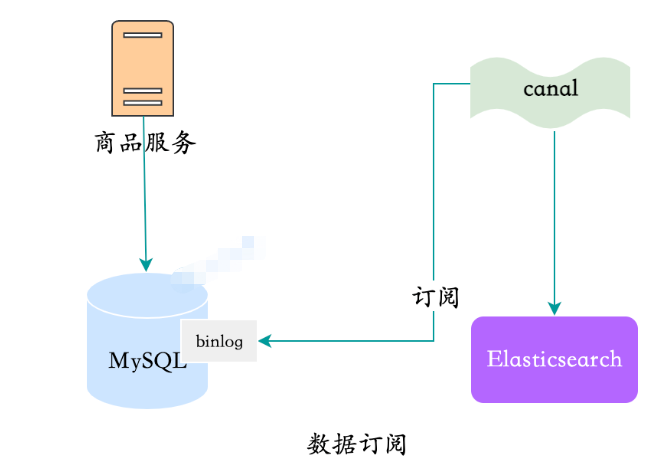 canal 同期データ
canal 同期データ
上司の提案に従い、同期作業に canal を使用しますが、実際にはコードを記述する必要があります。なぜ?
canal のサポートが限られているため、上記の複数のテーブルのデータ集約は引き続きレビューを通じて実装する必要があります。現時点では、canal-adapter の使用は適切ではありません。canal-client を自分で実装し、データを監視および集計し、ES に書き込む必要があります:
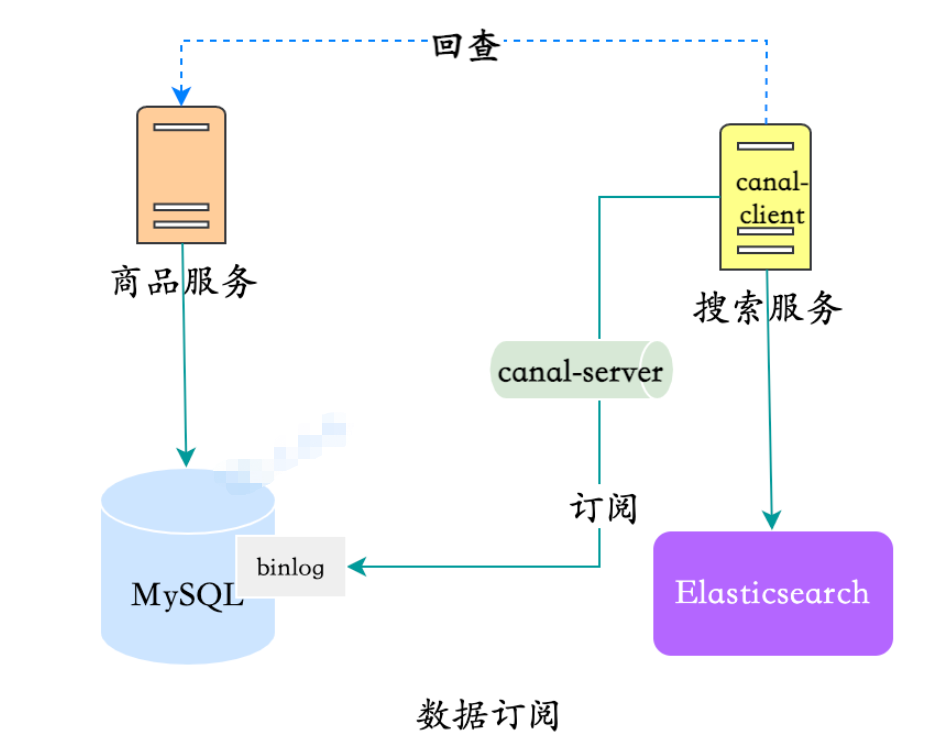 データ サブスクリプションreview
データ サブスクリプションreview
これは非同期二重書き込みに似ていますが、第一に製品とサービスの結合が減少し、第二にデータのリアルタイム性が向上します。
したがって、データ サブスクリプションを使用します:
利点:
- ビジネスへの侵入が少なくなります
- よりリアルタイム良い###
データ サブスクリプション フレームワークの選択に関しては、一般的に主流なのは次のとおりです。
| Cancal | Maxwell | Python-Mysql-Rplication | |
|---|---|---|---|
| Alibaba | Zendesk | コミュニティ | |
| Java | Java | Python | |
| アクティブ | アクティブ | アクティブ | |
| サポート | サポートされている | サポートされていない | |
| Java/Go/PHP/Python/Rust | なし | Python | |
| Kafka/RocketMQ など | ##Kafka/RabbitNQ/Redis など | カスタム | |
| カスタム | JSON | カスタム | ##ドキュメントの詳細 |
| 詳細 | 詳細 | Boostrap | |
| #サポートされている | サポートされていない | MySQL は、基本的に同様の方法を使用して、HBase などの他のデータ ストアと同期します。 |
以上がMySQL データを Elasticsearch と同期するためのソリューションは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。