
ホームページ >テクノロジー周辺機器 >AI >国産ChatGPT「シェル」の秘密が判明
国産ChatGPT「シェル」の秘密が判明

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-30 18:09:071614ブラウズ

「iFlytek は ChatGPT の隠蔽です!」 「Baidu Wenxin は安定版拡散の隠蔽です!」 「SenseTime の大きなモデルは実際には盗作です!」...
国産大型モデルが外部から疑問視されたことは一度や二度ではない。
業界関係者によるこの現象の説明は、高品質の中国語データ セットが実際に不足しているためです。モデルをトレーニングする際、 は購入した外国語の注釈付きデータ セットのみを使用できます。 「対外援助として行動する」#。トレーニングに使用されたデータセットがクラッシュすると、同様の結果が生成され、独自のインシデントが発生します。
他の方法の中でも、トレーニング データの生成を支援するために既存の大規模モデルを使用する場合、データ クリーニングが不十分になる傾向があります。トークンを再利用すると過剰適合につながります。まばらな大規模モデルをトレーニングするだけでは、長期的な解決策にはなりません。 業界は徐々にコンセンサスを形成してきました: AGI への道では、データ量とデータ品質の両方について非常に高い要件が引き続き提示されます。 現在の状況では、過去 2 か月間で、多くの国内チームが中国のデータ セットを次々とオープンソース化する必要があります。. 一般的なデータ セットに加えて、 Chuiyu では、専用のオープンソース中国語データセットもリリースされています。
高品質のデータ セットは入手可能ですが、数は少ないです。大規模モデルにおける新たな進歩は、高品質で豊富なデータ セットに大きく依存しています。 OpenAI の「ニューラル言語モデルのスケーリング則」によると、スケーリング則に続いて大規模なモデルが適用されます(スケーリング則)トレーニング データの量を個別に増加させると、事前学習済みモデルの効果がより良くなります。
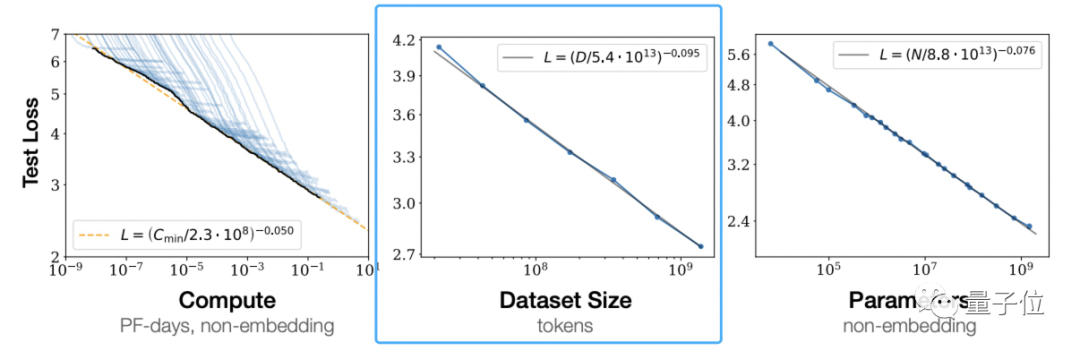
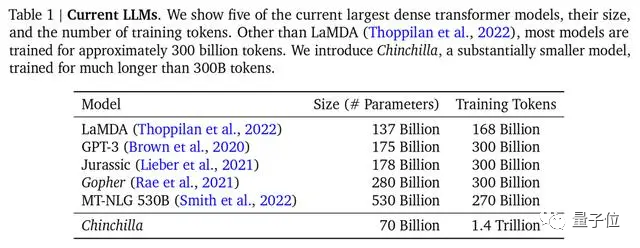
##主流 大型モデルの場合、チンチラはパラメータが最も少ないですが、最も十分なトレーニングを行っていますただし、トレーニングに使用される主流のデータセットは、Common Crawl、BooksCorpus、WiKipedia、ROOT など、主に英語です。最も人気のある Common Crawl である中国のデータは 4.8% にすぎません。 中国のデータセットの状況はどうなっているのでしょうか?
公開データ セットが存在しないわけではありません。これは、Lanzhou Technology の創設者兼 CEO であり、今日の NLP 分野で最も熟練した中国人の 1 人である Zhou Ming の Qubits によって確認されています。たとえば、名前付きエンティティ データ セットなどです。 MSRA-NER、Weibo -NER などのほか、GitHub で見つかる CMRC2018、CMRC2019、ExpMRC2022 などもありますが、全体の数は英語のデータセットと比較するとほんのわずかです。
さらに、彼らの中には古く、最新の NLP 研究概念を知らない人もいるかもしれません (新しい概念に関連する研究は、arXiv では英語でのみ表示されます)。
中国には高品質なデータセットが存在するものの、数が少なく使いにくいという、大規模モデル研究を行うすべてのチームが直面しなければならない厳しい状況があります。以前の清華大学電子工学部フォーラムで、清華大学コンピューターサイエンス学部教授のTang Jie氏は、1000億モデルChatGLM-130Bの事前トレーニング用のデータを準備する際に、次のような状況に直面したと語った。中国のデータを消去した後、使用可能な容量は 2TB 未満になったことがわかりました。
中国語圏における高品質のデータセットの不足を解決することが急務です。
効果的な解決策の 1 つは、英語データを直接使用して大規模なモデルをトレーニングすることです。
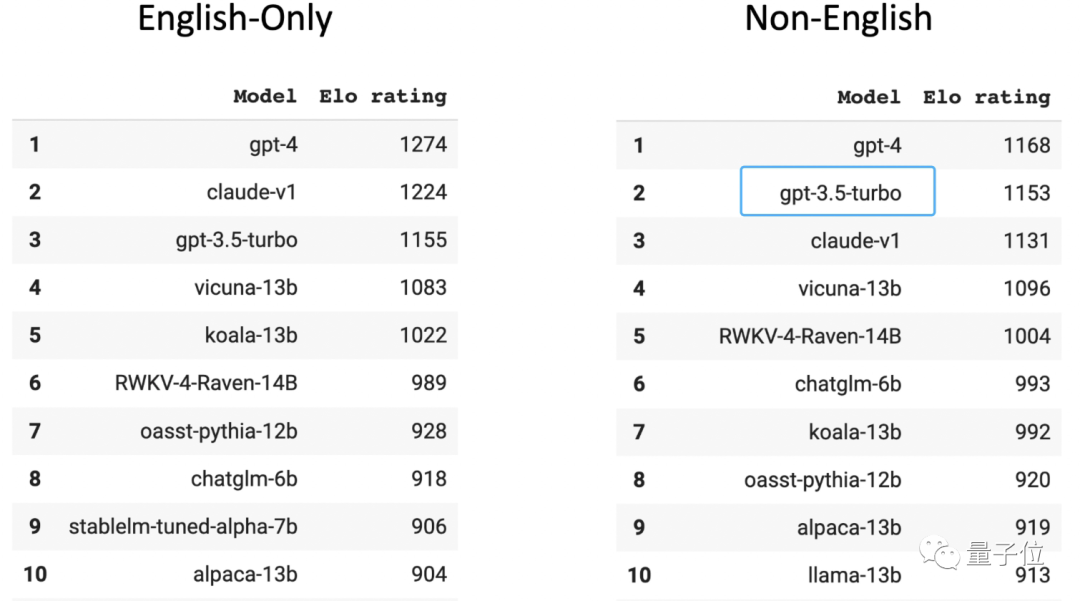
人間のプレイヤーによって評価された大規模な匿名アリーナのチャットボット アリーナ リストでは、GPT-3.5 は英語以外のランキングで 2 位にランクされています
(1 位は GPT-4)。 GPT-3.5 のトレーニング データの 96% は英語であり、他の言語を除くと、トレーニングに使用される中国語データの量は「1000 分の 1」で計算できるほど少ないことを知っておく必要があります。
中国のトップ 3 大学の 1 つからの大規模なモデル関連チームの博士号取得候補者は、この方法が採用され、それほど面倒でなければ、次のことが可能であることを明らかにしました。モデルに翻訳ソフトウェアを接続してすべての言語を翻訳することもでき、すべて英語に変換され、モデルの出力は中国語に変換されてユーザーに返されます。
 しかし、この方法で与えられる大きなモデルは常に英語の思考であり、熟語の書き換え、口語的な理解、冠詞の書き換えなどの中国語の特徴を持つコンテンツに遭遇すると、うまく処理されず、翻訳エラーが発生することがよくあります。または潜在的な文化的不正確さ。
しかし、この方法で与えられる大きなモデルは常に英語の思考であり、熟語の書き換え、口語的な理解、冠詞の書き換えなどの中国語の特徴を持つコンテンツに遭遇すると、うまく処理されず、翻訳エラーが発生することがよくあります。または潜在的な文化的不正確さ。
もう 1 つの解決策は、中国語コーパスを収集、クリーンアップ、ラベル付けし、
新しい高品質の中国語データ セットを作成し、それを大規模モデルに提供することです。
みんなで薪を集めるオープンソース データセット
現状に気づいた国内の大規模モデル チームの多くは、2 番目の道を選択し、プライベート データベースを使用してデータ セットを作成し始めました。
Baidu にはコンテンツの生態学的データがあり、Tencent には公的アカウントのデータがあり、Zhihu には Q&A データがあり、Alibaba には電子商取引と物流のデータがあります。
蓄積されたさまざまなプライベート データを使用すると、特定のシナリオや分野でコア アドバンテージ バリアを確立することができます。これらのデータを厳密に収集、並べ替え、フィルタリング、クリーニング、ラベル付けすることで、トレーニング済みモデルの有効性と精度を確保できます。 。
そして、プライベート データの利点がそれほど明らかではない大規模なモデル チームは、ネットワーク全体でデータをクロールし始めました (クローラー データの量が非常に大きくなることが予測されます)。
Pangu の大規模モデルを構築するために、ファーウェイはインターネットから 80TB のテキストをクロールし、最終的にそれを 1TB の中国語データセットにクリーンアップしました。Inspur Source 1.0 のトレーニングに使用された中国語データセットは 5000GB に達しました ( GPT3 モデル トレーニング データ セットは 570GB)、最近リリースされた Tianhe Tianyuan の大規模モデルも、天津スーパーコンピューティング センターによるグローバル Web データの収集と、さまざまなオープンソース トレーニング データおよび専門分野のデータ セットの組み込みの結果です。
同時に、過去 2 か月間、人々が中国のデータ セットを得るために薪を集める現象が発生しました -
多くのチームが、オープンソースの中国のデータ セットを次々にリリースしてきました。現在の中国のオープンソース データセットの欠陥または不均衡。
その一部は次のように構成されています:
- CodeGPT: GPT および GPT によって生成されたコード関連の会話データ セット。その背後にある機関は復旦大学です。 。
- CBook-150k: 人文科学、教育、技術、軍事、政治などの多くの分野をカバーする 150,000 冊の中国語書籍のダウンロードと抽出方法を含む中国語コーパス書籍コレクション。その背後にある組織は復旦大学です。
- RefGPT: 手動による注釈の高額なコストを回避するために、事実に基づいた対話を自動的に生成し、以下を含むデータの一部を公開する方法を提案します。 50,000 項目、複数回の中国語での対話、その背後には上海交通大学、香港理工大学などの NLP 実践者が参加します。
- COIG: 正式名称は「中国共通オープン命令データセット」で、より大規模で多様な命令チューニングコーパスであり、その品質は手動検証によって保証されています。そうした機関には、北京人工知能研究所、シェフィールド大学、ミシガン大学、ダートマス大学、浙江大学、北杭大学、カーネギーメロン大学などが含まれます。
- 素晴らしい中国の法律リソース: 上海交通大学によって収集、整理された中国の法律データ リソース。
- Huatuo: 医療ナレッジ グラフと GPT3.5 API を通じて構築された中国の医療指導データ セット。これに基づいて、LLaMA は改善するために微調整されています。指示の実行 医療分野における LLaMA の質疑応答効果; プロジェクトのソースはハルビン工業大学です。
- Baize: 少数の「シード質問」を使用して ChatGPT 自体とチャットさせ、高品質のマルチターン会話データに自動的に収集します。セット; カリフォルニア大学サンディエゴ校 (UCSD)中山大学および MSRA と協力するチームは、この方法を使用して収集されたデータセットをオープンソースにしました。
さらに多くの中国のデータセットがオープンソース化されて脚光を浴びると、業界の態度は歓迎と喜びの一つになります。たとえば、Zhipu AI の創設者兼 CEO である Zhang Peng 氏が表明した態度は、次のとおりです:
高品質の中国データは私室に隠されているだけです。この問題は誰もが認識しているので、当然、オープンソース データなどのソリューション。
つまり、良い方向に発展しているということですね。
この段階では、トレーニング前のデータに加えて、人間のフィードバック データも不可欠であることに注意してください。
既成のサンプルが私たちの前にあります:
GPT-3 と比較して、ChatGPT によって重ねられる重要なバフは、RLHF (ヒューマン フィードバック強化学習) を使用して生成することです。高品質のラベル付きデータを微調整することで、人間の意図に沿った大規模なモデルの開発が可能になります。
人間によるフィードバックを提供する最も直接的な方法は、AI アシスタントに「あなたの答えは間違っています」と伝えるか、AI アシスタントによって生成された返信のすぐ横に好きか嫌いかを伝えることです。

# 最初に使用すると、ユーザーからのフィードバックを集めて雪だるまを転がすことができます。これが、誰もが大型モデルのリリースを急ぐ理由の 1 つです。 。
現在、Baidu Wenxinyiyan、Fudan MOSS、Zhipu ChatGLM に至るまで、国内の ChatGPT に似た製品はすべてフィードバック オプションを提供しています。
しかし、ほとんどの経験豊富なユーザーの目から見て、これらの大型モデル製品の最も重要な属性は「おもちゃ」です。
不正確な答えや満足のいかない答えに遭遇した場合、対話インターフェイスを直接閉じることを選択しますが、これは背後にある大規模なモデルによる人間のフィードバックの収集に役立ちません。
以上が国産ChatGPT「シェル」の秘密が判明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。