
Redis の基本的なデータ構造は何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-27 16:02:341466ブラウズ
整数セット
セットに少数の整数要素しか含まれていない場合、Redis は整数セット intset を使用します。まず intset のデータ構造を見てください:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
実際、intset のデータ構造は比較的理解しやすいです。データを格納する要素であり、length にはコンテンツのサイズである要素数が格納され、encoding にはデータを格納する際の符号化方式が格納されます。
コードから、エンコードのエンコード タイプに次のものが含まれることがわかります。
#define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
実際、それが確認できます。 Redis エンコーディングのタイプは、データのサイズを指します。インメモリデータベースとしてメモリを節約する設計を採用しています。
データ構造は小さいものから大きいものまで 3 つあるため、データを挿入する際はメモリを節約するために、できるだけ小さいデータ構造を使用してください。挿入されたデータが元のデータ構造よりも大きい場合は、拡張がトリガーされます。
拡張には 3 つの手順があります。
新しい要素の型に応じて、配列全体のデータ型を変更し、スペースを再割り当てします
元のデータを新しいデータ型に変換し、あるべき場所に再配置し、順序を保持します。
次に、新しい要素を挿入します
整数コレクションはダウングレード操作をサポートしていません。一度アップグレードすると、ダウングレードすることはできません。
ジャンプ リスト
スキップ リストはリンク リストの一種で、空間を使用して時間を交換するデータ構造です。スキップ リストは、O(logN) の平均検索と最悪の場合の O(N) の複雑さの検索をサポートします。
スキップ リストは、zskiplist と複数の zskiplistNode で構成されます。まず、その構造を見てみましょう:
/* ZSETs use a specialized version of Skiplists *//*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
したがって、このコードに基づいて、次の構造図を描くことができます:
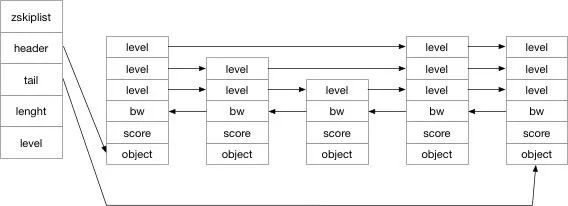
実際には、ジャンプ テーブルは使用空間です。時間変化データ構造では、レベルをリンク リストのインデックスとして使用します。
以前、誰かが Redis の作成者に、インデックスの構築にツリーではなくジャンプ テーブルを使用する理由を尋ねました。著者の答えは次のとおりです。
# メモリを節約します。
ZRANGE または ZREVRANGE を使用する場合、一般的なリンク リスト操作シナリオが含まれます。時間計算量のパフォーマンスは、バランスのとれたツリーのパフォーマンスと似ています。
最も重要な点は、ジャンプ テーブルの実装が非常に簡単で、O(logN) レベルに達する可能性があるということです。
圧縮リスト
圧縮リンク リスト Redis の作成者は、Redis を可能な限りメモリを節約するように設計された二重リンク リストとして紹介しています。
圧縮リストのコードのコメントに示されているデータ構造は次のとおりです。
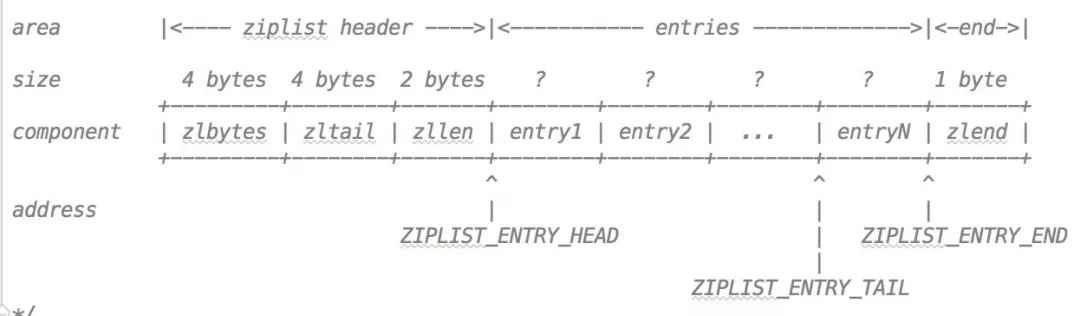
zlbytes はデータ構造を表します。圧縮リスト全体で使用されます。メモリバイト数
zltailは、圧縮リストの末尾ノードのオフセットを指定します。
zllenは、圧縮リスト内のエントリの数
entry は ziplist のノードです
zlend 圧縮リストの終わりをマークします
このリストには単一のポインタもあります:
ZIPLIST_ENTRY_HEAD リストの開始ノードの先頭オフセット
ZIPLIST_ENTRY_TAILリストの終了ノード
ZIPLIST_ENTRY_ENDリストの末尾ノードの終了オフセット
エントリの構造をもう一度見てください:
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;
これらのパラメータを順番に説明します。
prevrawlen 前のノードの長さ。ここには追加のサイズがあり、実際には prevrawlen のサイズが記録されます。メモリを節約するために、Redis はデフォルトの int 長を直接使用せず、徐々にアップグレードします。
同様に、len は現在のノードの長さを記録し、lensize は len の長さを記録します。 headersize は、上記の 2 つのサイズの合計です。 encoding は、このノードのデータ型です。ここで、エンコード タイプには整数と文字列のみが含まれることに注意してください。 p ノード ポインタについては、あまり説明する必要はありません。
注意すべき点は、各ノードが前のノードの長さを保存することです。ノードが更新または削除された場合、このノードの後のデータも変更する必要があります。最悪のシナリオは、各ノードがすべてノードは拡張する必要があるゼロ点にあり、これにより、このノードの後のノードがサイズ パラメータを変更し、連鎖反応が引き起こされます。このとき、リンクリストを圧縮する最悪の時間計算量は O(n^2) です。ただし、すべてのノードが臨界値にあるため、確率は比較的小さいと言えます。
以上がRedis の基本的なデータ構造は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。