
ホームページ >データベース >mysql チュートリアル >MySQL で SQL ステートメントを最適化する方法
MySQL で SQL ステートメントを最適化する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-26 14:07:431990ブラウズ
1. 概要
アプリケーション システムの開発プロセスでは、初期データ量が少ないため、開発者は SQL ステートメントを記述する際に機能実装に重点を置きますが、アプリケーション システムが正式に起動されると、量の急速な増加に伴い、多くの SQL ステートメントでパフォーマンス上の問題が徐々に現れ始め、本番環境への影響がますます大きくなり、現在、これらの問題のある SQL ステートメントがシステム全体のボトルネックになっています。システムのパフォーマンスに影響するため、それらを最適化する必要があります。
2. show status コマンドを使用して、さまざまな SQL の実行頻度を理解します。
MySQL クライアントが正常に接続された後、show [session|global]status を通じてサーバーのステータス情報を提供できます。コマンドを使用するか、オペレーティング システムで mysqladmin extend-status コマンドを使用してこれらのメッセージを取得できます。 show [session|global] status では、必要に応じてパラメータ「session」または「global」を追加して、セッション レベル (現在の接続) での統計結果と、(データベースが最後に起動されて以降の) グローバル レベルでの統計結果を表示できます。 )。記述されていない場合、デフォルトのパラメータは「session」が使用されます。
次のコマンドは、現在のセッションのすべての統計パラメータの値を表示します:
-- 查看会话所有统计的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
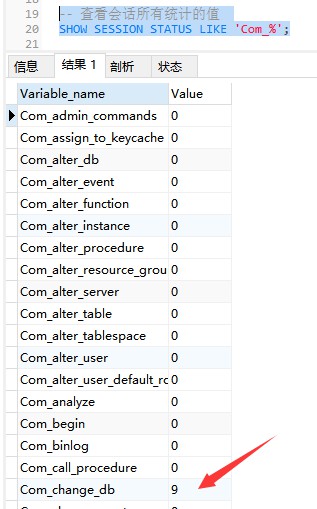
次のコマンドは、すべての統計パラメータの値を表示します。現在のグローバルのパラメータ:
-- すべてのグローバル統計の値を表示します
SHOW GLOBAL STATUS LIKE 'Com_%';
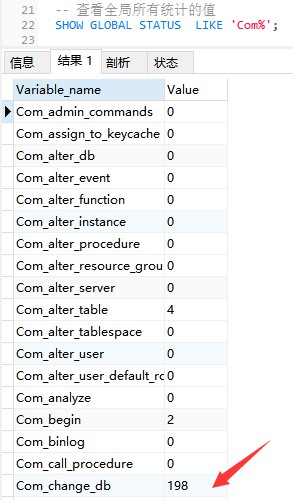
Com_xxx は、各 xxx ステートメントが実行された回数を示します通常、次の統計を考慮します。 パラメータ:
Com_select: SELECT 操作を実行する回数。1 つのクエリに対して 1 だけが蓄積されます。
Com_insert: INSERT 操作が実行された回数。バッチ挿入 INSERT 操作の場合、1 回だけ累積されます。
Com_update: UPDATE 操作が実行された回数。
Com_delete: DELETE 操作を実行する回数。
上記のパラメータは、すべてのストレージ エンジン テーブル操作に対して蓄積されます。これらのパラメータは InnoDB ストレージ エンジンにのみ適用され、その蓄積アルゴリズムは若干異なります。
Innodb_rows_read: SELECT クエリによって返される行の数。
Innodb_rows_inserted: INSERT 操作中に挿入された行の数。
Innodb_rows_updated: UPDATE 操作によって更新された行の数。
Innodb_rows_deleted: DELETE 操作によって削除された行の数。
上記のパラメータを通じて、現在のデータベース アプリケーション システムが主に挿入および更新操作に基づいているのか、クエリ操作に基づいているのか、またさまざまな種類の SQL の一般的な実行に基づいているのかを簡単に理解できます。 . 比率とは何ですか。コミットまたはロールバックに関係なく、更新操作のカウントは累積され、カウント オブジェクトは実行回数になります。
トランザクション アプリケーションの場合、Com_commit と Com_rollback を使用して、トランザクションの送信とロールバックを理解できます。ロールバック操作が非常に頻繁に行われるデータベースの場合、アプリケーションの作成に問題がある可能性があります。さらに、次のパラメータは、ユーザーがデータベースの基本的な状況を理解するのに役立ちます。
Connections: MySQL サーバーへの接続の試行回数。
- #稼働時間: サーバーの稼働時間。
- Slow_queries: 遅いクエリの数。
- 低速クエリ ログを通じて、実行効率の低い SQL ステートメントを見つけます。 --log-slow-queries[=file_name] オプションで開始すると、mysqld はすべての実行時間を含むファイルを書き込みますlong_query_time 秒間の SQL ステートメントのログ ファイルを超えています。
- スロー クエリ ログはクエリの完了後に記録されるため、アプリケーション システムが実行効率の問題を反映している場合、スロー クエリ ログをクエリしても問題を特定できません。現在の MySQL を表示するコマンド。スレッドのステータス、テーブルをロックするかどうかなど、進行中のスレッドで SQL の実行ステータスをリアルタイムで確認し、同時に一部のテーブル ロック操作を最適化できます。
 select_type: SELECT タイプを表し、一般的な値は次のとおりです:
select_type: SELECT タイプを表し、一般的な値は次のとおりです:
- SIMPLE (単純なテーブル、つまりテーブル接続やサブクエリは使用されません)。
- table: 結果セットを出力するテーブル。
type:表示表的连接类型,性能由好到差的连接类型为:
system(表中仅有一行,即常量表)。
const(单表中最多有一个匹配行,例如primary key或者unique index)。
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
index_merge(索引合并优化)。
unique_subquery(in的后面是一个查询主键字段的子查询)。
index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
range(单表中的范围查询)。
index(对于前面的每一行,都通过查询索引来得到数据)。
all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
Extra:执行情况的说明和描述。
Using index(此值表示mysql将使用覆盖索引,以避免访问表)。
Using where(mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。“Using where”有时提示了一种可能性:查询可以从不同的索引中受益。
Using temporary(mysql 对查询结果排序时会使用临时表)。
MySQL will apply an external index sorting on the results instead of reading rows from the table in index order.。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成)。
Range checked for each record(index map: N) (没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的)。
- PRIMARY (メインクエリ、つまり外側のクエリ)、UNION (UNION 内の 2 番目以降のクエリ文)、◎SUBQUERY (サブクエリ内の最初の SELECT) )wait。
5.确定问题并采取相应的优化措施
经过以上定位步骤,我们基本就可以分析到问题出现的原因。此时我们可以根据情况采取相应的改进措施,进行优化提高语句执行效率。
在上面的例子中,已经可以确认是goods_stock是走主键索引的,但是对goods_stock_price子表的进行了全表扫描导致效率的不理想,那么应该对goods_stock_price表的GoodsStockID字段创建索引,具体命令如下:
-- 创建索引 CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID); -- 附加删除跟查询索引语句 ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1; SHOW INDEX FROM goods_stock_price;
创建索引后,我们再看一下这条语句的执行计划,具体如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

可以发现建立索引后对goods_stock_price子表需要扫描的行数明显减少(从 3 行减少到1行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显。
以上がMySQL で SQL ステートメントを最適化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。