
ホームページ >データベース >mysql チュートリアル >ReplicationConnectionを使用してMySQLによる接続失敗の問題を解決する方法
ReplicationConnectionを使用してMySQLによる接続失敗の問題を解決する方法

- PHPz転載
- 2023-05-26 13:10:321607ブラウズ
はじめに
MySQL データベースの読み取りと書き込みの分離は、サービス品質を向上させるための一般的な方法の 1 つです。技術的なソリューションについては、sharding-jdbc、AbstractRoutingDatasource など、成熟したオープン ソース フレームワークやソリューションが多数あります。 spring、MySQL-Router など、および mysql-jdbc の ReplicationConnection もサポートできます。
この記事では、読み取りと書き込みの分離の技術的な選択についてはあまり分析しません。druid をデータ ソースとして使用し、それを読み取りと書き込みの分離のために ReplicationConnection と組み合わせた場合に接続が失敗する理由を調査するだけです。そして、シンプルで効果的な解決策を見つけます。
問題の背景
歴史的な理由により、特定のサービスには接続失敗の例外があり、主なエラー レポートは次のとおりです。これは、接続が長期間 MySQL サーバーと対話しなかったため、サーバーが接続を閉じてしまうことが原因であり、これは典型的な接続失敗の状況です。
関係する主な構成
jdbc 構成
##jdbc:mysql:replication://master_host:port,slave_host:port/database_namedruid 設定
testwhileIdle=true (つまり、アイドル接続チェックが有効になります);
timeBetweenEvictionRunsMillis=6000L (つまり、接続を取得するシナリオでは、接続が 1 分以上アイドル状態である場合にチェックされ、接続が無効な場合は破棄され、再取得されます。
添付ファイル: DruidDataSource.getConnectionDirect の処理ロジックは次のとおりです:「想定されている」経験では問題を説明できない場合、多くの場合、表面的な経験の束縛から飛び出して、問題の根本に到達する必要があります。では、この問題の本当の原因は何でしょうか? 本質的な理由if (testWhileIdle) { final DruidConnectionHolder holder = poolableConnection.holder; long currentTimeMillis = System.currentTimeMillis(); long lastActiveTimeMillis = holder.lastActiveTimeMillis; long lastExecTimeMillis = holder.lastExecTimeMillis; long lastKeepTimeMillis = holder.lastKeepTimeMillis; if (checkExecuteTime && lastExecTimeMillis != lastActiveTimeMillis) { lastActiveTimeMillis = lastExecTimeMillis; } if (lastKeepTimeMillis > lastActiveTimeMillis) { lastActiveTimeMillis = lastKeepTimeMillis; } long idleMillis = currentTimeMillis - lastActiveTimeMillis; long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis; if (timeBetweenEvictionRunsMillis <= 0) { timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS; } if (idleMillis >= timeBetweenEvictionRunsMillis || idleMillis < 0 // unexcepted branch ) { boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn); if (!validate) { if (LOG.isDebugEnabled()) { LOG.debug("skip not validate connection."); } discardConnection(poolableConnection.holder); continue; } } }mysql タイムアウト パラメーターの設定
wait_timeout=3600 (3600秒、つまり、接続が 1 時間以上サーバーと対話しなかった場合、接続はサーバーによって切断されます)。明らかに、上記の構成に基づいて、従来の理解によれば、「サーバーから最後に正常に受信されたパケットは xxx,xxx,xxx ミリ秒前でした」という問題は発生しないはずです。 (もちろん、その時点では、手動介入によってデータベース接続が切断される可能性も排除されました)。
druid をデータ ソースの管理に使用し、読み書き分離のために mysql-jdbc のネイティブ ReplicationConnection と組み合わせると、実際にはマスターとスレーブの 2 セットの接続が存在します。 ReplicationConnection プロキシ オブジェクトに Druid が含まれています 接続検出を行う場合、マスター接続のみが検出されます スレーブ接続を長期間使用しない場合、接続障害が発生します。
原因分析
mysql-jdbcでは、データベースドライバーの接続処理プロセス
com.mysql.jdbc.Driverのソースコードと組み合わせると、確認するのは難しくありません。 mysql-jdbc が取得する接続の主なプロセスは次のとおりです。
「jdbc:mysql:replication://」で始まる設定された jdbc-url の場合、 mysql-jdbc 経由で取得された接続、実際には ReplicationConnection のプロキシ オブジェクトです。デフォルトでは、「jdbc:mysql:replication://」の後の最初のホストとポートがマスター接続に対応し、後続のホストとポートが複数のスレーブ構成、シナリオでは、デフォルトで負荷分散にランダム ポリシーが使用されます。 ReplicationConnection プロキシ オブジェクトは、JDK 動的プロキシを使用して生成されます。InvocationHandler の特定の実装は ReplicationConnectionProxy です。キー コードは次のとおりです:public static ReplicationConnection createProxyInstance(List<String> masterHostList, Properties masterProperties, List<String> slaveHostList,
Properties slaveProperties) throws SQLException {
ReplicationConnectionProxy connProxy = new ReplicationConnectionProxy(masterHostList, masterProperties, slaveHostList, slaveProperties);
return (ReplicationConnection) java.lang.reflect.Proxy.newProxyInstance(ReplicationConnection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
} ReplicationConnectionProxy の重要なコンポーネント
ReplicationConnectionProxy の重要なコンポーネント
データベースについて
ReplicationConnectionProxy には、masterConnection とlavesConnection という 2 つの実際の接続オブジェクトがあります。CurrentConnection (現在の接続) は、masterConnection またはlavesConnection に切り替えることができます。 , 切り替え方法 readOnlyを設定することで実現できます。 ビジネス ロジックでは、読み取りと書き込みの分離を実現するための核心もここにあります。簡単に言うと、ReplicationConnection を使用して読み取りと書き込みを分離するときに、「接続の readOnly 属性を設定する」AOP を実行するだけです。 。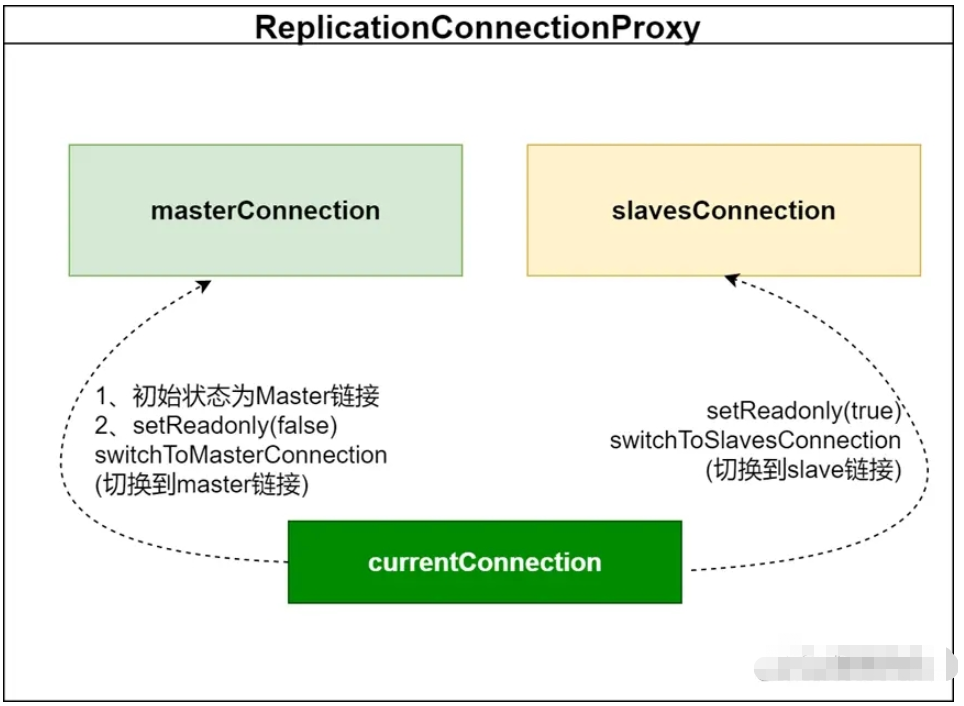 ビジネス ロジックで取得される接続プロキシ オブジェクトである ReplicationConnectionProxy に基づいて、データベース アクセス時のメイン ロジックは何ですか?
ビジネス ロジックで取得される接続プロキシ オブジェクトである ReplicationConnectionProxy に基づいて、データベース アクセス時のメイン ロジックは何ですか?
ReplicationConnection プロキシ オブジェクトの処理プロセス
ビジネス ロジックでは、取得した Connection インスタンスが ReplicationConnection プロキシ オブジェクトとなり、ReplicationConnectionProxy と ReplicationMySQLConnection を介したデータベース アクセスの処理が完了します。 InvocationHandler ですが、接続管理の役割も果たします。コア ロジックは次のとおりです:
对于prepareStatement等常规逻辑,ConnectionMySQConnection获取到当前连接进行处理(普通的读写分离的处理的重点正是在此);此时,重点提及pingInternal方法,其处理方式也是获取当前连接,然后执行pingInternal逻辑。
对于ping()这个特殊逻辑,图中描述相对简单,但主体含义不变,即:对master连接和sleves连接都要进行ping()的处理。
图中,pingInternal流程和druid的MySQ连接检查有关,而ping的特殊处理,也正是解决问题的关键。
druid数据源对MySQ连接的检查
druid中对MySQL连接检查的默认实现类是MySqlValidConnectionChecker,其中核心逻辑如下:
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (usePingMethod) {
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (clazz.isAssignableFrom(conn.getClass())) {
if (validationQueryTimeout <= 0) {
validationQueryTimeout = DEFAULT_VALIDATION_QUERY_TIMEOUT;
}
try {
ping.invoke(conn, true, validationQueryTimeout * 1000);
} catch (InvocationTargetException e) {
Throwable cause = e.getCause();
if (cause instanceof SQLException) {
throw (SQLException) cause;
}
throw e;
}
return true;
}
}
String query = validateQuery;
if (validateQuery == null || validateQuery.isEmpty()) {
query = DEFAULT_VALIDATION_QUERY;
}
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
if (validationQueryTimeout > 0) {
stmt.setQueryTimeout(validationQueryTimeout);
}
rs = stmt.executeQuery(query);
return true;
} finally {
JdbcUtils.close(rs);
JdbcUtils.close(stmt);
}
}对应服务中使用的mysql-jdbc(5.1.45版),在未设置“druid.mysql.usePingMethod”系统属性的情况下,默认usePingMethod为true,如下:
public MySqlValidConnectionChecker(){
try {
clazz = Utils.loadClass("com.mysql.jdbc.MySQLConnection");
if (clazz == null) {
clazz = Utils.loadClass("com.mysql.cj.jdbc.ConnectionImpl");
}
if (clazz != null) {
ping = clazz.getMethod("pingInternal", boolean.class, int.class);
}
if (ping != null) {
usePingMethod = true;
}
} catch (Exception e) {
LOG.warn("Cannot resolve com.mysql.jdbc.Connection.ping method. Will use 'SELECT 1' instead.", e);
}
configFromProperties(System.getProperties());
}
@Override
public void configFromProperties(Properties properties) {
String property = properties.getProperty("druid.mysql.usePingMethod");
if ("true".equals(property)) {
setUsePingMethod(true);
} else if ("false".equals(property)) {
setUsePingMethod(false);
}
}同时,可以看出MySqlValidConnectionChecker中的ping方法使用的是MySQLConnection中的pingInternal方法,而该方法,结合上面对ReplicationConnection的分析,当调用pingInternal时,只是对当前连接进行检验。执行检验连接的时机是通过DrduiDatasource获取连接时,此时未设置readOnly属性,检查的连接,其实只是ReplicationConnectionProxy中的master连接。
此外,如果通过“druid.mysql.usePingMethod”属性设置usePingMeghod为false,其实也会导致连接失效的问题,因为:当通过valideQuery(例如“select 1”)进行连接校验时,会走到ReplicationConnection中的普通查询逻辑,此时对应的连接依然是master连接。
题外一问:ping方法为什么使用“pingInternal”,而不是常规的ping?
原因:pingInternal预留了超时时间等控制参数。
解决方式
调整依赖版本
在服务中,使用的MySQL JDBC版本是5.1.45,并且使用的Druid版本是1.1.20。经过对其他高版本依赖的了解,依然存在该问题。
修改读写分离实现
修改的工作量主要在于数据源配置和aop调整,但需要一定的整体回归验证成本,鉴于涉及该问题的服务重要性一般,暂不做大调整。
拓展mysql-jdbc驱动
基于原有ReplicationConnection的功能,拓展pingInternal调整为普通的ping,集成原有Driver拓展新的Driver。方案可行,但修改成本不算小。
基于druid,拓展MySQL连接检查
为简单高效解决问题,选择拓展MySqlValidConnectionChecker,并在druid数据源中加上对应配置即可。拓展如下:
public class MySqlReplicationCompatibleValidConnectionChecker extends MySqlValidConnectionChecker {
private static final Log LOG = LogFactory.getLog(MySqlValidConnectionChecker.class);
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (conn instanceof ReplicationConnection) {
try {
((ReplicationConnection) conn).ping();
LOG.info("validate connection success: connection=" + conn.toString());
return true;
} catch (SQLException e) {
LOG.error("validate connection error: connection=" + conn.toString(), e);
throw e;
}
}
return super.isValidConnection(conn, validateQuery, validationQueryTimeout);
}
}ReplicatoinConnection.ping()的实现逻辑中,会对所有master和slaves连接进行ping操作,最终每个ping操作都会调用到LoadBalancedConnectionProxy.doPing进行处理,而此处,可在数据库配置url中设置loadBalancePingTimeout属性设置超时时间。
以上がReplicationConnectionを使用してMySQLによる接続失敗の問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。