
ホームページ >テクノロジー周辺機器 >AI >スケールとパフォーマンスで OpenAI を倍増させた Meta Voice が、LLaMA レベルのマイルストーンに到達しました。オープンソースの MMS モデルは 1100 以上の言語を認識します
スケールとパフォーマンスで OpenAI を倍増させた Meta Voice が、LLaMA レベルのマイルストーンに到達しました。オープンソースの MMS モデルは 1100 以上の言語を認識します

- PHPz転載
- 2023-05-24 16:25:061384ブラウズ
音声の面では、Meta は LLaMA レベルのマイルストーンをさらに達成しました。
本日、Meta は音声テクノロジーに革命をもたらす MMS と呼ばれる大規模な多言語音声プロジェクトを立ち上げます。
MMS は 1,000 以上の言語をサポートし、聖書に基づいてトレーニングされており、エラー率は Whisper データセットの半分です。
メタはたった 1 つのモデルでバベルの塔を構築しました。
さらに、Meta は、世界の言語の多様性の保護に貢献したいと考え、すべてのモデルとコードをオープンソースにすることを選択しました。

以前のモデルでは約 100 言語をカバーできましたが、今回は MMS によって直接この数が 10 ~ 40 倍に増加しました。
具体的には、Meta は 1,100 を超える言語の多言語音声認識/合成モデルと、4,000 を超える言語の音声認識モデルを公開しました。
OpenAI Whisper と比較して、多言語 ASR モデルは 11 倍多くの言語をサポートしていますが、54 言語での平均エラー率は FLEURS の半分以下です。
さらに、ASR を非常に多くの言語に拡張しても、パフォーマンスの低下はごくわずかです。
論文アドレス: https://research.facebook.com/publications/scaling-speech-technology-to-1000-langages/
消えゆく言語を保護、MMS で音声認識が 40 倍に向上
機械に音声を認識して生成する機能を持たせ、より多くの人が情報を取得できるようにします。
ただし、これらのタスク用の高品質な機械学習モデルを生成するには、何千時間もの音声や書き起こしなど、大量のラベル付きデータが必要です。ほとんどの言語では、この種のデータは単純です。存在しない。
既存の音声認識モデルは約 100 言語のみをカバーしており、これは地球上で知られている 7,000 以上の言語のほんの一部にすぎません。憂慮すべきことに、これらの言語の半分は私たちが生きている間に消滅する危険にさらされています。
大規模多言語音声 (MMS) プロジェクトでは、研究者たちは wav2vec 2.0 (自己教師あり学習におけるメタの先駆的な研究) と新しいデータセットの課題を組み合わせることで、この問題の一部を克服しました。
このデータセットは、1,100 以上の言語のラベル付きデータと、約 4,000 言語のラベルなしデータを提供します。

#wav2vec 2.0 は、言語を超えたトレーニングを通じて、複数の言語で使用される音声単位を学習します
これらの言語の中には、Tatuyo など、話者が数百人しかいないものもあります。また、データセット内のほとんどの言語では、音声テクノロジーが以前は存在していませんでした。
結果は、MMS モデルのパフォーマンスが既存のモデルよりも優れており、カバーされる言語の数が既存のモデルの 10 倍であることを示しています。
Meta は常に多言語の仕事に注力してきました。テキストに関しては、Meta の NLLB プロジェクトが多言語翻訳を 200 言語に拡張し、MMS プロジェクトが音声技術をより多くの言語に拡張しました。
聖書は音声データセットの問題を解決します数千の言語で音声データを収集することは簡単な問題ではなく、これはメタが直面する最初の問題でもあります研究者にとっては挑戦です。
既存の最大の音声データ セットは、最大でも 100 言語しかカバーしていないことを知っておく必要があります。この問題を克服するために、研究者たちは聖書などの宗教文書に目を向けてきました。
このような文書はさまざまな言語に翻訳され、広範な研究に使用され、さまざまな公開録音が行われてきました。
この目的を達成するために、メタ研究者は 1,100 以上の言語で新約聖書の朗読データ セットを特別に作成し、言語ごとに平均 32 時間のデータを提供しました。
他のさまざまな宗教文書のタグなし録音を追加することで、研究者らは利用可能な言語の数を 4,000 以上に増やしました。
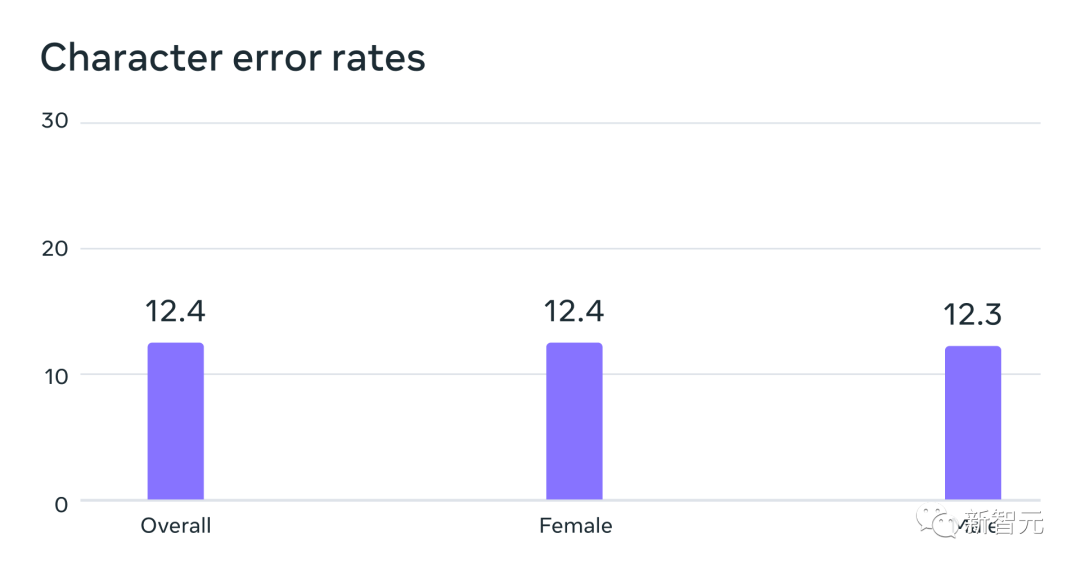
#MMS データでトレーニングされた自動音声認識モデルは、FLEURS ベンチマークのエラー率で男性話者と女性話者で同様のパフォーマンスを示しました
#データは通常男性によって話されていますが、モデルは男性の声でも女性の声でも同様に良好に機能します。
そして、録音の内容は宗教的なものでしたが、これによりモデルがより宗教的な言語を生成する方向に過度に偏ることはありませんでした。
研究者らは、これは、音声認識に使用される大規模な言語モデルやシーケンス間モデルよりも制限が緩いコネクショニスト時間分類法を使用したためであると考えています。
モデルが大きいほど、より強力に戦うことができますか?研究者らは、まずデータを前処理して品質を向上させ、機械学習アルゴリズムで利用できるようにしました。
これを行うために、研究者らは 100 を超える言語の既存データで位置合わせモデルをトレーニングし、このモデルを効率的な強制位置合わせアルゴリズムで使用しました。このアルゴリズムは約 20 言語の記録を処理できます。分以上。
研究者らはこのプロセスを複数回繰り返し、モデルの精度に基づいて最終的な相互検証フィルタリング手順を実行して、不整合の可能性があるデータを除去しました。
他の研究者が新しい音声データセットを作成できるようにするために、研究者はアライメント アルゴリズムを PyTorch に追加し、アライメント モデルをリリースしました。
現在、各言語には 32 時間のデータがありますが、これは従来の教師あり音声認識モデルをトレーニングするには十分ではありません。
これが、研究者が wav2vec 2.0 でモデルをトレーニングする理由です。これにより、モデルのトレーニングに必要な注釈付きデータの量を大幅に削減できます。
具体的には、研究者らは、1,400 を超える言語での約 500,000 時間の音声データに基づいて自己教師ありモデルをトレーニングしました。これは、過去のほぼ 5 倍に相当します。
その後、研究者は、多言語音声認識や言語認識などの特定の音声タスクに合わせてモデルを微調整できます。
大規模な多言語音声データでトレーニングされたモデルのパフォーマンスをより深く理解するために、研究者らは既存のベンチマーク データセットでモデルを評価しました。
研究者らは、1B パラメーター wav2vec 2.0 モデルを使用して、1,100 を超える言語の多言語音声認識モデルをトレーニングしました。
言語の数が増えるとパフォーマンスは低下しますが、その低下は穏やかです。61 言語から 1107 言語まで、文字エラー率は約 0.4 % しか増加しません。しかし、言語範囲は 18 倍以上に増加しました。各システムでサポートされる言語の数を 61 から増やす場合、MMS データを使用してトレーニングされた多言語認識システムの
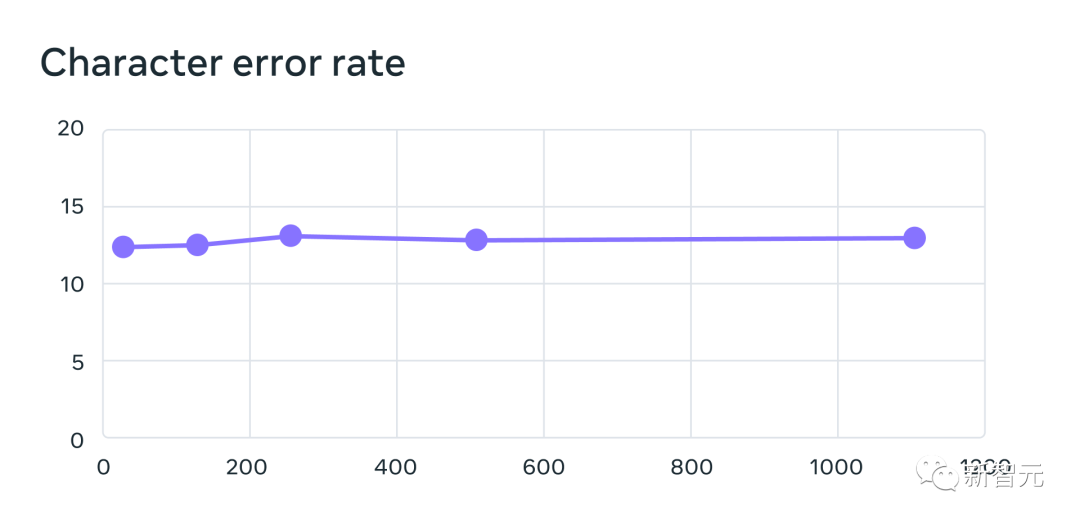
61 FLEURS 言語のエラー率は 1,107 までです。エラー率が高いほど、パフォーマンスが低いことを示します
OpenAI の Whisper との同一条件での比較では、研究者らは、大規模多言語音声データのワード エラーについてトレーニングされたモデルのほぼ半数であることを発見しました。率は高いですが、Massively Multilingual Speech は Whisper の 11 倍以上の言語をカバーしています。
データから、現在最高の音声モデルと比較した場合、Meta のモデルは非常に優れたパフォーマンスを示していることがわかります。
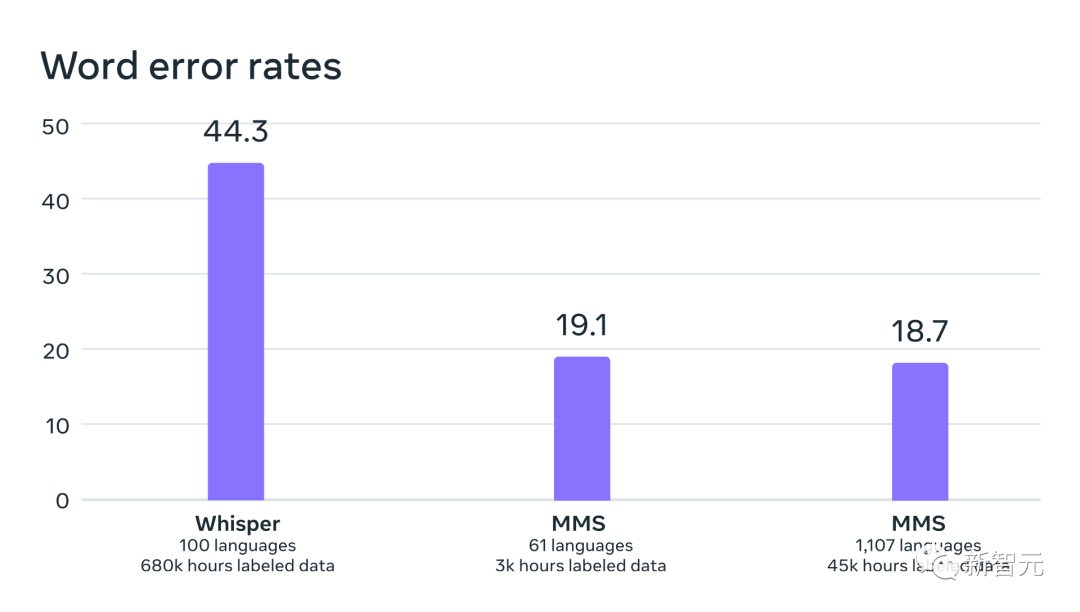
OpenAI Whisper と 54 の FLEURS 言語における大規模多言語スピーチの単語誤り率の比較
次へ研究者らは、独自のデータセットと FLEURS や CommonVoice などの既存のデータセットを使用して 4,000 以上の言語の言語識別 (LID) モデルをトレーニングし、FLEURS LID タスクで評価しました。
事実は、40 倍近くの言語をサポートしても、依然としてパフォーマンスが非常に優れていることを証明しています。
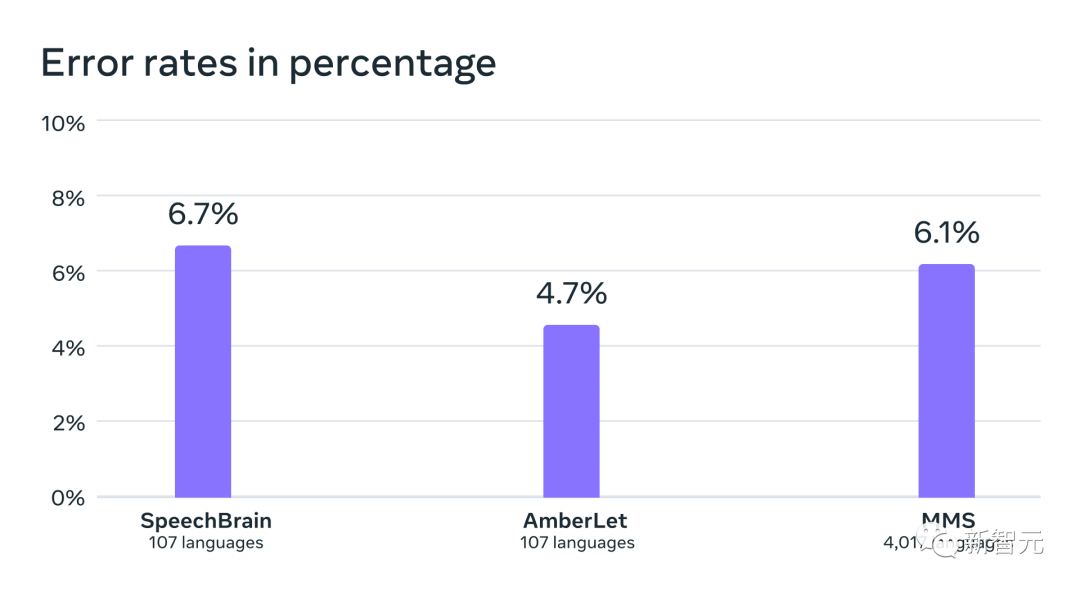
既存の作業の VoxLingua-107 ベンチマークでの言語認識精度は、100 をわずかに超える言語をサポートし、MMS は 4,000 を超える言語をサポートします言語。
研究者らは、1,100 を超える言語に対応するテキスト読み上げシステムも構築しました。
大規模な多言語音声データの制限の 1 つは、多くの言語で、比較的少数の異なる話者 (多くの場合 1 人の話者のみ) が含まれていることです。
ただし、この機能はテキスト読み上げシステムを構築する場合に利点があるため、研究者は 1,100 以上の言語に対して同様のシステムをトレーニングしてきました。
結果は、これらのシステムによって生成される音声品質は悪くないことを示しています。
未来は単一のモデルに属します
Meta の研究者はその結果に満足していますが、すべての新興 AI テクノロジーと同様に、Meta の現在のモデルは完璧ではありません。
たとえば、音声テキスト変換モデルでは、選択された単語やフレーズの特徴が誤って認識され、不快な出力や不正確な出力が生じる可能性があります。
同時に、メタ社は、責任ある AI テクノロジーの開発には、AI 大手企業の協力が不可欠であると考えています。
世界の言語の多くは消滅の危機に瀕しており、現在の音声認識および音声生成テクノロジーの限界は、この傾向を加速させるだけです。
研究者らは、テクノロジーが逆効果となり、人々が自分の好みの言語を話すことで情報にアクセスしたりテクノロジーを利用したりできるようになるため、言語を維持するよう奨励する世界を構想しています。
大規模な多言語音声プロジェクトは、この方向への重要な一歩です。
研究者らは将来、対象言語をさらに拡大し、より多くの言語をサポートし、さらには方言を処理する方法も見つけたいと考えています。ご存知のとおり、既存の音声テクノロジーにとって方言は単純ではありません。
Meta の最終目標は、人々が好みの言語で情報にアクセスし、デバイスを使用できるようにすることです。
最後に、メタ研究者は、単一のモデルがすべての言語の複数の音声タスクを解決できるという将来のシナリオも想定しました。
Meta は現在、音声認識、音声合成、言語認識用に個別のモデルをトレーニングしていますが、研究者らは、将来的には 1 つのモデルだけでこれらすべてのタスクを完了できるようになると考えています。よりも。
以上がスケールとパフォーマンスで OpenAI を倍増させた Meta Voice が、LLaMA レベルのマイルストーンに到達しました。オープンソースの MMS モデルは 1100 以上の言語を認識しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。