
ホームページ >テクノロジー周辺機器 >AI >1 日に 4 つの主要データベースで 100 以上の脆弱性を自動的に発見、浙江大学の研究が SIGMOD 2023 で最優秀論文を受賞
1 日に 4 つの主要データベースで 100 以上の脆弱性を自動的に発見、浙江大学の研究が SIGMOD 2023 で最優秀論文を受賞

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-24 15:58:061008ブラウズ
2023 ACM SIGMOD/PODS International Conference on Data Management (SIGMOD 2023) は、現地時間 6 月 18 日から 23 日まで米国シアトルで開催されます。このカンファレンスは最近、最優秀論文のリストを発表し、Microsoft Researchの「データサイエンスパイプラインの述語プッシュダウン」と浙江大学の「DBMSにおける結合最適化のロジックバグの検出」が受賞した。 1975年の創設以来、中国本土の研究チームが同会議で最優秀論文賞を受賞するのは初めて。その中で、浙江大学の研究は、MySQL、MariaDB、TiDB、PolarDB などのデータベース管理システムの論理的脆弱性を自動的に発見できる新しい方法を提案しました。

過去数十年にわたり、最新のデータベース管理システム (DBMS) は、クラウド プラットフォームなどのさまざまな新しいアーキテクチャをサポートするために進化し続けてきました。 HTAP では、クエリ評価のますます高度な最適化が必要になります。クエリ オプティマイザーは DBMS で最も複雑かつ重要なコンポーネントの 1 つであると考えられており、その機能は入力 SQL クエリを解析し、組み込みのコスト モデルを利用して効率的な実行プランを生成することです。クエリ オプティマイザーの実装におけるエラーは、クラッシュの脆弱性やロジック ホールなどの脆弱性 (バグ) を引き起こす可能性があります。クラッシュが発生するとシステムが即座に停止するため、クラッシュの脆弱性は簡単に検出できます。ただし、ロジックの脆弱性は、DBMS が検出が難しい誤った結果セットを返す原因となる可能性があるため、見落とされがちです。このペーパーでは、これらのサイレント脆弱性の検出に焦点を当てます。

DBMS の論理脆弱性を検出する新しいアプローチ、つまりピボットクエリ合成 (PQS) が登場しました。このメソッドの中心的な考え方は、テーブルからピボット行 (ピボット行) をランダムに選択し、この行を結果として含むクエリを生成することです。合成されたクエリがそのデータ行を返せない場合は、ロジックの脆弱性が検出されました。 PQS は主に単一テーブルのオプション クエリをサポートするために使用され、報告された脆弱性の 90% は単一テーブル クエリのみに関係しています。異なる結合アルゴリズムと結合構造を使用する複数テーブル クエリ (単一テーブル クエリよりもエラーが発生しやすい) については、まだ研究の余地が大きくあります。
次の図は、MySQL でのクエリの接続における 2 つの論理的な抜け穴を示しています。どちらの脆弱性も、この記事で提案されている新しいツールを使用して検出できます。
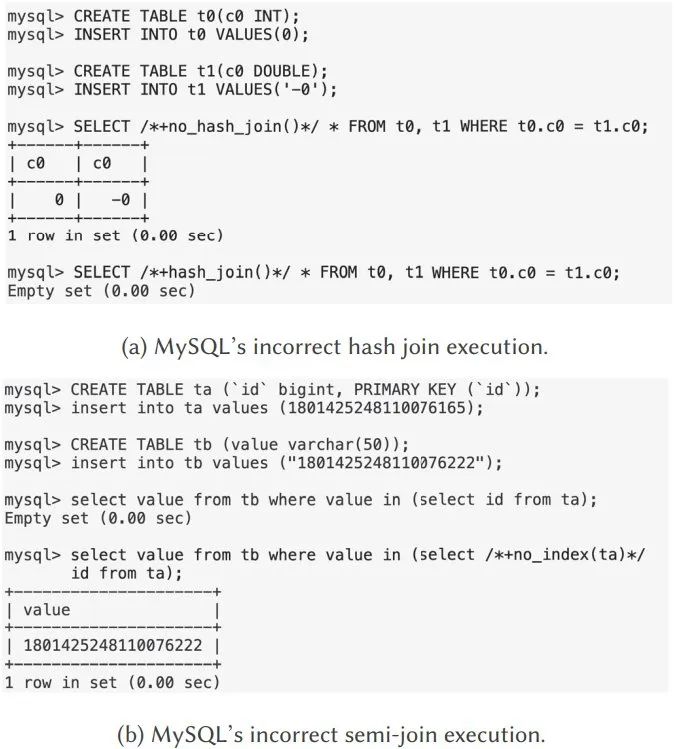
#図 1: DBMS の結合最適化における論理的脆弱性の例
# 図 1(a) は、MySQL 8.0.18 のハッシュ結合におけるロジックの脆弱性を示しています。この例では、最初のクエリはブロック ネスト ループ結合を使用して実行されるため、正しい結果セットが返されます。ただし、内部ハッシュ結合を使用した 2 番目のクエリは失敗し、誤って空の結果セットを返しました。これは、基礎となるハッシュ結合アルゴリズムが 0 が -0 に等しくないという誤った想定を行っているためです。
図 1 (b) のロジックの脆弱性は、MySQL 8.0.28 のセミ結合処理に起因します。最初のクエリでは、ネストされたループの内部結合によってデータ型 varchar が bigint に変換され、正しい結果セットが得られます。ハッシュセミ結合を使用して 2 番目のクエリを実行すると、データ型 varchar が double に変換されるため、データの精度が失われ、同等の比較でエラーが発生します。
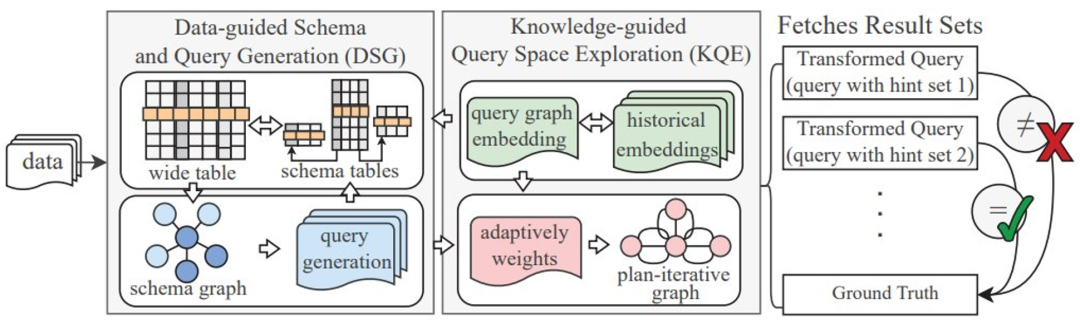
#複数テーブル結合クエリの論理脆弱性検出にクエリ合成手法を使用することは、単一テーブル クエリよりもはるかに困難です。これには次の 2 つの課題が伴います:上記の問題に対応して、浙江大学の研究者は、Transformed Query Synthesis (TQS) と呼ばれる手法を提案しました。 TQS は、DBMS の結合最適化における論理脆弱性を検出するタスク用の、新しく汎用的でコスト効率の高いツールです。 上記の最初の課題に対応して、研究者によって提案された解決策は、データガイド付きスキーマとクエリ生成の略である DSG です。) 。データ セットが幅の広いテーブルとして表される場合、DSG は、検出されたパラダイムに基づいてデータ セットを複数のテーブルに分割できます。脆弱性の発見を迅速化するために、DSG は生成されたデータベースに人工ノイズ データも注入します。まず、データベース スキーマをグラフに変換します。ノードはテーブル/列、エッジはノード間の関係です。 DSG は、パターン グラフ上でランダム ウォークを使用してクエリ用のテーブルを選択し、これらのテーブルを使用して結合を生成します。複数のテーブルを含む特定の結合クエリの場合、広いテーブルから真実の結果を簡単に見つけることができます。このようにして、DSG はデータベース検証用のコレクション (クエリ、結果) を効果的に生成できます。 #上記の 2 番目の課題に対応して、研究者によって設計された手法は、知識誘導型のクエリ空間探索である KQE です。このアプローチは、パターン グラフをクエリ生成空間全体を表す計画反復グラフに拡張することから始まります。各結合クエリはサブグラフとして表されます。生成されたクエリ グラフをスコアリングするために、KQE は埋め込みベースのグラフ インデックスを採用し、すでに探索された空間から構造的に類似したクエリ グラフを検索します。ランダム ウォーク クエリ ジェネレーターは、カバレッジ スコアに基づいて、未知のクエリ空間を可能な限り探索するようにガイドされます。 #この方法の多用途性と有効性を実証するために、研究者らは、一般的に使用される 4 つの DBMS (MySQL、MariaDB、TiDB、PolarDB) で TQS を評価しました 。 24 時間の実行後、TQS は 115 件の脆弱性の発見に成功しました。そのうち 31 件は MySQL、30 件は MariaDB、31 件は TiDB、23 件は PolarDB でした。根本原因を分析することでこれらの脆弱性の種類をまとめると、MySQL で 7 種類、MariaDB で 5 種類、TiDB で 5 種類、PolarDB で 3 種類の脆弱性があります。研究者らは発見した脆弱性を適切なコミュニティに提出し、肯定的なフィードバックを受け取りました。 以下では、解決すべき問題と浙江大学が提案する解決策を数学的な形式で説明します。 データベースの脆弱性には、クラッシュと論理的脆弱性の 2 種類があります。クラッシュの脆弱性は、オペレーティング システムと DBMS の実行によって発生します。メモリなどのリソース不足や無効なメモリアドレスへのアクセスなどの理由により、DBMS が強制終了する可能性があります。したがって、クラッシュの脆弱性は簡単に発見されます。データベースは引き続き正常に実行され、クエリを処理し、一見正しい結果を返すため、ロジックの脆弱性を見つけるのははるかに困難です (ほとんどの場合、正しい結果が返されますが、場合によっては間違った結果セットを読み取る可能性があります)。これらのサイレント脆弱性は目に見えない爆弾のようなもので、検出が難しく、アプリケーションの正確さに影響を与える可能性があるため、より危険です。 このペーパーでは、複数テーブルの結合クエリの問題に対する論理的な脆弱性を検出するクエリ オプティマイザーを紹介します。研究者はこれらの脆弱性を結合最適化バグと呼んでいます。表 1 に示す表記を使用すると、結合最適化の脆弱性検出問題は次のように正式に定義できます。 定義: クエリ ワークロード Q 内の各クエリ qi に対して、クエリを最適化します。サーバーは次のように実行します。複数の実際の計画を介して qi を結合し、グラウンド トゥルース #表 1: シンボル説明表 図 2 は、TQS のアーキテクチャの概要を示しています。ベースライン データ セットとターゲット DBMS が与えられると、TQS はデータ セットに基づいてクエリを生成することにより、DBMS 内の潜在的な論理的脆弱性を検索します。 TQS には、データに基づいたスキーマおよびクエリ生成 (DSG) と知識に基づいたクエリ空間探索 (KQE) という 2 つの主要なコンポーネントがあります。 図 2: TQS の概要 DSG は、元のタプルに加えて、入力データ セットを広いテーブルとして扱います。 , DSG は、エラーが発生しやすい値 (null 値や非常に長い文字列など) を含む一部のタプルも意図的に合成します。結合クエリの場合、DSG はワイド テーブルを複数のテーブルに分割することでワイド テーブルの新しいスキーマを作成し、テーブルが関数依存関係ベースのパラダイムに確実に準拠するようにします。 DSG はデータベース スキーマをグラフとしてモデル化し、スキーマ グラフ上のランダム ウォークを通じて論理/概念的クエリを生成します。 DSG は、論理クエリを物理的な実行プランに具体化し、さまざまなヒントを使用してクエリを変換します。これにより、DBMS は複数の異なる物理的な実行プランを実行して脆弱性を検索できるようになります。結合クエリの場合、グランド トゥルースの結果は、結合グラフをワイド テーブルにマッピングし直すことによって取得されます。 スキーマのセットアップとデータ分割が完了すると、KQE はスキーマ図を計画反復図に拡張します。各クエリはサブグラフとして表されます。 KQE は、履歴内 (つまり、すでに探索されたクエリ空間内) のクエリ グラフの埋め込みに対して、埋め込みベースのグラフ インデックスを構築します。直観的に言えば、KQE の役割は、新しく生成されたクエリ グラフが履歴内で最も近いクエリ グラフからできるだけ遠く離れていることを確認することです。つまり、これは、既存のクエリ グラフを繰り返すのではなく、新しいクエリ グラフを探索することです。 KQE は、適応ランダム ウォーク法を使用してクエリを生成しながら、(履歴内のクエリ グラフとの) 構造的類似性に基づいて、生成されたクエリ グラフをスコアリングすることによってこれを行います。 。 アルゴリズム 1 は、TQS の核となる考え方を要約したもので、2、10、12 行目は DSG、4、8、9 行目は KQE です。 データセット KQE は、パターン図を計画反復図に拡張します (4 行目)。同様のパスのテストを避けるために、KQE は埋め込みベースのグラフ インデックス を構築して、既存のクエリ グラフの埋め込みにインデックスを付けます (9 行目)。 KQE は、現在のクエリ グラフと既存のクエリ グラフの間の構造的類似性に基づいて、計画反復グラフ G のエッジの重み π を更新します (8 行目)。 KQE は、ランダム ウォーク ジェネレーターをガイドする次の可能なパスをスコア付けし、それによって未知のクエリ空間の探索を優先します。 クエリ DSG と KQE の詳細については、元の論文をお読みください。 TQS は、MySQL、MariaDB、TiDB、PolarDB などのデータベース管理システムの論理的な脆弱性をいくつか発見することに成功し、それらは MySQL の 7 つの脆弱性と 7 つの脆弱性を含む 20 種類に分類されます。 MariaDB には、以下の表に示すように、TiDB が 5 種類、PolarDB が 5 種類、PolarDB が 3 種類あります。 他の方法と比較して、浙江大学が提案した TQS の全体的なパフォーマンスも非常に優れており、多くの指標で大幅な改善を達成しています。優れた結果が得られ、各コンポーネントの有効性も制御変数実験を通じてテストされました。 しかし研究者らは、TQS が現在等結合クエリに重点を置いているとも述べています。それにもかかわらず、DSG と KQE のアイデアは非等価結合の場合にも拡張できます。唯一の困難は、クエリの真の結果を生成および管理する方法です。非等結合の場合、これらの結果のサイズは指数関数的に増加します。この点については、今後さらに研究が必要です。
問題の定義
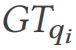
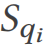 を使用してその結果セットを検証します。
を使用してその結果セットを検証します。 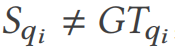 の場合、接続最適化の脆弱性が見つかりました。
の場合、接続最適化の脆弱性が見つかりました。 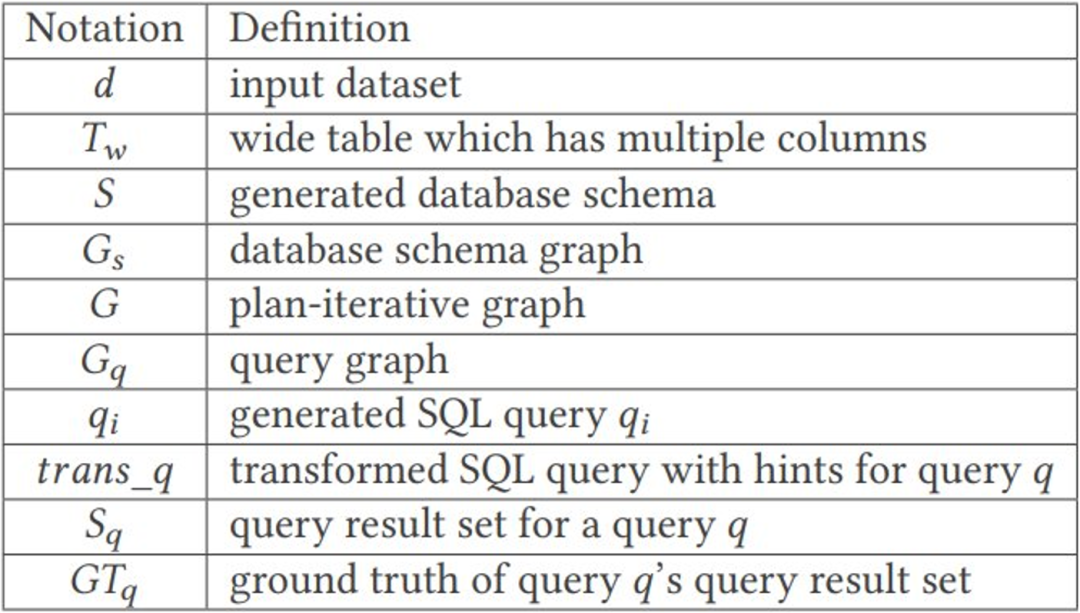
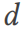 と
と 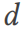 からサンプリングされた幅広いテーブル
からサンプリングされた幅広いテーブル 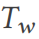 がある場合、DSG はテーブル # を実行します。
がある場合、DSG はテーブル # を実行します。 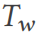 ## は複数のテーブルに分割されており、これらのテーブルは 3NF に準拠したデータベース スキーマ
## は複数のテーブルに分割されており、これらのテーブルは 3NF に準拠したデータベース スキーマ 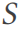 (行 2) を形成します。パターン
(行 2) を形成します。パターン 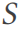 はグラフ
はグラフ 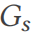 として表示できます。テーブルと列は頂点であり、エッジは頂点間の関係を表します。 DSG は、
として表示できます。テーブルと列は頂点であり、エッジは頂点間の関係を表します。 DSG は、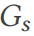 でランダム ウォークを使用して、クエリの結合式を生成します (行 10)。実際、結合クエリは
でランダム ウォークを使用して、クエリの結合式を生成します (行 10)。実際、結合クエリは 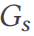 のサブグラフとして投影できます。 DSG は、サブグラフをワイド テーブル
のサブグラフとして投影できます。 DSG は、サブグラフをワイド テーブル 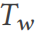 (行 12) にマッピングし直すことで、このクエリのグラウンド トゥルース結果を簡単に取得できます。
(行 12) にマッピングし直すことで、このクエリのグラウンド トゥルース結果を簡単に取得できます。 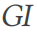
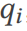 の場合、TQS はプロンプト セット を通じてクエリを変換し、複数の異なる実際のクエリ プランを実行します (セクション 11 OK)。最後に、クエリ
の場合、TQS はプロンプト セット を通じてクエリを変換し、複数の異なる実際のクエリ プランを実行します (セクション 11 OK)。最後に、クエリ 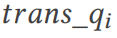
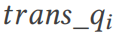 # の結果セットがグラウンド トゥルース値
# の結果セットがグラウンド トゥルース値 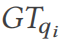 (14 行目) と比較されます。それらが矛盾している場合は、結合最適化の脆弱性が検出されています (15 行目)。
(14 行目) と比較されます。それらが矛盾している場合は、結合最適化の脆弱性が検出されています (15 行目)。 実験結果
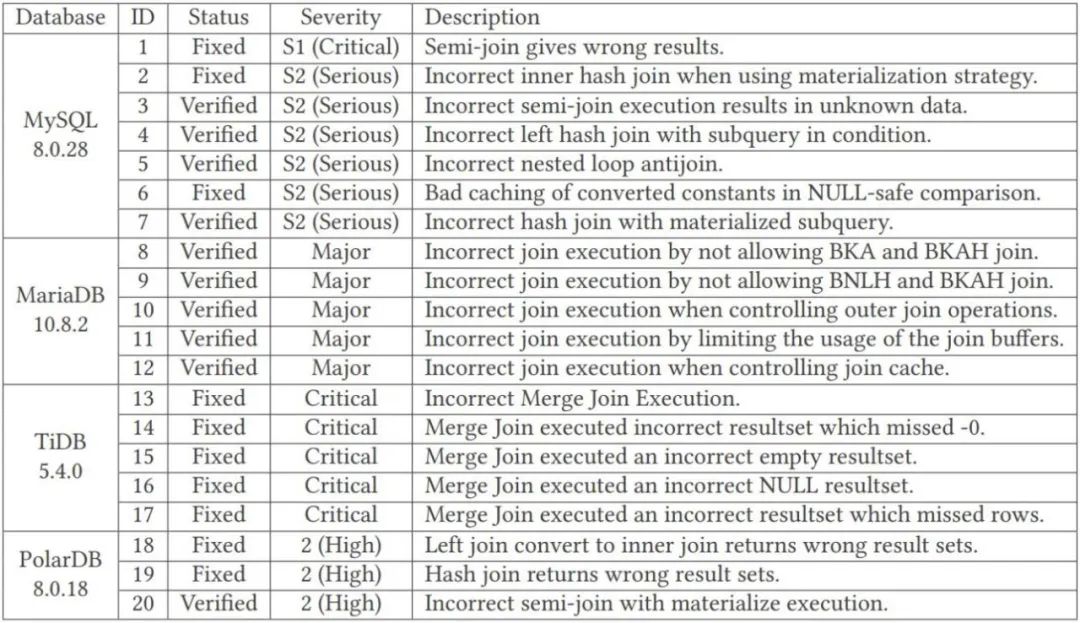
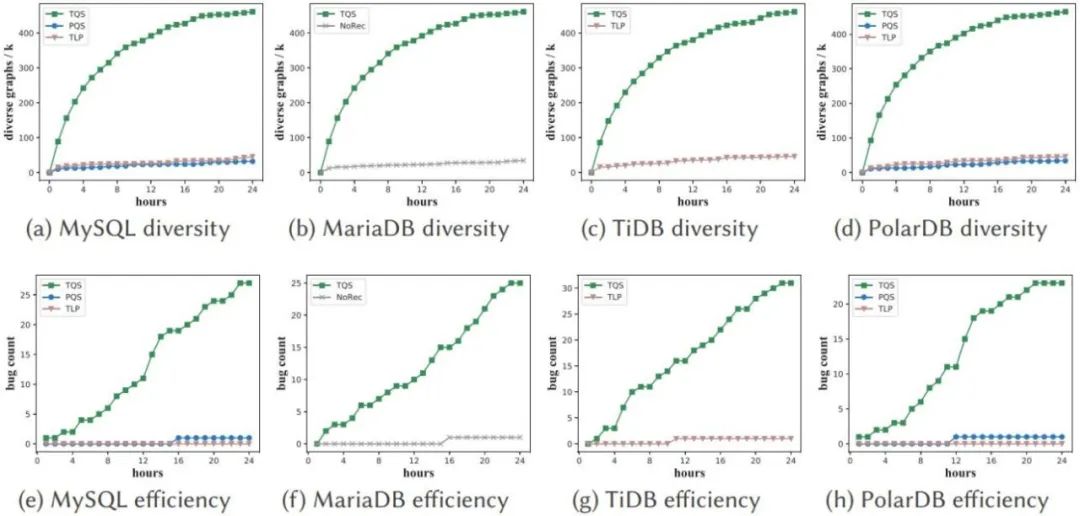
以上が1 日に 4 つの主要データベースで 100 以上の脆弱性を自動的に発見、浙江大学の研究が SIGMOD 2023 で最優秀論文を受賞の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。