
ホームページ >バックエンド開発 >Python チュートリアル >Python で動的視覚化チャートを描くのはとてもクールです!
Python で動的視覚化チャートを描くのはとてもクールです!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-24 12:01:062629ブラウズ

ストーリーテリングはデータ サイエンティストにとって重要なスキルです。自分の考えを表現し、他の人を説得するには、効果的にコミュニケーションする必要があります。そして、美しいビジュアライゼーションは、このタスクに最適なツールです。
この記事では、データ ストーリーをより美しく効果的にする、従来とは異なる 5 つの視覚化テクニックを紹介します。ここでは Python の Plotly グラフィックス ライブラリが使用され、アニメーション チャートやインタラクティブなチャートを簡単に生成できます。
モジュールをインストールする
Plotly をまだインストールしていない場合は、ターミナルで次のコマンドを実行するだけでインストールを完了できます:
pip install plotly
ビジュアル ダイナミック グラフ
さまざまな指標の進化を研究するとき、時間データが関係することがよくあります。以下の図に示すように、Plotly アニメーション ツールに必要なコードは 1 行だけで、時間の経過に伴うデータの変化を観察できます。
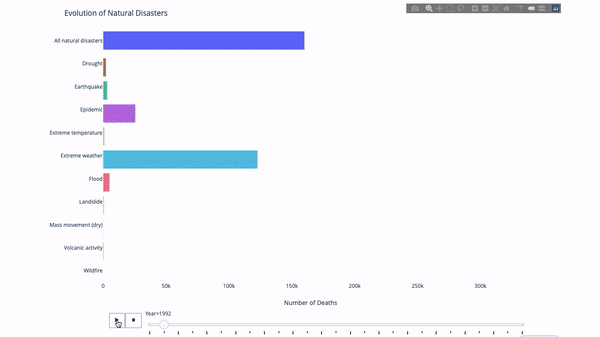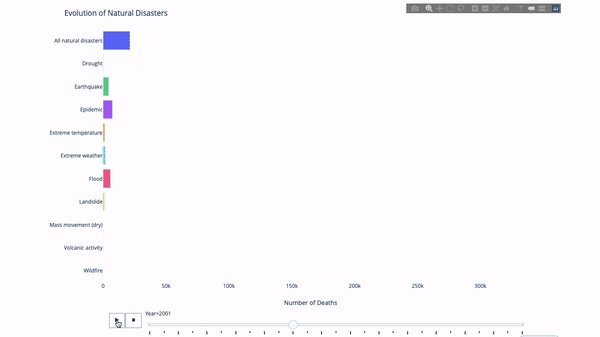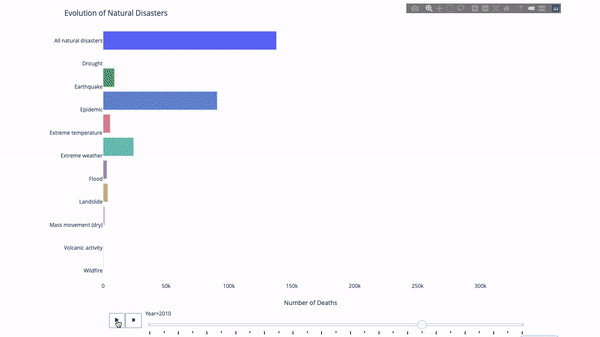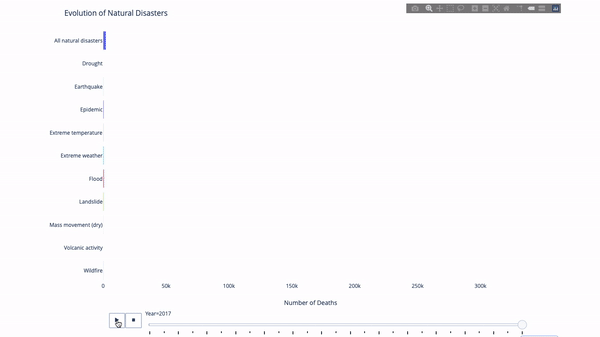
コードは次のとおりです。
import plotly.express as px from vega_datasets import data df = data.disasters() df = df[df.Year > 1990] fig = px.bar(df, y="Entity", x="Deaths", animation_frame="Year", orientation='h', range_x=[0, df.Deaths.max()], color="Entity") # improve aesthetics (size, grids etc.) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', title_text='Evolution of Natural Disasters', showlegend=False) fig.update_xaxes(title_text='Number of Deaths') fig.update_yaxes(title_text='') fig.show()
フィルターに適用する時間変数がある限り、ほぼすべてのチャートをアニメーション化できます。以下は、散布図アニメーションの作成例です。
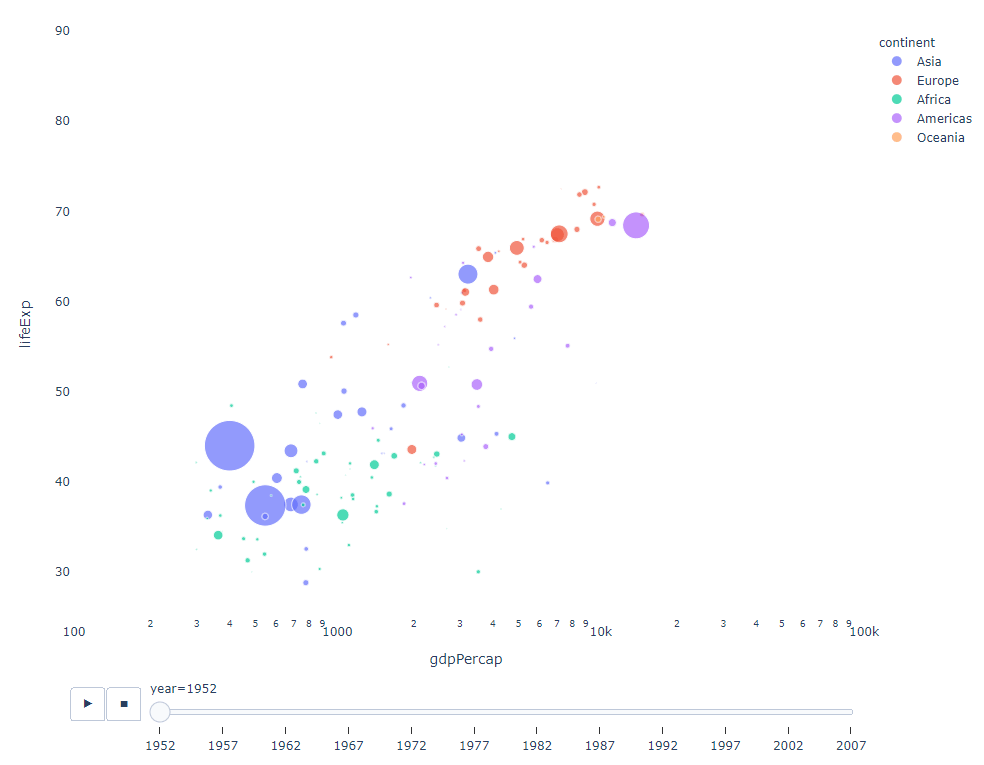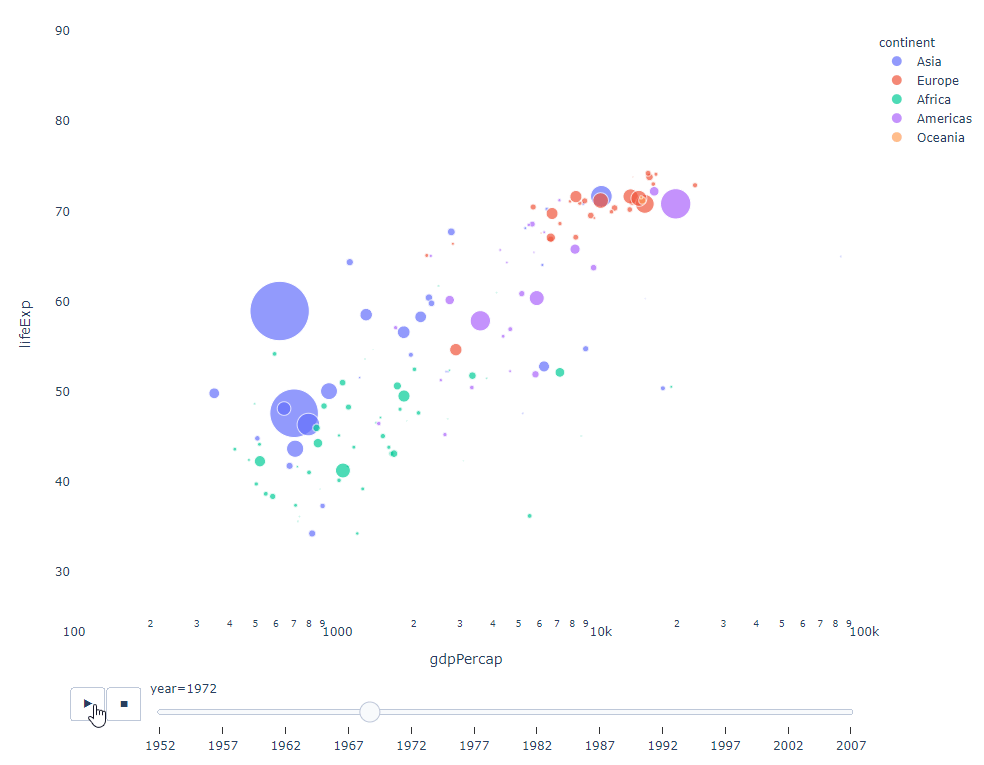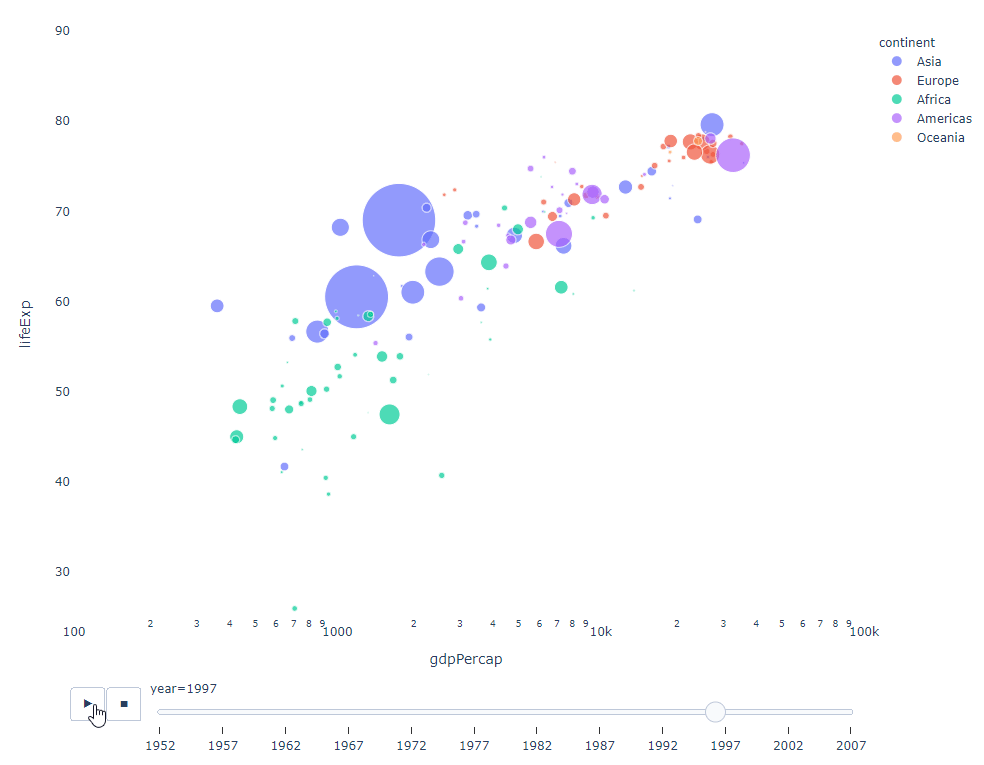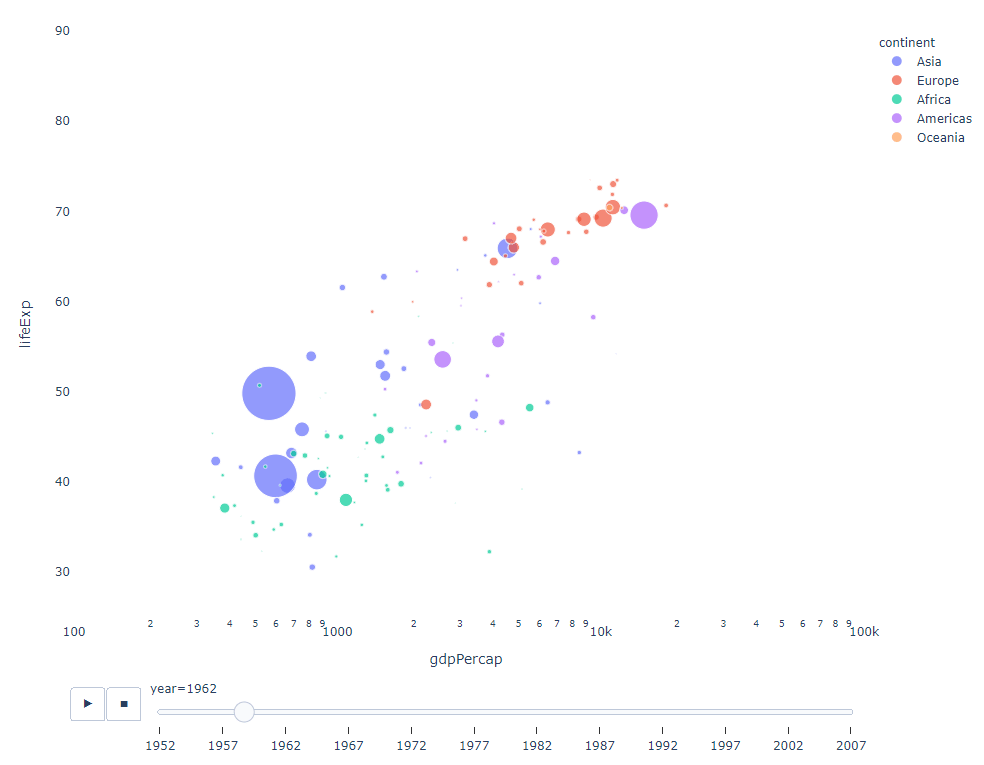
import plotly.express as px df = px.data.gapminder() fig = px.scatter( df, x="gdpPercap", y="lifeExp", animation_frame="year", size="pop", color="continent", hover_name="country", log_x=True, size_max=55, range_x=[100, 100000], range_y=[25, 90], # color_continuous_scale=px.colors.sequential.Emrld ) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
サンバースト チャート
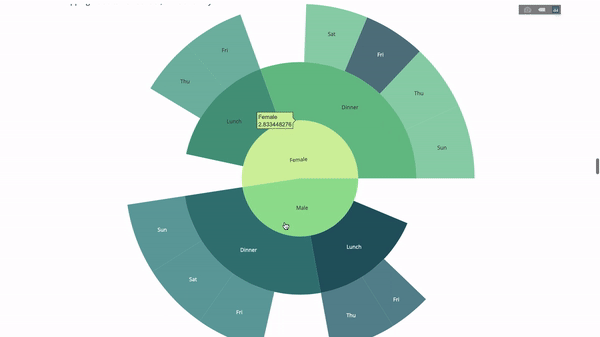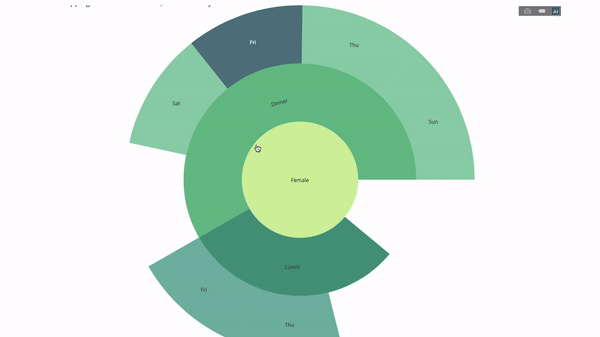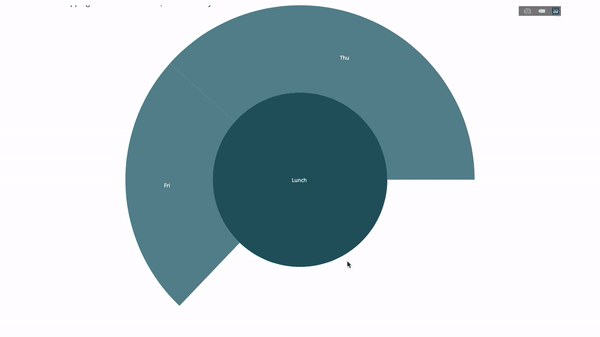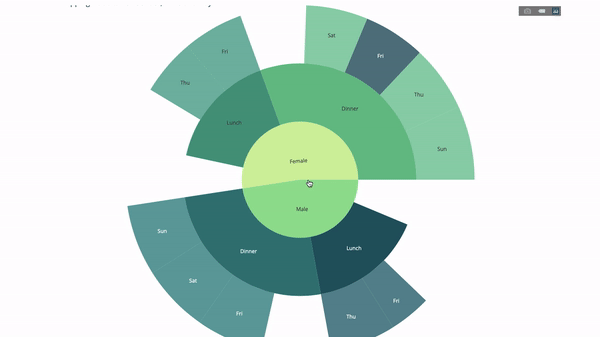
サンバースト チャートは、ステートメントごとのグループを視覚化するのに適した方法です。方法。特定の数量を 1 つ以上のカテゴリ変数で分類する場合は、太陽グラフを使用します。
平均チップ データを性別と時間帯に応じて分類したいとします。この 2 つの group by ステートメントは、表と比較して視覚化することでより効果的に表示できます。
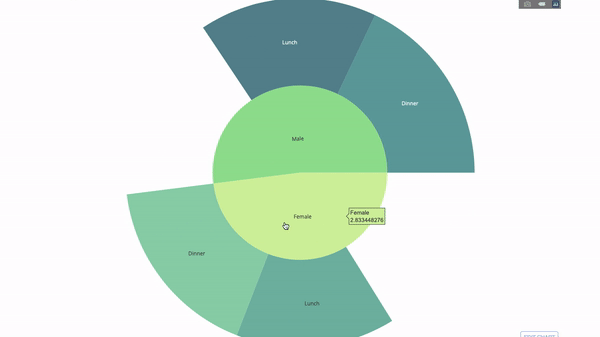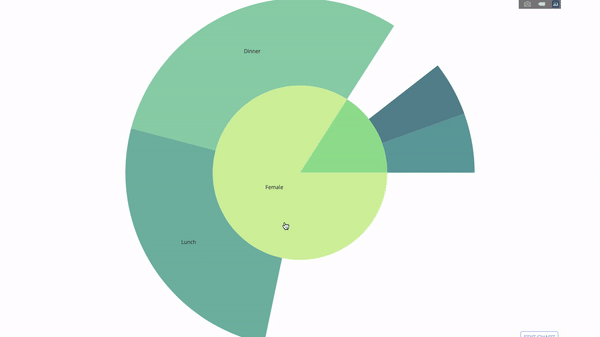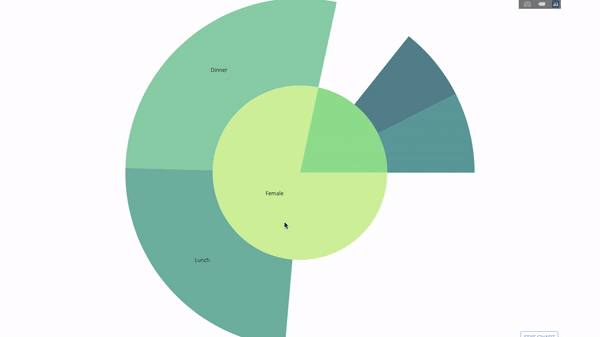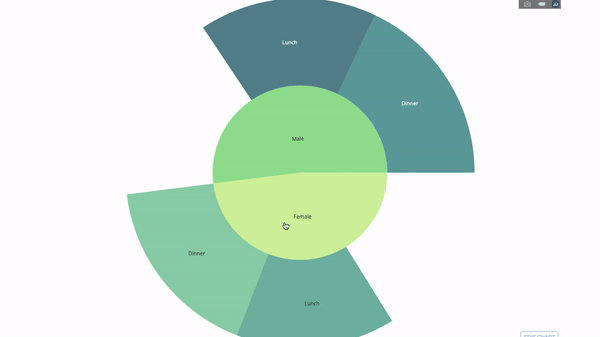
このグラフはインタラクティブなので、クリックして自分でカテゴリを探索できます。すべてのカテゴリを定義し、カテゴリ間の階層を宣言し (以下のコードのparents パラメータを参照)、対応する値を割り当てるだけです。この場合、これは group by ステートメントの出力です。
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
ここで、この階層にもう 1 つのレイヤーを追加します。
これを行うには、3 つのカテゴリ変数値を含む別の group by ステートメントを追加します。
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri', 'Sat', 'Sun', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
ポインタ図
ポインタ図は見た目だけを目的としています。 KPI などの成功指標をレポートし、それらが目標にどれだけ近づいているかを示す場合は、このタイプのグラフを使用します。
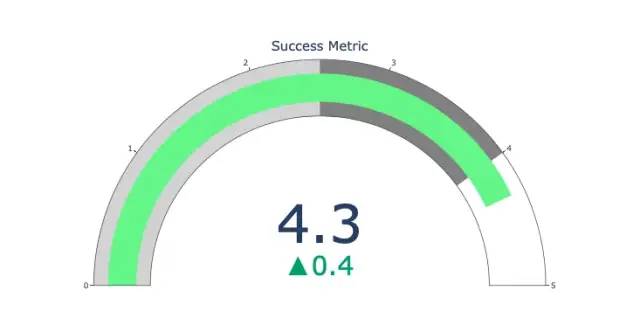
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
Sankey Plot
カテゴリ変数間の関係を調べるもう 1 つの方法は、次のような平行座標プロットです。いつでも値をドラッグ、ドロップ、ハイライト表示、参照できるので、プレゼンテーションに最適です。
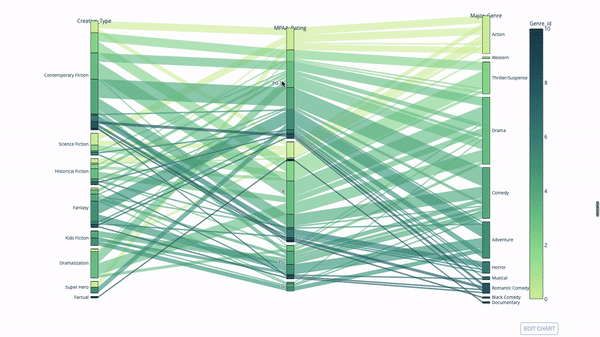
コードは次のとおりです。
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_categories( df, dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'], color="Genre_id", color_continuous_scale=px.colors.sequential.Emrld, ) fig.show()
平行座標チャート
平行座標チャートは、上記のチャートから派生したものです。ここで、各文字列は 1 つの観測値を表します。これは、外れ値 (データの残りの部分から遠く離れた単一の線)、クラスター、傾向、および冗長変数 (たとえば、2 つの変数がすべての観測で同様の値を持つ場合、それらはは同じ水平線上にあり、冗長性の存在を示す便利なツールです)。
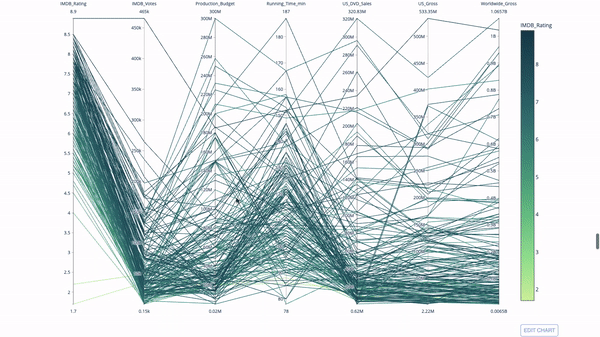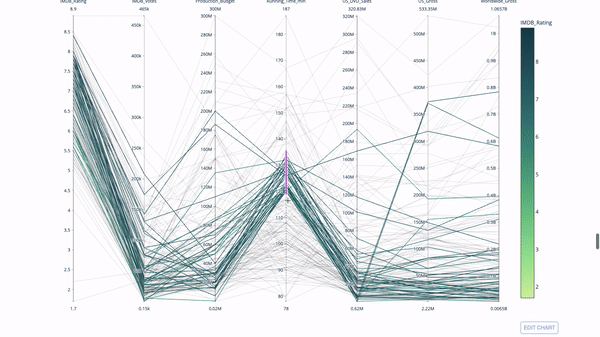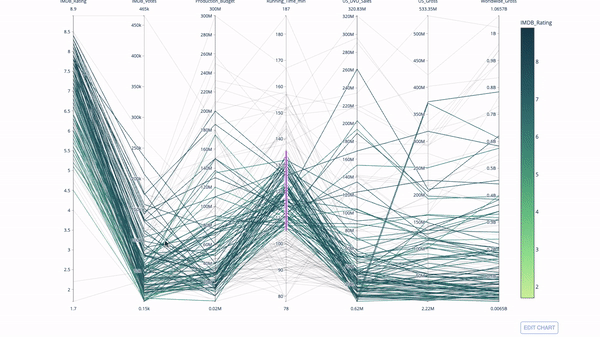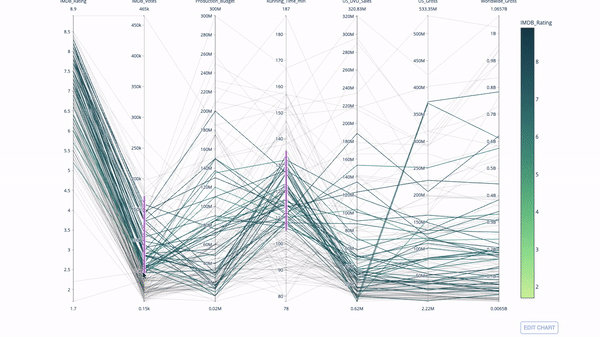
コードは次のとおりです:
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_coordinates( df, dimensions=[ 'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales' ], color='IMDB_Rating', color_continuous_scale=px.colors.sequential.Emrld) fig.show()
以上がPython で動的視覚化チャートを描くのはとてもクールです!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。