
ホームページ >テクノロジー周辺機器 >AI >PandaLM、北京大学、西湖大学などのオープンソース「審判大規模モデル」: ChatGPT の 94% の精度で LLM を完全に自動的に評価する 3 行のコード
PandaLM、北京大学、西湖大学などのオープンソース「審判大規模モデル」: ChatGPT の 94% の精度で LLM を完全に自動的に評価する 3 行のコード

- 王林転載
- 2023-05-19 11:55:051840ブラウズ
ChatGPT のリリース後、自然言語処理分野のエコシステムは完全に変わり、これまで解決できなかった多くの問題が ChatGPT を使用することで解決できるようになりました。
しかし、大きなモデルの性能が強すぎて、各モデルの違いを肉眼で評価するのが難しいという問題もあります。
たとえば、モデルの複数のバージョンが異なる基本モデルとハイパーパラメーターを使用してトレーニングされた場合、パフォーマンスは例と同様になる可能性があり、2 つのモデル間のパフォーマンスのギャップを完全に埋めることはできません。定量化された。
現在、大規模な言語モデルを評価するには 2 つの主なオプションがあります:1. 評価のために OpenAI の API インターフェイスを呼び出します。
ChatGPT は 2 つのモデルの出力の品質を評価するために使用できますが、ChatGPT は繰り返しアップグレードされています。同じ質問に対する異なる時点での応答は異なる場合があり、評価は結果は存在します
問題を再現できません##。2. 手動アノテーション
クラウドソーシング プラットフォームで手動アノテーションを依頼する場合は、資金が不足しているチーム
余裕がなければ、サードパーティ企業がデータを漏洩するケースもあります。 このような「大規模モデル評価問題」を解決するために、北京大学、ウェストレイク大学、ノースカロライナ州立大学、カーネギーメロン大学、MSRA の研究者が協力して PandaLM を開発しました。新しい言語モデル評価フレームワークは、プライバシー保護、信頼性、再現性、そして安価な大規模モデル評価ソリューションの実現に取り組んでいます。
プロジェクトリンク: https://github.com/WeOpenML/PandaLM
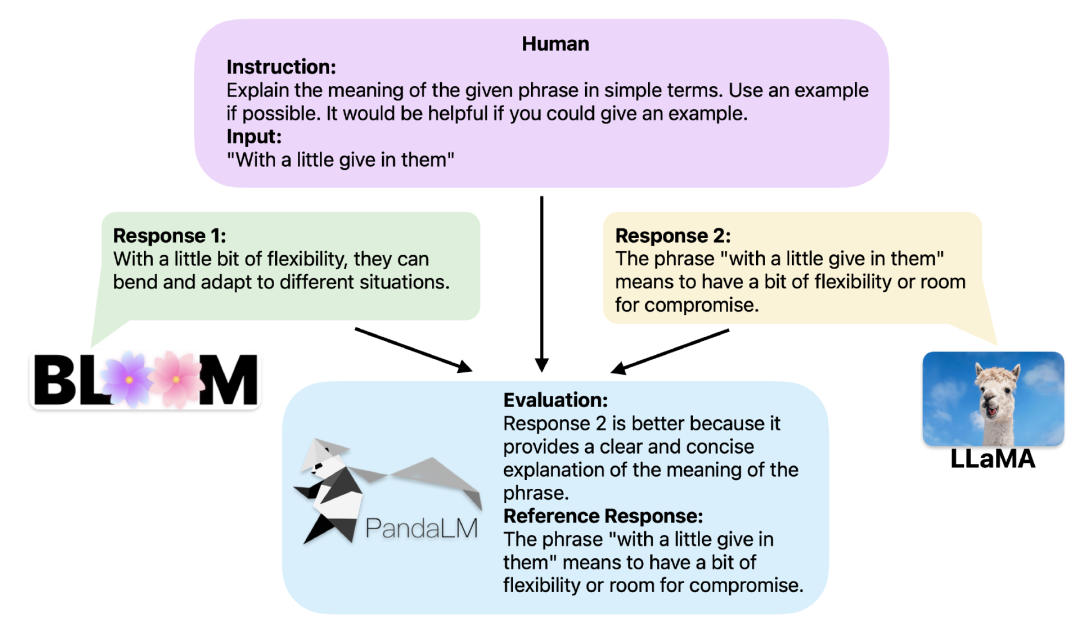
同じコンテキストが提供されると、PandaLM は異なる LLM の応答出力を比較し、特定の理由を提供できます。
ツールの信頼性と一貫性を実証するために、研究者らは約 1,000 個のサンプルからなる人間による注釈付きの多様なテスト データセットを作成しました。その中で PandaLM-7B の精度は ## の 94% に達しました。 #ChatGPT の評価機能。
PandaLM を使用した 3 行のコード2 つの異なる大規模モデルが同じ命令とコンテキストに対して異なる応答を生成する場合、PandaLM は 2 つの大規模モデルを比較するように設計されています。モデルの応答品質を確認し、比較結果、比較理由、参照用の応答を出力します。
3 つの比較結果があります。応答 1 の方が優れており、応答 2 の方が優れており、応答 1 と応答 2 は同様の品質です。
複数の大規模モデルのパフォーマンスを比較する場合、PandaLM を使用してそれらをペアで比較し、ペアごとの比較の結果を要約して、複数のモデルのパフォーマンスをランク付けまたは描画するだけです。大規模モデル: モデルの半順序関係図により、異なるモデル間のパフォーマンスの違いを明確かつ直感的に分析できます。
PandaLM は「ローカルに展開」するだけでよく、「人間の参加を必要としない」ため、PandaLM の評価はプライバシーを保護でき、非常に安価です。
より良い解釈性を提供するために、PandaLM はその選択を自然言語で説明し、追加の参照応答セットを生成することもできます。
このプロジェクトでは、研究者はケース分析のために Web UI を使用した PandaLM の使用をサポートするだけでなく、また、任意のモデルやデータによって生成されたテキスト評価のために PandaLM を呼び出すための 3 行のコードもサポートしています。
既存のモデルやフレームワークの多くがオープンソースではないか、ローカルで推論を完了することが難しいことを考慮して、PandaLM は、指定されたモデルの重みを使用して評価対象のテキストを生成するか、評価対象のテキストを含む .json ファイルを直接渡すことをサポートしています。評価されました。 ユーザーは、モデル名/HuggingFace モデル ID または .json ファイル パスを含むリストを渡すだけで、PandaLM を使用してユーザー定義モデルを評価し、データを入力できます。以下は最小限の使用例です: 
#誰もが PandaLM を柔軟に無料評価できるようにするために、研究者はPandaLM のモデルの重みは、huggingface の Web サイトでも公開されており、次のコマンドを使用して PandaLM-7B モデルをロードできます:

PandaLM の特徴
再現性
PandaLM の重みは公開されるため、言語モデルにはランダム性があり、ランダムシードが固定されている場合、PandaLMの評価結果は常に一貫性を保つことができます。
オンライン API に基づくモデルの更新は透過的ではなく、その出力は時間によって非常に一貫性がなくなる可能性があり、モデルの古いバージョンにはアクセスできなくなります。オンライン API に基づく評価にはアクセスできないことがよくあります。
自動化、プライバシー保護、低オーバーヘッド
PandaLM モデルをローカルにデプロイし、既製のコマンドを呼び出すだけですアノテーションのために専門家を雇うなど、専門家と常にコミュニケーションをとらなくても、さまざまな大規模モデルの評価を開始でき、情報漏えいの問題もなく、API利用料や人件費もかからないため、手軽に評価を開始できます。とても安い。
評価レベル
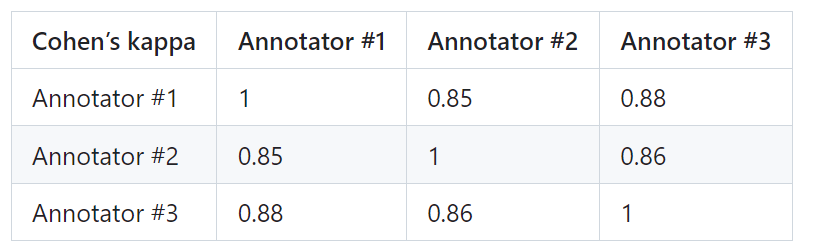
PandaLM の信頼性を証明するために、研究者は 3 人の専門家を雇い、独立した繰り返しアノテーションを実施しました。手動で注釈が付けられたテスト セットが作成されました。
テスト セットには 50 の異なるシナリオが含まれており、各シナリオには複数のタスクが含まれています。このテスト セットは多様性があり、信頼性が高く、テキストに対する人間の好みと一致しています。テスト セットの各サンプルは、命令とコンテキスト、および異なる大規模モデルによって生成された 2 つの応答で構成され、2 つの応答の品質は人間によって比較されます。
アノテーター間で大きな差があるサンプルを選別して、最終的なテスト セットでの各アノテーターの IAA (アノテーター間合意) が 0.85 に近いことを確認します。 PandaLM のトレーニング セットには、手動でアノテーションを付けて作成されたテスト セットと重複がないことは注目に値します。
#これらのフィルタリングされたサンプルには、判断を支援するために追加の知識や入手困難な情報が必要であり、人間にとっては困難です正確にラベルを付けます。
フィルタリングされたテスト セットには 1000 個のサンプルが含まれていますが、フィルタリングされていない元のテスト セットには 2500 個のサンプルが含まれています。テスト セットの分布は {0:105, 1:422, 2:472} です。ここで、0 は 2 つの応答が同様の品質であることを示し、1 は応答 1 の方が優れていることを示し、2 は応答 2 の方が優れていることを示します。人間のテスト セットをベンチマークとして使用した場合、PandaLM と gpt-3.5-turbo のパフォーマンスの比較は次のとおりです。
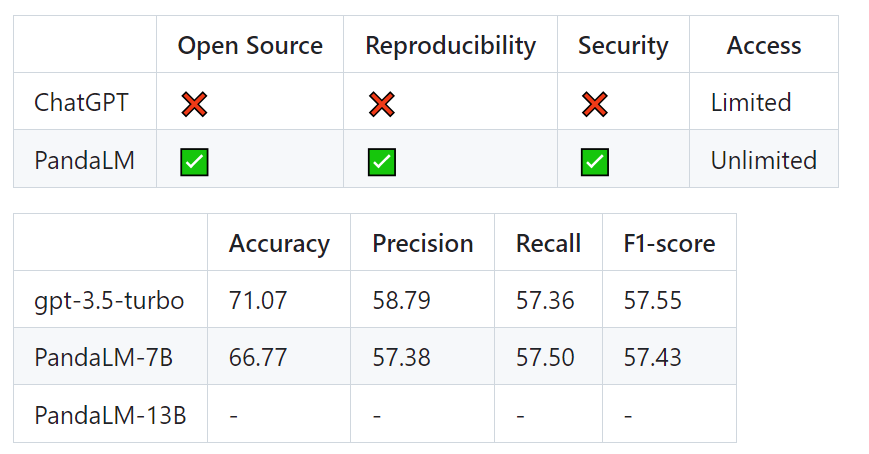
次のことがわかります。 PandaLM-7B の精度は gpt-3.5-turbo の 94% のレベルに達しており、精度、再現率、F1 スコアの点で、PandaLM-7B は gpt-3.5-turbo とほぼ同等です。
したがって、gpt-3.5-turboと比較して、PandaLM-7Bはすでにかなりの大規模モデル評価能力を備えていると考えられます。
テスト セットの精度、適合率、再現率、F1 スコアに加えて、同様のサイズの 5 つの大規模なオープンソース モデル間の比較結果も提供されます。
最初に同じトレーニング データを使用して 5 つのモデルを微調整し、次に人間、gpt-3.5-turbo、および PandaLM を使用して 5 つのモデルを個別に比較しました。
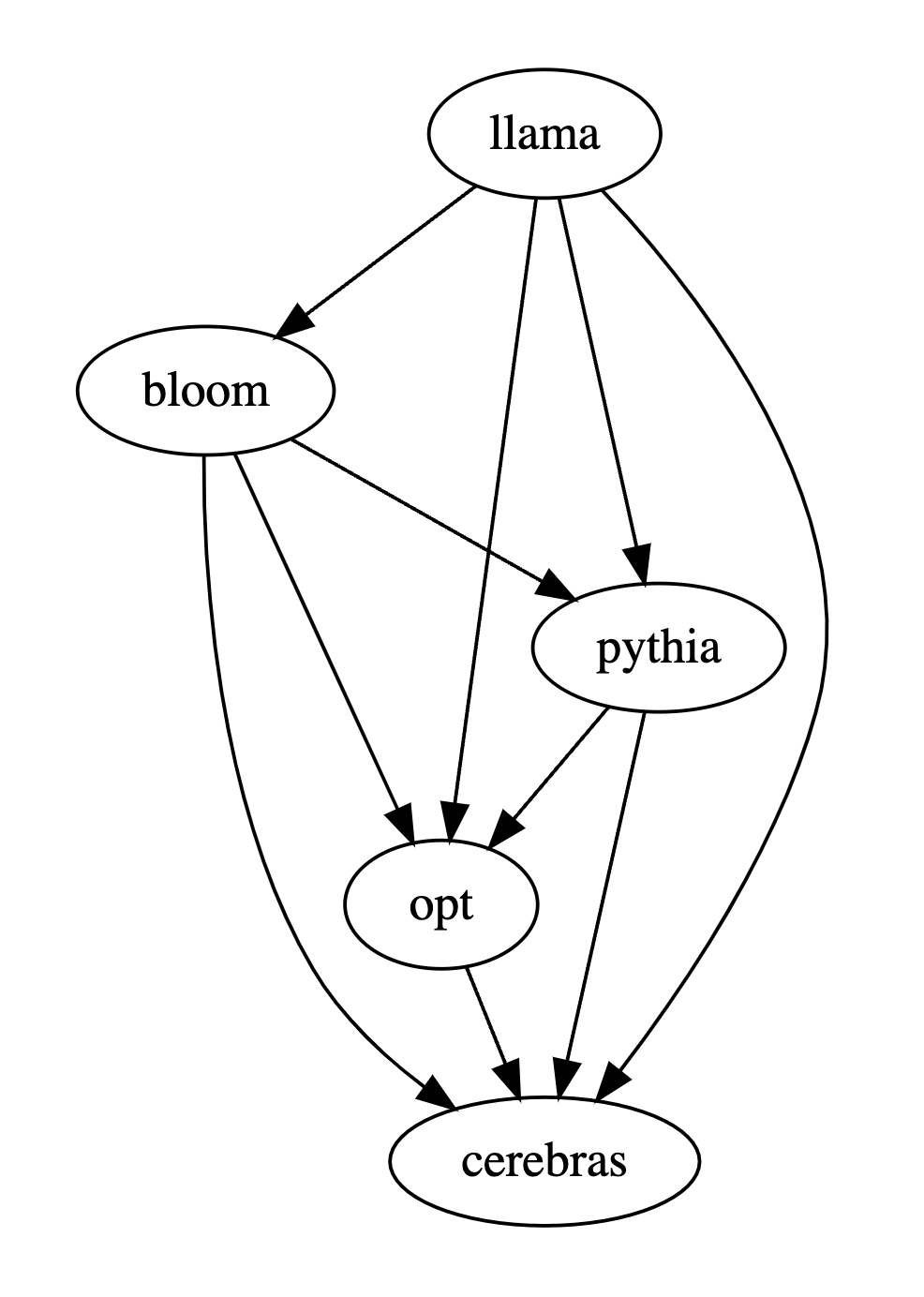
以下の表の最初の行の最初のタプル (72、28、11) は、Bloom-7B よりも優れた LLaMA-7B 応答が 72 個あることを示しています。 28 LLaMA -7B の応答は Bloom-7B よりも悪く、2 つのモデル間で同様の品質の応答が 11 件あります。
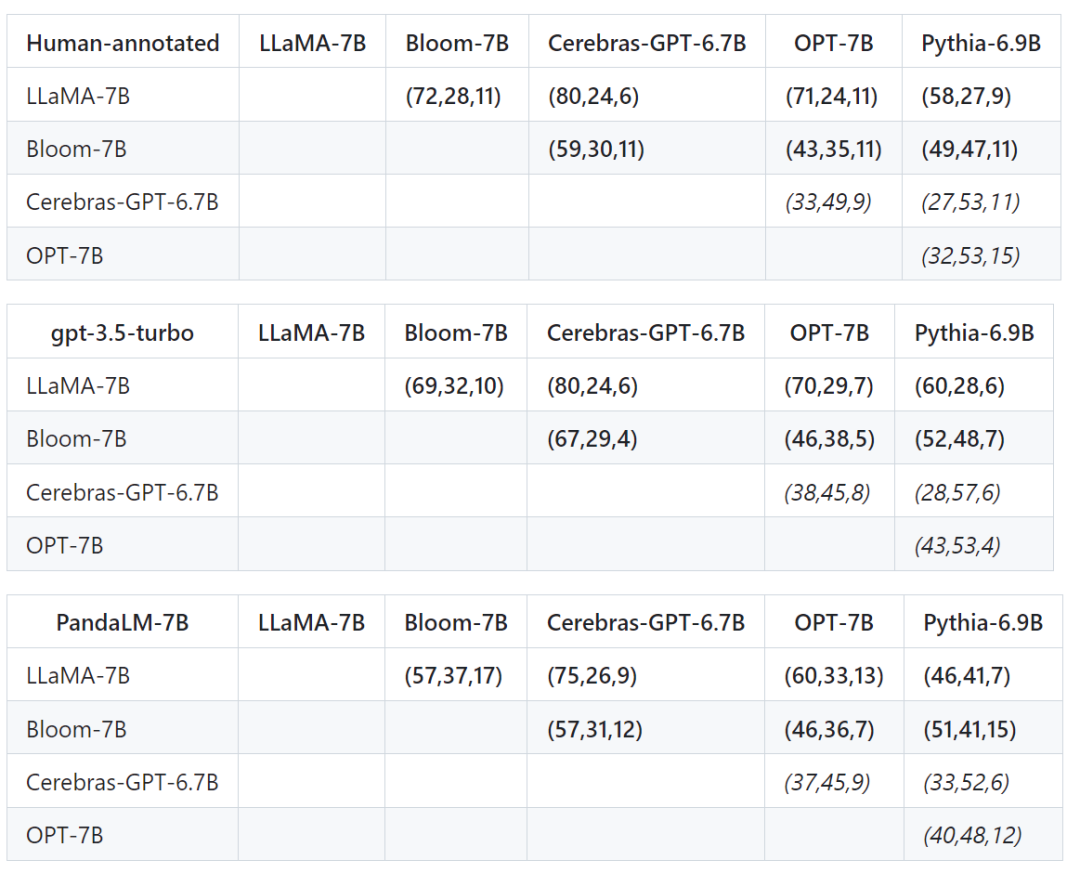
つまり、この例では、人間は LLaMA-7B が Bloom-7B よりも優れていると考えています。次の 3 つの表の結果は、人間、gpt-3.5-turbo、および PandaLM-7B が各モデルの長所と短所の関係について完全に一貫した判断を行っていることを示しています。
概要
PandaLM は人間による評価と OpenAI API の評価に加えて 3 番目の記事を提供します。大規模なモデルを評価するために、PandaLM は高い評価レベルを備えているだけでなく、再現可能な評価結果、自動化された評価プロセス、プライバシー保護、および低いオーバーヘッドを備えています。
今後、PandaLM は学術界や産業界で大規模モデルの研究を推進し、より多くの人が大規模モデルの開発から恩恵を受けられるようにしていきます。
以上がPandaLM、北京大学、西湖大学などのオープンソース「審判大規模モデル」: ChatGPT の 94% の精度で LLM を完全に自動的に評価する 3 行のコードの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。