
ホームページ >バックエンド開発 >Python チュートリアル >Python イメージを保存してアクセスする 3 つの方法は何ですか?
Python イメージを保存してアクセスする 3 つの方法は何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-16 21:08:301793ブラウズ
はじめに
ImageNet は、オブジェクトの分類、検出、セグメンテーションなどのタスクのモデルをトレーニングするために使用されるよく知られた公開画像データベースであり、1,400 万を超える画像が含まれています。
たとえば、Python で画像データを処理する場合、畳み込みニューラル ネットワーク (CNN とも呼ばれる) などのアルゴリズムを適用すると、大量の画像データ セットを処理できます。ここでは、データを保存および読み取る方法を学習する必要があります。最も簡単な方法です。
画像データの処理、ファイルの読み書きにかかる時間、ディスクメモリの使用量などを定量的に比較する方法が必要です。
さまざまな方法を使用して、画像の保存とパフォーマンスの最適化の問題を処理および解決します。
データの準備
再生可能なデータ セット
私たちがよく知っている画像データ セット CIFAR-10 は、60,000 個の 32x32 ピクセルのカラー画像で構成されており、これらの画像はさまざまなオブジェクト カテゴリに属しています。 、犬、猫、飛行機など。 CIFAR は比較的大きなデータセットではありませんが、TinyImages データセット全体を使用すると、約 400 GB の空きディスク容量が必要になります。
この記事のコードは、データ セットのダウンロード アドレス CIFAR-10 データ セットに適用されます。
このデータは、cPickle を使用してシリアル化され、バッチで保存されます。 pickle モジュールは、追加のコードや変換を必要とせずに、Python で任意のオブジェクトをシリアル化できます。ただし、大量のデータを処理すると、評価できないセキュリティ リスクが生じる可能性があります。
NumPy 配列への画像の読み込み
import numpy as np
import pickle
from pathlib import Path
# 文件路径
data_dir = Path("data/cifar-10-batches-py/")
# 解码功能
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# 每个图像都是扁平化的,通道按 R, G, B 的顺序排列
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# 重建原始图像
images.append(np.dstack((im_channels)))
# 保存标签
labels.append(batch_data[b"labels"][i])
print("加载 CIFAR-10 训练集:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")画像ストレージの設定
画像処理用のサードパーティ ライブラリ Pillow をインストールします。
pip install Pillow
LMDB
「Lightning メモリ マップ データベース」(LMDB) は、その速度とメモリ マップ ファイルの使用のため、「Lightning データベース」とも呼ばれます。これはキーと値のストアであり、リレーショナル データベースではありません。
画像処理用のサードパーティ ライブラリ lmdb をインストールします。
pip install lmdb
HDF5
HDF5 は Hierarchical Data Format の略で、HDF4 または HDF5 として知られるファイル形式です。このポータブルでコンパクトな科学データ形式は、国立スーパーコンピューティング アプリケーション センターから提供されています。
画像処理用のサードパーティ ライブラリ h6py をインストールします。
pip install h6py
単一画像ストレージ
3 種類のデータ読み取り方法
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")同時に読み込んだデータは別のフォルダーに保存可能
disk_dir.mkdir(parents=True, exist_ok=True) lmdb_dir.mkdir(parents=True, exist_ok=True) hdf5_dir.mkdir(parents=True, exist_ok=True)
保存先disc
Pillow の使用 入力は単一のイメージ画像であり、NumPy 配列としてメモリに保存され、一意のイメージ ID image_id で名前が付けられます。
単一イメージがディスクに保存されました
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" 将单个图像作为 .png 文件存储在磁盘上。
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])LMDB に保存されました
LMDB はキーと値のペアのストレージ システムであり、各エントリはバイト配列として保存され、キーは各画像の一意の識別子であり、値は画像自体になります。
キーと値は両方とも文字列である必要があります。一般的な使用法は、値を文字列にシリアル化し、それを読み取るときに逆シリアル化することです。
再構成に使用される画像サイズ。一部のデータ セットには異なるサイズの画像が含まれる場合があり、この方法が使用されます。
class CIFAR_Image:
def __init__(self, image, label):
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" 将图像作为 numpy 数组返回 """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)単一イメージを LMDB に保存
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" 将单个图像存储到 LMDB
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()ストレージ HDF5
1 つの HDF5 ファイルに複数のデータセットを含めることができます。画像用とメタデータ用の 2 つのデータセットを作成できます。
import h6py
def store_single_hdf5(image, image_id, label):
""" 将单个图像存储到 HDF5 文件
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"image", np.shape(image), h6py.h6t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h6py.h6t.STD_U8BE, data=label
)
file.close()ストレージ比較
単一の画像を保存する 3 つの関数をすべて辞書に入れます。
_store_single_funcs = dict(
disk=store_single_disk,
lmdb=store_single_lmdb,
hdf5=store_single_hdf5
)CIFAR の最初の画像とそれに対応するタグを 3 つの異なる方法で保存します。
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"存储方法: {method}, 使用耗时: {t}")比較してみましょう。
| ストレージ方法 | ストレージ消費時間 | メモリの使用 |
|---|---|---|
| ディスク | 2.1 ミリ秒 | 8 K |
| LMDB | 1.7 ミリ秒 | 32 K |
| HDF5 | 8.1 ms | 8 K |
複数画像の保存
単一画像と同じ画像 保存方法も同様で、複数の画像データを保存するようにコードを変更します。
複数の画像調整コード
複数の画像を .png ファイルとして保存することは、store_single_method() メソッドを複数回呼び出すこととみなすことができます。各イメージが異なるデータベース ファイルに存在するため、LMDB または HDF5 ではこのアプローチは不可能です。
画像のグループをディスクに保存する
store_many_disk(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 一张一张保存所有图片
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# 将所有标签保存到 csv 文件
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
writer.writerow([label])画像のグループを LMDB に保存する
def store_many_lmdb(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# 为所有图像创建一个新的 LMDB 数据库
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# 在一个事务中写入所有图像
with env.begin(write=True) as txn:
for i in range(num_images):
# 所有键值对都必须是字符串
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()画像のグループを HDF5 に保存する
def store_many_hdf5(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"images", np.shape(images), h6py.h6t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h6py.h6t.STD_U8BE, data=labels
)
file.close()データセットの準備比較
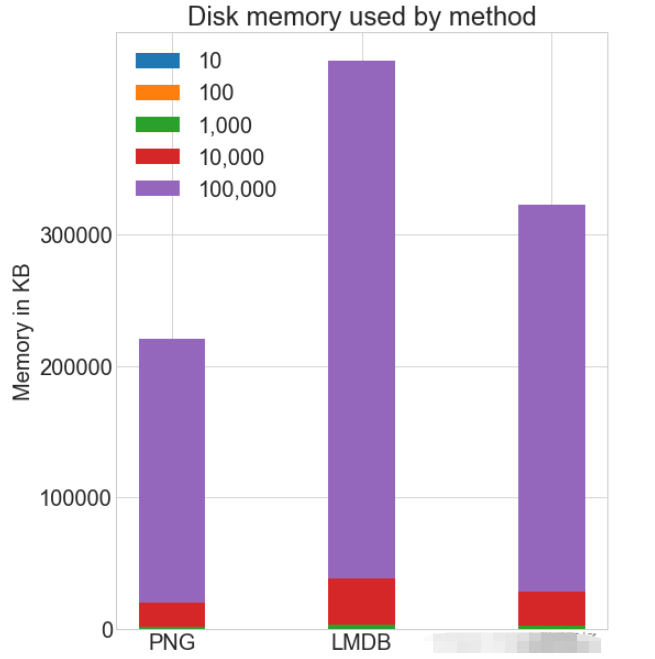
100000画像を使用したテスト
cutoffs = [10, 100, 1000, 10000, 100000] images = np.concatenate((images, images), axis=0) labels = np.concatenate((labels, labels), axis=0) # 确保有 100,000 个图像和标签 print(np.shape(images)) print(np.shape(labels))
比較のための計算を作成
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# 打印出方法、截止时间和使用时间
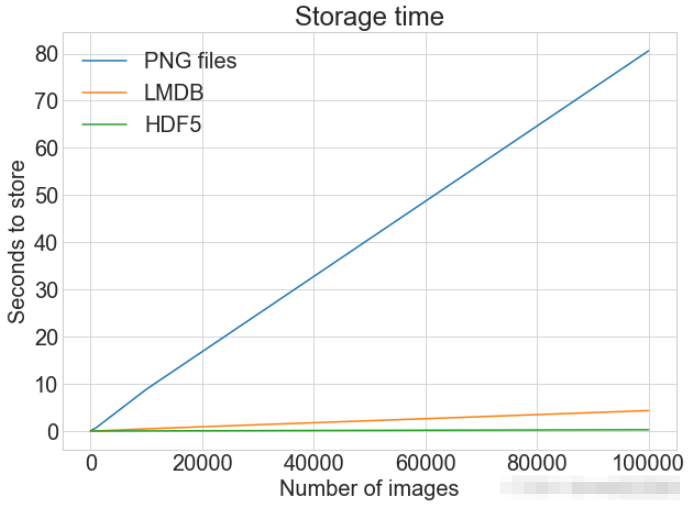
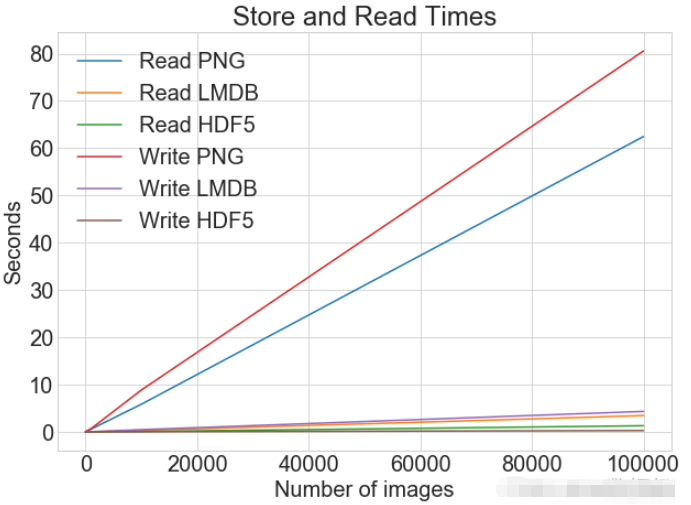
print(f"Method: {method}, Time usage: {t}")PLOTは、複数のデータセットと一致する凡例を含む単一のプロットを表示します
import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" 参数:
--------------
x_range 包含 x 数据的列表
y_data 包含 y 值的列表
legend_labels 字符串图例标签列表
x_label x 轴标签
y_label y 轴标签
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"数据集的数量与标签的数量不匹配"
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
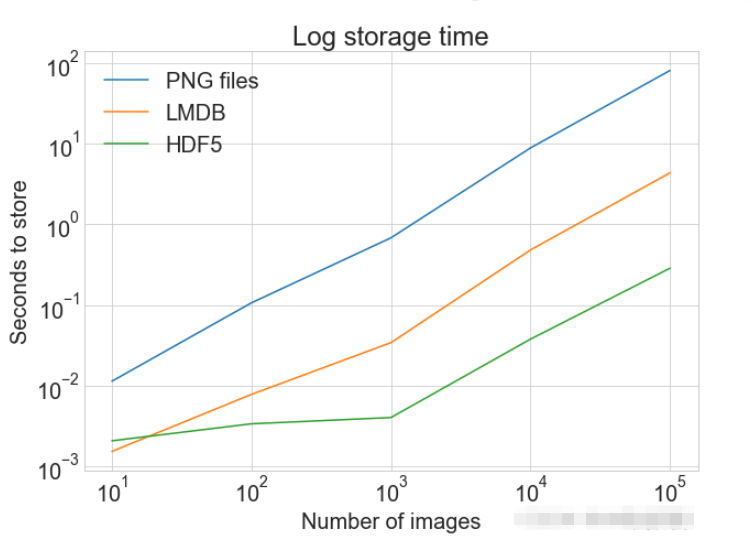
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)
def read_single_disk(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, label
LMDB からの読み取り Getdef read_single_lmdb(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 LMDB 环境
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 进行编码
data = txn.get(f"{image_id:08}".encode("ascii"))
# 加载的 CIFAR_Image 对象
cifar_image = pickle.loads(data)
# 检索相关位
image = cifar_image.get_image()
label = cifar_image.label
env.close()
return image, label
読み取り元HDF5def read_single_hdf5(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "r+")
image = np.array(file["/image"]).astype("uint8")
label = int(np.array(file["/meta"]).astype("uint8"))
return image, label
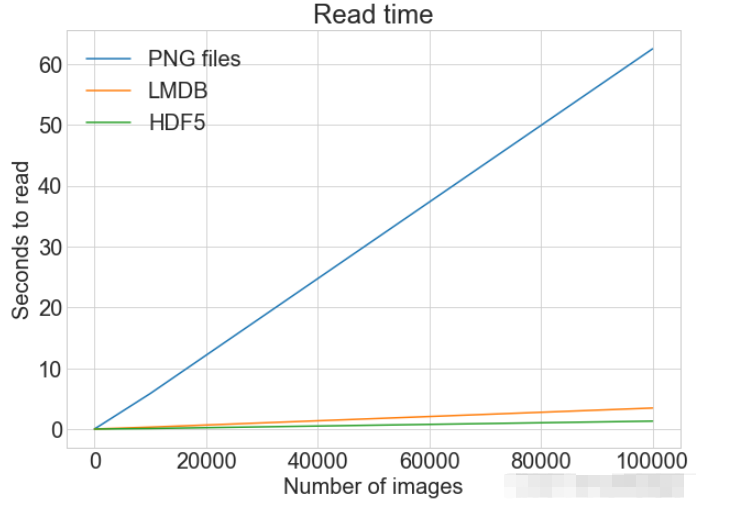
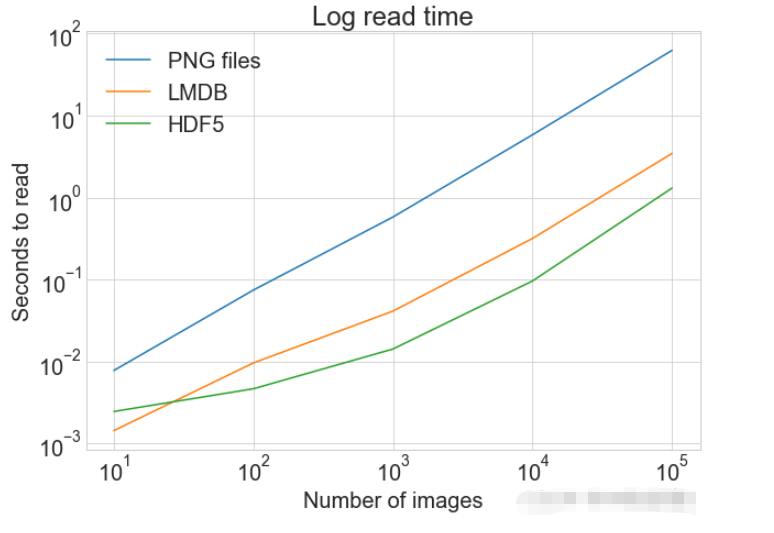
読み取り方式の比較from timeit import timeit
read_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_single_funcs[method](0)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
read_single_timings[method] = t
print(f"读取方法: {method}, 使用耗时: {t}")
| ストレージ消費時間 | |
|---|---|
| 1.7 ms | |
| 4.4 ms | |
| 2.3 MS############ |
以上がPython イメージを保存してアクセスする 3 つの方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。