
ホームページ >バックエンド開発 >Python チュートリアル >Python で連鎖呼び出しを実装する方法
Python で連鎖呼び出しを実装する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-15 18:28:062285ブラウズ
なぜチェーンコールなのでしょうか?
チェーン呼び出し、またはメソッド チェーンとも呼ばれるのは、文字通り、一連の操作または関数メソッドをチェーンのようにつなぎ合わせるコード メソッドを意味します。
私はチェーンコールの「美しさ」に初めて気づき、R言語のパイプライン演算子を使い始めました。
library(tidyverse) mtcars %>% group_by(cyl) %>% summarise(meanmeanOfdisp = mean(disp)) %>% ggplot(aes(x=as.factor(cyl), y=meanOfdisp, fill=as.factor(seq(1,3))))+ geom_bar(stat = 'identity') + guides(fill=F)
R ユーザーは、このコード部分でプロセス全体のステップが何であるかをすぐに理解できます。すべては記号 %>% (パイプ演算子) で始まります。
パイプ演算子を介して、左側のものを次のものに渡すことができます。ここでは、mtcars データ セットを group_by 関数に渡し、次にその結果を summary 関数に渡し、最後に視覚的な描画のために ggplot 関数に渡します。
もし私がチェーン呼び出しを学ばなかったら、最初に R 言語を学んだときに次のように書いていたでしょう:
library(tidyverse) cyl4 <p>パイプ演算子を使用しなかったら、不要なものを作成するでしょう。 assigns を作成し、元のデータ オブジェクトを上書きしますが、実際には cyl# とその中で生成されるデータは実際にはグラフ ピクチャを提供するためにのみ使用されるため、コードが冗長になるという問題があります。 </p><p>チェーン呼び出しはコードを大幅に簡素化するだけでなく、コードの可読性を向上させ、各ステップが何を行っているかをすぐに理解できるようにします。この方法はデータ分析やデータ処理に非常に役立ち、不要な変数の作成を減らし、迅速かつ簡単な方法で探索を行うことができます。 </p><p>チェーンコールやパイプライン操作は色々なところで見られますが、ここではR言語以外の代表的な例を2つ紹介します。 </p><p>1 つはシェル ステートメントです: </p><pre class="brush:php;toolbar:false">echo "`seq 1 100`" | grep -e "^[3-4].*" | tr "3" "*"
シェル ステートメントで「|」パイプ演算子を使用すると、チェーン呼び出しをすばやく実装できます。ここでは、最初に 1 ~ 100 のすべての整数を出力し、次に Passそれを grep メソッドに入力し、3 または 4 で始まるすべての部分を抽出し、この部分を tr メソッドに渡し、3 を含む数字の部分をアスタリスクに置き換えます。結果は次のようになります:
もう 1 つは Scala 言語です:
object Test { def main(args: Array[String]): Unit = { val numOfseq = (1 to 100).toList val chain = numOfseq.filter(_%2==0) .map(_*2) .take(10) } }この例では、最初に numOfseq 変数に 1 ~ 100 のすべての整数が含まれ、次にチェーン部分から始まり、まず、numOfseq に基づいて filter メソッドを呼び出してこれらの数値の中から偶数をフィルタリングし、次に、map メソッドを呼び出してフィルタリングされた数値を 2 倍し、最後に take メソッドを使用して最初の 10 個の数値を取り出します。新しく形成された数値、数値、これらの数値は一緒にチェーン変数に割り当てられます。
上記の説明を通じて、チェーンコールについての予備的な印象を持っていただけたと思いますが、チェーンコールをマスターすると、コーディングスタイルが変わるだけでなく、プログラミングの思考もさまざまな改善が見られます。
Python の連鎖呼び出し
Python で単純な連鎖呼び出しを実装するには、クラス メソッドを構築し、オブジェクト自体を返すか、所属するクラス (@classmethod ) を返します。
class Chain: def __init__(self, name): self.name = name def introduce(self): print("hello, my name is %s" % self.name) return self def talk(self): print("Can we make a friend?") return self def greet(self): print("Hey! How are you?") return self if __name__ == '__main__': chain = Chain(name = "jobs") chain.introduce() print("-"*20) chain.introduce().talk() print("-"*20) chain.introduce().talk().greet()ここでは、Chain クラスを作成し、インスタンス オブジェクトを作成するために名前文字列パラメータを渡す必要があります。このクラスには、introduction、talk、greet という 3 つのメソッドがあります。
毎回 self が返されるので、オブジェクトの所属クラスのメソッドを継続的に呼び出すことができ、結果は次のようになります:
hello, my name is jobs -------------------- hello, my name is jobs Can we make a friend? -------------------- hello, my name is jobs Can we make a friend? Hey! How are you?
Pandas でチェーン呼び出しを使用する
ここまで道を切り開いてきたので、いよいよ Pandas のチェーン呼び出し部分について説明します。
Pandas のほとんどのメソッドは API によって処理されるため、チェーン メソッドを使用した操作に適しています。 Series 型または DataFrame 型が多いため、対応するメソッドを直接呼び出すことができます ここでは、今年の 2 月頃に他の人向けにケースのデモを行ったときにクロールした Huanong Brothers B ステーションのビデオ データを例に挙げます。リンクから取得できます。
データ フィールド情報は次のとおりです。300 個のデータと 20 個のフィールドがあります:
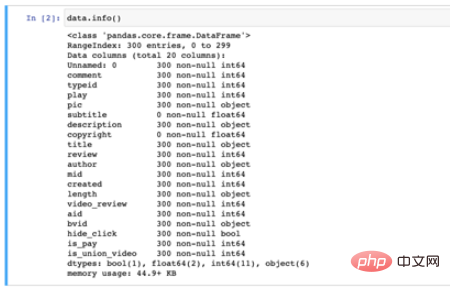
フィールド情報
ただし使用中ですデータのこの部分の前に、データのこの部分の予備クリーニングを行う必要があります。ここでは主に次のフィールドを選択しました:
補助: に対応する AV 番号video
comment: コメント数
play: 再生回数
title: タイトル
-
video_review: コメント数
- # 作成日: アップロード日
- # 長さ: 動画の長さ
各フィールドの対応する値は次のとおりです:
#フィールド値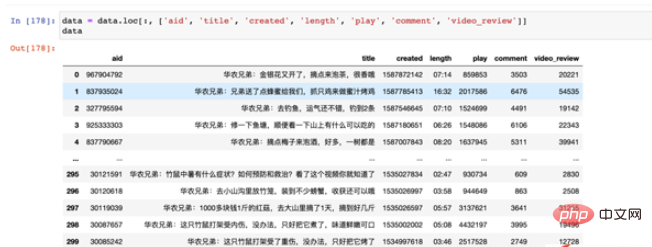
- 作成 アップロード日は長い一連の値として表示されているように見えますが、実際には 1970 年のタイムスタンプですこれを判読可能な年、月、日の形式に処理する必要があります;
length 播放量长度只显示了分秒,但是小时并未用「00」来进行补全,因此这里我们一方面需要将其补全,另一方面要将其转换成对应的时间格式
链式调用操作如下:
import re import pandas as pd # 定义字数统计函数 def word_count(text): return len(re.findall(r"[\u4e00-\u9fa5]", text)) tidy_data = ( pd.read_csv('~/Desktop/huanong.csv') .loc[:, ['aid', 'title', 'created', 'length', 'play', 'comment', 'video_review']] .assign(title = lambda df: df['title'].str.replace("华农兄弟:", ""), title_count = lambda df: df['title'].apply(word_count), created = lambda df: df['created'].pipe(pd.to_datetime, unit='s'), created_date = lambda df: df['created'].dt.date, length = lambda df: "00:" + df['length'], video_length = lambda df: df['length'].pipe(pd.to_timedelta).dt.seconds ) )
这里首先是通过loc方法挑出其中的列,然后调用assign方法来创建新的字段,新的字段其字段名如果和原来的字段相一致,那么就会进行覆盖,从assign中我们可以很清楚地看到当中字段的产生过程,同lambda 表达式进行交互:
1.title 和title_count:
原有的title字段因为属于字符串类型,可以直接很方便的调用str.* 方法来进行处理,这里我就直接调用当中的replace方法将「华农兄弟:」字符进行清洗
基于清洗好的title 字段,再对该字段使用apply方法,该方法传递我们前面实现定义好的字数统计的函数,对每一条记录的标题中,对属于\u4e00到\u9fa5这一区间内的所有 Unicode 中文字符进行提取,并进行长度计算
2.created和created_date:
对原有的created 字段调用一个pipe方法,该方法会将created 字段传递进pd.to_datetime 参数中,这里需要将unit时间单位设置成s秒才能显示出正确的时间,否则仍以 Unix 时间错的样式显示
基于处理好的created 字段,我们可以通过其属于datetime64 的性质来获取其对应的时间,这里 Pandas 给我们提供了一个很方便的 API 方法,通过dt.*来拿到当中的属性值
3.length 和video_length:
原有的length 字段我们直接让字符串00:和该字段进行直接拼接,用以做下一步转换
基于完整的length时间字符串,我们再次调用pipe方法将该字段作为参数隐式传递到pd.to_timedelta方法中转化,然后同理和create_date字段一样获取到相应的属性值,这里我取的是秒数。
2、播放量趋势图
基于前面稍作清洗后得到的tidy_data数据,我们可以快速地做一个播放量走势的探索。这里我们需要用到created这个属于datetime64的字段为 X 轴,播放量play 字段为 Y 轴做可视化展示。
# 播放量走势 %matplotlib inline %config InlineBackend.figure_format = 'retina' import matplotlib.pyplot as plt (tidy_data[['created', 'play']] .set_index('created') .resample('1M') .sum() .plot( kind='line', figsize=(16, 8), title='Video Play Prend(2018-2020)', grid=True, legend=False ) ) plt.xlabel("") plt.ylabel('The Number Of Playing')
这里我们将上传日期和播放量两个选出来后,需要先将created设定为索引,才能接着使用resample重采样的方法进行聚合操作,这里我们以月为统计颗粒度,对每个月播放量进行加总,之后再调用plot 接口实现可视化。
链式调用的一个小技巧就是,可以利用括号作用域连续的特性使整个链式调用的操作不会报错,当然如果不喜欢这种方式也可以手动在每条操作后面追加一个\符号,所以上面的整个操作就会变成这样:
tidy_data[['created', 'play']] \ .set_index('created') \ .resample('1M') .sum() .plot( \ kind='line', \ figsize=(16, 8), \ title='Video Play Prend(2018-2020)', \ grid=True, \ legend=False \ )
但是相比于追加一对括号来说,这种尾部追加\符号的方式并不推荐,也不优雅。
但是如果既没有在括号作用域或未追加\ 符号,那么在运行时 Python 解释器就会报错。
3、链式调用性能
通过前两个案例我们可以看出链式调用可以说是比较优雅且快速地能实现一套数据操作的流程,但是链式调用也会因为不同的写法而存在性能上的差异。
这里我们继续基于前面的tidy_data操作,这里我们基于created_date 来对play、comment和video_review进行求和后的数值进一步以 10 为底作对数化。最后需要得到以下结果:
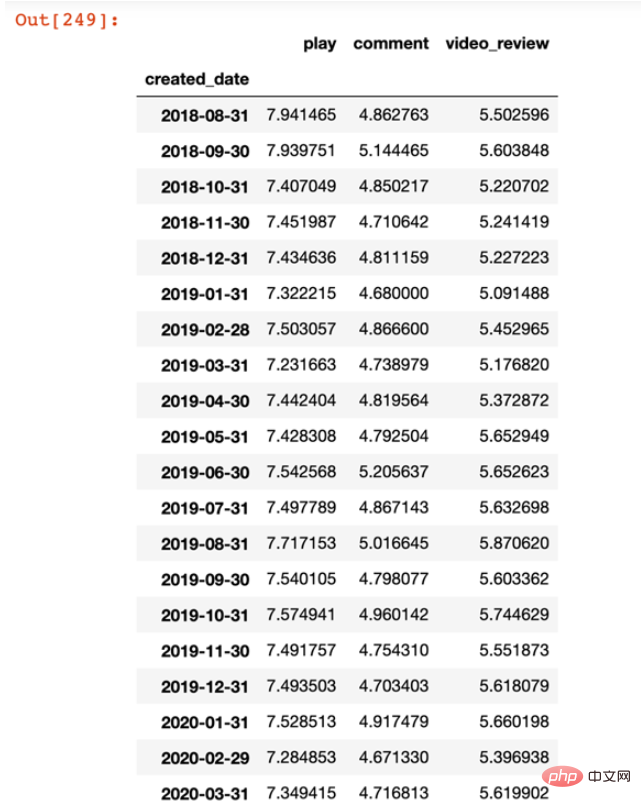
统计表格
写法一:一般写法
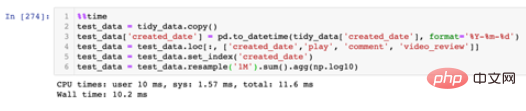
一般写法
这种写法就是基于tidy_data拷贝后进行操作,操作得到的结果会不断地覆盖原有的数据对象
写法二:链式调用写法
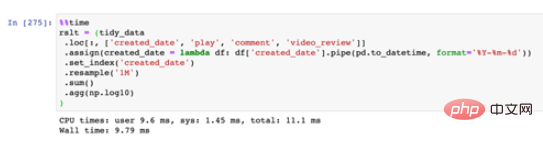
链式调用写法
可以看到,链式调用的写法相比于一般写法而言会快上一点,不过由于数据量比较小,因此二者时间的差异并不大;但链式调用由于不需要额外的中间变量已经覆盖写入步骤,在内存开销上会少一些。
结尾:链式调用的优劣
从本文的只言片语中,你能领略到链式调用使得代码在可读性上大大的增强,同时以尽肯能少的代码量去实现更多操作。
当然,链式调用并不算是完美的,它也存在着一定缺陷。比如说当链式调用的方法超过 10 步以上时,那么出错的几率就会大幅度提高,从而造成调试或 Debug 的困难。比如这样:
(data .method1(...) .method2(...) .method3(...) .method4(...) .method5(...) .method6(...) .method7(...) # Something Error .method8(...) .method9(...) .method10(...) .method11(...) )
以上がPython で連鎖呼び出しを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。