
ホームページ >テクノロジー周辺機器 >AI >機械学習モデルの最適なしきい値の設定: バイナリ分類の最適なしきい値は 0.5 ですか?
機械学習モデルの最適なしきい値の設定: バイナリ分類の最適なしきい値は 0.5 ですか?

- 王林転載
- 2023-05-15 14:49:061106ブラウズ
バイナリ分類の場合、分類器は実数値のスコアを出力し、その値をしきい値処理してバイナリ応答を生成します。たとえば、ロジスティック回帰は確率 (0.0 ~ 1.0 の間の値) を出力し、スコアが 0.5 以上の観測値は正の出力を生成します (他の多くのモデルはデフォルトで 0.5 のしきい値を使用します)。
しかし、デフォルトのしきい値 0.5 を使用するのは理想的ではありません。この記事では、バイナリ分類器から最適なしきい値を選択する方法を説明します。この記事では、Plomber を使用して実験を並列実行し、sklearn-evaluation を使用してグラフを生成します。
これは、ロジスティック回帰のトレーニングの例です。有害なコンテンツ (画像、ビデオなど) を含む投稿にモデルがフラグを立て、人間がそれを見て、コンテンツを削除する必要があるかどうかを決定するコンテンツ モデレーション システムを開発しているとします。
単純なバイナリ分類器を構築する
次のコード スニペットは分類器をトレーニングします:
import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import datasets from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn_evaluation.plot import ConfusionMatrix # matplotlib settings mpl.rcParams['figure.figsize'] = (4, 4) mpl.rcParams['figure.dpi'] = 150 # create sample dataset X, y = datasets.make_classification(1000, 10, n_informative=5, class_sep=0.4) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # fit model clf = LogisticRegression() _ = clf.fit(X_train, y_train)
次に、テスト セットで予測を行い、混同行列を通じて評価してみましょう。パフォーマンス:
# predict on the test set y_pred = clf.predict(X_test) # plot confusion matrix cm_dot_five = ConfusionMatrix(y_test, y_pred) cm_dot_five
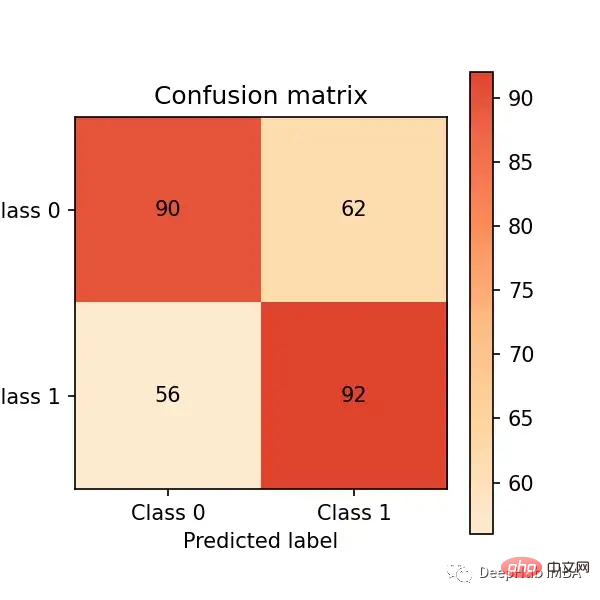
混同行列は、4 つの領域におけるモデルのパフォーマンスを要約しています。
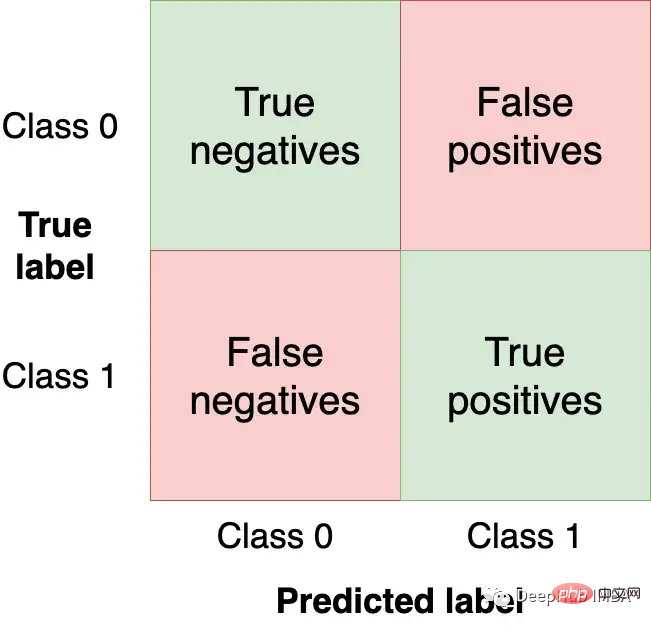
私たちはトップを獲得したいと考えています。左と右下の象限で、モデルが取得する正しい観測値と同じだけ多くの観測値 (テスト セットから) を取得します。他の象限はモデル誤差です。
モデルのしきい値を変更すると、混同行列の値が変更されます。前の例では、 clf.predict を使用するとバイナリ応答が返されました (つまり、しきい値として 0.5 を使用) が、 clf.predict_proba 関数を使用して生の確率を取得し、カスタムしきい値を使用することもできます:
y_score = clf.predict_proba(X_test)
より低いしきい値を設定することで分類器をより積極的にし (つまり、より多くの投稿を有害としてラベル付けする)、新しい混同行列を作成できます:
cm_dot_four = ConfusionMatrix(y_score[:, 1] >= 0.4, y_pred)
sklearn-evaluation ライブラリを使用するとこれが簡単になります 2 つの行列を比較します:
cm_dot_five + cm_dot_four
三角形の上の部分はしきい値 0.5 から来ており、下の部分はしきい値 0.4 から来ています:
- どちらのモデルも同じ観測数に対して 0 を予測します (これは偶然です)。 0.5 しきい値: (90 56 = 146)。 0.4 しきい値: (78 68 = 146)
- しきい値を下げると偽陰性が増加します (56 件から 68 件に)
- しきい値を下げると真陽性の数が大幅に増加します ( 92 件から) 154 件追加)
しきい値の小さな変更は混同行列に大きく影響します。 2 つのしきい値のみを分析しました。すべての値にわたってモデルのパフォーマンスを分析できれば、しきい値のダイナミクスをよりよく理解できるようになります。しかし、それが起こる前に、モデル評価のための新しい指標を定義する必要があります。
これまで、モデルを評価するために絶対数値を使用してきました。比較と評価を容易にするために、2 つの正規化されたメトリクスを定義します (値は 0.0 から 1.0 の間です)。
精度は、ラベルが付けられた観察されたイベントの割合です (たとえば、モデルが有害であるとみなした投稿は有害です)。再現率は、モデルによって取得された実際のイベントの割合です (つまり、すべての有害な投稿のうち、検出できた割合)。
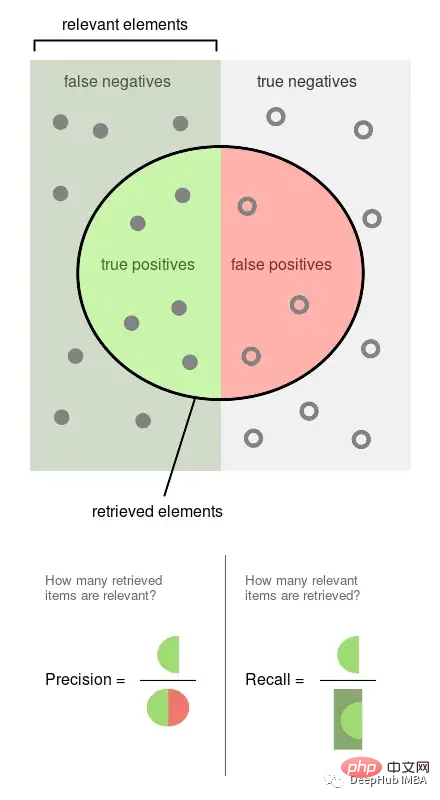
上の図は Wikipedia からのもので、これら 2 つの指標がどのように計算されるかをよく示しています。適合率と再現率はどちらも比例するため、両方とも 0 対 1 の比率になります。
実験を実行する
いくつかのしきい値に基づいて精度、再現率、その他の統計を取得し、しきい値がそれらにどのような影響を与えるかをよりよく理解します。また、この実験を複数回繰り返して、ばらつきを測定します。
このセクションのコマンドはすべて bash コマンドです。これらはターミナルで実行する必要があります。Jupyter を使用している場合は、%%sh マジック コマンドを使用できます。
ここでは、Plomber Cloud を使用して実験を実行します。それは実験を並行して実行し、結果を迅速に取得できるからです。
モデルに適合するノートブックを作成し、複数のしきい値の統計を計算し、同じノートブックを 20 回並列実行しました。
curl -O https://raw.githubusercontent.com/ploomber/posts/master/threshold/fit.ipynb?utm_source=medium&utm_medium=blog&utm_campaign=threshold
このノートブックを実行してみましょう (ファイル内の設定により、Plomber Cloud はこのノートブックを 20 回並行して実行するように指示されます):
ploomber cloud nb fit.ipynb
数分後に、20 回の実験が完了したことがわかります。
ploomber cloud status @latest --summary status count -------- ------- finished 20 Pipeline finished. Check outputs: $ ploomber cloud products
.csv ファイルに保存されている実験結果をダウンロードしましょう:
ploomber cloud download 'threshold-selection/*.csv' --summary
実験結果の視覚化
は、すべての実験の結果をロードし、一度にプロットします。
rreeee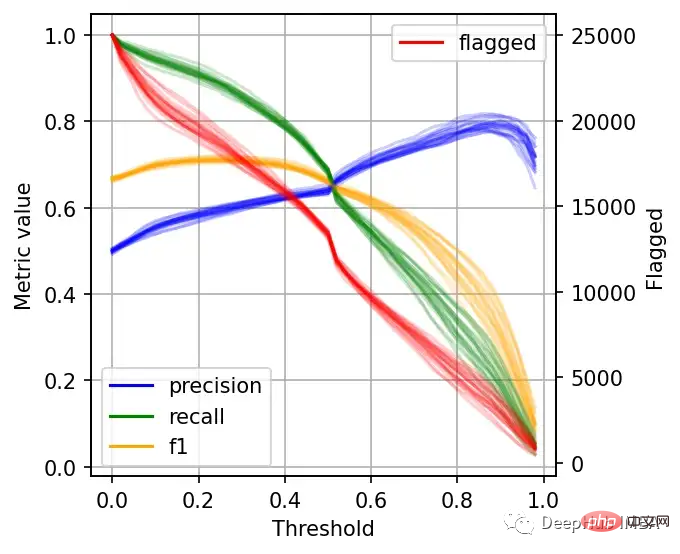
左边的刻度(从0到1)是我们的三个指标:精度、召回率和F1。F1分为精度与查全率的调和平均值,F1分的最佳值为1.0,最差值为0.0;F1对精度和召回率都是相同对待的,所以你可以看到它在两者之间保持平衡。如果你正在处理一个精确度和召回率都很重要的用例,那么最大化F1是一种可以帮助你优化分类器阈值的方法。
这里还包括一条红色曲线(右侧的比例),显示我们的模型标记为有害内容的案例数量。
在这个的内容审核示例中,可能有X个的工作人员来人工审核模型标记的有害帖子,但是他们人数是有限的,因此考虑标记帖子的总数可以帮助我们更好地选择阈值:例如每天只能检查5000个帖子,那么模型找到10,000帖并不会带来任何的提高。如果我人工每天可以处理10000贴,但是模型只标记了100贴,那么显然也是浪费的。
当设置较低的阈值时,有较高的召回率(我们检索了大部分实际上有害的帖子),但精度较低(包含了许多无害的帖子)。如果我们提高阈值,情况就会反转:召回率下降(错过了许多有害的帖子),但精确度很高(大多数标记的帖子都是有害的)。
所以在为我们的二元分类器选择阈值时,我们必须在精度或召回率上妥协,因为没有一个分类器是完美的。我们来讨论一下如何推理选择合适的阈值。
选择最佳阈值
右边的数据会产生噪声(较大的阈值)。需要稍微清理一下,我们将重新创建这个图,我们将绘制2.5%、50%和97.5%的百分位数,而不是绘制所有值。
shape = (df.shape[0], len(metrics))
precision = np.zeros(shape)
recall = np.zeros(shape)
f1 = np.zeros(shape)
n_flagged = np.zeros(shape)
for i, df in enumerate(metrics):
precision[:, i] = df.precision.values
recall[:, i] = df.recall.values
f1[:, i] = df.f1.values
n_flagged[:, i] = df.n_flagged.values
precision_ = np.quantile(precision, q=0.5, axis=1)
recall_ = np.quantile(recall, q=0.5, axis=1)
f1_ = np.quantile(f1, q=0.5, axis=1)
n_flagged_ = np.quantile(n_flagged, q=0.5, axis=1)
plt.plot(df.threshold, precision_, color='blue', label='precision')
plt.plot(df.threshold, recall_, color='green', label='recall')
plt.plot(df.threshold, f1_, color='orange', label='f1')
plt.fill_between(df.threshold, precision_interval[0],
precision_interval[1], color='blue',
alpha=0.2)
plt.fill_between(df.threshold, recall_interval[0],
recall_interval[1], color='green',
alpha=0.2)
plt.fill_between(df.threshold, f1_interval[0],
f1_interval[1], color='orange',
alpha=0.2)
plt.xlabel('Threshold')
plt.ylabel('Metric value')
plt.legend()
ax = plt.twinx()
ax.plot(df.threshold, n_flagged_, color='red', label='flagged')
ax.fill_between(df.threshold, n_flagged_interval[0],
n_flagged_interval[1], color='red',
alpha=0.2)
ax.legend(loc=3)
plt.ylabel('Flagged')
plt.grid()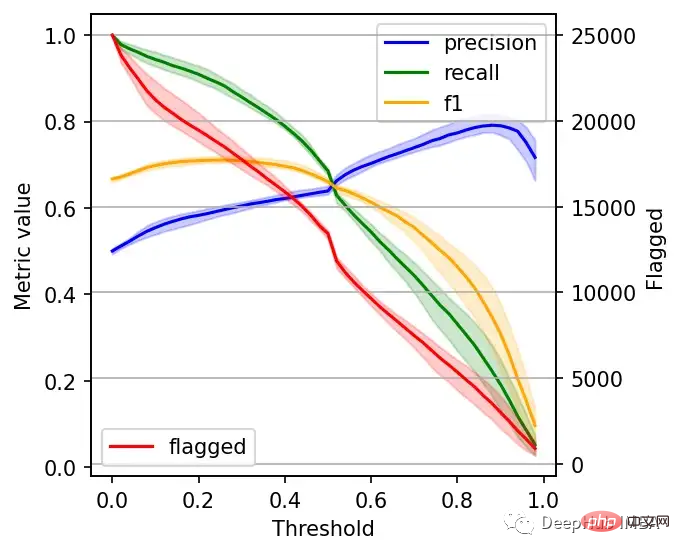
我们可以根据自己的需求选择阈值,例如检索尽可能多的有害帖子(高召回率)是否更重要?还是要有更高的确定性,我们标记的必须是有害的(高精度)?
如果两者都同等重要,那么在这些条件下优化的常用方法就是最大化F-1分数:
idx = np.argmax(f1_)
prec_lower, prec_upper = precision_interval[0][idx], precision_interval[1][idx]
rec_lower, rec_upper = recall_interval[0][idx], recall_interval[1][idx]
threshold = df.threshold[idx]
print(f'Max F1 score: {f1_[idx]:.2f}')
print('Metrics when maximizing F1 score:')
print(f' - Threshold: {threshold:.2f}')
print(f' - Precision range: ({prec_lower:.2f}, {prec_upper:.2f})')
print(f' - Recall range: ({rec_lower:.2f}, {rec_upper:.2f})')
#结果
Max F1 score: 0.71
Metrics when maximizing F1 score:
- Threshold: 0.26
- Precision range: (0.58, 0.61)
- Recall range: (0.86, 0.90)在很多情况下很难决定这个折中,所以加入一些约束条件会有一些帮助。
假设我们有10个人审查有害的帖子,他们可以一起检查5000个。那么让我们看看指标,如果我们修改了阈值,让它标记了大约5000个帖子:
idx = np.argmax(n_flagged_ <= 5000)
prec_lower, prec_upper = precision_interval[0][idx], precision_interval[1][idx]
rec_lower, rec_upper = recall_interval[0][idx], recall_interval[1][idx]
threshold = df.threshold[idx]
print('Metrics when limiting to a maximum of 5,000 flagged events:')
print(f' - Threshold: {threshold:.2f}')
print(f' - Precision range: ({prec_lower:.2f}, {prec_upper:.2f})')
print(f' - Recall range: ({rec_lower:.2f}, {rec_upper:.2f})')
# 结果
Metrics when limiting to a maximum of 5,000 flagged events:
- Threshold: 0.82
- Precision range: (0.77, 0.81)
- Recall range: (0.25, 0.36)如果需要进行汇报,我们可以在在展示结果时展示一些替代方案:比如在当前约束条件下(5000个帖子)的模型性能,以及如果我们增加团队(比如通过增加一倍的规模),我们可以做得更好。
总结
二元分类器的最佳阈值是针对业务结果进行优化并考虑到流程限制的阈值。通过本文中描述的过程,你可以更好地为用例决定最佳阈值。
另外,Ploomber Cloud!提供一些免费的算力!如果你需要一些免费的服务可以试试它。
以上が機械学習モデルの最適なしきい値の設定: バイナリ分類の最適なしきい値は 0.5 ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。