
ホームページ >テクノロジー周辺機器 >AI >自動運転視覚認識アルゴリズム技術のレビュー
自動運転視覚認識アルゴリズム技術のレビュー

- 王林転載
- 2023-05-10 21:37:131816ブラウズ
環境認識は自動運転における最初のリンクであり、車両と環境の間のリンクです。自動運転システムの全体的なパフォーマンスは、知覚システムの品質に大きく依存します。現在、環境センシング技術には 2 つの主流の技術ルートがあります:
① ビジョン主導のマルチセンサー融合ソリューション (代表的なのは Tesla)
② LIDAR を主体とし、その他のセンサーを利用した技術ソリューション。代表的なものとしては、Google、Baidu などが挙げられます。
環境知覚における主要な視覚知覚アルゴリズムを紹介し、そのタスク範囲と技術分野を下図に示します。 2D および 3D の視覚認識アルゴリズムのコンテキストと方向性をそれぞれ整理するために、2 つのセクションに分かれています。
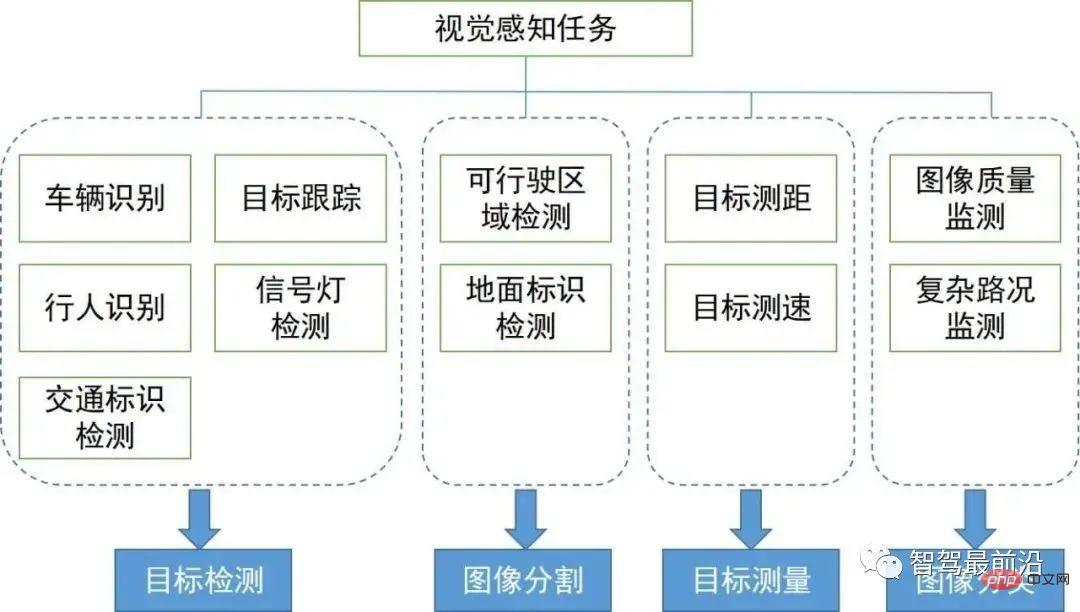
# このセクションでは、まず、自動運転で広く使用されているいくつかのタスクに基づく 2D 視覚認識アルゴリズムを紹介します。 . 画像またはビデオの 2D オブジェクトの検出と追跡、および 2D シーンのセマンティック セグメンテーション。近年、ディープラーニングは視覚のさまざまな分野に参入し、良好な成果を上げているため、いくつかの古典的なディープラーニングアルゴリズムを整理しました。
#01 ターゲットの検出
1.1 2 段階の検出
2 段階とは、検出を達成する方法を指し、物体の領域を抽出するプロセスと、CNN で領域を分類して識別するプロセスの 2 つのプロセスがあるため、「2 段階」は、ターゲット検出に基づくターゲット検出とも呼ばれます。候補地域 (地域提案)。代表的なアルゴリズムとしては、R-CNNシリーズ(R-CNN、Fast R-CNN、Faster R-CNN)などがあります。
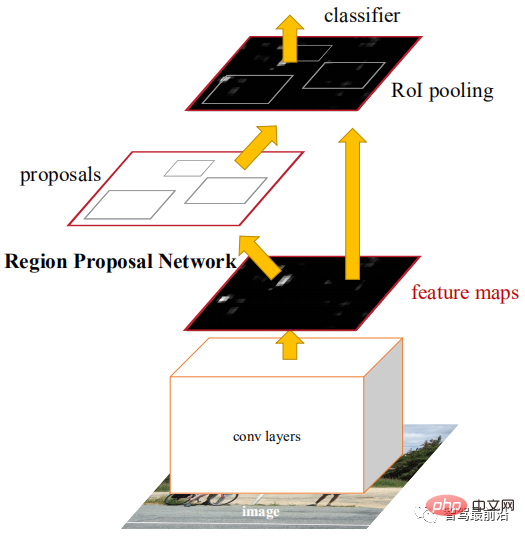
Faster R-CNN は、初のエンドツーエンド検出ネットワークです。第 1 段階では、領域候補ネットワーク (RPN) を使用して特徴マップに基づいて候補フレームを生成し、ROIPooling を使用して候補特徴のサイズを調整します。第 2 段階では、完全接続レイヤーを使用して洗練された分類と回帰。ここでは、計算の難易度を軽減し、速度を向上させるために、アンカーのアイデアが提案されています。特徴マップの各位置により、さまざまなサイズとアスペクト比のアンカーが生成され、オブジェクト フレーム回帰の参照として使用されます。アンカーの導入により、回帰タスクは比較的小さな変更のみを処理できるため、ネットワークの学習が容易になります。以下の図は Faster R-CNN のネットワーク構成図です。
CascadeRCNN の最初のステージは Faster R-CNN とまったく同じで、2 番目のステージは複数の RoiHead レイヤーを使用します。カスケード用。その後の作業は主に、上記のネットワークのいくつかの改善、または以前の作業の寄せ集めを中心に展開されており、画期的な改善はほとんどありません。
1.2 1 段階検出
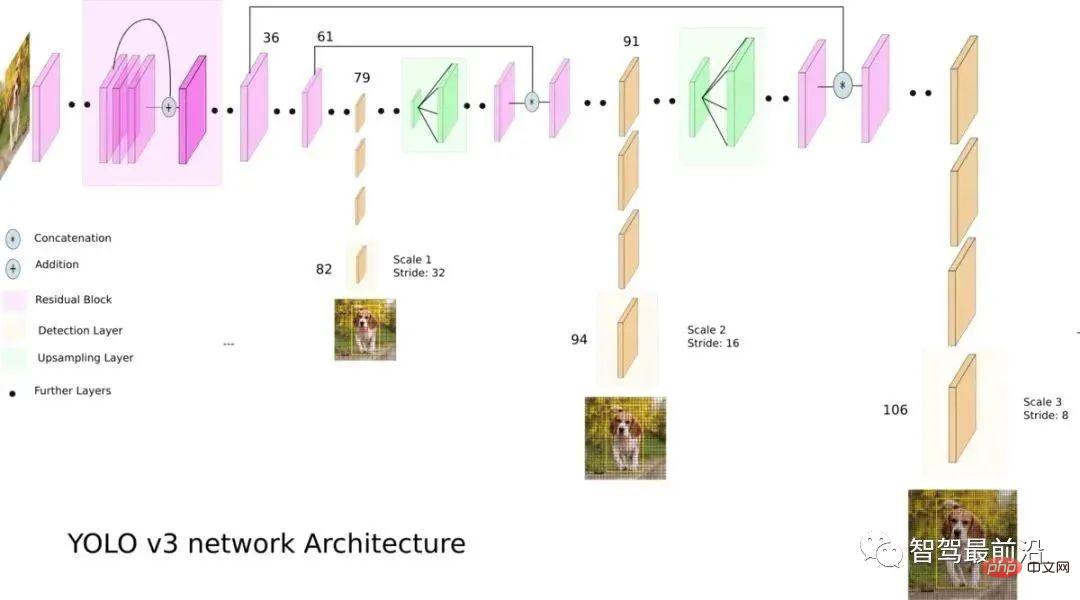
2 段階アルゴリズムと比較して、1 段階アルゴリズムでは必要なのは特徴を一度抽出することでターゲットの検出を実現できますが、アルゴリズムの速度は速く、一般的な精度はわずかに低くなります。このタイプのアルゴリズムの先駆者は YOLO であり、その後 SSD や Retinanet によって改良されました。YOLO を提案したチームは、これらのパフォーマンス向上に役立つトリックを YOLO アルゴリズムに統合し、その後 YOLOv2 ~ YOLOv5 の 4 つの改良バージョンを提案しました。 YOLO は 2 段階のターゲット検出アルゴリズムに比べて予測精度は劣りますが、実行速度が速いため、業界の主流となっています。以下の図はYOLOv3のネットワーク構成図です。
1.3 アンカーフリー検出 (アンカー検出なし)
このタイプのメソッドは通常、オブジェクトをいくつかのキー ポイントとして表し、これらのキー ポイントの位置を返すために CNN が使用されます。キーポイントは、オブジェクトフレームの中心点 (CenterNet)、コーナーポイント (CornerNet)、または代表点 (RepPoints) です。 CenterNet は、ターゲット検出問題を中心点予測問題に変換します。つまり、ターゲットを表すためにターゲットの中心点を使用し、ターゲットの中心点のオフセット、幅、高さを予測することによってターゲットの長方形のフレームを取得します。
ヒートマップは分類情報を表し、カテゴリごとに個別のヒートマップが生成されます。各ヒートマップでは、特定の座標にターゲットの中心点が含まれる場合、ターゲットにキー ポイントが生成されます。キー ポイント全体をガウス円を使用して表現します。具体的な詳細は次の図に示されています。

#RepPoints は、オブジェクトを代表点セットとして表現し、変形可能な畳み込みを通じてオブジェクトの形状変化に適応することを提案します。点セットは最終的にオブジェクト フレームに変換され、手動アノテーションとの差分を計算するために使用されます。
1.4 変圧器検出
ターゲット検出が 1 段階か 2 段階か、アンカーが使用されるかどうかそうでない場合でも、注意メカニズムが十分に活用されていません。この状況に対応して、Relation Net と DETR は Transformer を使用して、ターゲット検出の分野にアテンション メカニズムを導入します。 Relation Net は、Transformer を使用して異なるターゲット間の関係をモデル化し、関係情報を機能に組み込み、機能の強化を実現します。 DETR は Transformer に基づいた新しいターゲット検出アーキテクチャを提案し、ターゲット検出の新時代を切り開きます。次の図は DETR のアルゴリズム プロセスです。最初に CNN を使用して画像の特徴を抽出し、次に Transformer を使用してグローバルな空間関係をモデル化します。最後に、 の出力は、二部グラフ マッチング アルゴリズムを通じて手動の注釈と照合されます。
以下の表の精度は MSCOCO データベースの mAP を指標として使用し、速度は FPS で測定され、上記の一部を比較しています。ネットワークの構造設計にはさまざまな選択肢があるため (入力サイズの違い、バックボーン ネットワークの違いなど)、各アルゴリズムの実装ハードウェア プラットフォームも異なるため、精度と速度は完全に比較できません。 . ここに示すのはあくまで大まかなリストであり、結果は参考としてご利用ください。
02 ターゲット追跡
自動運転アプリケーションでは、入力はビデオ データであり、注意を払う必要があるターゲットが多数あります。車両や歩行者、自転車などしたがって、これは典型的な複数オブジェクト追跡タスク (MOT) です。 MOT タスクでは、現在最も一般的なフレームワークは Tracking-by-Detection であり、そのプロセスは次のとおりです。
①ターゲット フレーム出力は、単一フレーム画像上のターゲット検出器によって取得されます。 ;
②検出された各ターゲットの特徴を抽出します。これには通常、視覚的特徴や動きの特徴が含まれます。;
##③特徴に基づいて隣接するフレームからターゲットを計算します。検出間の類似性は、それらが同じターゲットからのものである確率を決定するために使用されます。④ 隣接するフレーム内のターゲット検出を照合し、同じオブジェクトを同じターゲットからのオブジェクトに割り当てます。 .ID。
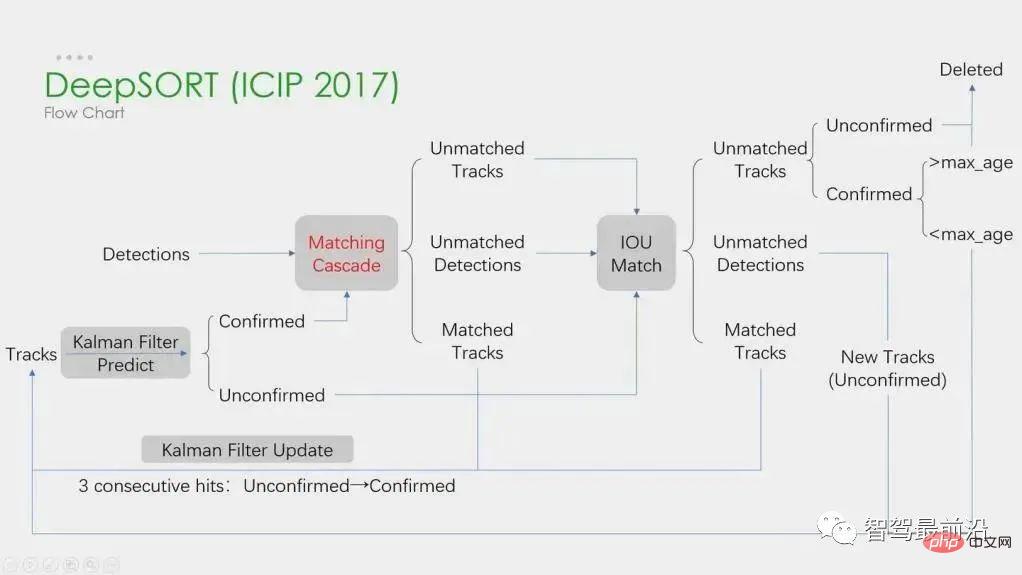
ディープラーニングは上記の 4 つのステップで適用されますが、最初の 2 つのステップが主要なステップです。ステップ 1 では、深層学習の適用は主に高品質の物体検出器を提供することであるため、一般に精度の高い方法が選択されます。 SORTは、Faster R-CNNに基づく物体検出手法であり、カルマンフィルターアルゴリズムのハンガリーアルゴリズムを使用することで、複数物体追跡の速度を大幅に向上させ、SOTAの精度を実現しており、実用的に広く使用されているアルゴリズムでもあります。 。ステップ 2 では、深層学習のアプリケーションは主に CNN を使用してオブジェクトの視覚的特徴を抽出します。 DeepSORTの最大の特徴は、外観情報を追加し、ReIDモジュールを借用して深層学習の特徴を抽出し、IDスイッチの数を削減することです。全体的なフローチャートは次のとおりです。
03 セマンティック セグメンテーション
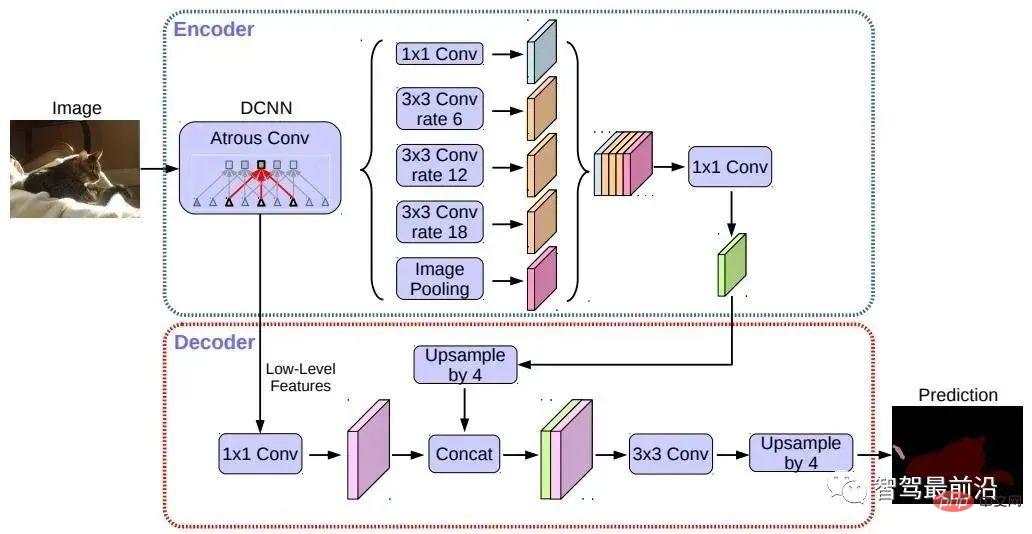
セマンティック セグメンテーションは、自動運転の車線境界線検出タスクと走行可能領域検出タスクの両方で使用されます。代表的なアルゴリズムとしてはFCN、U-Net、DeepLabシリーズなどがあります。 DeepLab は、拡張コンボリューションと ASPP (Atrous Spatial Pyramid Pooling) 構造を使用して、入力画像に対してマルチスケール処理を実行します。最後に、従来のセマンティック セグメンテーション手法で一般的に使用されている条件付きランダム フィールド (CRF) を使用して、セグメンテーション結果を最適化します。以下の図は DeepLab v3 のネットワーク構造です。
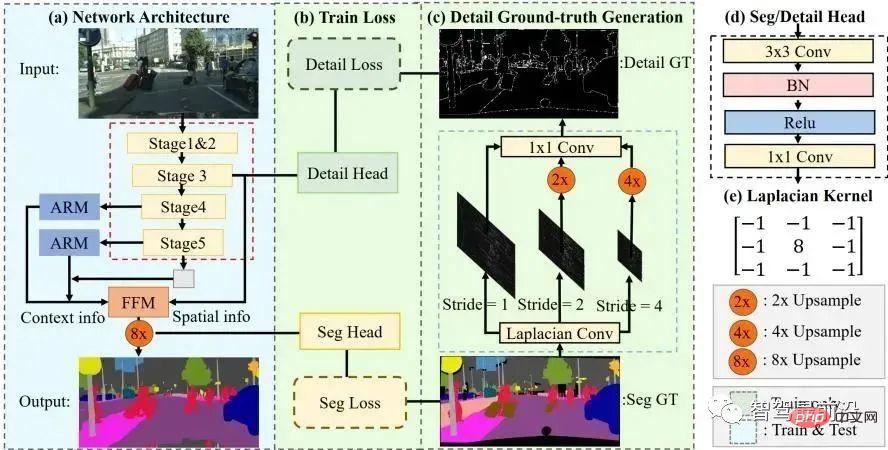
#近年の STDC アルゴリズムは、U-Net アルゴリズムの複雑なデコーダ構造を取り除き、FCN アルゴリズムと同様の構造を採用しています。しかし同時に、ネットワーク ダウンサンプリングのプロセスで、ARM モジュールを使用して異なるレイヤーの特徴マップからの情報を継続的に融合することで、単一ピクセルの関係のみを考慮する FCN アルゴリズムの欠点を回避します。 STDC アルゴリズムは速度と精度のバランスが取れており、自動運転システムのリアルタイム要件を満たすことができると言えます。アルゴリズムの流れを以下の図に示します。
#次に、自動運転に不可欠な3Dシーン認識について紹介します。なぜなら、奥行き情報や対象物の三次元サイズなどは二次元知覚では得られず、自動運転システムが周囲の環境を正しく判断するための鍵となる情報だからです。 3D 情報を取得する最も直接的な方法は、LiDAR を使用することです。ただし、LiDARにはコストが高い、車載グレードの製品の量産が難しい、天候の影響が大きいなどの欠点もあります。したがって、カメラのみに基づいた 3D 知覚は依然として非常に意味があり、価値のある研究方向です. 次に、単眼と両眼に基づいたいくつかの 3D 知覚アルゴリズムを整理します。
04 単眼 3D 認識
単一カメラ画像に基づいて 3D 環境を認識するのは不適切な問題ですが、解決できます。幾何学的な仮定 (ピクセルが地面に配置されているなど)、事前の知識、または解決に役立つ追加情報 (深さの推定など) を通じて。今回は、自動運転を実現するための2つの基本タスク(3Dターゲット検出と深度推定)から関連アルゴリズムを紹介します。
#4.1 3D ターゲット検出
# 表現変換(擬似ライダー):視覚センサーによる周囲の他車両の検知では、オクルージョンや距離計測不能などの問題が起こりがちですが、透視図を鳥瞰図表現に変換することができます。ここでは 2 つの変換方法を紹介します。 1 つ目は、すべてのピクセルが地面にあり、カメラの外部パラメータが正確であることを前提とした逆遠近マッピング (IPM) です。このとき、ホモグラフィー変換を使用して画像を BEV に変換し、次に、 YOLO ネットワークは、ターゲットの地上フレームを検出するために使用されます。 2 つ目は直交特徴変換 (OFT) で、ResNet-18 を使用して遠近感のある画像特徴を抽出します。次いで、投影されたボクセル領域にわたって画像ベースの特徴を蓄積することによって、ボクセルベースの特徴が生成される。次に、ボクセル フィーチャは垂直に折り畳まれ、直交する地表フィーチャが生成されます。最後に、ResNet に似た別のトップダウン ネットワークが 3D オブジェクト検出に使用されます。これらの方法は、地面に近い車両と歩行者にのみ適しています。
交通標識や信号機などの非地上ターゲットの場合、3D 検出のための深度推定を通じて疑似点群を生成できます。擬似 LiDAR は、まず深度推定結果を使用して点群を生成し、次に LIDAR ベースの 3D ターゲット検出器を直接適用して 3D ターゲット フレームを生成します。アルゴリズム フローは、次の図に示されています。
 # キーポイントと 3D モデル: 車両や歩行者などの検出対象のサイズと形状は比較的固定されており、既知です。対象物の 3D 情報を推定するために先験的に使用されます。 DeepMANTA は、この方向における先駆的な作品の 1 つです。まず、Faster RNN などのいくつかのターゲット検出アルゴリズムを使用して 2D ターゲット フレームを取得し、ターゲットのキー ポイントも検出します。次に、これらの 2D ターゲット フレームとキー ポイントがデータベース内のさまざまな 3D 車両 CAD モデルと照合され、最も類似性の高いモデルが 3D ターゲット検出の出力として選択されます。 MonoGRNet は、単眼 3D ターゲット検出を 2D ターゲット検出、インスタンス レベルの深度推定、投影された 3D 中心推定、およびローカル コーナー回帰の 4 つのステップに分割することを提案しており、アルゴリズム フローは次の図に示されています。このタイプの方法は、ターゲットが比較的固定された形状モデルを持っていることを前提としています。これは車両にとっては一般に満足ですが、歩行者にとっては比較的困難です。
# キーポイントと 3D モデル: 車両や歩行者などの検出対象のサイズと形状は比較的固定されており、既知です。対象物の 3D 情報を推定するために先験的に使用されます。 DeepMANTA は、この方向における先駆的な作品の 1 つです。まず、Faster RNN などのいくつかのターゲット検出アルゴリズムを使用して 2D ターゲット フレームを取得し、ターゲットのキー ポイントも検出します。次に、これらの 2D ターゲット フレームとキー ポイントがデータベース内のさまざまな 3D 車両 CAD モデルと照合され、最も類似性の高いモデルが 3D ターゲット検出の出力として選択されます。 MonoGRNet は、単眼 3D ターゲット検出を 2D ターゲット検出、インスタンス レベルの深度推定、投影された 3D 中心推定、およびローカル コーナー回帰の 4 つのステップに分割することを提案しており、アルゴリズム フローは次の図に示されています。このタイプの方法は、ターゲットが比較的固定された形状モデルを持っていることを前提としています。これは車両にとっては一般に満足ですが、歩行者にとっては比較的困難です。
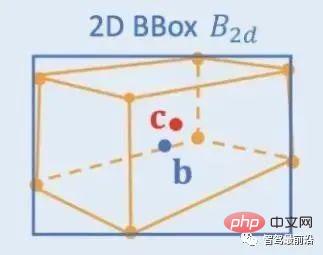
2D/3D 幾何学的制約: 3D 中心の投影と大まかなインスタンスの深さを回帰し、両方を使用して大まかな 3D 位置を推定します。先駆的な研究は Deep3DBox で、最初に 2D ターゲット ボックス内の画像特徴を使用してターゲットのサイズと方向を推定します。次に、中心点の 3D 位置が 2D/3D 幾何拘束によって解決されます。この制約は、画像上の 3D ターゲット フレームの投影が 2D ターゲット フレームに密接に囲まれている、つまり 3D ターゲット フレームの少なくとも 1 つのコーナー ポイントが 2D ターゲット フレームの両側に存在するということです。事前に予測されたサイズと方向をカメラのキャリブレーション パラメーターと組み合わせることで、中心点の 3D 位置を計算できます。 2D ターゲット ボックスと 3D ターゲット ボックスの間の幾何学的制約を次の図に示します。 Deep3DBox に基づいた Shift R-CNN は、以前に取得した 2D ターゲット ボックス、3D ターゲット ボックス、カメラ パラメーターを入力として組み合わせ、完全に接続されたネットワークを使用してより正確な 3D 位置を予測します。
# 3DBox を直接生成: この方法は、密な 3D ターゲット候補ボックスから開始し、2D 画像上の特徴ペアを使用します。すべての候補ボックスにスコアが付けられ、最も高いスコアを持つ候補ボックスが最終出力となります。ターゲット検出における従来のスライディング ウィンドウ法にある程度似ています。代表的な Mono3D アルゴリズムは、まず、ターゲットの以前の位置 (Z 座標は地上) とサイズに基づいて、密な 3D 候補ボックスを生成します。これらの 3D 候補フレームが画像座標に投影された後、2D 画像上の特徴を統合することによってスコア付けされ、CNN を通じて 2 回目のスコアリングが実行されて、最終的な 3D ターゲット フレームが取得されます。
M3D-RPN は、2D および 3D アンカーを定義するアンカーベースのメソッドです。 2D アンカーは画像上の高密度サンプリングを通じて取得され、3D アンカーはトレーニング セット データの事前知識 (ターゲットの実際のサイズの平均など) を通じて決定されます。 M3D-RPN は、標準畳み込みと深度認識畳み込みの両方も使用します。前者は空間不変性を持ち、後者は画像の行 (Y 座標) を複数のグループに分割し、各グループは異なるシーンの深度に対応し、異なるコンボリューション カーネルで処理されます。上記の高密度サンプリング方法は、非常に多くの計算を必要とします。 SS3D は、画像内の各関連オブジェクトの冗長表現と対応する不確実性推定値を出力する CNN と 3D バウンディング ボックス オプティマイザーを含む、より効率的な単一ステージ検出を使用します。 FCOS3D も 1 段階の検出方法であり、回帰ターゲットは、3D ターゲット フレームの中心を 2D 画像に投影することによって得られる追加の 2.5D 中心 (X、Y、深さ) を追加します。
4.2 深度推定
前述の 3D ターゲット検出であっても、自動運転の別の重要なタスクであっても認識 —— 2D から 3D まで拡張されるセマンティック セグメンテーションには、多かれ少なかれ、適用される疎または密な深度情報があります。単眼奥行き推定の重要性は自明であり、その入力は画像であり、出力は各ピクセルに対応するシーンの奥行き値からなる同じサイズの画像です。入力はビデオ シーケンスにすることもでき、カメラまたはオブジェクトの動きによってもたらされる追加情報を使用して深度推定の精度を向上させます。
教師あり学習と比較して、単眼奥行き推定の教師なし方法は、困難なグラウンドトゥルースデータセットの構築を必要とせず、実装の難易度も低くなります。単眼奥行き推定の教師なし方法は、単眼ビデオ シーケンスに基づく方法と、同期されたステレオ画像ペアに基づく 2 つのタイプに分類できます。
前者は、移動するカメラと静止したシーンを前提としています。後者の方法では、Garg らはまず、画像再構成に同時にステレオ補正された両眼画像ペアを使用することを試み、両眼判定によって左右のビューの姿勢関係が得られ、比較的理想的な効果が得られました。これに基づいて、ゴダールらは精度をさらに向上させるために左右の一貫性制約を使用しましたが、層ごとのダウンサンプリングによって高度な特徴を抽出して受容野を増加させる一方で、特徴の解像度も常に低下しており、粒度も低下しています。は常に失われ、詳細なディテールの処理とエッジの明瞭さに影響を与えます。この問題を軽減するために、Godard らはフル解像度のマルチスケール損失を導入し、低テクスチャ領域のブラック ホールとテクスチャ複製アーティファクトを効果的に削減しました。ただし、この精度の向上にはまだ限界があります。
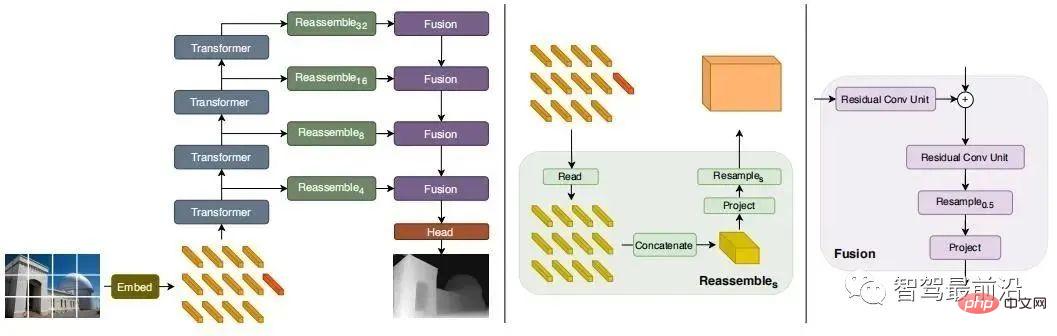
最近、ステージ全体のグローバルな受容野の取得を目的とした Transformer ベースのモデルが次々と登場しており、集中的な奥行き推定タスクにも非常に適しています。教師あり DPT では、ローカルな予測精度とグローバルな予測の一貫性を同時に確保するために、Transformer とマルチスケール構造を使用することが提案されており、次の図はネットワーク構造図です。
05 両眼視による 3D 認識
両眼視では、遠近変換によって生じる曖昧さを解決できるため、理論的には 3D 認識の精度を向上させることができます。ただし、双眼システムにはハードウェアとソフトウェアの点で比較的高い要件があります。ハードウェア的には、正確に登録された 2 台のカメラが必要であり、車両の運行中に登録の精度を確保する必要があります。ソフトウェア的には、アルゴリズムは 2 台のカメラからのデータを同時に処理する必要があり、計算の複雑さが高く、アルゴリズムのリアルタイム性を保証するのが困難です。単眼に比べて、両眼の仕事は比較的少なくなります。次に、3Dターゲット検出と奥行き推定の2つの側面からも簡単に紹介します。
5.1 3D ターゲット検出
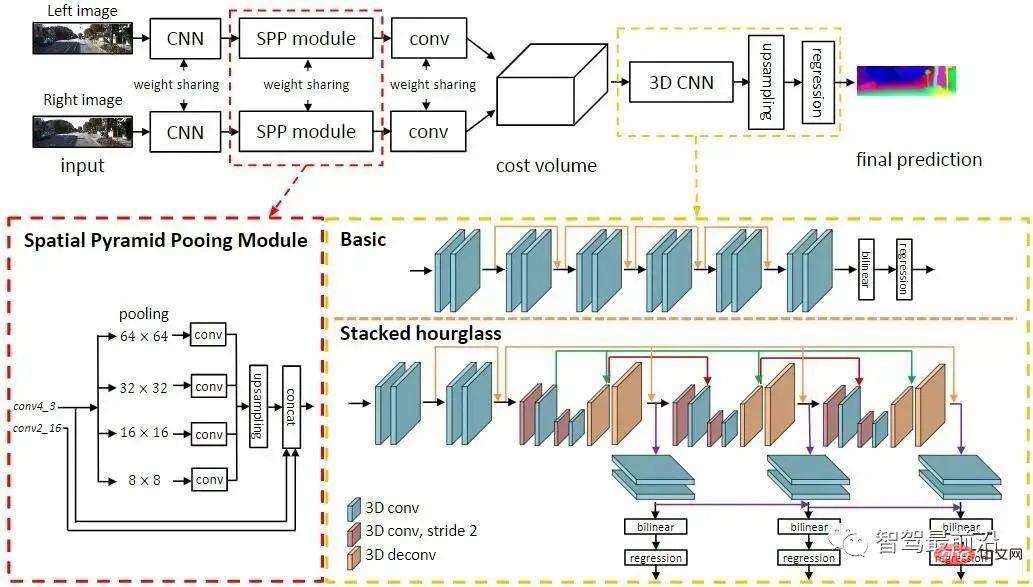
3DOP は 2 段階の検出方法であり、Fast R-CNN です。 3Dフィールドの拡大。まず、両眼画像を使用して深度マップが生成されます。深度マップは点群に変換され、グリッド データ構造に定量化されます。これは、3D ターゲットの候補フレームを生成するための入力として使用されます。以前に紹介した疑似 LiDAR と同様に、(単眼、両眼、または低線数の LiDAR からの) 高密度深度マップが点群に変換され、点群ターゲット検出の分野のアルゴリズムが適用されます。 DSGN は、ステレオ マッチングを利用して平面スキャン ボリュームを構築し、3D ジオメトリとセマンティック情報をエンコードするためにそれらを 3D ジオメトリに変換します。これは、ステレオ マッチングと高度なオブジェクト認識のためにピクセル レベルの特徴を抽出できるエンドツーエンドのフレームワークです。 、シーンの深度の推定と 3D オブジェクトの検出を同時に行うことができます。
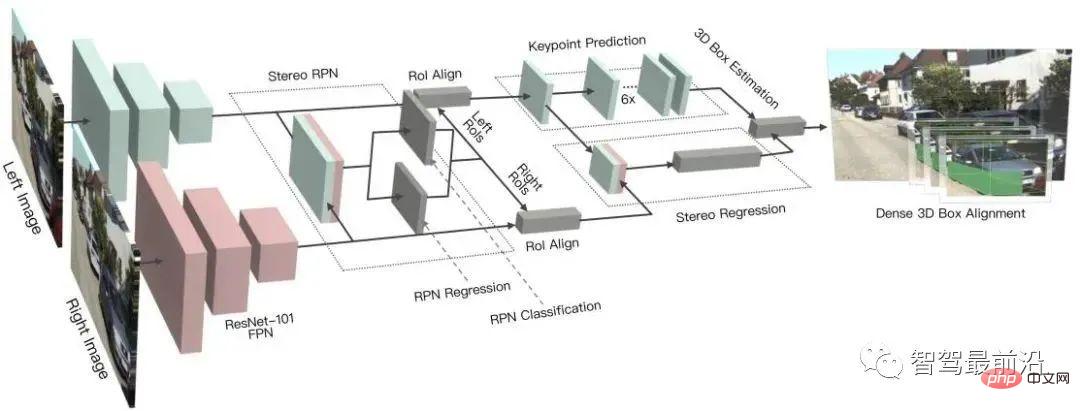
ステレオ R-CNN は、ステレオ入力用の Faster R-CNN を拡張し、左右のビューでオブジェクトを同時に検出して関連付けます。 RPN の後に追加のブランチが追加され、まばらなキーポイント、視点、オブジェクト サイズを予測し、左右のビューの 2D 境界ボックスを結合して、粗い 3D オブジェクト境界ボックスを計算します。次に、左右の関心領域の領域ベースのフォトメトリック位置合わせを使用して、正確な 3D バウンディング ボックスが復元されます。下の図はそのネットワーク構造です。
5.2 深度推定
両眼の原理奥行きの推定は非常に単純で、左側と右側のビュー上の同じ 3D 点の間のピクセル距離 d に基づいています (2 台のカメラが同じ高さを維持していると想定しているため、水平方向の距離のみが考慮されます)。視差、カメラの焦点距離 f、カメラ間の距離 B (基線長) を使用して 3D 点の奥行きを推定します。計算式は次のとおりです。視差。次に、他の画像上でピクセルごとに一致する点を見つけるだけです。

以上が自動運転視覚認識アルゴリズム技術のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。