
ホームページ >テクノロジー周辺機器 >AI >青北マイクロソフトは GPT を深く掘り下げ、文脈学習を理解しています。パラメーターが変更されていないことを除けば、基本的には微調整と同じです。
青北マイクロソフトは GPT を深く掘り下げ、文脈学習を理解しています。パラメーターが変更されていないことを除けば、基本的には微調整と同じです。

- 王林転載
- 2023-05-10 21:37:041113ブラウズ
大規模な事前トレーニング済み言語モデルの重要な機能の 1 つは、コンテキスト内で学習できる機能 (In-Context Learning、ICL) です。つまり、いくつかの例示的な入力とラベルのペアを通じて、次のことを学習できます。パラメータを更新せずに、新しい入力ラベルが予測されます。
パフォーマンスは向上しましたが、大規模モデルの ICL 機能がどこから来るのかは依然として未解決の問題です。
ICL の仕組みをより深く理解するために、清華大学、北京大学、マイクロソフトの研究者は共同で、言語モデルをメタオプティマイザー (メタオプティマイザー) として解釈し、ICL を理解する論文を発表しました。暗黙的な微調整として。

#紙のリンク: https://arxiv.org/abs/2212.10559
#理論的には、Transformer の注目には勾配降下法最適化に基づく双対形式 (dual form) が存在することを明らかにしており、これを踏まえた ICL の理解は次のようになります。 GPT はまずデモンストレーション インスタンスに基づいてメタ グラデーションを生成し、次にこれらのメタ グラデーションを元の GPT に適用して ICL モデルを構築します。実験では、研究者らは、ICL の動作と実際のタスクに基づく明示的な微調整を包括的に比較し、この理解を裏付ける経験的証拠を提供しました。
結果は、ICL が予測レベル、表現レベル、注意行動レベルで明示的な微調整と同様に機能することを証明しています。
さらに、この記事は、運動量ベースの勾配降下法アルゴリズムとの類似性を通じて、メタ最適化の理解に触発されて、
運動量ベースの注意力##も設計しました。 # は、通常の注意と比較してパフォーマンスが優れており、この理解が別の側面から正しいことを裏付けるとともに、この理解を使用してモデルをさらに設計できる可能性も示しています。 ICL の原理
研究者らはまず、Transformer の線形注意メカニズムの定性分析を実施し、それと勾配降下ベースの最適化との関係を調べました。デュアルフォーム。次に、ICL が明示的な微調整と比較され、これら 2 つの最適化形式間のリンクが確立されます。
トランスフォーマーの注目はメタ最適化です
X がクエリ全体の入力表現であり、X' であると仮定します。は特性評価の例です。q はクエリ ベクトルです。ICL 設定の下では、モデル内の頭部のアテンション結果は次のようになります。
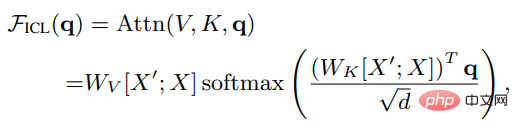 ご覧のとおり、スケーリングは削除されています。ルート d とソフトマックスを因数分解した後、標準のアテンション メカニズムは次のように近似できます。
ご覧のとおり、スケーリングは削除されています。ルート d とソフトマックスを因数分解した後、標準のアテンション メカニズムは次のように近似できます。
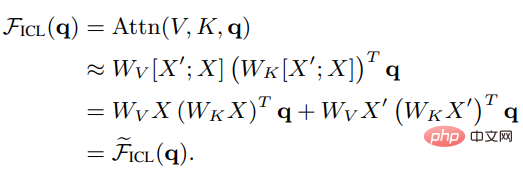 # Wzsl をゼロに設定します。 -ショット学習 (ZSL) 初期パラメータの後、Transformer のアテンションは次の二重形式に変換できます:
# Wzsl をゼロに設定します。 -ショット学習 (ZSL) 初期パラメータの後、Transformer のアテンションは次の二重形式に変換できます:
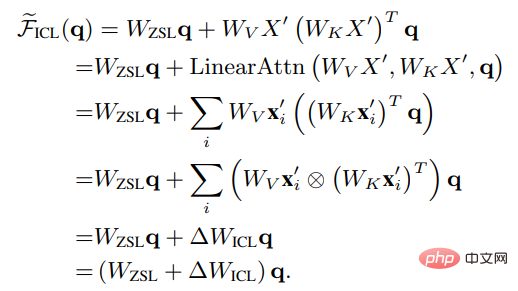 ICL であることがわかります。メタ最適化 (メタ最適化) プロセスとして解釈できます:
ICL であることがわかります。メタ最適化 (メタ最適化) プロセスとして解釈できます:
#1. Transformer に基づく事前トレーニング済み言語モデルをメタオプティマイザーとして使用します。
2. 正の方向計算を通じて、デモンストレーション例に基づいてメタ勾配を計算します;
3. アテンション メカニズムを通じて、メタ勾配を適用しますICL モデルを確立するための元の言語モデル。
ICL と微調整の比較
ICL のメタ最適化と明示的最適化を比較するために、研究者らは比較のベースラインとして特定の微調整設定を設計しました。 : ICL を考慮 注目のキーと値にのみ直接影響するため、微調整はキーと値の射影のパラメーターのみを更新します。同様に、線形注意の非厳密形式では、微調整された頭部注意の結果は次のように表すことができます:
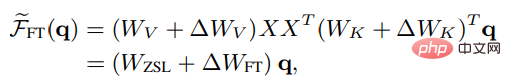
# # ICL とより公平に比較するために、実験では 微調整設定制限 が次のようにさらに設定されます:
1. トレーニング例を次のように指定します。 ICL のデモンストレーション例;
2. 各例でトレーニングの 1 ステップのみを実行し、順序は ICL のデモンストレーション順序と同じです;
3. ICL で使用されるものを使用する テンプレートは各トレーニング サンプルをフォーマットし、因果言語モデリング目標を使用して微調整します。
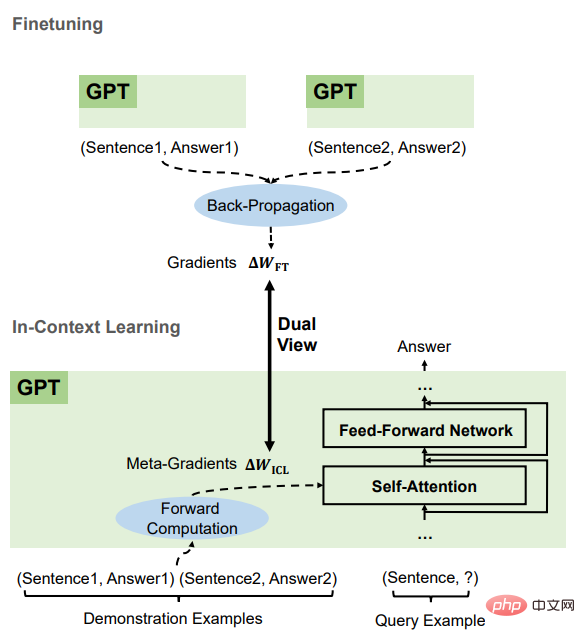
比較すると、ICL と微調整には、主に 4 つの側面を含む多くの共通の属性があることがわかります。
これらはすべて勾配降下法です
ICL と Fine の両方が存在することがわかります。 -チューニングは Wzsl Update、つまり勾配降下で実行されます。唯一の違いは、ICL が順方向計算によってメタ勾配を生成するのに対し、ファインチューニングは逆伝播によって真の勾配を取得することです。
#同じトレーニング情報ICL のメタ勾配は、以下に基づいて取得されます。デモンストレーションの例では、微調整の勾配も同じトレーニング サンプルから取得されます。つまり、ICL と微調整は同じトレーニング情報ソースを共有します。
トレーニング例の因果関係の順序は同じですICL と問題ありません。チューニング共有トレーニング例 因果的順序の場合、ICL はデコーダーのみのトランスフォーマーを使用するため、例の後続のトークンは前のトークンに影響を与えません。微調整の場合、トレーニング例の順序は同じであり、1 つのエポックのみがトレーニングされるためです。 、後続のトークンも保証できます。サンプルは前のサンプルに影響を与えません。
#すべては注意に基づいて行動します
ゼロショット学習と比較すると、ICL は直接微調整と微調整の影響は、注目のキーと値の計算に限定されます。 ICL の場合、モデル パラメーターは変更されず、例の情報を追加のキーと値にエンコードして注意の動作を変更します。微調整で導入された制限により、トレーニング情報は注意キーの投影にのみ影響し、マトリックスの値。
ICL と微調整の間のこれらの共通の特徴に基づいて、研究者らは、ICL を一種の暗黙的な微調整として理解するのが合理的であると考えています。
実験部分
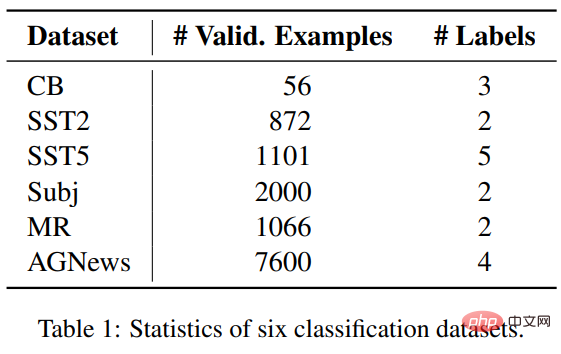
タスクとデータセット研究者 6 つのデータICL と微調整を比較するために、感情分類用の SST2、SST-5、MR、Subj の 4 つのデータ セットを含む 3 つの分類タスクにわたるセットが選択されました。AGNews はトピック分類データ セットで、CB は自然言語推論に使用されます。
 #実験設定
#実験設定
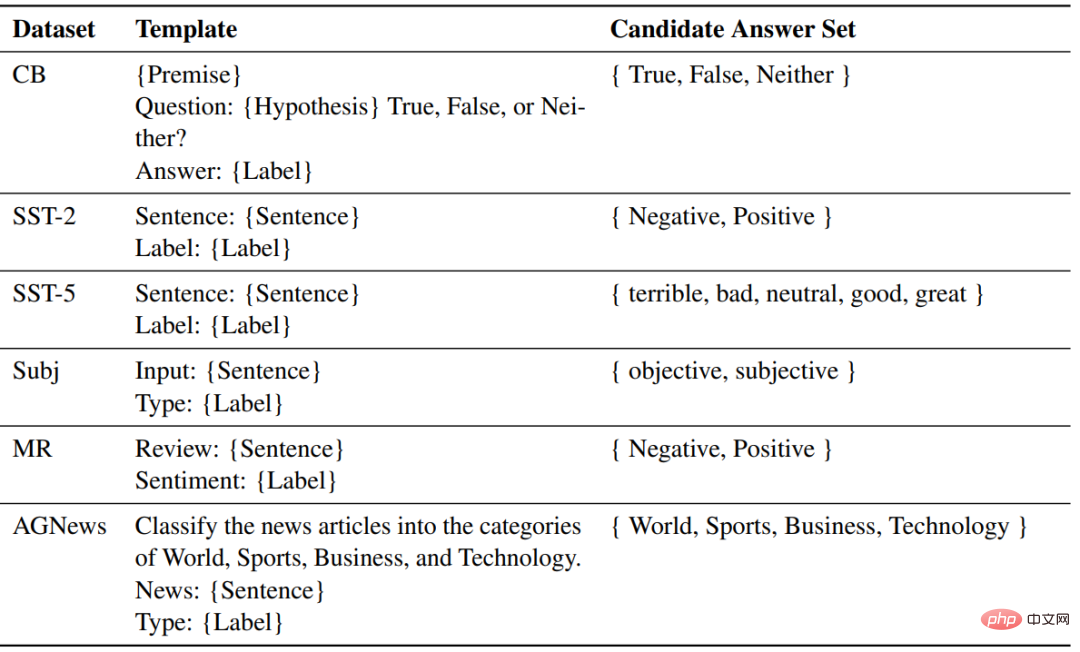
使用したモデル部品GPT に似た 2 つの事前トレーニング済み言語モデルが、それぞれ 1.3B と 2.7B のパラメーター サイズで、fairseq によってリリースされました。
各タスクでは、同じテンプレートが ZSL、ICL に使用されます。フォーマット用に微調整されたサンプル。
#結果
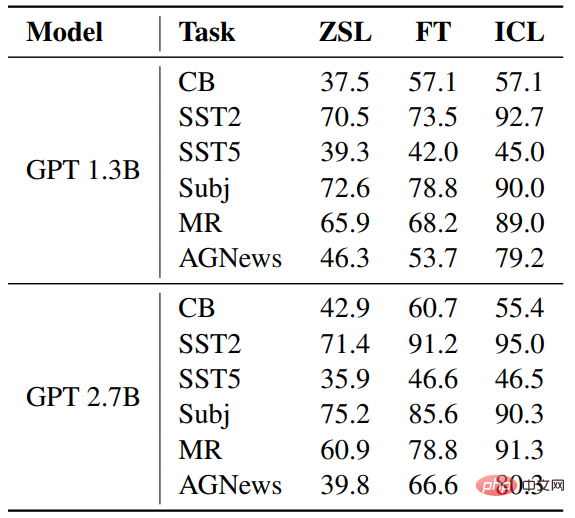
##正解率 #ZSL と比較すると、ICL と微調整の両方が大幅な改善を達成しています。これは、それらの最適化がこれらの下流タスクに役立つことを意味します。さらに、場合によっては、微調整よりも ICL の方が優れています。
 Rec2FTP(予測の微調整の呼び出し)
Rec2FTP(予測の微調整の呼び出し)
#6 つのデータセットに対する GPT モデルのスコアリング結果は、平均して、ICL が例の 87.64% を正確に予測でき、微調整により ZSL を修正できることを示しています。予測レベルでは、ICL は微調整のための正しい動作のほとんどをカバーできます。
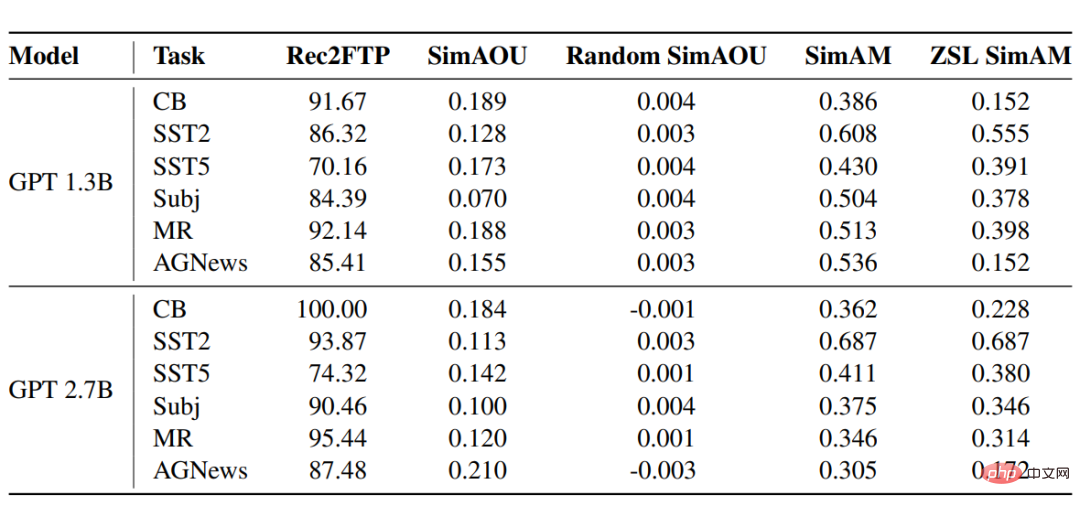
SimAOU(注意出力更新の類似性)
この結果から、ICL との差は次のとおりであることがわかります。更新と微調整更新は、類似性がランダム更新よりもはるかに高く、これは、表現レベルで、ICL が微調整の変更と同じ方向にアテンションの結果を変更する傾向があることも意味します。
SimAM(アテンション マップの類似性)
SimAM のベースライン メトリックとして、ZSL SimAM は ICL アテンション 類似性を計算します。重みと ZSL アテンション重みの間。これら 2 つのメトリクスを比較すると、ZSL と比較して、ICL は微調整と同様の注意の重みを生成する傾向があることがわかります。
同様に、注意行動のレベルでは、ICL が微調整と同様に動作することが実験結果によって証明されています。
以上が青北マイクロソフトは GPT を深く掘り下げ、文脈学習を理解しています。パラメーターが変更されていないことを除けば、基本的には微調整と同じです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。