



タイムライン
2018年6月
OpenAIは、1億1,000万のパラメーターを備えたGPT-1モデルをリリースしました。
2018年11月
OpenAIは15億個のパラメーターを備えたGPT-2モデルをリリースしましたが、悪用の懸念から、モデルのすべてのコードとデータは公開されていません。
2019年2月
OpenAIはGPT-2モデルの一部のコードとデータを公開しましたが、アクセスは依然として制限されています。
2019 年 6 月 10 日
OpenAI は、1,750 億のパラメーターを備えた GPT-3 モデルをリリースし、一部のパートナーにアクセスを提供しました。
2019年9月
OpenAIはGPT-2のすべてのコードとデータを公開し、より大きなバージョンをリリースしました。
2020 年 5 月に
#OpenAI は、1,750 億のパラメーターを持ち、これまでで最大の自然言語処理モデルである GPT-3 モデルのベータ版のリリースを発表しました。 2022 年 3 月OpenAI は、命令チューニングを使用して InstructGPT をリリースしました2022 年 11 月 30 日OpenAI は、大規模言語の GPT-3.5 シリーズに合格しました。新しい会話型 AI モデル ChatGPT がモデルの微調整を経て正式リリースされました。 2022 年 12 月 15 日ChatGPT の最初のアップデート。全体的なパフォーマンスが向上し、履歴の会話記録を保存および表示する新機能が追加されます。 2023年1月9日ChatGPTが2回目のアップデートを行い、回答の信頼性が向上し、新たに「生成停止」機能が追加されました。 2023年1月21日OpenAIは、一部のユーザーに限定されたChatGPT Professionalの有料版をリリースしました。 2023 年 1 月 30 日ChatGPT の 3 回目のアップデートでは、回答の信頼性が向上するだけでなく、数学的スキルも向上します。 2023年2月2日OpenAIはChatGPT有料版のサブスクリプションサービスを正式に開始し、新バージョンは無料版よりも応答が速く、動作が安定しています。 2023 年 3 月 15 日OpenAI は、テキストを読み取るだけでなく、画像を認識してテキスト結果を生成できる大規模マルチモーダル モデル GPT-4 を衝撃的に発表しました。接続された ChatGPT は Plus ユーザーに公開されています。 GPT-1: 一方向 Transformer に基づく事前トレーニング済みモデル GPT が登場する前は、NLP モデルは主に大量の注釈付きデータに基づいてトレーニングされていました。特定のタスク用。これにより、いくつかの制限が発生します: 大規模で高品質のアノテーション データを取得するのは容易ではありません; モデルは受けたトレーニングに限定されており、一般化能力が不十分です; 実行できません すぐに使用できるタスクは、モデルの実際の適用を制限します。 これらの問題を克服するために、OpenAI は大規模モデルを事前トレーニングする道を歩み始めました。 GPT-1 は、2018 年に OpenAI によってリリースされた最初の事前トレーニング済みモデルです。一方向の Transformer モデルを採用し、トレーニングに 40 GB 以上のテキスト データを使用します。 GPT-1 の主な機能は、生成的な事前トレーニング (教師なし) と識別タスクの微調整 (教師あり) です。まず、教師なし学習の事前トレーニングを使用し、8 つの GPU で 1 か月間かけて大量のラベルなしデータから AI システムの言語機能を強化し、大量の知識を取得しました。 NLP タスクのシステム パフォーマンスを向上させるために統合されました。 GPT-1 はテキストの生成とタスクの理解において優れたパフォーマンスを示し、当時最も先進的な自然言語処理モデルの 1 つとなりました。 GPT-2: マルチタスク事前トレーニング モデル シングルタスク モデルには一般化が欠けており、マルチタスクの学習には多数の効果的なトレーニング ペアが必要であるため、 , GPT-2はGPT-1をベースに拡張・最適化されており、教師あり学習が削除され教師なし学習のみが残されています。 GPT-2 は、より大きなテキスト データとより強力なコンピューティング リソースをトレーニングに使用し、パラメータ サイズは 1 億 5,000 万に達し、GPT-1 の 1 億 1,000 万のパラメータをはるかに上回ります。 GPT-2 では、学習に大規模なデータ セットと大規模なモデルを使用することに加えて、新しくてより困難なタスクであるゼロショット学習 (ゼロショット) も提案しています。これは、事前トレーニングされたモデルを多くの下流タスクに直接適用することです。 GPT-2 は、テキスト生成、テキスト分類、言語理解などを含む複数の自然言語処理タスクで優れたパフォーマンスを実証しています。

ステップ 1: 教師あり SFT の微調整: デモ データを収集し、教師ありポリシーをトレーニングします。私たちのタガーは、入力プロンプト配布での望ましい動作のデモンストレーションを提供します。次に、教師あり学習を使用して、これらのデータに基づいて事前トレーニングされた GPT-3 モデルを微調整します。
ステップ 2: 報酬モデルのトレーニング。比較データを収集し、報酬モデルをトレーニングします。私たちは、ラベラーが特定の入力に対してどの出力を好むかを示す、モデル出力間の比較のデータセットを収集しました。次に、人間が好む出力を予測するために報酬モデルをトレーニングします。
ステップ 3: 報酬モデルでの近接ポリシー最適化 (PPO) による強化学習: RM の出力をスカラー報酬として使用します。 PPO アルゴリズムを使用して監視戦略を微調整し、この報酬を最適化します。
ステップ 2 と 3 は継続的に繰り返すことができ、現在の最適な戦略に関してさらに多くの比較データが収集され、それを使用して新しい RM をトレーニングし、次に新しい戦略をトレーニングします。
最初の 2 つのステップのプロンプトは、OpenAI のオンライン API 上のユーザー使用状況データから取得され、雇用されたアノテーターによって手書きされます。最後のステップはすべて API データからサンプリングされます。InstructGPT の特定のデータ:
1. SFT データ セット
SFT データ セットは、最初のトレーニングに使用されます。ステップ 教師ありモデルは、収集された新しいデータを使用して、GPT-3 のトレーニング方法に従って GPT-3 を微調整します。 GPT-3 はプロンプト学習に基づく生成モデルであるため、SFT データセットもプロンプトと応答のペアで構成されるサンプルです。 SFT データの一部は OpenAI の PlayGround ユーザーから提供され、もう 1 つの部分は OpenAI が雇用する 40 人のラベラーから提供されます。そして彼らはラベラーを訓練しました。このデータセットでは、アノテーターの仕事は、内容に基づいて指示自体を記述することです。
2. RM データ セット
RM データ セットは、ステップ 2 で報酬モデルをトレーニングするために使用されます。 GPT/ChatGPTを指導します。この報酬目標は微分可能である必要はありませんが、モデルが生成する必要があるものとできるだけ包括的かつ現実的に一致している必要があります。もちろん、この報酬は手動のアノテーションによって提供することもできますし、人為的なペアリングを通じて、バイアスを含む生成されたコンテンツに低いスコアを与え、人間が好まないコンテンツを生成しないようにモデルを促すことができます。 InstructGPT/ChatGPT のアプローチは、最初にモデルに候補テキストのバッチを生成させ、次にラベラーを使用して、生成されたデータの品質に従って生成されたコンテンツを並べ替えることです。
3. PPO データ セット
InstructGPT の PPO データには注釈が付けられておらず、GPT-3 API ユーザーから取得されます。さまざまなユーザーによって提供される生成タスクにはさまざまな種類があり、その割合が最も高いのは生成タスク (45.6%)、QA (12.4%)、ブレインストーミング (11.2%)、対話 (8.4%) などです。
#付録:
ChatGPT のさまざまな機能のソース:


以上がChatGPT トピック 1 つの GPT ファミリーの進化の歴史の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 タイムシリーズの予測用のTimesfmApr 11, 2025 am 10:26 AM
タイムシリーズの予測用のTimesfmApr 11, 2025 am 10:26 AMGoogleのTimesFM:革新的な前提条件の時系列モデル Google Researchは、TimesFMを発表しました。これは、単変量の時系列予測用に設計された画期的な前提条件の基礎モデルです。 この革新的なモデルは、頻繁に複雑なプロを簡素化します
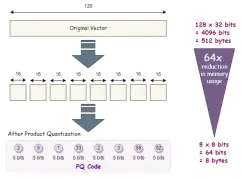 高次元データの高度なベクトルインデックス手法Apr 11, 2025 am 10:16 AM
高次元データの高度なベクトルインデックス手法Apr 11, 2025 am 10:16 AM高次元ベクトル検索:高度なインデックス作成手法のマスタリング 今日のデータ駆動型の世界では、推奨システム、画像認識、自然言語処理(NLP)、異常などのアプリケーションに高次元ベクトルが重要です
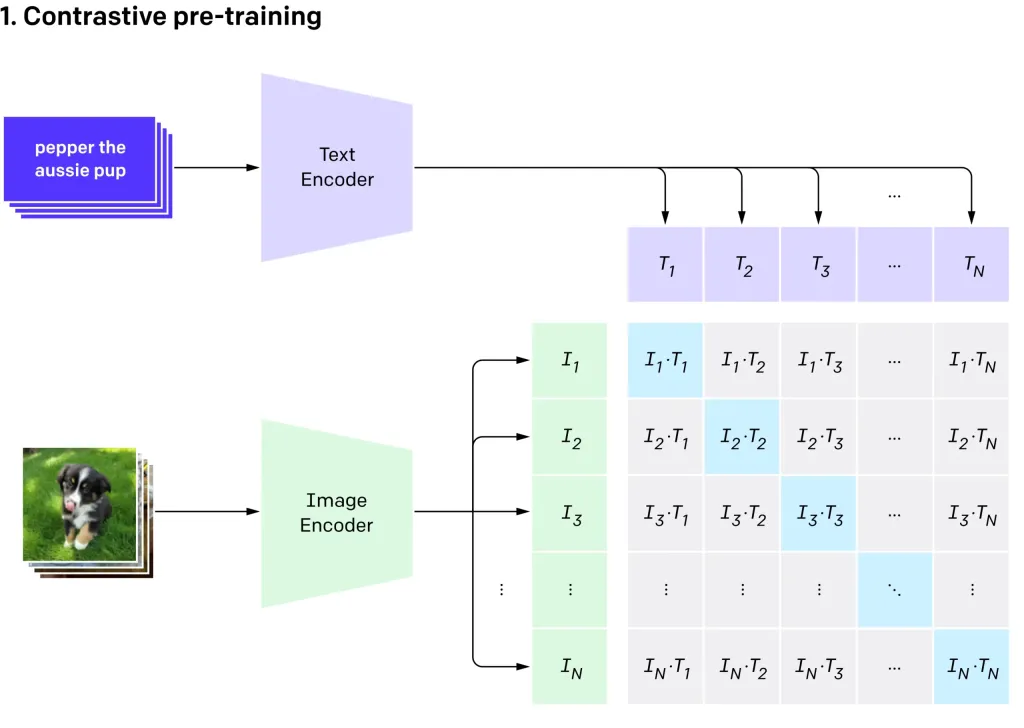 Openai'のクリップVIT-L14を使用したゼロショット画像分類Apr 11, 2025 am 10:04 AM
Openai'のクリップVIT-L14を使用したゼロショット画像分類Apr 11, 2025 am 10:04 AMOpenaiのクリップ(コントラスト言語 - イメージ前訓練)モデル、特にクリップVIT-L14バリアントは、マルチモーダル学習と自然言語処理の大幅な進歩を表しています。 この強力なコンピュータービジョンシステムは、RepreSeに優れています
 コードなしでAIエージェントを構築するための7つのステップ-AnalyticsVidhyaApr 11, 2025 am 10:03 AM
コードなしでAIエージェントを構築するための7つのステップ-AnalyticsVidhyaApr 11, 2025 am 10:03 AMWordwareを使用してAIエージェントのパワーを活用してください:楽なAIエージェント作成のためのノーコードプラットフォーム。 AIエージェントは、コンピューターとの対話方法、タスクの自動化、意思決定の合理化に革命をもたらしています。 このブログは、構築方法を示しています
 モバイルのLLMS:現在および将来の可能性 - 分析vidhyaApr 11, 2025 am 09:58 AM
モバイルのLLMS:現在および将来の可能性 - 分析vidhyaApr 11, 2025 am 09:58 AM生成AI:次のスマートフォンの戦場 スマートフォン業界は、高度な生成AIを統合するための競争である激しい競争に閉じ込められています。 ユーザーの相互作用の向上から生産性の向上まで、利害関係は高いです。 AppleのiPhone16
 2025年に続くトップ10の生成AIサブレッドディット - 分析vidhyaApr 11, 2025 am 09:51 AM
2025年に続くトップ10の生成AIサブレッドディット - 分析vidhyaApr 11, 2025 am 09:51 AM生成AI:10の必須redditコミュニティへのガイド 生成AIは急速に進化しており、新しいモデルが絶えず出現しています。 更新のままであることが重要であり、Redditはこの分野に特化した活気のあるコミュニティを提供しています。この記事はtを強調しています
 AIモデルの重要な課題と制限 - 分析VidhyaApr 11, 2025 am 09:44 AM
AIモデルの重要な課題と制限 - 分析VidhyaApr 11, 2025 am 09:44 AM導入 人工知能(AI)は、AIの研究開発への実質的な投資によって促進されたさまざまな職場に急速に統合されています。 AIのアプリケーションは、仮想アシスタントのような単純なタスクからcomまで、幅広い範囲に広がっています
 SQLでnull値を処理しますApr 11, 2025 am 09:37 AM
SQLでnull値を処理しますApr 11, 2025 am 09:37 AM導入 データベースの領域では、ヌル値はしばしば独自の課題を提示します。 欠落している、未定義、または未知のデータを表して、データ管理と分析を複雑にする可能性があります。顧客のフィードバックが欠落している販売データベースまたはORDEを検討してください


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

WebStorm Mac版
便利なJavaScript開発ツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

