
ホームページ >テクノロジー周辺機器 >AI >TensorFlow と Keras を使用すると、最初のニューラル ネットワークを簡単に構築してトレーニングできます
TensorFlow と Keras を使用すると、最初のニューラル ネットワークを簡単に構築してトレーニングできます

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-09 19:04:06932ブラウズ
AI 技術は急速に発展しており、さまざまな高度な AI モデルを使用して、チャット ロボット、人型ロボット、自動運転車などが作成できます。 AI は最も急速に成長しているテクノロジーであり、物体検出と物体分類が最近のトレンドです。
この記事では、畳み込みニューラル ネットワークを使用して画像分類モデルを最初から構築してトレーニングする完全な手順を紹介します。この記事では、公開されている Cifar-10 データセットを使用してこのモデルをトレーニングします。このデータセットは、車、飛行機、犬、猫などの日常的な物体の画像が含まれているという点でユニークです。この記事では、これらの物体でニューラル ネットワークをトレーニングすることにより、現実世界でこれらの物体を分類するインテリジェント システムを開発します。これには、10 種類のオブジェクトの 60,000 枚以上の 32x32 画像が含まれています。このチュートリアルが終わるまでに、視覚的特徴に基づいてオブジェクトを識別できるモデルが完成します。

図 1 データセットのサンプル画像|datasets.activeloop の画像
この記事では最初からすべてを説明するため、ニューラル ネットワークをまだ学習していない場合は、実際の実装はまったく問題ありません。
このチュートリアルの完全なワークフローは次のとおりです:
- 必要なライブラリのインポート
- データのロード
- データの前処理
- モデルの構築
- モデルのパフォーマンスの評価
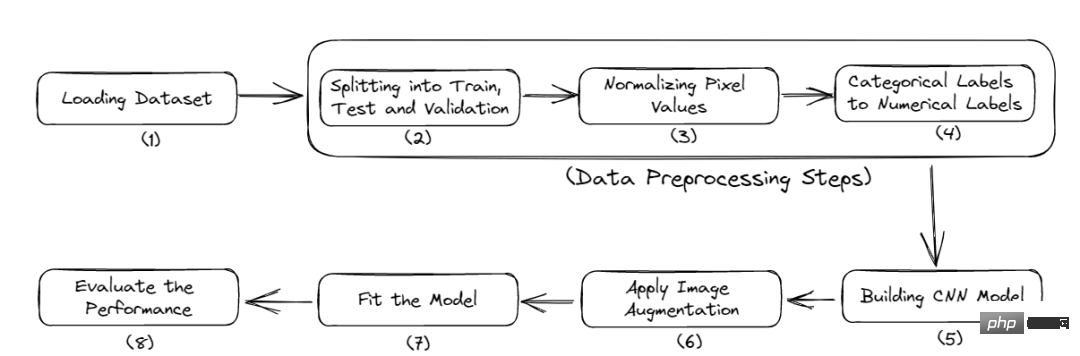
図 2 完了プロセス
必要なライブラリのインポート
このプロジェクトを開始するには、まずいくつかのモジュールをインストールする必要があります。無料の GPU トレーニングを提供する Google Colab をこの記事では使用します。
必要なライブラリをインストールするコマンドは次のとおりです:
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
ライブラリを Python ファイルにインポートします。
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>
- Numpy: 画像を含む大規模なデータセットの効率的な配列計算に使用されます。
- Tensorflow: Google が開発したオープンソースの機械学習ライブラリです。大規模でスケーラブルなモデルを構築するための多くの機能を提供します。
- Keras: TensorFlow 上で実行される別の高レベルのニューラル ネットワーク API。
- Matplotlib: この Python ライブラリはグラフを作成し、より優れたデータ視覚化を提供します。
- Sklearn: データの前処理とデータセットの特徴抽出タスクを実行する関数を提供します。これには、精度、精度、偽陽性、偽陰性などのモデル評価指標を見つけるための組み込み関数が含まれています。
次に、データの読み込みステップに入ります。
データのロード
このセクションでは、データ セットをロードし、トレーニングとテストのデータ分割を実行します。
データのロードと分割:
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>
cifar10 データセットは、Keras データセット ライブラリから直接ロードされます。そして、これらのデータもトレーニングデータとテストデータに分けられます。トレーニング データは、モデル内のパターンを認識できるようにモデルをトレーニングするために使用されます。テスト データはモデルには見えませんが、そのパフォーマンス、つまりデータ ポイントの総数に対して正しく予測されたデータ ポイントの数をチェックするために使用されます。
training_label には、training_data の画像に対応するラベルが含まれます。
次に、組み込み sklearn の train_test_split 関数を使用して、トレーニング データを検証データに再度分割します。検証データは、最終モデルの選択と調整に使用されました。最後に、すべてのトレーニング、テスト、および検証データが 32 ビット浮動小数点数に変換されます。
これで、データセットのロードが完了しました。次のセクションでは、この記事でいくつかの前処理手順を実行します。
データ前処理
データ前処理は、機械学習モデルの開発における最初で最も重要なステップです。これを行う方法については、この記事に従ってください。
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>
出力:
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
このデータセットには 10 カテゴリの画像が含まれており、各画像のサイズは 32x32 ピクセルです。各ピクセルには 0 ~ 255 の値があり、計算プロセスを簡素化するために 0 ~ 1 の間で正規化する必要があります。その後、カテゴリラベルをワンホットエンコードされたラベルに変換します。これは、機械学習アルゴリズムを問題なく適用できるように、カテゴリデータを数値データに変換するために行われます。
次に、CNN モデルの構築に入ります。
CNN モデルの構築
CNN モデルは 3 つの段階で機能します。最初のステージは、画像から関連する特徴を抽出するための畳み込みレイヤーで構成されます。第 2 段階は、イメージのサイズを削減するためのプール層で構成されます。また、モデルの過剰適合を軽減するのにも役立ちます。 3 番目のステージは、2D 画像を 1D 配列に変換する高密度のレイヤーで構成されます。最後に、この配列は完全に接続された層に入力されて、最終的な予測が行われます。
次はコードです:
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
この記事では 3 つの層グループを適用します。各グループには 2 つの畳み込み層、最大プーリング層とドロップアウト層が含まれます。 Conv2D レイヤーは、input_shape を (32, 32, 3) として受け取ります。これは画像と同じサイズでなければなりません。
各 Conv2D レイヤーには、アクティベーション関数、つまり relu も必要です。アクティベーション関数は、システムの非線形性を高めるために使用されます。より簡単に言うと、特定のしきい値に基づいてニューロンを活性化する必要があるかどうかを判断します。 ReLu、Tanh、Sigmoid、Softmax など、さまざまな種類の活性化関数があり、さまざまなアルゴリズムを使用してニューロンの発火を決定します。
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
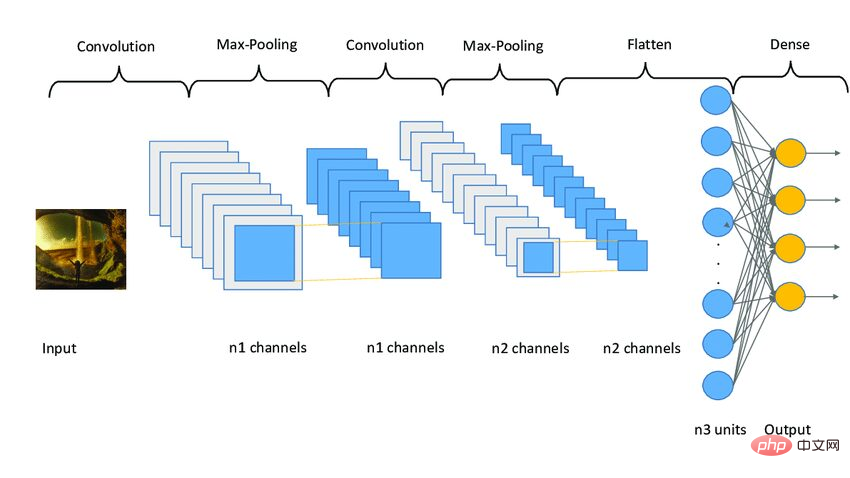
图3 Sampe CNN架构|图片来源:Researchgate
编译模型
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
拟合模型
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:

图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
评估模型性能
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>
输出:
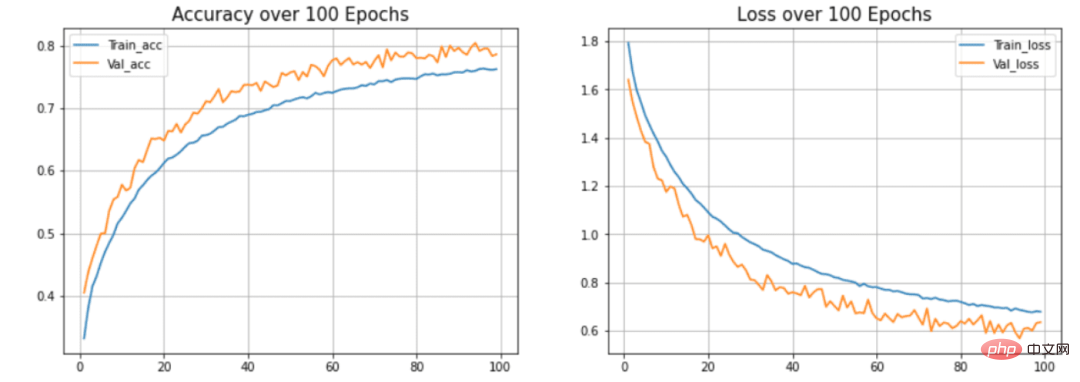
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
总结
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
以上がTensorFlow と Keras を使用すると、最初のニューラル ネットワークを簡単に構築してトレーニングできますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。