
ホームページ >Java >&#&チュートリアル >Java の HashMap のマルチスレッド同時実行問題を解決する方法
Java の HashMap のマルチスレッド同時実行問題を解決する方法

- PHPz転載
- 2023-05-09 14:28:171659ブラウズ
同時実行問題の症状
マルチスレッド put により get の無限ループが発生する可能性がある
以前、Java コードでは何らかの理由で HashMap が使用されていましたが、当時のプログラムはシングルスレッドだったので、すべて問題ありません。その後、プログラムのパフォーマンスに問題が発生したため、マルチスレッドにする必要がありました。そこで、マルチスレッドにした後、オンラインにしたところ、プログラムが CPU の 100% を占有していることがよくありました。スタックを確認すると、次のことがわかります。プログラムはすべて HashMap でハングします。.get() メソッドがインストールされており、プログラムを再起動すると問題は解消されました。しかし、しばらくするとまたやって来ます。さらに、この問題はテスト環境で再現するのが難しい場合があります。
独自のコードを単純に見ると、HashMap が複数のスレッドによって操作されていることがわかります。 Java のドキュメントには、HashMap はスレッドセーフではないため、ConcurrentHashMap を使用する必要があると記載されています。しかし、ここでその理由を学ぶことができます。単純なコードは次のとおりです:
package com.king.hashmap;
import java.util.HashMap;
public class TestLock {
private HashMap map = new HashMap();
public TestLock() {
Thread t1 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t1 over" );
}
};
Thread t2 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t2 over" );
}
};
Thread t3 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t3 over" );
}
};
Thread t4 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t4 over" );
}
};
Thread t5 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t5 over" );
}
};
Thread t6 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t6 over" );
}
};
Thread t7 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t7 over" );
}
};
Thread t8 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t8 over" );
}
};
Thread t9 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t9 over" );
}
};
Thread t10 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t10 over" );
}
};
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
t10.start();
}
public static void main(String[] args) {
new TestLock();
}
}は 10 個のスレッドを開始し、非スレッドセーフな HashMap にコンテンツを継続的に put/get コンテンツします。put の内容は非常に単純で、キーと値は次のとおりです。 0 から増加します。整数 (この put の内容が適切に行われていなかったため、後で問題を分析するという私のアイデアに支障をきたしました)。 HashMap で同時書き込み操作を実行すると、ダーティ データが生成されるだけだと思いました。しかし、このプログラムを繰り返し実行すると、スレッド t1 と t2 がハングします。ほとんどの場合、1 つのスレッドがハングし、もう 1 つは正常に終了します。 、場合によっては 10 個のスレッドすべてがハングすることがあります。
この無限ループの根本原因は、保護されていない共有変数、つまり「HashMap」データ構造の操作にあります。すべての操作方法に「同期」を追加したところ、すべてが正常に戻りました。これはjvmのバグですか?いいえ、この現象はずっと前から報告されていたと言わなければなりません。 Sun のエンジニアは、これがバグであるとは考えていませんが、そのようなシナリオでは "ConcurrentHashMap" を使用する必要があると提案しています。
過剰な CPU 使用率は、通常、無限ループの発生により発生し、一部のスレッドが実行され続けることが原因です。 . 、CPU 時間を消費します。問題の原因は、HashMap がスレッドセーフではないためで、複数のスレッドを置くと、特定のキー値 Entry key List の無限ループが発生し、問題が発生します。
別のスレッドがこのエントリ リストの無限ループのキーを取得すると、この get が常に実行されます。その結果、スレッドが無限ループに陥り、最終的にはサーバーがクラッシュします。一般に、HashMap が特定の値を繰り返し挿入すると、前の値が上書きされると考えられていますが、これは正しいです。ただし、マルチスレッド アクセスの場合、その内部実装メカニズムにより (マルチスレッド環境で同期が行われていない場合、同じ HashMap に対する put 操作により 2 つ以上のスレッドが同時に再ハッシュ操作を実行する可能性があり、これにより、循環キー テーブルが表示されると、スレッドが終了できず CPU を占有し続け、その結果 CPU 使用率が高くなり、セキュリティの問題が発生する可能性があります。
jstack ツールを使用して、問題のあるサーバーのスタック情報をダンプします。無限ループがある場合は、まず RUNNABLE のスレッドを検索し、次のように問題のコードを見つけます:
java.lang.Thread.State:RUNNABLE
at java.util.HashMap。 get(HashMap.java:303 )
at com.sohu.twap.service.logic.TransformTweeter.doTransformTweetT5(TransformTweeter.java:183)
合計 23 回登場しました。
java.lang.Thread.State:RUNNABLE
java.util.HashMap.put(HashMap.java:374)
com.sohu.twap.service.logic.TransformTweeter.transformT5(TransformTweeter. java:816)
は合計 3 回出現します。
注: HashMapを不適切に使用すると、デッドロックではなく無限ループが発生します。
マルチスレッドの put により要素が失われる可能性がある
主な問題は、addEntry メソッドの新しいエントリ (ハッシュ、キー、値、e) にあります。同時に、次の要素はすべて e になり、テーブル要素に値を割り当てると、一方は成功し、もう一方は失われます。
null 以外の要素を配置した後、得られる結果は null です。
転送メソッドのコードは次のとおりです。
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for ( int j = 0 ; j < src.length; j++) {
Entry e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}このメソッドでは、古い配列を割り当てます。 src にアクセスして src を走査する場合、src の要素が null でない場合は、src の要素を null に設定します。つまり、古い配列の要素を null に設定します。これは次の文です:
if (e != null ) {
src[j] = null ;If thereはこのキーにアクセスするための get メソッドですが、依然として古い配列を取得しますが、当然のことながら、対応する値を取得することはできません。
要約: HashMap が同期されていない場合、並行プログラムで多くの微妙な問題が発生し、表面から原因を見つけるのは困難です。したがって、HashMap の使用時に直観に反する現象が発生した場合、それは同時実行性が原因である可能性があります。
HashMap データ構造
古典的なデータ構造 HashMap について簡単に説明する必要があります。
HashMap は通常、ポインター配列 (table[] と想定) を使用してすべてのキーを分散します。キーが追加されると、配列の添字 i はハッシュ アルゴリズムを通じてキーから計算され、その後これを table[i] に挿入します。同じ i に 2 つの異なるキーが含まれる場合、それは競合と呼ばれ、衝突とも呼ばれます。これにより、table[i] にリンクされたリストが形成されます。
table[] のサイズが 2 つなど非常に小さい場合、および 10 個のキーを入力すると衝突が非常に頻繁になることがわかっているため、O(1) 検索アルゴリズムは次のようになります。リンク リストのトラバーサルがないと、パフォーマンスが O(n) になります。これは、ハッシュ テーブルの欠陥です。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this );
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null ;
}检查容量是否超标:
void addEntry( int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize( 2 * table.length);
}新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize( int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = ( int )(newCapacity * loadFactor);
}迁移的源代码,注意高亮处:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for ( int j = 0 ; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash过程
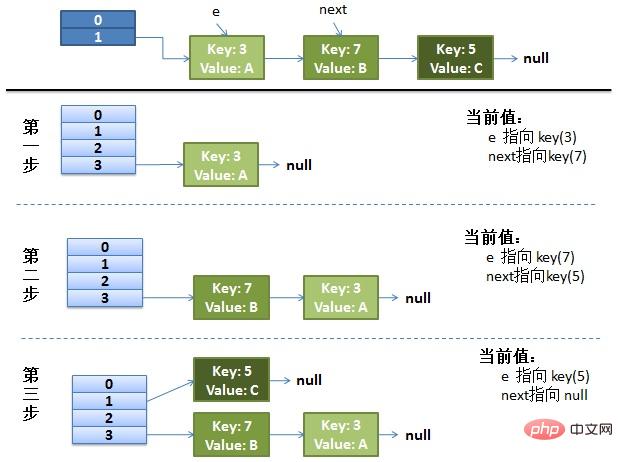
画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table1这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的 重新rehash的过程。
并发的Rehash过程
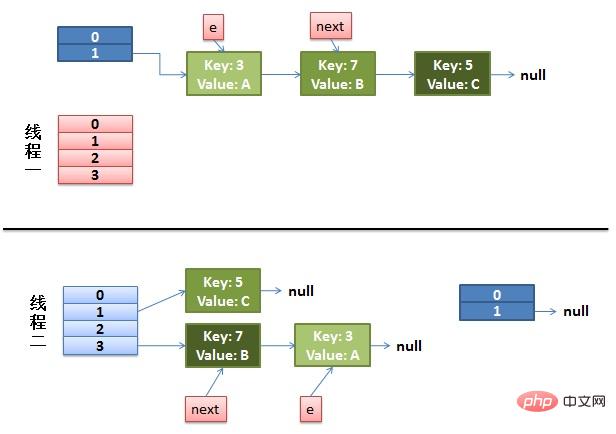
(1)假设我们有两个线程。我用红色和浅蓝色标注了一下。我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );而我们的线程二执行完成了。于是我们有下面的这个样子。
注意:因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
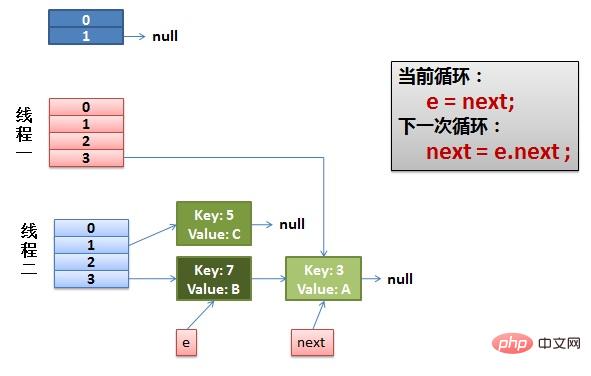
(2)线程一被调度回来执行。
先是执行 newTalbe[i] = e。
然后是e = next,导致了e指向了key(7)。
而下一次循环的next = e.next导致了next指向了key(3)。
(3)一切安好。 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
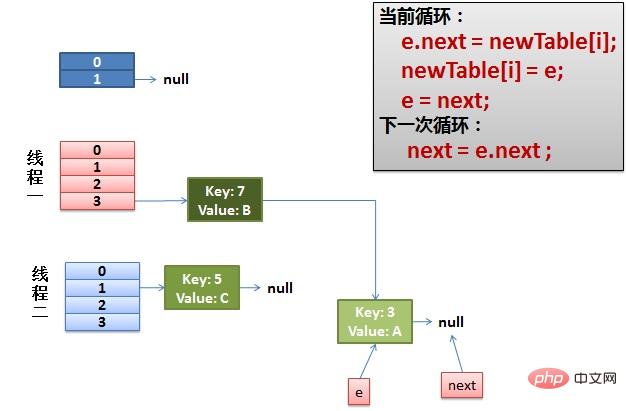
(4)环形链接出现。 e.next = newTable[i] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
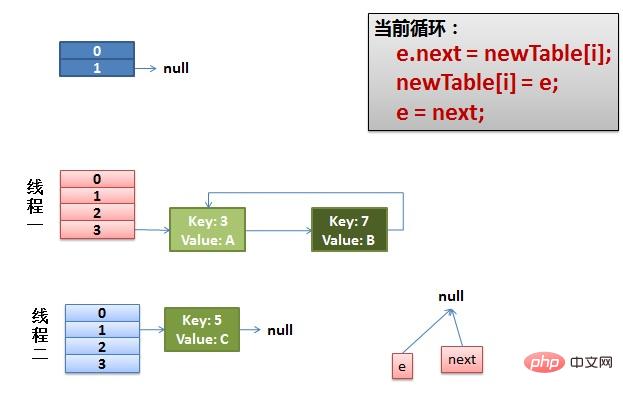
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三种解决方案
Hashtable替换HashMap
Hashtable 是同步的,但由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 视图方法”返回的 Collection 的 listIterator 方法都是快速失败的:在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的移除或添加方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险。由 Hashtable 的键和值方法返回的 Enumeration 不是快速失败的。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测程序错误。
Collections.synchronizedMap将HashMap包装起来
返回由指定映射支持的同步(线程安全的)映射。为了保证按顺序访问,必须通过返回的映射完成对底层映射的所有访问。在返回的映射或其任意 collection 视图上进行迭代时,强制用户手工在返回的映射上进行同步:
Map m = Collections.synchronizedMap( new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized (m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}不遵从此建议将导致无法确定的行为。如果指定映射是可序列化的,则返回的映射也将是可序列化的。
ConcurrentHashMap は HashMap を置き換えます
取得における完全な同時実行性と、更新における必要な調整可能な同時実行性をサポートするハッシュ テーブル。このクラスは Hashtable と同じ機能仕様に準拠しており、Hashtable の各メソッドに対応するメソッド バージョンを含みます。ただし、すべての操作はスレッドセーフですが、取得操作をロックする必要はなく、すべてのアクセスを阻止する方法でテーブル全体をロックすることはサポートされていません。このクラスは、同期の詳細とは関係なく、スレッド セーフに応じて、プログラム的にハッシュテーブルと完全に相互運用できます。取得操作 (get を含む) は通常、ブロックされないため、更新操作 (put および delete を含む) と重複する可能性があります。取得は、最後に完了した更新操作の結果に影響します。 putAll や clear などの一部の集計操作では、同時取得は特定のエントリの挿入と削除にのみ影響する場合があります。同様に、反復子と列挙型は、反復子/列挙型の作成時またはそれ以降、ある時点でのハッシュ テーブルの状態に影響を与えた要素を返します。 ConcurrentModificationException はスローされません。ただし、イテレータは一度に 1 つのスレッドのみで使用されるように設計されています。
以上がJava の HashMap のマルチスレッド同時実行問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。