
ホームページ >テクノロジー周辺機器 >AI >パラメータは半分でCLIPと同等、ピクセルから画像とテキストの一体化を実現するビジュアルTransformerです。
パラメータは半分でCLIPと同等、ピクセルから画像とテキストの一体化を実現するビジュアルTransformerです。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-05 20:43:051666ブラウズ
近年、Transformer に基づく大規模なマルチモーダル トレーニングにより、視覚、言語、音声など、さまざまな分野の最先端テクノロジーの向上が実現しています。特にコンピューター ビジョンと画像言語の理解では、事前トレーニングされた単一の大規模モデルが、特定のタスクに関してエキスパート モデルよりも優れたパフォーマンスを発揮する可能性があります。
ただし、大規模なマルチモーダル モデルでは、モダリティまたはデータセット固有のエンコーダーとデコーダーが使用されることが多く、それに応じてプロトコルが複雑になります。たとえば、このようなモデルには、データセット固有の前処理を使用したり、タスク固有の方法でさまざまな部分を転送したりして、それぞれのデータセット上でモデルのさまざまな部分をトレーニングするさまざまな段階が含まれることがよくあります。このパターンとタスク固有のコンポーネントは、新しい事前トレーニングの損失や下流タスクを導入するときに、エンジニアリングのさらなる複雑さと課題を引き起こす可能性があります。
したがって、あらゆるモダリティまたはモダリティの組み合わせを処理できる単一のエンドツーエンド モデルを開発することは、マルチモーダル学習への重要なステップとなります。この記事では、チューリッヒの Google Research (Google Brain チーム) の研究者が主に画像とテキストに焦点を当てます。

論文アドレス: https://arxiv.org/pdf/2212.08045.pdf
#多くの主要な統合により、マルチモーダル学習のプロセスが加速されます。まず、Transformer アーキテクチャが一般的なバックボーンとして機能し、テキスト、ビジュアル、オーディオ、その他のドメインで適切にパフォーマンスを発揮できることが証明されています。第 2 に、多くの論文では、入出力インターフェイスを簡素化するため、または複数のタスクに対応する単一のインターフェイスを開発するために、さまざまなモダリティを単一の共有埋め込み空間にマッピングすることを検討しています。第三に、モダリティの代替表現により、あるドメインでのニューラル アーキテクチャまたは別のドメインで設計されたトレーニング手順の利用が可能になります。たとえば、[54] と [26,48] はそれぞれテキストとオーディオを表し、これらの形式を画像 (オーディオの場合はスペクトログラム) としてレンダリングすることによって処理されます。この記事では、純粋にピクセルベースのモデルを使用したテキストと画像のマルチモーダル学習について説明します。このモデルは、RGB イメージとしてレンダリングされるビジュアル入力またはテキスト、またはその両方を一緒に処理する別個のビジュアル Transformer です。すべてのモダリティは、低レベルの特徴処理を含む同じモデル パラメーターを使用します。つまり、モダリティ固有の初期畳み込み、トークン化アルゴリズム、または入力埋め込みテーブルはありません。このモデルは、CLIP と ALIGN によって普及した対照学習という 1 つのタスクのみでトレーニングされます。したがって、このモデルは CLIP-Pixels Only (CLIPPO) と呼ばれます。
画像分類とテキスト/画像検索用に設計された CLIP の主なタスクでは、CLIPPO は特定のタワー モダリティを持たないにもかかわらず、CLIP と同様に実行します (1 ~ 2% 以内の類似性) )。驚くべきことに、CLIPPO は、左から右への言語モデリング、マスクされた言語モデリング、または明示的な単語レベルの損失を必要とせずに、複雑な言語理解タスクを実行できます。特に GLUE ベンチマークでは、CLIPPO は ELMO BiLSTM の注目などの古典的な NLP ベースラインを上回っており、さらに、ピクセルベースのマスク言語モデルも上回っており、BERT のスコアに近づいています。
興味深いことに、CLIPPO は、画像とテキストを一緒にレンダリングするだけの場合でも、そのようなデータで事前トレーニングされていないにもかかわらず、VQA で優れたパフォーマンスを達成します。従来の言語モデルと比較したピクセルベースのモデルの直接的な利点は、事前に決定された語彙が必要ないことです。その結果、従来のトークナイザーを使用した同等のモデルと比較して、多言語検索のパフォーマンスが向上しました。最後に、この研究では、CLIPPO をトレーニングすると、以前に観察されたモーダル ギャップが減少する場合があることもわかりました。
メソッドの概要
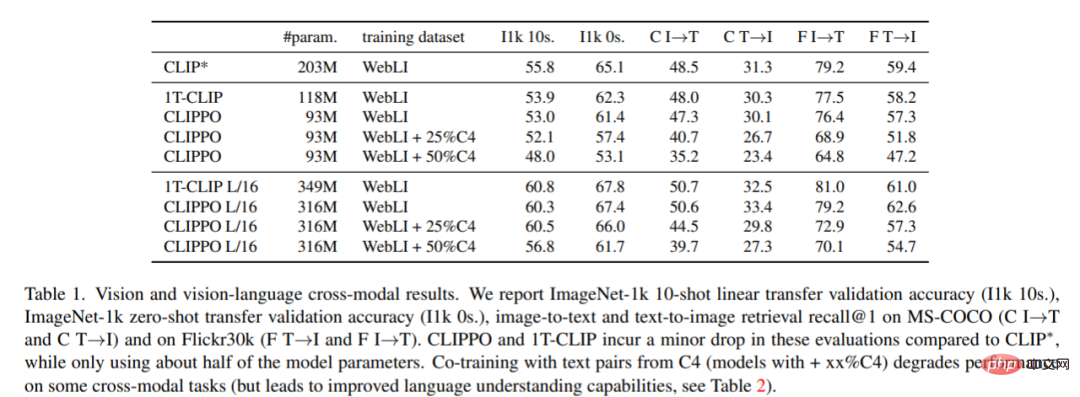
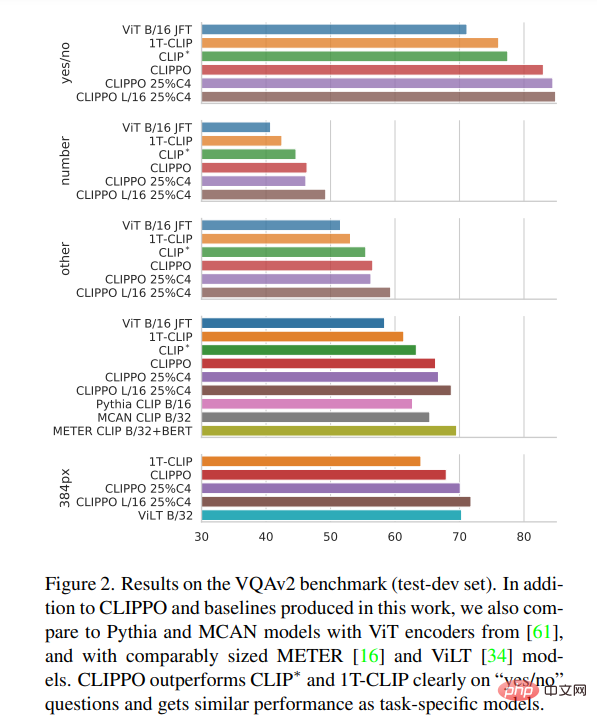
CLIP は、データセット上で多目的ビジョン モデルをトレーニングするための強力でスケーラブルなパラダイムとして登場しました。具体的には、このアプローチは画像と代替テキストのペアに依存しており、Web から大規模に自動的に収集できます。その結果、テキストによる説明は多くの場合ノイズが多くなり、単一のキーワード、キーワードのセット、または場合によっては長い説明で構成される場合があります。このデータを使用して、2 つのエンコーダー、つまり代替テキストを埋め込むテキスト エンコーダーと、共有潜在空間に対応する画像を埋め込む画像エンコーダーが共同トレーニングされます。 2 つのエンコーダーは、対応する画像と代替テキストの埋め込みが他のすべての画像と代替テキストの埋め込みとは異なる一方で、類似するように促す対照的な損失を使用してトレーニングされます。このようなエンコーダ ペアは、一度トレーニングされると、さまざまな方法で使用できます。テキストの説明によって視覚的概念の固定セットを分類できます (ゼロショット分類)。埋め込みを使用して、特定の情報を取得できます。あるいは、ラベル付きデータセットで微調整するか、凍結された画像エンコーダ表現でヘッドをトレーニングすることにより、ビジュアル エンコーダを教師付きの方法で下流のタスクに転送することもできます。原理的には、テキスト エンコーダは独立したテキスト埋め込みとして使用できます。しかし、誰もこのアプリケーションに関する詳細な研究を行っていないと報告されています。一部の研究では、低品質の代替テキストが引用されており、その結果、言語モデリングのパフォーマンスが低下します。テキストエンコーダ。 これまでの研究では、パッチ埋め込みを使用して画像が埋め込まれる共有トランスフォーマー モデル (シングル タワー モデル、または 1T-CLIP とも呼ばれます) を使用して画像エンコーダーとテキスト エンコーダーを実装できることが示されています。 , トークン化されたテキストは、別の単語埋め込みを使用して埋め込まれます。モダリティ固有の埋め込みを除き、すべてのモデル パラメーターは 2 つのモダリティ間で共有されます。このタイプの共有では通常、画像/画像から言語へのタスクのパフォーマンスが低下しますが、モデル パラメーターの数も半分に減ります。 CLIPPO は、このアイデアをさらに一歩進めます。テキスト入力は空白の画像上にレンダリングされ、最初のパッチの埋め込みを含めて全体が画像として処理されます (図 1 を参照)。以前の研究との比較トレーニングを通じて、単一のビジュアル インターフェイスを通じて画像とテキストを理解できる単一のビジュアル トランスフォーマー モデルが生成され、画像、画像言語、および純粋言語の理解タスクを解決するために使用できるソリューションを提供します。 CLIPPO は、マルチモーダルな多用途性に加えて、テキスト処理における一般的な困難、つまり適切なトークナイザーと語彙の開発を軽減します。これは、テキスト エンコーダが数十の言語を処理する必要がある大規模な多言語設定のコンテキストで特に興味深いものです。 画像と代替テキストのペアでトレーニングされた CLIPPO は、公開画像と画像言語のベンチマーク、および強力なベースラインを使用した GLUE ベンチマークで 1T-CLIP と同等のパフォーマンスを発揮することがわかります。言語モデルコンテスト。ただし、代替テキストは品質が低く、通常は文法的な文章ではないため、代替テキストだけから言語理解を学習することには基本的に限界があります。したがって、言語ベースのコントラスト トレーニングを画像/代替テキストのコントラストの事前トレーニングに追加できます。具体的には、テキストコーパスからサンプリングされた連続した文のペア、異なる言語で翻訳された文のペア、翻訳後の文のペア、および単語が欠落している文のペアを考慮する必要があります。 視覚および視覚言語理解 画像の分類と検索#。表 1 は CLIPPO のパフォーマンスを示しており、CLIPPO と 1T-CLIP は CLIP* と比較して絶対値が 2 ~ 3 パーセント減少していることがわかります。 VQA。モデルとベースラインの VQAv2 スコアを図 2 に示します。 CLIPPO は CLIP∗、1T-CLIP、ViT-B/16 を上回り、66.3 のスコアを達成していることがわかります。 #多言語ビジョン - 言語理解
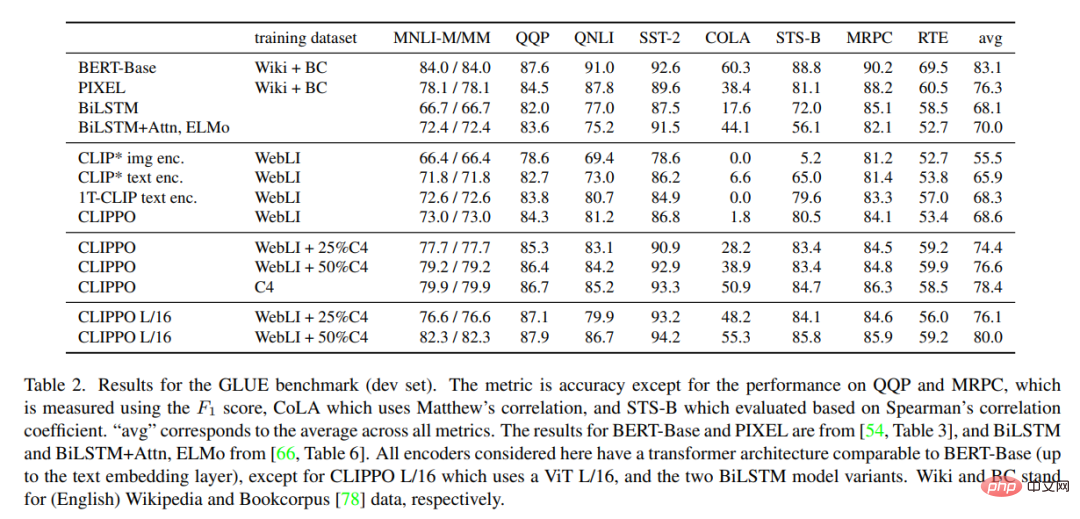
表 2 は、CLIPPO とベースラインの GLUE ベンチマーク結果を示しています。 WebLI でトレーニングされた CLIPPO は、大規模な言語コーパスでトレーニングされた深い単語埋め込みを備えた BiLSTM Attn ELMo ベースラインと競合することがわかります。さらに、CLIPPO と 1T-CLIP は、標準的な対比言語視覚事前トレーニングを使用してトレーニングされた言語エンコーダーよりも優れたパフォーマンスを発揮することがわかります。 研究の詳細については、元の論文を参照してください。 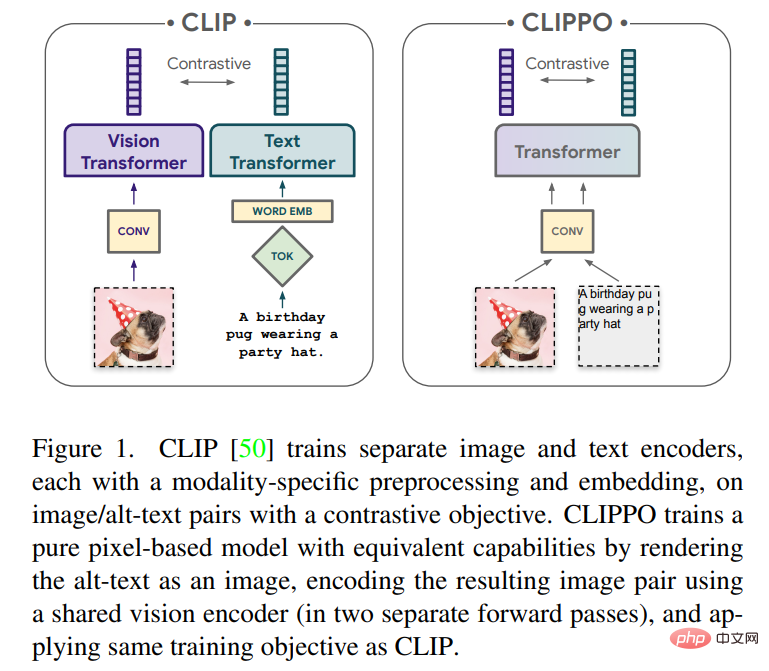
実験結果
言語理解
以上がパラメータは半分でCLIPと同等、ピクセルから画像とテキストの一体化を実現するビジュアルTransformerです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。