
ホームページ >テクノロジー周辺機器 >AI >ツールフォーマーの解釈
ツールフォーマーの解釈

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-05 20:10:051679ブラウズ
大規模言語モデル (LLM) は、限られたテキスト データを使用して新しいタスクを解決する際に驚くべき利点を示しています。しかし、それにもかかわらず、次のような他の点で制限があります。
- 最新情報へのアクセスの欠如
- 事実について空想する傾向
- 低リソース言語の問題点
- 正確な計算のための数学的スキルの欠如
- 時間プロセスの理解の欠如
大規模なモデルを使用してより多くの問題を解決する方法?記事「TaskMatrix.AIの解釈」では、TaskMatrix.AIはToolformerとchatGPTを組み合わせたもので、基本モデルを何百万ものAPIと接続してタスクを完了します。では、ツールフォーマーとは何でしょうか?
Toolformer は、電卓、Wikipedia 検索、辞書検索など、API の使用を必要とする問題を解決できる Meta の新しいオープンソース モデルです。 Toolformer は、ツールを使用する必要があることを認識し、使用するツールとツールの使用方法を決定します。 Toolformers の使用例は、あらゆる質問に対する即時検索結果の提供から、町の最高のレストランなどのコンテキスト情報の提供まで、無限に広がる可能性があります。
1.Toolformer とは何ですか?
ツールフォーマーとは何ですか?つまり、Toolformer は、ツールの使用方法を自ら学習できる言語モデルです。
Toolformer は、自己教師あり学習手法を使用してトレーニングされた、67 億個のパラメーターを備えた事前トレーニング済み GPT-J モデルに基づいています。このアプローチには、既存のテキスト データセットを拡張するための API 呼び出しのサンプリングとフィルタリングが含まれます。
Toolformer は、次の 2 つの要件を通じて、ツールの使用方法を自己学習する LLM のタスクを完了したいと考えています。
- ツールの使用方法は、指導者を必要とせずに自己監視を通じて学習する必要があります。多くの肉体労働に注意してください。
- LM は汎用性を失わず、どのツールをいつどのように使用するかを自分で決定できる必要があります。
次の図は、Toolformer の予測 (データ サンプルに埋め込まれた API 呼び出しなど) を示しています。

2. Toolformer のアーキテクチャと実装方法
ChatGPT の中核機能の 1 つは、コンテキストベースの学習 (インコンテキスト学習) です。これは、モデルが特定のコンテキストまたは環境から提示される機械学習方法を指します。例から。コンテキスト学習の目標は、特定のコンテキストや状況に適した言語を理解し、生成するモデルの能力を向上させることです。自然言語処理 (NLP) タスクでは、特定のプロンプトや質問に対する応答を生成するように言語モデルをトレーニングできます。では、Toolformer はどのように In-Context Learning を活用しているのでしょうか?
Toolformer は、API 呼び出しを通じてさまざまなツールの使用を可能にする大規模な言語モデルです。各 API 呼び出しの入力と出力は、セッション内で自然に流れるように、一連のテキスト/会話としてフォーマットする必要があります。

上の画像からわかるように、Toolformer はまずモデルのコンテキスト学習機能を活用して、潜在的な多数の API 呼び出しをサンプリングします。
これらの API 呼び出しを実行し、取得した応答が将来のトークンの予測に役立ち、フィルター基準として使用できるかどうかを確認します。フィルタリング後、さまざまなツールへの API 呼び出しが生データ サンプルに埋め込まれ、その結果、モデルが微調整された強化されたデータセットが生成されます。
具体的には、上の図は、質問と回答ツールを使用してこのタスクを実行するモデルを示しています:
- LM データセットにはサンプル テキストが含まれています: 「ピッツバーグ」の場合はプロンプト「ピッツバーグ」と入力してくださいとしても知られています。」は「鋼鉄都市」としても知られています。
- 正しい答えを見つけるには、モデルが API 呼び出しを行って正しく行う必要があります。
- いくつかの API 呼び出し、特に「ピッツバーグは他にどのような名前で知られていますか?」および「ピッツバーグはどの国にありますか?」がサンプリングされました。
- 対応する答えは「Steel City」と「United States」です。最初の答えの方が優れているため、API 呼び出し「ピッツバーグは [QA("ピッツバーグの他の名前は何によって知られていますか?") -> Steel City] the Steel City とも呼ばれる、新しい LM データセットに組み込まれます。 。
- これには、予期される API 呼び出しと応答が含まれています。この手順を繰り返して、さまざまなツール (API 呼び出しなど) を使用して新しい LM データセットを生成します。
したがって、LM はテキストに埋め込まれた API 呼び出しを使用して大量のデータに注釈を付け、次にこれらの API 呼び出しを使用して LM を微調整して有用な API 呼び出しを実行します。これが自己教師ありトレーニングの仕組みであり、このアプローチの利点は次のとおりです。
- 手動の注釈の必要性が少なくなります。
- API 呼び出しをテキストに埋め込むことで、LM は複数の外部ツールを使用してコンテンツを追加できるようになります。
Toolformer は、各タスクにどのツールが使用されるかを予測することを学習します。
2.1 API 呼び出しのサンプリング
次の図は、Toolformer がユーザー入力に応じて API 呼び出しの開始と終了を表すために と を使用することを示しています。 API ごとにプロンプトを記述すると、Toolformer がサンプルに関連する API 呼び出しの注釈を付けることが促進されます。

Toolformer は、指定されたシーケンスの継続の可能性として各トークンに確率を割り当てます。このメソッドは、シーケンス内の各位置で API 呼び出しを開始するために ToolFormer によって割り当てられた確率を計算することにより、API 呼び出しの候補位置を最大 k 個サンプリングします。指定されたしきい値よりも確率が高い位置が保持されます。各位置について、API 呼び出しの接頭辞とシーケンス終了マーカーの接尾辞が付いたシーケンスを使用して Toolformer からサンプリングすることによって、最大 m 個の API 呼び出しが取得されます。
2.2 API 呼び出しの実行
API 呼び出しの実行は、呼び出しを実行しているクライアントに完全に依存します。クライアントは、別のニューラル ネットワークから Python スクリプト、大規模なコーパスを検索する検索システムまで、さまざまな種類のアプリケーションにすることができます。クライアントが呼び出しを行うと、API は単一のテキスト シーケンス応答を返すことに注意することが重要です。この応答には、呼び出しの成功または失敗のステータス、実行時間など、呼び出しに関する詳細情報が含まれています。
したがって、正確な結果を得るために、クライアントは正しい入力パラメータが提供されていることを確認する必要があります。入力パラメータが正しくない場合、API は間違った結果を返す可能性があり、それはユーザーにとって受け入れられない可能性があります。さらに、クライアントは、通話中の接続の中断やその他のネットワークの問題を回避するために、API への接続が安定していることを確認する必要があります。
2.3 API 呼び出しのフィルタリング
フィルタリング プロセス中、Toolformer は、API 呼び出し後のトークンを介して Toolformer の加重クロスエントロピー損失を計算します。
次に、2 つの異なる損失計算を比較します。
(i) 1 つは、Toolformer への入力として結果を含む API 呼び出しです。
(ii) 1 つは API 呼び出しなし、またはAPI 呼び出しが行われましたが、結果が返されませんでした。
API 呼び出しに提供される入力と出力により、Toolformer が将来のトークンを予測しやすくなる場合、API 呼び出しは有用であるとみなされます。フィルタリングしきい値を適用して、2 つの損失の差がしきい値以上である API 呼び出しのみを保持します。
2.4 モデルの微調整
最後に、Toolformer は残りの API 呼び出しを元の入力とマージし、新しい API 呼び出しを作成してデータセットを強化します。つまり、拡張されたデータセットには、元のデータセットと同じテキストが含まれており、API 呼び出しのみが挿入されています。
次に、新しいデータ セットを使用して、標準言語モデリングの目標を使用して ToolFormer を微調整します。これにより、拡張されたデータセットでのモデルの微調整が、元のデータセットでの微調整と同じコンテンツに公開されるようになります。 API 呼び出しを正確な位置に挿入し、ヘルプ モデルを使用して将来のトークンの入力を予測することで、拡張データを微調整することで、言語モデルが独自のフィードバックに基づいて API 呼び出しをいつどのように使用するかを理解できるようになります。
2.5 推論
推論中、言語モデルが API 呼び出しに対して次に期待される応答を示す「→」トークンを生成すると、デコード プロセスは中断されます。次に、適切な API を呼び出して応答を取得し、応答とトークンを挿入した後デコードを続行します。
この時点で、取得した応答が前のトークンから期待される応答と一致することを確認する必要があります。一致しない場合は、正しい応答を取得するように API 呼び出しを調整する必要があります。デコードに進む前に、推論プロセスの次のステップに備えていくつかのデータ処理を実行する必要もあります。これらのデータプロセスには、応答の分析、コンテキストの理解、推論パスの選択が含まれます。したがって、推論プロセス中に、API を呼び出して応答を取得するだけでなく、推論プロセスの正確さと一貫性を確保するために一連のデータ処理と分析を実行する必要があります。
2.6 API ツール
Toolformer で使用できるすべての API ツールは、次の 2 つの条件を満たす必要があります:
- 入力/出力はテキストとして表現される必要があります。順序 。
- これらのツールの使用方法を示すデモが用意されています。
Toolformer の初期実装では、次の 5 つの API ツールがサポートされています。
- Q&A: これは、簡単な事実に関する質問に答える別の LM です。
- 電卓: 現在、基本的な四則演算と小数点第 2 位への四捨五入のみをサポートしています。
- Wiki 検索: Wikipedia から切り取った短いテキストを返す検索エンジン。
- 機械翻訳システム: あらゆる言語のフレーズを英語に翻訳できる LM。
- Calendar: 入力を受け付けずに現在の日付を返すカレンダーへの API 呼び出し。
次の図は、使用されるすべての API の入力例と出力例を示しています:

3. アプリケーション例
Toolformer は、LAMA、数学データセット、質問応答、時間データセットなどのタスクではベースライン モデルや GPT-3 よりも優れていますが、多言語質問応答では他のモデルよりもパフォーマンスが劣ります。 Toolformer は、LAMA API、電卓 API、Wikipedia 検索ツール API などの API 呼び出しを使用してタスクを完了します。
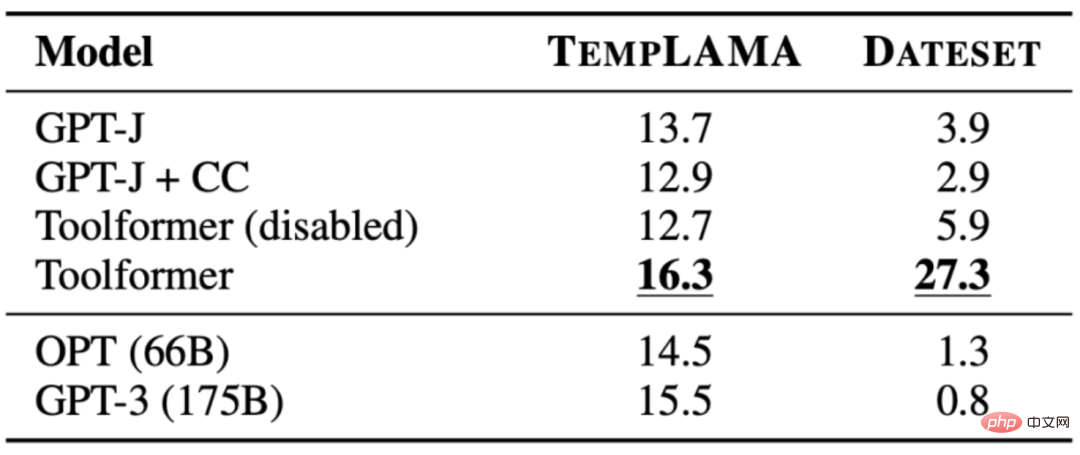
3.1 LAMA
課題は、事実が欠けている陳述を完成させることです。 Toolformer は、ベースライン モデルだけでなく、GPT-3 などのより大きなモデルよりも優れたパフォーマンスを発揮します。次の表は、LAMA API 呼び出しを通じて取得された結果を示しています。
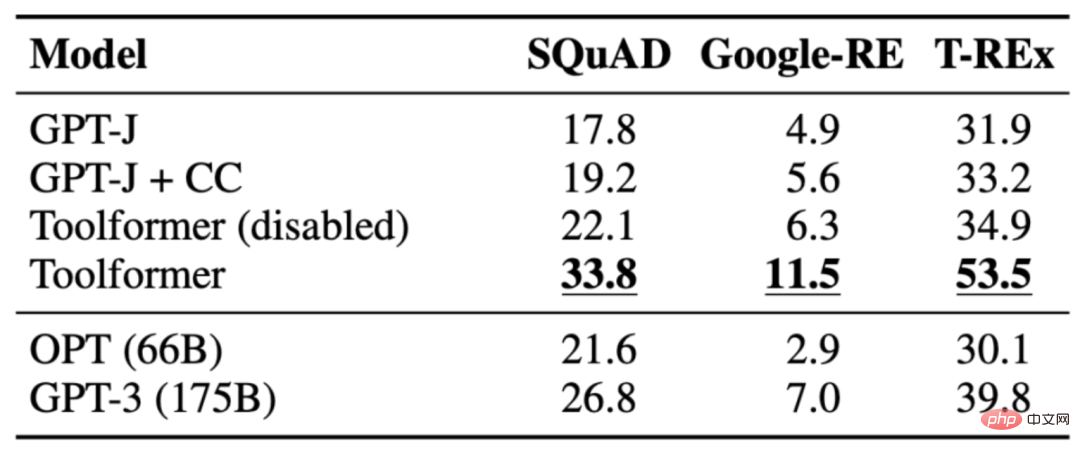
3.2 数学的データセット
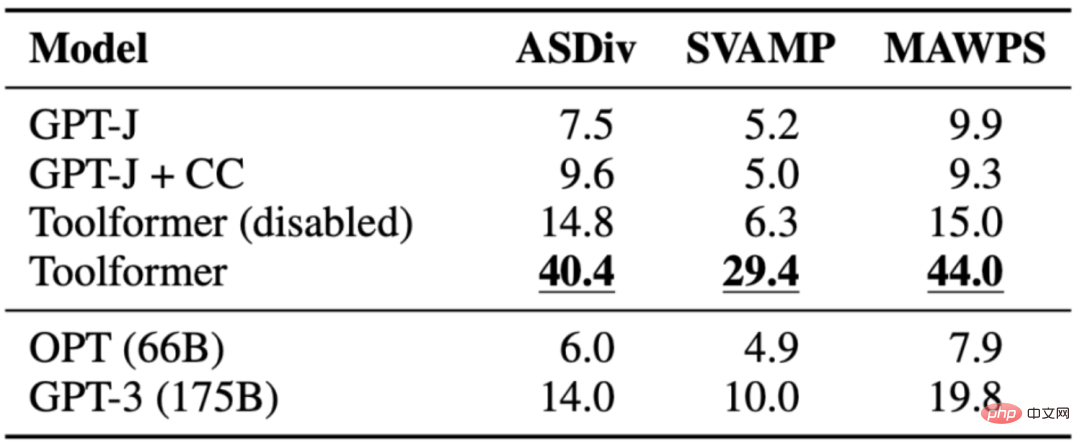
タスクは、数学的推論を評価することです。 Toolformer のさまざまなベースライン モデルを比較する機能。 Toolformer は、おそらく API 呼び出しの例が微調整されているため、他のモデルよりもパフォーマンスが優れています。モデルに API 呼び出しを許可すると、すべてのタスクのパフォーマンスが大幅に向上し、OPT や GPT-3 などのより大きなモデルよりも優れたパフォーマンスを発揮します。ほとんどの場合、モデルは計算ツールに助けを求めることにしました。
次の表は、電卓 API 呼び出しを通じて取得された結果を示しています。
3.3 質問の回答
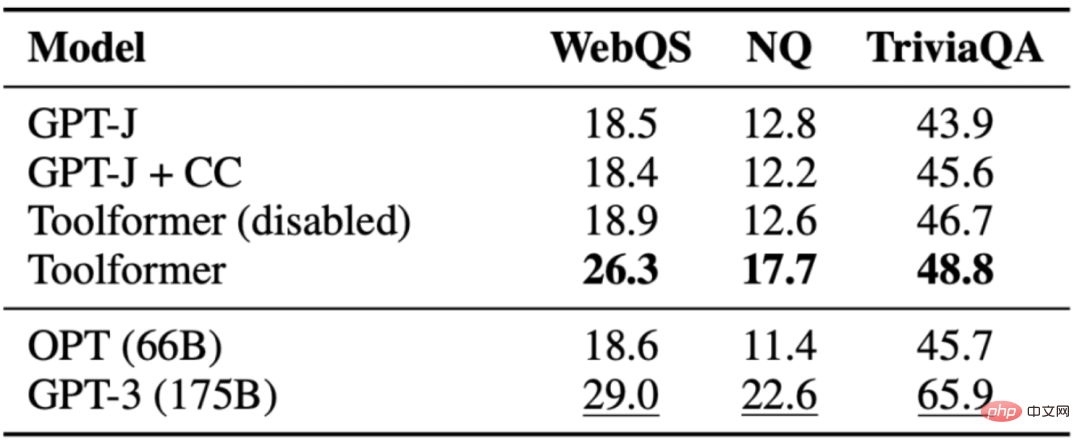
課題は、質問に答えることです。Toolformer は、同じサイズのベースライン モデルよりも優れていますが、GPT-3(175B) よりも優れています。 Toolformer は、このタスクのほとんどの例で Wikipedia の検索ツールを利用します。次の表は、Wikipedia 検索ツール API 呼び出しを通じて取得された結果を示しています。
3.4 多言語の質問と回答
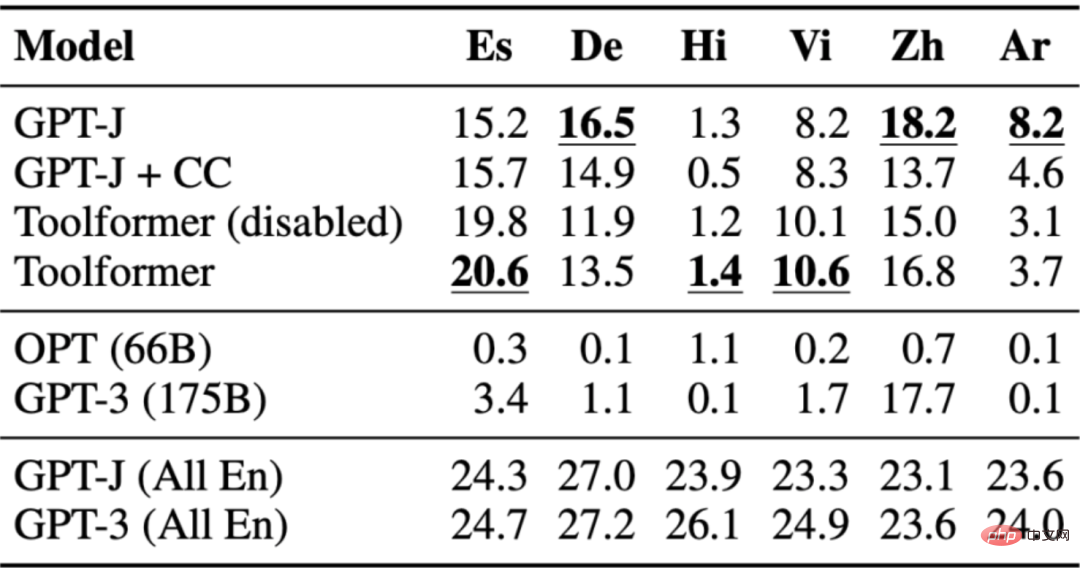
質問と回答データセットは、多言語質問応答ベンチマーク MLQA で使用されます。このベンチマークには、英語のコンテキスト文と、アラビア語、ドイツ語、スペイン語、ヒンディー語、ベトナム語、または簡体字中国語の質問が含まれています。 Toolformer は、おそらく CCNet がすべての言語にわたって調整されていないため、ここでは最も優れたパフォーマンスを発揮するわけではありません。
次の表は、Wikipedia 検索ツール API 呼び出しを通じて取得された結果を示しています。
3.5 時間データセット
課題は、質問に答えるために現在の日付がどこに重要であるかを知ることです。 Toolformer はベースラインを上回るパフォーマンスを発揮できましたが、明らかにカレンダー ツールを 100% 活用していませんでした。代わりに、Wikipedia 検索を使用します。次の表は、Wikipedia 検索ツール API 呼び出しを通じて取得された結果を示しています:
4. ToolFormer の制限
Toolformer にはまだ次のような機能があります。いくつかの制限 複数のツールを同時に使用できないこと、多すぎる結果を返すツールを処理できないこと、非効率につながる入力文言への敏感さ、高い計算コストにつながる可能性のある使用コストを考慮していないことなどの制限。詳細は次のとおりです:
- 各ツールの API 呼び出しは独立して生成されるため、Toolformer は 1 つのプロセスで複数のツールを使用できません。
- 特に、何百もの異なる結果を返す可能性のあるツール (検索エンジンなど) の場合、Toolformer は対話的に使用できません。
- Toolformer を使用してトレーニングされたモデルは、入力の正確な表現に非常に敏感です。このアプローチは一部のツールでは非効率的で、少数の有用な API 呼び出しを生成するには広範なドキュメントが必要です。
- 各ツールの使用を決定する場合、その使用コストは考慮されないため、計算コストが高くなる可能性があります。
5. 概要
Toolformer は、インコンテキスト学習を使用して、特定のコンテキストや状況に適した言語を理解して生成するモデルの能力を向上させる大規模な言語モデルです。 API 呼び出しを使用して大量のデータに注釈を付け、次にこれらの API 呼び出しを使用してモデルを微調整し、有用な API 呼び出しを実行します。 Toolformer は、各タスクにどのツールが使用されるかを予測することを学習します。ただし、Toolformer には、プロセス内で複数のツールを使用できないことや、何百もの異なる結果を返す可能性のある対話型ツールを使用できないことなど、いくつかの制限があります。
#[参考資料と関連書籍]- Toolformer: Language Models Can Teach Self to Use Tools、https://arxiv.org/pdf/2302.04761.pdf
- Meta の Toolformer は API を使用してゼロショット NLP タスクで GPT-3 を上回ります。 https://www.infoq.com/news/2023/04/meta-toolformer/
- Toolformer: 言語モデルで教えられる自分自身でツールを使用する (2023)、https://kikaben.com/toolformer-2023/
- ツールフォーマーの分析、https://www.shape.ai/blog/breaking-down-toolformer
- Toolformer: Meta が Wikipedia を使用した新しいモデルで ChatGPT レースに再参入、https://thechainsaw.com/business/meta-toolformer-ai/
- Toolformer 言語モデルは独自の外部ツールを使用します、https://the-decoder.com/toolformer- language-model-uses-external-tools-on-its-own/
以上がツールフォーマーの解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。