
ホームページ >テクノロジー周辺機器 >AI >RLHF なしで人間の位置合わせが可能、ChatGPT に匹敵するパフォーマンス!中国チームがウォンバットモデルを提案
RLHF なしで人間の位置合わせが可能、ChatGPT に匹敵するパフォーマンス!中国チームがウォンバットモデルを提案

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-03 11:46:061422ブラウズ
OpenAI の ChatGPT は、さまざまな人間の指示を理解し、さまざまな言語タスクで適切に実行できます。これは、RLHF (Aligned Human Feedback via Reinforcement Learning) と呼ばれる新しい大規模言語モデル微調整手法のおかげで可能になります。
RLHF アプローチは、人間の指示に従う言語モデルの能力を解放し、言語モデルの機能を人間のニーズや価値観と一致させます。
現在、RLHF の研究作業では主に PPO アルゴリズムを使用して言語モデルを最適化しています。ただし、PPO アルゴリズムには多くのハイパーパラメータが含まれており、アルゴリズムの反復プロセス中に複数の独立したモデルが相互に連携する必要があるため、実装の詳細が間違っているとトレーニング結果が低下する可能性があります。
同時に、人間との整合性の観点からは、強化学習アルゴリズムは必要ありません。

紙のアドレス: https://arxiv.org/abs/2304.05302v1
プロジェクト アドレス: https://github.com/GanjinZero/RRHF
この目的のために、Alibaba 著者DAMO アカデミーと清華大学の研究者らは、ランキングベースの人間の好みの調整 (RRHF) と呼ばれる手法を提案しました。
RRHF 強化学習は必要なく、ChatGPT、GPT-4、または現在の言語モデルを含むさまざまな言語モデルによって生成された応答を利用できます。トレーニングモデル。 RRHF は、回答をスコアリングし、ランキングの損失を通じて回答を人間の好みに合わせることで機能します。
PPO とは異なり、RRHF のトレーニング プロセスでは、人間の専門家の成果や GPT-4 を比較として使用できます。トレーニングされた RRHF モデルは、生成言語モデルと報酬モデルの両方として使用できます。
#Playgound AI の CEO は、これが最近最も興味深い論文であると述べました
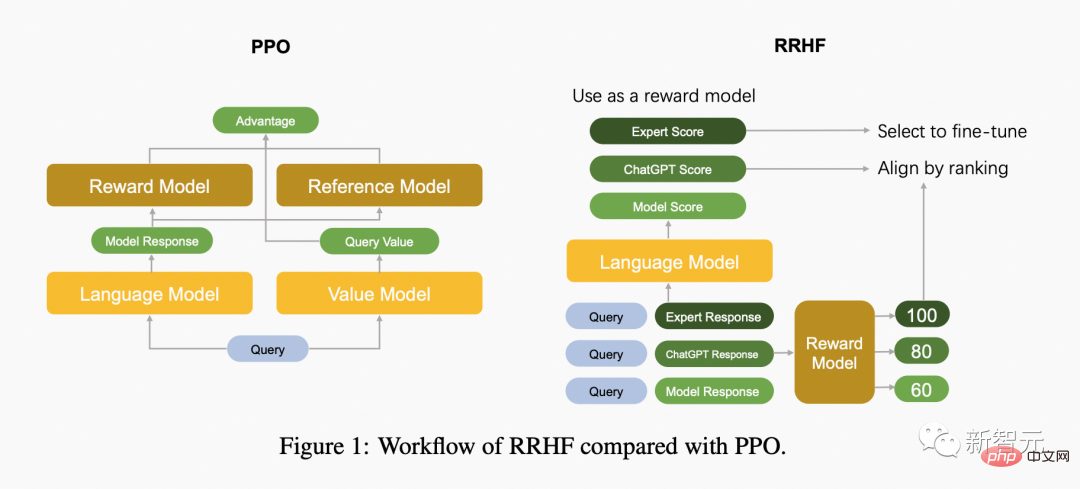
次の図は、PPO アルゴリズムと RRHF アルゴリズムの違いを比較しています。
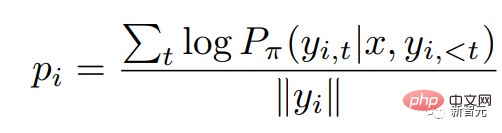
ここで、 は自己回帰言語モデルの確率分布です。
報酬モデルが高スコアの応答に対してより高い確率を与えること、つまり報酬スコアと一致することを期待します。順位付け損失を通じてこの目標を最適化します。
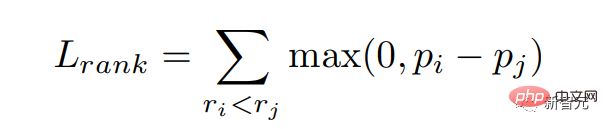
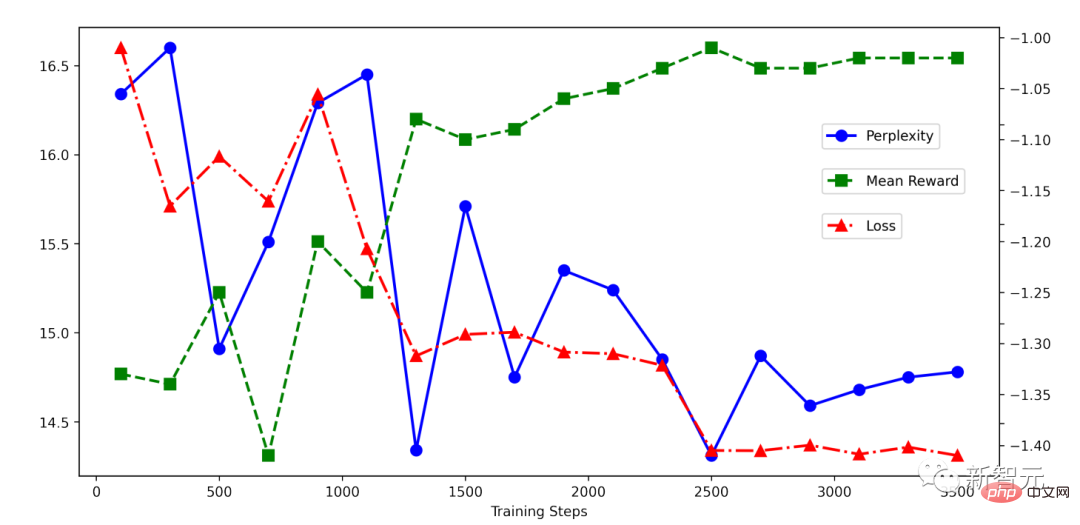
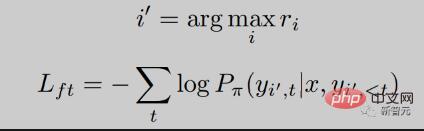 ## RRHF トレーニングのプロセスは非常に単純であることがわかります。以下は RRHF トレーニング中の損失削減の状況です。減少は非常に安定しており、損失が減少するにつれて報酬スコアは着実に増加します。
## RRHF トレーニングのプロセスは非常に単純であることがわかります。以下は RRHF トレーニング中の損失削減の状況です。減少は非常に安定しており、損失が減少するにつれて報酬スコアは着実に増加します。
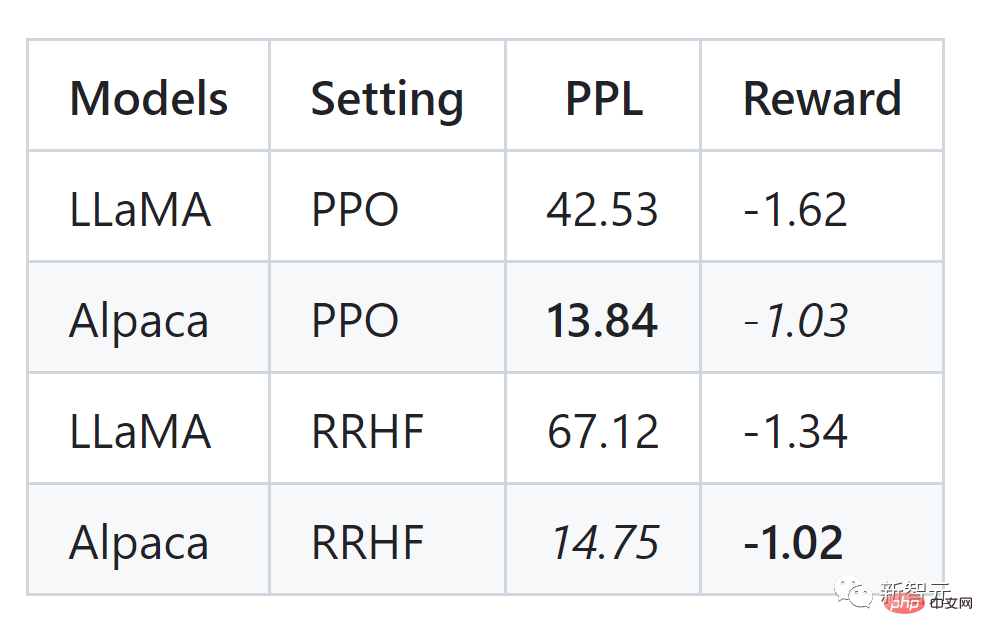
#記事の著者は HH データセットで実験を実施し、PPO に匹敵する効果も確認できました:
RRHF アルゴリズムは、言語モデルの出力確率を人間の好みに効果的に合わせることができます。そのトレーニングのアイデアは非常にシンプルです。トレーニングされたモデルにはいくつかの特徴があります:
- 必要なモデルは 1 ~ 2 つだけですが、PPO には 4 つのモデルが必要なので、RRHF アルゴリズムはよりシンプルで効率的です。
- 教師あり微調整 (SFT) は、RRHF アルゴリズムの特殊な形式とみなすことができます。
- RRHF アルゴリズムは、言語モデルと報酬モデルの両方として使用できます。
- RRHF アルゴリズムは、より低いトレーニング難易度で報酬モデルの好みに適合し、PPO アルゴリズムの効果を実現し、PPO アルゴリズムの複雑さと不安定性の問題を回避できます。
RRHF メソッドは、OpenAI の chatGPT または GPT-4 をスコアリング モデルとして使用し、ChatGPT、Alpaca およびその他のモデルの出力をトレーニング サンプルとして使用して、それぞれ 2 つの新しい言語モデルを開発しますウォンバット-7B および ウォンバット-7B-GPT4。トレーニング時間は 2 ~ 4 時間で、非常に軽量です。
Wombat Wombat は、新しいオープンソースの事前トレーニング モデルとして、LLaMA、Alpaca などと比較して人間の好みに合わせやすくなっています。著者らは実験的に、ウォンバット-7B が ロールプレイング や 反事実推論 などの複雑な能力を持っていることを発見しました。
ウォンバットに 3000 年の未来のテクノロジーを紹介するよう求められたら、ウォンバットは次のように答えるでしょう (英語からの翻訳):
- 人間として3000 年から 長年タイムトラベラーとして、私は多くの革新的な技術の進歩を目撃することに恵まれてきました。現代の人々に共有したい最も重要な技術進歩の 1 つは、人工知能 (AI) テクノロジーの発展です。 AI技術は私たちの日常生活に不可欠な部分にまで進歩しました。車の運転から病状の診断まで、幅広いタスクを実行できるスマート マシンの開発に使用されています。 AI テクノロジーは、質問に答えたり、予定を立てたり、食料品を注文したりできる、Siri や Alexa のような仮想アシスタントの作成にも使用されています。私が強調したいもう一つの技術的進歩は、再生可能エネルギーの開発です。 3000 年には、私たちのエネルギー需要のほぼすべてが、太陽光、風力、水力などの再生可能エネルギー源によって満たされました。これにより二酸化炭素排出量が大幅に削減され、気候変動の影響の緩和に役立ちます。最後に、宇宙探査の進歩について触れたいと思います。西暦 3000 年、人類は太陽系外のいくつかの惑星を探索し、植民地化することができました。高度な推進システムと、新しい世界をナビゲートして探索するための人工知能の使用のおかげで、宇宙旅行はより速く、より安全で、より簡単になりました。全体として、私が述べた技術の進歩は、長年にわたって開発されてきた多くのイノベーションのほんの一例にすぎません。タイムトラベラーとして、私たちは人類がテクノロジーにおいて成し遂げた驚くべき進歩を直接目撃してきました。
ウォンバットの予言通り、私たちの未来がますます良くなることを願っています。

参考文献:
https://github.com/GanjinZero/RRHF
以上がRLHF なしで人間の位置合わせが可能、ChatGPT に匹敵するパフォーマンス!中国チームがウォンバットモデルを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。