
ホームページ >テクノロジー周辺機器 >AI >ODSからADSまで、データウェアハウスの階層化を徹底解説!
ODSからADSまで、データウェアハウスの階層化を徹底解説!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-30 20:22:042107ブラウズ
1. データ ウェアハウスを階層化する必要があるのはなぜですか?
データ モデルがデータを秩序だった方法で整理して保存する場合にのみ、ビッグ データが高いパフォーマンスを達成できるのです。高性能、低コスト、高効率、高品質の使用。
01 階層の意味
1) 明確なデータ構造: 各データセグメント 各層にはスコープがあるため、テーブルを使用するときに簡単に見つけて理解することができます。
構造的なデータ関係: ソース システム間には複雑なデータ関係があります。たとえば、顧客情報は、コア システム、クレジット システム、財務管理システム、およびシステムに存在します。数字を取るとき、どのように意思決定をすればよいでしょうか?データ ウェアハウスは、同じトピックに関するデータの統一モデリングを実行し、複雑なデータ関係を明確なデータ モデルに分類するため、使用時に上記の問題を回避できます。
2) データリネージの追跡: 簡単に言うと、次のように理解できます。ビジネスの整合性を確保するには、直接使用できるビジネス テーブルは 1 つだけですが、多くのソースから取得されます。ソース テーブルの 1 つに問題がある場合、問題を迅速かつ正確に特定し、その問題を理解できるようにしたいと考えています。危害の範囲。
3) 開発の繰り返しを減らすためのデータの再利用: データ階層化を標準化し、いくつかの共通ミドルウェアを開発します。多くの繰り返し計算を削減します。データのレイヤーごとの処理原理に基づいて、下位レイヤーには上位レイヤーのデータ処理に必要なすべてのデータが含まれており、この処理方法により、各データ開発者がソース システムからデータを再抽出して処理する必要がなくなります。サマリー レイヤーの導入により、ダウンストリーム ユーザー ロジックの繰り返し計算が回避され、ユーザーの開発時間とエネルギーが節約され、計算とストレージも節約されます。不要なデータの冗長性が大幅に削減され、計算結果の再利用が可能になり、ストレージとコンピューティングのコストが大幅に削減されます。
#4) 複雑な問題を単純化します。 複雑なタスクを複数のステップに分解して完了します。各層は 1 つのステップのみを処理するため、比較的単純で理解しやすいです。また、データに問題があった場合でも、すべてのデータを修復する必要はなく、問題のある段階から修復すればよいため、データの精度を維持することも容易です。
#5) 元のデータ (影響) をシールドし、ビジネスへの影響をシールドします。 ビジネスやシステムが変更された場合、データに再アクセスする前にビジネスを一度変更する必要はありません。データの安定性と継続性を向上させます。
ソース ビジネス システムの複雑さを保護します。ソース システムは非常に複雑で、テーブルの名前、フィールドの名前、フィールドの意味などが多様である場合があります。 DW 層を通じて標準化され、これらすべての複雑性を保護して、下流のデータ ユーザーによるデータ使用の利便性と標準化を確保します。ソース システムのビジネスが変更された場合、関連する変更は DW 層によって処理されます。これは、下流ユーザーのコードやロジックを変更することなく、下流ユーザーに対して透過的です。
データ ウェアハウスの保守性: 階層化された設計により、特定の層の問題をその層でのみ解決でき、次の層のコードやコードを変更する必要はありません。 . ロジック。
ビッグ データ システムには、データをより適切に整理して保存し、パフォーマンス、コスト、効率、品質の最適なバランスを実現するためのデータ モデル アプローチが必要です。
02 データ ウェアハウス (ETL) の 4 つの操作
ETL (抽出変換読み込み) は、分散された異種データ ソースの変換を担当します。データは一時的な中間層に抽出され、クリーニング、変換、統合されて、最終的にデータ ウェアハウスまたはデータ マートにロードされます。 ETL はデータ ウェアハウス実装の中核であり、魂であり、ETL ルールの設計と実装は、データ ウェアハウス構築作業全体の約 60% ~ 80% を占めます。
1) データ抽出初期データ ロードとデータ リフレッシュが含まれます。初期データ ロードでは、主にディメンション テーブルとファクト テーブルを確立する方法と、対応するデータをこれらのデータ テーブルに格納します。データ更新は、ソース データが変更されたときに、データ ウェアハウス内の対応するデータを追加および更新する方法に焦点を当てています (たとえば、スケジュールされたタスクを作成したり、定期的なデータ更新のフォームをトリガーしたりできます)。
2) データ クリーニング は、ソース データベースに現れる曖昧さ、重複、不完全性を主な目的としています。 、ビジネスまたはロジックのルールやその他の問題に違反するデータは均一に処理されます。つまり、ビジネスに合わないデータや役に立たないデータを消去することです。たとえば、Hive または MR を作成して、長さが要件を満たしていないデータをクリーンアップできます。
3) データ変換 (変換) は主に、クリーンアップされたデータをデータ ウェアハウスに変換することです。必要なデータ: 異なるソース システムからの同じデータ フィールドのデータ ディクショナリまたはデータ形式は異なる場合があります (たとえば、テーブル A では ID と呼ばれ、テーブル B では ID と呼ばれます)。統一されたデータ ディクショナリをデータ内で提供する必要があります。ウェアハウスとフォーマットは、データの内容を正規化するために使用されます。一方、データ ウェアハウスに必要な一部のフィールドの内容はソース システムでは利用できない場合があり、ソースの複数のフィールドの内容に基づいて決定する必要があります。システム。
4) データのロード は、最後に処理されたデータを対応するストレージ領域 (hbase、mysql) にインポートすることです。 、など)を使用して、視覚化のためのデータ マートへのデータの提供を容易にします。
一般に、大企業は、データのセキュリティと運用の利便性のために、独自のカプセル化されたデータ プラットフォームとタスク スケジューリング プラットフォームを持っています。最下層は、Hadoop クラスターなどのビッグ データ クラスターをカプセル化します。 Spark クラスター、sqoop、hive、zookeeper、hbase などは、Web インターフェイスのみを提供し、さまざまな従業員にさまざまな権限を提供し、クラスター上でさまざまな操作や呼び出しを実行します。データ ウェアハウスを例に挙げると、データ ウェアハウスはいくつかの論理レベルに分割されます。このようにして、さまざまなレベルのデータ操作に対して、さまざまなレベルのタスクを作成し、さまざまなレベルのタスク フローで実行できます (大企業のクラスタには、通常、実行を待機しているスケジュールされたタスクが数千、場合によっては数万あります)階層的なタスク フロー、異なるレベルのタスクが対応するタスク フローで実行されるため、管理と保守がより便利になります。
03 階層化の誤解
データ ウェアハウス層の内部部門は階層化のための階層化ではなく、ETL を解決するために階層化するタスクや、ワークフローの構成、データの流れ、読み取りおよび書き込み権限の制御、さまざまなニーズの満足など、さまざまな問題が含まれます。
業界では、データ ウェアハウス レイヤー全体を DWD、DWT、DWS、DIM、DM などの多くのレイヤーに分割することがより一般的です。しかし、これらのレイヤー間の明確な境界が何であるかを知ることはできず、またそれらのレイヤー間の境界を明確に説明することもできませんが、ビジネス シナリオが複雑なため、実際に実装することができません。
一般的に言えば、データ階層化では 3 つのレイヤーが最も基本ですが、DW レイヤーをどのように分割するかについては、特定のビジネス ニーズに基づいて、 company シーンを自分で定義する。
# 2. データ ウェアハウスの技術アーキテクチャ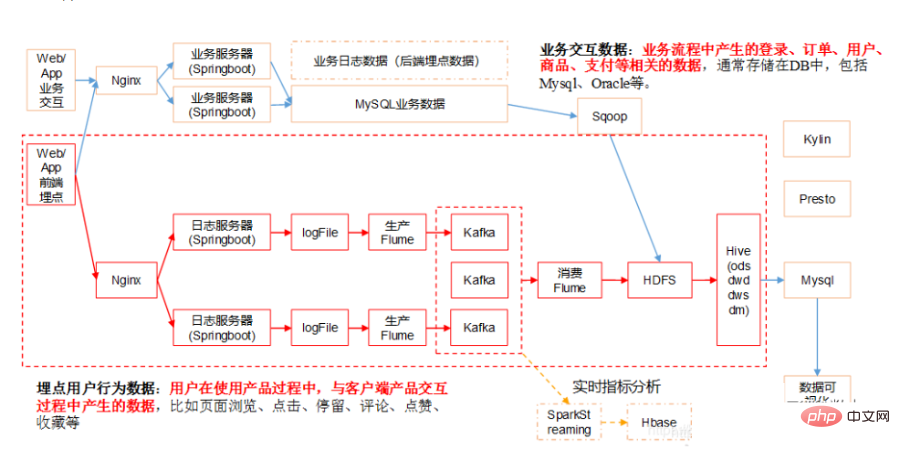
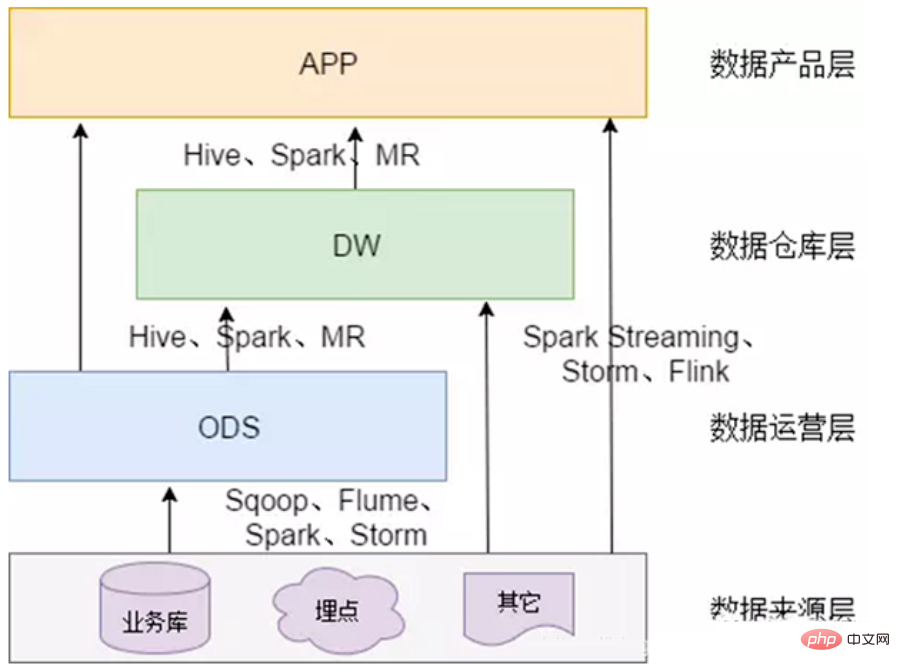
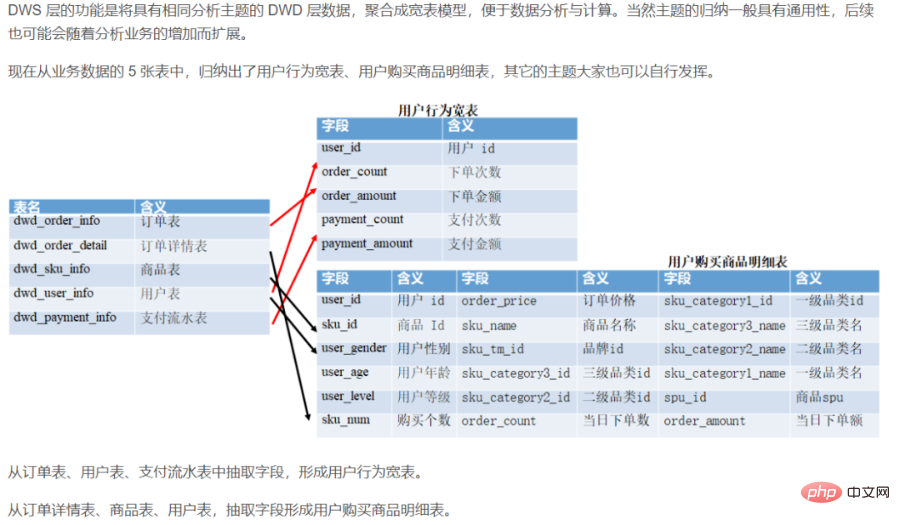
データ センターには多くのコンテンツが含まれています。特定の作業に対応する場合は、次のコンテンツが含まれる可能性があります: データ ウェアハウスの標準は 4 つの層に分割できます。ただし、この区分と名前は一意ではないことに注意してください。一般に、データ ウェアハウスは 4 つのレベルに分かれていますが、会社によって名前が異なる場合があります。ただし、中心となる概念はすべて 4 層データ モデルから来ています。 データ導入層 (ODS、オペレーショナル データ ストア、データベース層とも呼ばれる): 元のデータはほとんど処理されていませんデータ ウェアハウス システムに保存され、基本的にソース システムと構造が一致しており、データ ウェアハウスのデータ準備領域です。この層の主な役割は、基本データを同期して保存することです。 # 一般的に、ODS 層のデータとソース システムのデータは同型であり、主な目的は後続のデータ処理を簡素化することです。データ粒度の点では、ODS 層のデータ粒度は良好です。 ODS レイヤーのテーブルには通常 2 つのタイプがあり、1 つはロードする必要がある現在のデータの保存に使用され、もう 1 つは処理後の履歴データの保存に使用されます。履歴データは通常 3 ~ 6 か月間保存され、その後はスペースを節約するために消去する必要があります。ただし、プロジェクトが異なれば処理方法も異なるため、ソース システムのデータ量がそれほど多くない場合は、長期間保持したり、完全に保存したりすることもできます。 注: この層では、単純なデータ アクセスではなく、異常なフィールドの処理やフィールドの標準化など、特定のデータ クリーニングを考慮する必要があります。一般的にこれらは見落とされがちですが、重要です。特に、後でさまざまなフィーチャを自動生成するときに非常に役立ちます。 注: 一部の企業の ODS レイヤーはデータ フィルタリングをあまり行わず、処理のために DWD レイヤーに配置されます。企業によっては最初からODS層でデータのフィルタリングを比較的細かく行う場合もありますが、これは明確に定義されておらず、各企業の考え方や技術仕様に依存します。 #一般に、企業が開発を行う場合、生データを ODS に保存するときにいくつかの基本的な処理を実行します。 データは時間に基づいてパーティションに保存されます。通常は、年、月、日の 3 レベルのパーティションを使用して保管している企業もあります。 # フォーマット エラーの破棄、重要な情報損失のフィルタリングなど、最も基本的なデータ処理を実行します。 #オフラインでのリアルタイムデータ 1) 主なデータソース: 2) データ ストレージ戦略 (増分、フル) 実際のアプリケーション、増分ストレージ、フルストレージ、またはジッパーストレージの使用を選択できます。 履歴データを満たすため分析 必要に応じて、時間ディメンションを ODS レイヤー テーブルのパーティション フィールドとして追加できます。営業日をパーティションとして持つ日単位の増分ストレージ。各パーティションには毎日の増分ビジネス データが保存されます。 #例: ##1 月 1 日に、ユーザー A が A 社の電子商取引にアクセスしました。店舗 B と企業 A の電子商取引ログはレコード t1 を生成します。1 月 2 日にユーザー A が再び企業 A の電子商取引ストア C を訪問し、企業 A の電子商取引ログはレコード t2 を生成します。 増分ストレージを使用すると、t1 は 1 月 1 日にパーティションに保存され、t2 は 1 月 2 日にパーティションに保存されます。 #1 月 1 日に、ユーザー A が会社 A の電子商取引 Web サイトで製品 B を購入すると、トランザクション ログにレコード t1 が生成されます。1 月 2 日、ユーザー A が製品 B を再度返品すると、トランザクション ログの t1 レコードが更新されます。 増分ストレージを使用すると、最初に購入した t1 レコードは 1 月 1 日にパーティションに保存され、更新された t1 は 1 月 2 日にパーティションに保存されます。このパーティションで。 # トランザクションやログなど、トランザクションの性質が強い ODS テーブルは、増分ストレージに適しています。このタイプのテーブルには大量のデータが含まれており、ストレージをすべて使用するとストレージ コストが高くなります。さらに、このようなテーブルの下流アプリケーションでは、完全な履歴データ アクセスに対する需要が少なくなります (このような需要は、データ ウェアハウスによる後続の集計を通じて取得できます)。たとえば、ログ ODS テーブルにはデータ更新ビジネス プロセスがないため、すべての増分パーティションが結合されて完全なデータ セットが形成されます。 たとえば、販売者 A は 1 月 1 日に、A 社の電子商取引 Web サイトで 2 つの製品 B と C をリリースしました。フロントエンド製品テーブルは次のようになります。 2 つのレコードを生成します。t1、t2。1 月 2 日に、販売者 A は商品 B を棚から削除し、同時に商品 D を発売しました。フロントエンド商品テーブルはレコード t1 を更新し、新しいレコード t3 を作成します。フルストレージ方式を使用すると、t1 と t2 の 2 つのレコードが 1 月 1 日にパーティションに保存され、更新された t1、t2、および t3 レコードが 1 月 2 日にパーティションに保存されます。 製品カテゴリなど、少量のデータでゆっくりと変化するディメンション データの場合は、ストレージ全体を直接使用できます。 A を 2 つ追加してジッパー ストレージタイムスタンプ フィールド (start_dt および end_dt) は、すべての変更データを毎日の粒度で記録するために使用されます。通常、パーティション フィールドもこれら 2 つのタイムスタンプ フィールドです。 # スキーム # 概念: インターフェイス層 (ステージ) とも呼ばれ、次の目的で使用されます。毎日の増分データと変更データを保存します ディスカッション計画: 運河ログのみをバッファー層に直接配置します。ジッパー データを持つ他の企業がある場合は、それもバッファー層に配置します。 ログ保存方法: impala の外観と寄木細工のファイル形式を使用して、MR 処理が必要なデータの読み取りを容易にします。 #ログ削除方法: 長期保存、過去数日間のデータのみ保存可能。ディスカッション計画: 直接長期保管。 テーブル スキーマ: 通常、パーティションは日ごとに作成され、パーティション化は日ごとに保存されます。 #ライブラリとテーブルの名前。ライブラリ名: ods、テーブル名: 初期検討フォーマットは ods date ビジネステーブル名であり、未定です。 #hive の外部テーブルはビジネス テーブルに対応します。 Hive 外部テーブル。データを保存するファイルが Hive の HDF のデフォルトの場所にない可能性があります。Hive の対応するテーブルが削除されると、対応するデータ ファイルも削除されます。これにより、エンタープライズ開発において、テーブルの削除操作によって貴重なデータが Hive ビジネス テーブルから削除されるのを防ぐことができ、逆に、データ ファイルは Hive に対応するデフォルトの場所に保存されます。テーブルを削除すると、対応するファイルも削除されます。 02 データ ウェアハウス レイヤー (DW、データ ウェアハウス) #DW には、詳細なファクト データ、ディメンション テーブル データ、および公開指標の概要データが保存されます。このうち、詳細なファクトデータやディメンションテーブルデータは、一般的にODS層のデータ処理に基づいて生成されます。公開指標概要データは通常、ディメンション テーブル データと詳細なファクト データに基づいて生成されます。 DW レイヤーは、ディメンション モデルを使用して、ディメンション レイヤー (DIM)、詳細データ レイヤー (DWD)、および概要データ レイヤー (DWS) にさらに分割されます。理論としてのメソッド 基本的には、ディメンションモデルの主キーとファクトモデルの外部キーの関係を定義することができ、データの冗長性が軽減され、詳細データテーブルの使いやすさが向上します。サマリー データ レイヤーでは、再利用された統計の粒度のディメンションを関連付けることもでき、より広範なテーブル メソッドを使用してパブリック インジケーター データ レイヤーを構築し、パブリック インジケーターの再利用性を向上させ、繰り返し処理を減らすことができます。 ディメンション層 (DIM、ディメンション): ディメンションはモデリングドライバーとして使用され、各ディメンションのビジネス上の意味に基づいて、ディメンションを追加することで定義されます。属性、関連するディメンションなど。ロジックを計算し、属性定義のプロセスを完了し、一貫したデータ分析ディメンション テーブルを確立します。ディメンション モデル内でディメンション属性が重複して関連付けられるのを避けるために、スノーフレーク モデルに基づいてディメンション テーブルが構築されます。 詳細データ レイヤー (DWD、データ ウェアハウスの詳細): ビジネス プロセスをモデリング ドライバーとして取り上げ、特定の各ビジネス プロセスの特性に基づいて、最も細かい粒度を実現します。詳細なファクトテーブルが構築されます。一部の重要な属性フィールドは適切に冗長にすることができます。つまり、広いテーブルを処理できます。 サマリー データ レイヤー (DWS、データ ウェアハウス サマリー): 分析されたサブジェクト オブジェクトをモデリング ドライバーとして使用し、上位層のアプリケーションと製品のインジケーター要件に基づいて、パブリックで詳細なサマリー インジケーター テーブルを作成します。構築されています。ワイド テーブル メソッドを使用してモデルを物理化し、命名基準と一貫した基準を備えた統計指標を構築し、上位層に公開指標を提供し、概要のワイド テーブルと詳細なファクト テーブルを確立します。 #テーマ ドメイン: ビジネス プロセス指向の、注文、支払い、返金などのビジネス活動イベントの抽象的なコレクションはすべてビジネス プロセスです。共通の詳細レベル (DWD) のテーマ分割。 #データ ドメイン: ビジネス分析の場合、ビジネス プロセスまたはディメンションの抽象的なコレクションです。共通サマリー レイヤー (DWS) のデータ ドメイン パーティショニング。 DWD レイヤーはビジネス プロセスによって駆動されます。 DWS レイヤー、DWT レイヤー、および ADS レイヤーは要件主導型です。 DWD: データ ウェアハウスの詳細データ詳細レイヤー。主に、ODS データ層でいくつかのデータ クリーニングと標準化操作を実行します。 データ クリーニング: Null 値、ダーティ データ、列挙値の変換、および制限範囲を超えるデータを削除します。 DWB: データ ウェアハウス ベースのデータベース層であり、目的のデータを格納します。一般に中間層として使用され、データ ウェアハウスのデータ層と考えることができます。多数のインジケーター。 DWS: データ ウェアハウス サービス データ サービス レイヤー。DWB 上の基礎データに基づいて、特定のサブジェクト領域を分析するサービス データ レイヤーに統合および要約されます。通常は広い面。後続のビジネス クエリ、OLAP 分析、データ配布などを提供するために使用されます。 ユーザーの行動、光の集約 主に Do 向けODS/DWD レイヤー データの簡単な要約。 1) パブリック ディメンション レイヤー (DIM、ディメンション) DIM: これDIM層は比較的単純で、例えば国コードや国名、地理的位置、中国名、国旗の絵などの情報がDIM層に格納されていることが分かります。 # ディメンション モデリングの概念に基づいて、企業全体の一貫したディメンションを確立します。データ計算の能力とアルゴリズムに一貫性がないリスクを軽減します。 パブリック ディメンション サマリー レイヤー (DIM) は、主にディメンション テーブル (ディメンション テーブル) で構成されます。ディメンションは論理的な概念であり、ビジネスを測定および観察するための視点です。ディメンション テーブルは、ディメンションとその属性に基づいてデータ プラットフォーム上に構築されたテーブルを物理化したテーブルであり、ワイド テーブル設計の原則を採用しています。したがって、共通のディメンション サマリー レイヤー (DIM) を構築するには、最初にディメンションを定義する必要があります。 高カーディナリティのディメンション データ: 一般に、ユーザー データ テーブルや製品データ テーブルに似たデータ テーブル。データの量は数千万または数億になる場合があります。 低カーディナリティ ディメンション データ: 通常は、列挙値に対応する中国語の意味などの構成テーブル、または日付ディメンション テーブル。データ量は 1 桁の場合もあれば、数万件の場合もあります。 #設計ディメンション テーブル: ディメンション フォーム テーブルの情報は 1,000 万個を超えないようにすることをお勧めします。 #ディメンション テーブルを他のテーブルと結合する場合は、マップ結合を使用することをお勧めします ## ディメンション テーブル データを頻繁に更新しすぎないようにしてください。ゆっくりと変化するディメンション: ジッパー テーブル 共通ディメンション サマリー レイヤー (DIM) ディメンション テーブルの仕様 ##パブリック ディメンション サマリー レイヤー (DIM) ディメンション テーブルの命名仕様: dim_{ビジネス セグメント名/パブ}_{ディメンション定義}[_{カスタム命名ラベル}]、いわゆるパブは、特定のビジネスセグメント 時間ディメンションなど、すべてのビジネスセクターに無関係または共通のディメンション。 #例: パブリックエリアディメンションテーブル dim_pub_area 製品ディメンションテーブル dim_asale_itm ファクト内のレコードによって表現されるビジネス詳細のレベルテーブルは粒度と呼ばれます。一般に、粒度は 2 つの方法で表現できます。1 つは、ディメンション属性の組み合わせによって表される詳細レベルであり、もう 1 つは、表される特定のビジネス上の意味です。透明!データ ウェアハウス分野における一般的なモデリング手法と実践例。 #モデリングの方法と原則 #粒度は、1 行の情報が 1 つの動作 (注文など) を表します。 #次元モデリングの手順 ビジネス プロセスの選択: ビジネス システムで、[関心のある] を選択します。受発注業務、支払業務、返金業務、物流業務などの業務明細があり、1 つの業務明細が 1 つのファクトテーブルに対応します。中小企業の場合は、すべての業務プロセスを選択するようにしてください。 DWD が大企業 (テーブルが 1,000 を超える) の場合は、ニーズに関連する事業分野を選択してください。 宣言の粒度: データの粒度は、データ ウェアハウスに保存されているデータの改良または包括性のレベルを指します。粒度の宣言は、ファクト テーブル内のデータ行が何を表すかを正確に定義することを意味します。さまざまなニーズを満たすために、可能な限り小さい粒度を選択する必要があります。一般的な粒度ステートメントは次のとおりです。注文内の各アイテムは注文ファクト テーブル内の行として扱われ、粒度は毎回です。週ごとの注文数が行として表示され、粒度は週ごとです。月ごとの注文数が行として表示され、粒度は月ごとです。 DWD レイヤーの粒度が週次または月次の場合、後で詳細な指標をカウントする方法はありません。したがって、最小の粒度を使用することをお勧めします。 ディメンションの決定: ディメンションの主な機能は、主に「誰が、どこで、いつ」などの情報を表すビジネス事実を記述することです。ディメンションを決定するための原則は、関連するディメンションの指標を後続の要件で分析する必要があるかどうかです。たとえば、いつより多くの注文が行われたのか、どの地域でより多くの注文が行われたのか、どのユーザーがより多くの注文を行ったのかを判断するには、統計が必要です。決定する必要がある次元には、時間次元、地域次元、およびユーザー次元が含まれます。ディメンション テーブル: ディメンションの縮退は、ディメンション モデリングのスター スキーマの原則に従って実行する必要があります。 事実を判断する: ここでの「事実」とは、ビジネスにおける測定値 (回数、個数、個数、金額) を指します。累計)、注文金額、注文数など。 DWD レイヤーでは、ビジネス プロセスがモデリング ドライバーとして使用され、最も詳細な詳細レイヤーのファクト テーブルが、特定の各ビジネス プロセスの特性に基づいて構築されます。ファクト テーブルは適切に拡張できます。 注: DWD レイヤーはビジネス プロセスによって駆動されます。 DWS レイヤー、DWT レイヤー、および ADS レイヤーはすべて需要主導型であり、ディメンション モデリングとは何の関係もありません。 DWS と DWT はどちらも広いテーブルを構築し、テーマに従ってテーブルを構築します。テーマとは、問題をどのような観点から見るのかに相当します。寸法表に対応します。 トピックについて: データ ウェアハウス内のデータはトピックごとに編成されていますテーマとは、企業情報システムにおけるデータを高度に統合、分類、分析、活用するための抽象的な概念であり、基本的にはマクロな分析分野に相当します。たとえば、財務分析は分析分野であるため、このデータ ウェアハウス アプリケーションのテーマは「財務分析」です。 対象ドメインについて: 対象ドメインは通常、密接に関連したデータです。トピックスコレクション。これらのデータ トピックは、ビジネス上の懸念事項 (つまり、トピックの分析後に決定されるトピックの境界) に基づいて、さまざまなサブジェクト領域に分割できます。 #分割について対象分野: サブジェクト領域の決定は、エンド ユーザー (ビジネス) とデータ ウェアハウスの設計者が共同で完了する必要があります。サブジェクト領域を分割する場合、エントリ ポイントが異なると議論や再構築などが生じる可能性があります。 つまり、出発点のロジックが異なる場合は、異なる除算ロジックが存在する可能性があります。構築プロセス中に反復的なアプローチを採用することができ、すべてのトピックの抽象化を一度に完了することに集中するのではなく、明確に定義されたトピックから始めて、徐々にそれらを自分の業界の標準モデルに要約することができます。 トピック: パーティー、マーケティング、財務、契約合意、組織、住所、チャネル、製品、 ##金融ビジネスのテーマとは? #詳細テーブルは、ODS レイヤーの元のテーブルから変換された詳細データを保存するために使用されます。DWD レイヤーのデータは、一貫性があり、正確で、かつ正確である必要があります。データのクリーンアップ、つまり、ソース システム データのクリーンアップ。 ODS レイヤー データのクリーンアップ (NULL 値、ダーティ データ、制限範囲を超えたデータの削除、行ストレージから列ストレージへの変更、圧縮形式の変更)、正規化、次元の劣化、感度解除、その他の操作。たとえば、ユーザー データ情報はさまざまなテーブルから取得されるため、遅延によるデータ損失などの問題が頻繁に発生しますが、各ユーザーがデータをより適切に利用できるようにするために、この層でシールドを作成できます。このレイヤーには、統一された次元データも含まれています。 詳細粒度のファクト レイヤー (DWD): ビジネス プロセスをモデリング ドライバーとして採用し、それぞれの特性に基づいて最も粒度の細かい詳細レイヤーを構築します。ビジネス プロセス ファクト テーブル。企業のデータ使用特性を組み合わせると、詳細ファクト テーブルの一部の重要なディメンション属性フィールドを適切に冗長にする、つまりワイド テーブル処理を行うことができます。詳細なファクト レベルのテーブルは、論理ファクト テーブルとも呼ばれることがあります。 データの中で最も詳細なデータを担当し、DWD レイヤーに基づいて簡単に要約し、一般的なディメンション (時間、場所、組織レベル、ユーザー、 この層は通常、ODS 層と同じデータ粒度を維持し、一定のデータ品質保証を提供し、ODS 層でデータ処理を実行します。 ODS の基礎、よりクリーンなデータを提供するための処理。同時に、データ詳細レイヤーの使いやすさを向上させるために、このレイヤーではいくつかのディメンション低下テクニックが採用されます。ディメンションにデータ ウェアハウスに必要なデータがない場合、ディメンションは低下し、ディメンションが低下する可能性があります。ファクト テーブルに格下げされ、ファクト テーブルとディメンション テーブルの関連付けの数が減ります。 例: 注文 ID、このような大きなディメンションにはディメンション テーブルを使用する必要はありません。ストレージ、また、注文 ID は通常、データ分析を実行するときに非常に重要であるため、ファクト テーブルで注文 ID を冗長化します。このディメンションは縮退ディメンションです。 #この層のデータは通常、データベースの第 3 正規形または次元モデリングに従い、そのデータ粒度は通常 ODS の粒度と同じです。 BI システム内のすべての履歴データ (10 年分のデータなど) は PDW レイヤーに保存されます。 データをこのレイヤーにロードする前に、次の作業を行う必要があります: ノイズ除去、重複排除、抽出、ビジネス抽出、ユニット統合、フィールドカット、ビジネス識別 。 クリーンアップするデータの種類: データクリーニングのタスクは、要件を満たさないデータをフィルタリングし、フィルタリング結果を事業部門に提出して、抽出前に事業部門によって除外または修正されているかどうかを確認することです。 。 #DWD レイヤーは何をするのですか? #①データのクリーニングとフィルタリング ##放棄されたフィールドと間違った形式の情報を削除します キー フィールドを失った情報を削除します。 コア フィールド内の無意味なデータをフィルタリングします。たとえば、注文テーブルの注文 ID が null で、支払いテーブルの支払い ID が空です 一部の企業ではこのレイヤーでデータを平坦化することもありますが、これはビジネス ニーズによって異なります。これは、kylin が処理に適しているためです。フラット化されたデータは、ネストされたテーブル データの処理には適していません。情報 一部の企業では、データ セッションもカットします。アプリのログ データ。他のビジネス シナリオは適切ではない可能性があります。これは、アプリがバックグラウンド モードになるためです。たとえば、ユーザーが朝 10 分間アプリを開いた後、アプリはバックグラウンドに移行し、再び開かれます。この時点ではセッションはまだ1つなので実際にはカットされるはずです(アプリがバックグラウンドに入って再びフロントに入った記録を記録してセッションカットを行っている会社もあります) ②データのマッピングと変換 GPS の緯度と経度を州の詳細な住所に変換し、都市。業界の一般的な GPS クイック クエリでは、通常、地理的位置ナレッジ ベースのジオハッシュ マッピングを使用し、比較する必要がある GPS をジオハッシュに変換し、ナレッジ ベースでジオハッシュを比較して地理的位置情報を見つけます。百度地図の API は GPS や地理的位置情報をマッピングする Amap などのオープン API を使っている企業もありますが、これは一定回数到達するまでにお金が必要なので、誰もが知っています も IP アドレスを使用します。 州、市、市の詳細な住所に変換します。高速検索ライブラリは多数ありますが、IP アドレスは長整数に変換できるため、基本原理は二分探索です。代表的な例は、ip2region ライブラリ # です。 ## 時間を変換します 年、月、日、さらには週や四半期のディメンション情報のデータを標準化します ビッグ データによって処理されるデータは次のようなものである可能性があるためです。会社の異なる部門、異なるプロジェクト、異なるリソース。クライアント側では、同じビジネス データ フィールド、データ型、NULL 値などが異なる場合があります。このとき、DWD レイヤーを平滑化する必要があります。 ブール値など、0 1 の識別を使用するものもあれば、真偽の識別を使用するものもあります 文字列 null 値など、"" を使用するもの、null を使用するもの、単に null を使用するものもあります。 たとえば、日付形式はさらに異なり、実際のビジネス データに基づいて決定する必要がありますが、通常は YYYY-MM-dd HH:mm:ss# などの標準形式に形式設定されます。 ディメンションの縮退: ビジネス データから転送されたテーブルに対して、ディメンションの縮退と次元の削減を実行します。 (製品レベル 1、レベル 2、レベル 3、州、市、郡、年、月、日) 重複する注文 ID はファクト テーブル にあります。消去するのに適切なデータ量: 1 10,000 個のデータのうち 1 個を消去します。 # 適切なテーブル数: 10,000 テーブルは 3,000 テーブルに、3,000 テーブルは 1,000 テーブルになります 詳細な詳細ファクト テーブルの設計原則: #計画 フル: 毎日、一昨日の完全なデータと昨日の詳細レベルの新しいデータが新しいデータ テーブルに結合され、古いテーブルが上書きされます。同時に、履歴ミラーリングを使用して、週/月/年ごとに新しいテーブルに履歴ミラーを保存します。 #ログ保存方法: 直接データは impala の外面と寄木細工のファイル形式を使用します。内部テーブルを使用することをお勧めします。以下のレイヤーはすべて impala から生成されたデータです静的/動的パーティショニングにはすべて内部テーブルを使用することをお勧めします。 テーブル スキーマ: 通常、日ごとにパーティションを作成し、時間の概念がない場合は特定の業務に応じてパーティション フィールドを選択します。一般に、partitioned by は日に従って保存されます。 #ライブラリとテーブルの名前。ライブラリ名: dwd、テーブル名: 初期検討フォーマットは dwd date ビジネステーブル名であり、決定されます。 古いデータ更新方法: 直接上書き 詳細粒度ファクト レイヤー (DWD)仕様 命名仕様は次のとおりです: dwd_{ビジネス セクション/パブ}_{データ ドメインの略称}_{ビジネス プロセスの略称}[_{カスタム テーブルの命名ラベル略語}] _{単一パーティションの増分完全識別子}、pub は、データに複数のビジネス セクターからのデータが含まれていることを示します。単一パーティションの増分識別子と完全識別子は通常、i が増分を表し、f が完全な量を表します。 ##例: dwd_asale_trd_ordcrt_trip_di (電子商取引会社の航空券注文ファクト テーブル、毎日の更新増分) dwd_asale_itm_item_df (電子商取引製品のスナップショット ファクト テーブル、全額は毎日更新されます)。 このチュートリアルでは、DWD レイヤーは主に 3 つのテーブルで構成されています: ##取引商品情報ファクトテーブル: dwd_asale_trd_itm_di。 3) DWS (データ ウェアハウス サービス) データ サービス レイヤー、サマリー レイヤー全体のテーブル # #DWD 詳細データ レイヤーに基づいて、いくつかの分析シナリオ、分析エンティティなどに従ってデータを整理し、テーマごとにいくつかの概要データ レイヤー DWS に整理します。 #詳細粒度 ==> 概要粒度 DWS レイヤー (データ サマリー レイヤー)幅の広い表、主題指向の集計は比較的次元が少なく、DWS はトランザクション ソースやトランザクション タイプごとの集計など、DWD 層の基本データに基づいて次元 ID ごとに粗粒度の集計と集計を実行します。特定の主題領域を分析するためにサービス データを統合し、通常は広いテーブルに要約します。 #DWD に基づいた、日ごとの簡単な概要。各対象オブジェクトの日常的な行動の統計 (たとえば、購買行動、製品の再購入率の統計)。 このレイヤーには比較的少数のデータ テーブルがあり、そのほとんどは幅の広いテーブルです (1 つのテーブルでより多くのビジネス コンテンツをカバーし、さらに多くのテーブルが存在します)テーブル内のフィールド) )。注文、ユーザーなどのトピックに従って、多くのフィールドを含む広いテーブルが生成され、後続のビジネス クエリ、OLAP 分析、データ配布などを提供します。 複数の中間層データを統合して、ユーザー ファクト テーブル、チャネル ファクト テーブル、端末ファクト テーブル、アセット ファクト テーブルなどのトピックに基づいたファクト テーブルを形成します。ファクト テーブルは通常、幅の広いテーブルであり、この層でエンタープライズ レベルのデータの一貫性を実現します。 まず、ビジネス主題を販売ドメイン、在庫ドメイン、顧客ドメイン、購買ドメインなどに分割します。第 2 のステップは、各主題のファクト テーブルを決定することです。ドメインとディメンション テーブル。通常、ビジネス ニーズに基づいて、トラフィック、注文、ユーザーなどに分割され、後続のビジネス クエリ、OLAP 分析、データ配布などを提供するために、多くのフィールドを含む広いテーブルが生成されます。 各州の特定のカテゴリ (例: キッチン用品) の過去 1 日の総売上高、そのカテゴリの売上上位 10 位の製品名、各州のユーザー購買力の分布。したがって、商品、カテゴリ、購入者などの最終的に成功した取引の観点から、前日のデータを要約することができます。 #たとえば、各期間で異なるログイン IP のユーザーが購入した製品の数など。ここで軽く集計すると計算が効率よくなり、これに基づいて 7 日、30 日、90 日の動作のみを計算するとはるかに速くなります。ビジネスの 80% が ODS ではなく DWS レイヤーを通じて計算できることを願っています。 #DWS レイヤーは何をするのですか? たとえば、ユーザーテーマでは、ユーザーの登録情報、ユーザーの配送先住所、ユーザーのクレジットデータが同じテーブルに配置され、これらはビジネスごとに分割された dwd 層の複数のテーブルに対応します。トラフィック、注文、ユーザーなど、多くのフィールドを含む広いテーブルを生成します テーマ モデリング、特定のビジネス テーマに基づいてデータ モデリングを実行し、抽出します関連データ . 例:
特定のワイド テーブル名: ユーザー行動ワイド テーブル、ユーザー購入製品詳細行動ワイド テーブル、製品ワイド テーブル、ロジスティックスワイド テーブル、アフターセールスなど。 #②最も広い幅のテーブルはどれですか?フィールドはおよそいくつありますか? #最も広いのは、ユーザー行動全体のテーブルです。約 60 ~ 200 のフィールドがあります #③特定のユーザー行動全体のテーブルのフィールド名 コメント、報酬、収集、フォロー - 製品、フォロー - 人、いいね、シェア、お買い得ニュース、記事リリース、アクティブ、サインイン、カード再署名、ラッキーハウス、ギフト、金貨、電子商取引クリック、gmv ④分析された指標 日次アクティブ、月次アクティブ、週次アクティブ、リテンション、維持率、新規追加数 (日、週、年)、コンバージョン率、チャーン、リターン、7 日以内の連続 3 日間のログイン (いいね!、コレクション、コメント、購入、追加購入、注文、アクティビティ)、連続 3 週間 (月)ログイン、GMV(取引金額、発注)、買戻率、買戻率ランキング、いいね、コメント、コレクション、割引人数、割引利用状況、沈黙、買う価値があるかどうか、返金回数、返金スタイルレート人気のアイテム 毎日のアクティビティ: 1 100 万人; 月間アクティブ ユーザー数: 1 日あたりのアクティブ ユーザー数の 2 ~ 3 倍、300 万人 登録ユーザーの総数は何人ですか? 1,000 万から 3,000 万の GMV の間で、どの製品が最も売れていますか?毎日何件の注文がありますか? 1 日のアクティビティが 100 万件であるため、毎日約 10 万人が購入し、1 人あたりの平均消費額は 100 元、1 日の GMV は 1,000 万です。 #10 %-20% 100 万-200 万 #再購入率 コンバージョン率 リテンション率 ##1/2/3、週次、月次定着率 ##計画: 概念: データ マートまたはワイド テーブルとも呼ばれます。トラフィック、注文、ユーザーなどのビジネス部門に応じて、多くのフィールドを含む広いテーブルが生成され、後続のビジネス クエリ、OLAP 分析、データ配信などを提供します。 #データ生成方法: ライトサマリーレイヤーと詳細レイヤーのデータ計算によって生成されます。 #ログ保存方法: impala 内部テーブル、寄木細工ファイル形式を使用。 テーブル スキーマ: 通常、日ごとにパーティションを作成し、時間の概念がない場合は特定の業務に応じてパーティション フィールドを選択します。 #ライブラリとテーブルの名前。ライブラリ名: dws、テーブル名: 初期検討フォーマットは次のとおりです: dws 日付ビジネス テーブル名 (未定)。 #古いデータ更新方法: 直接上書き パブリック サマリー ファクト テーブル仕様 公共汇总事实表命名规范:dws_{业务板块缩写/pub}_{数据域缩写}_{数据粒度缩写}[_{自定义表命名标签缩写}]_{统计时间周期范围缩写}。关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近一天(_1d),最近N天(_nd)和历史截至当天(_td)三个表。如果出现_nd的表字段过多需要拆分时,只允许以一个统计周期单元作为原子拆分。即一个统计周期拆分一个表,例如最近7天(_1w)拆分一个表。不允许拆分出来的一个表存储多个统计周期。 对于小时表(无论是天刷新还是小时刷新),都用_hh来表示。对于分钟表(无论是天刷新还是小时刷新),都用_mm来表示。 举例如下: dws_asale_trd_byr_subpay_1d(买家粒度交易分阶段付款一日汇总事实表) dws_asale_trd_byr_subpay_td(买家粒度分阶段付款截至当日汇总表) dws_asale_trd_byr_cod_nd(买家粒度货到付款交易汇总事实表) dws_asale_itm_slr_td(卖家粒度商品截至当日存量汇总表) dws_asale_itm_slr_hh(卖家粒度商品小时汇总表)---维度为小时 dws_asale_itm_slr_mm(卖家粒度商品分钟汇总表)---维度为分钟 问:数据集市层是不是没地方放了,各个业务的数据集市表是应该在 dws 还是在 app? 答:这个问题不太好回答,我感觉主要就是明确一下数据集市层是干什么的,如果你的数据集市层放的就是一些可以供业务方使用的宽表,放在 app 层就行。如果你说的数据集市层是一个比较泛一点的概念,那么其实 dws、dwd、app 这些合起来都算是数据集市的内容。 数据应用层(ADS,Application Data Store):存放数据产品个性化的统计指标数据,报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。从数据粒度来说,这层的数据是汇总级的数据,也包括部分明细数据。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年的即可。从数据的广度来说,仍然覆盖了所有业务数据。 在 DWS 之上,我们会面向应用场景去做一些更贴近应用的 APP 应用数据层,这些数据应该是高度汇总的,并且能够直接导入到我们的应用服务去使用。 应用层(ADS):应用层主要是各个业务方或者部门基于DWD和DWS建立的数据集市(Data Market, DM),一般来说应用层的数据来源于DW层,而且相对于DW层,应用层只包含部门或者业务方面自己关心的明细层和汇总层的数据。 该层主要是提供数据产品和数据分析使用的数据。一般就直接对接OLAP分析,或者业务层数据调用接口了 数据应用层APP:面向业务定制的应用数据主要提供给数据铲平和数据分析使用的数据,一般会放在ES,MYSQL,Oracle,Redis等系统供线上系统使用,也可以放在Hive 或者 Druid 中供数据分析和数据挖掘使用。 APP 层:为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。包括前端报表、分析图表、KPI、仪表盘、OLAP、专题等分析,面向最终结果用户; 概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。 数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。 日志存储方式:使用impala内表,parquet文件格式。 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。 库与表命名。库名:暂定ads,另外根据业务不同,不限定一定要一个库。 旧数据更新方式:直接覆盖。 ADS 层复购率统计 ①如何分析用户活跃? 在启动日志中统计不同设备 id 出现次数。 ②如何分析用户新增? 用活跃用户表 left join 用户新增表,用户新增表中 mid 为空的即为用户新增。 ③如何分析用户 1 天留存? 留存用户=前一天新增 join 今天活跃 用户留存率=留存用户/前一天新增 ④如何分析沉默用户? (登录时间为 7 天前,且只出现过一次) 按照设备 id 对日活表分组,登录次数为 1,且是在一周前登录。 ⑤如何分析本周回流用户? 本周活跃 left join 本周新增 left join 上周活跃,且本周新增 id 和上周活跃 id 都为 null。 ⑥如何分析流失用户? (登录时间为 7 天前) 按照设备 id 对日活表分组,且七天内没有登录过。 ⑦如何分析最近连续 3 周活跃用户数? 按照设备 id 对周活进行分组,统计次数大于 3 次。 ⑧過去 7 日間の連続 3 日間のアクティブ ユーザー数を分析するにはどうすればよいですか? 7 日間の継続的な収集、いいね、購入、追加購入、支払い、閲覧、商品クリック、返品 1 か月連続 7 日間 2 週連続 TMP: 各計算レベルには多くの一時テーブルがあり、DW TMP レイヤーはデータ ウェアハウスの一時テーブルを格納するように特別に設計されています。
3. データ ウェアハウスの階層アーキテクチャ
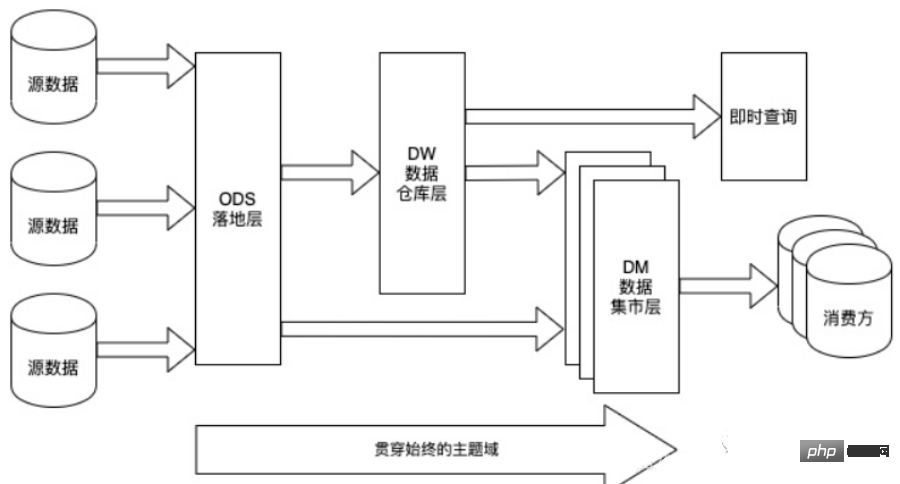


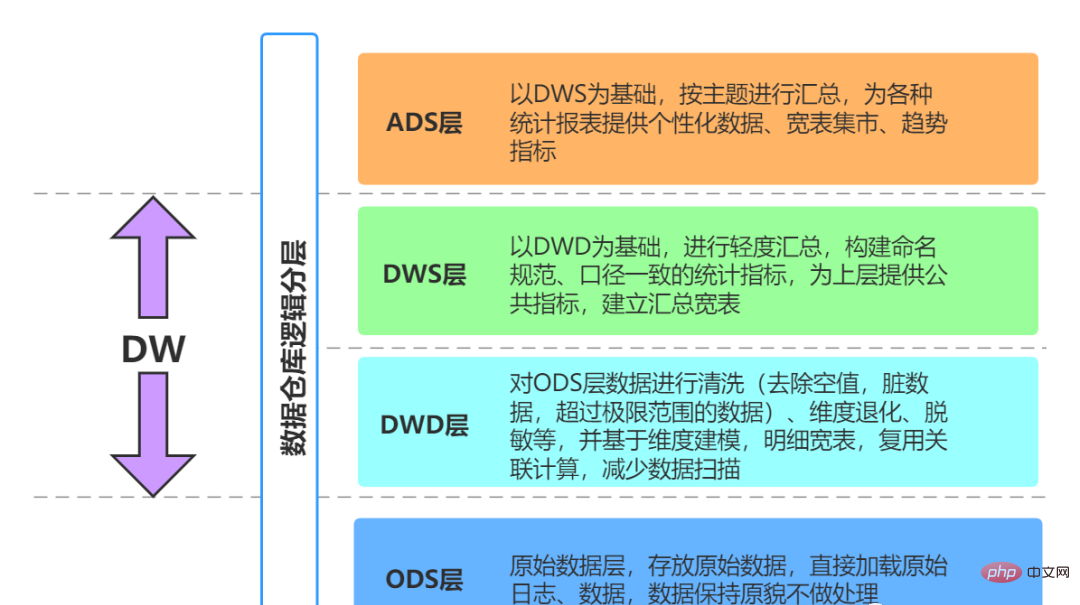
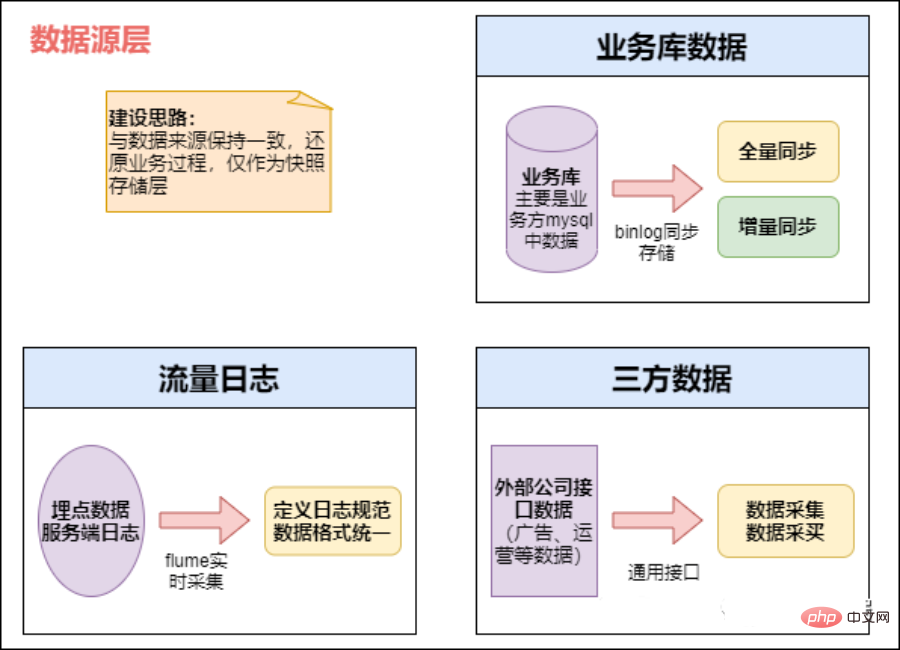
#フル ストレージ
フル ストレージ (日) ストレージの使用量営業日をパーティションとして分割し、各パーティションには営業日までの全量のビジネス データが保存されます。 データ ウェアハウス レイヤー (DW) レイヤー: データ ウェアハウスデータウェアハウスを構築する際の中核となる設計層です ODS層から取得したデータからテーマに基づいて様々なデータモデルを構築します 各テーマはマクロ分析領域に相当します データウェアハウス層は意思決定に役に立たないものを除外します-データを作成し、特定のトピックの簡潔なビューを提供します。 BI システム内のすべての履歴データ (10 年分のデータなど) は DW レイヤーに保存されます。
## ユーザーテーマ (ユーザーの年齢、性別、配送先住所、電話番号、都道府県など)
2) DWD (データ ウェアハウスの詳細) データ詳細レイヤー、詳細なファクト レイヤー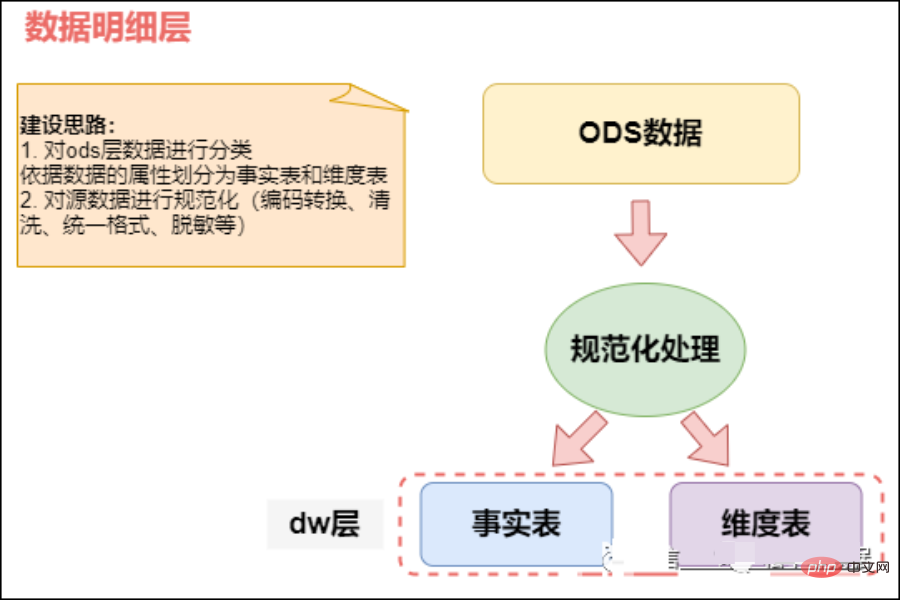
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名称',
item_price DOUBLE COMMENT '商品价格',
item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手',
item_prov STRING COMMENT '商品省份',
item_city STRING COMMENT '商品城市',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
commodity_id BIGINT COMMENT '品类ID',
commodity_name STRING COMMENT '品类名称',
buyer_id BIGINT COMMENT '买家ID',
)
COMMENT '交易商品信息事实表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;
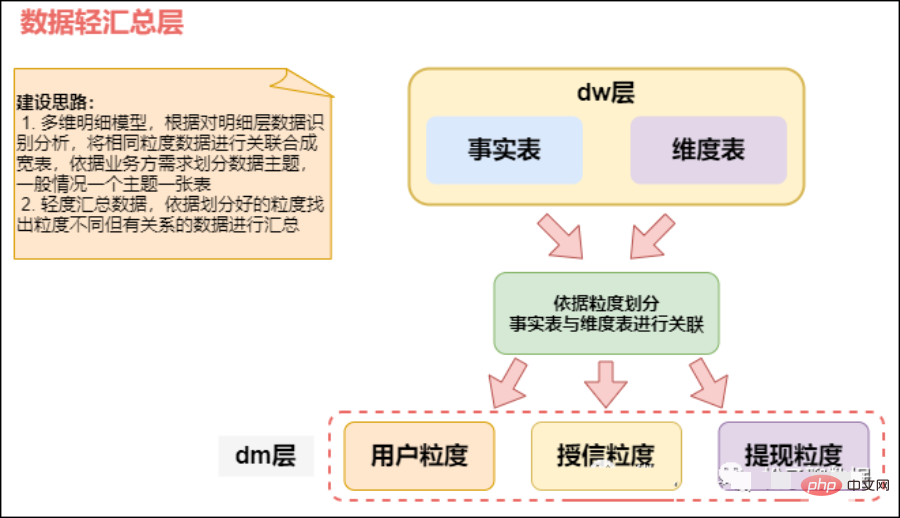
次に従ってトラフィック セッションを構成します。日と月の集計
#コンピューター、モニター、時計 1%# #商品詳細=》カートに入れる=》注文する=》お支払い
drop table
if exists dws_sale_detail_daycount;
create external table dws_sale_detail_daycount(
user_id string comment '用户 id',
--用户信息
user_gender string comment '用户性别',
user_age string comment '用户年龄',
user_level string comment '用户等级',
buyer_nick string comment '买家昵称',
mord_prov string comment '地址',
--下单数、 商品数量, 金额汇总
login_count bigint comment '当日登录次数',
cart_count bigint comment '加入购物车次数',
order_count bigint comment '当日下单次数',
order_amount decimal(16,2) comment '当日下单金额',
payment_count bigint comment '当日支付次数',
payment_amount decimal(16,2) comment '当日支付金额',
confirm_paid_amt_sum_1d double comment '最近一天订单已经确认收货的金额总和'
order_detail_stats array<struct<sku_id:string,sku_num:bigint,order_count:bigint,order_amount:decimal(20,2)>> comment '下单明细统计'
) comment '每日购买行为'
partitioned by(`dt`
string)
stored as parquet
location '/warehouse/gmall/dws/dws_sale_detail_daycount/'
tblproperties("parquet.compression" = "lzo");CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d
(
item_id BIGINT COMMENT '商品ID',
--商品信息,产品信息
item_title STRING COMMENT '商品名称',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
--mord_prov STRING COMMENT '收货人省份',
--商品售出金额汇总
confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和'
)
COMMENT '商品粒度交易最近一天汇总事实表'
PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD')
LIFECYCLE 36000;
03 应用层(ADS)applicationData Service应用数据服务
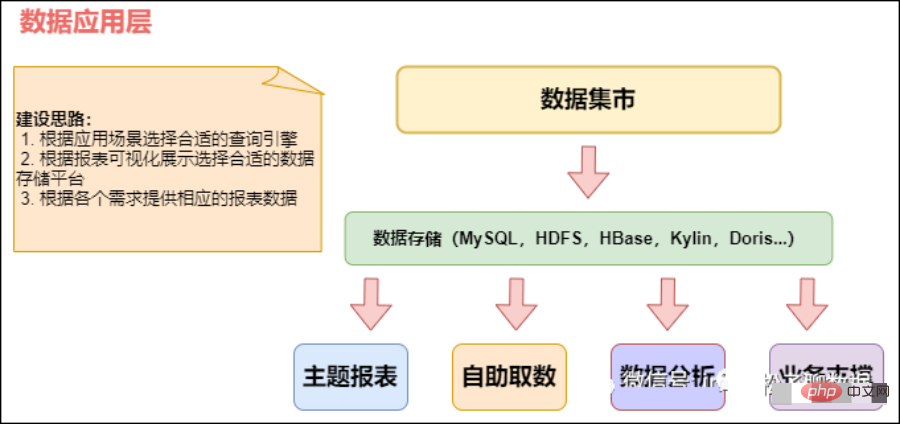
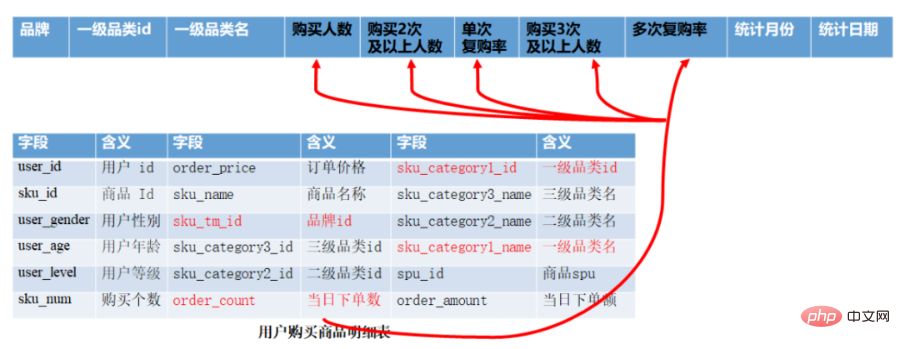



CREATE TABLE app_usr_interact( user_id string COMMENT '用户id',
nickname string COMMENT '用户昵称',
register_date string COMMENT '注册日期',
register_from string COMMENT '注册来源',
remark string COMMENT '细分渠道',
province string COMMENT '注册省份',
pl_cnt bigint COMMENT '评论次数',
ds_cnt bigint COMMENT '打赏次数',
sc_add bigint COMMENT '添加收藏',
sc_cancel bigint COMMENT '取消收藏',
gzg_add bigint COMMENT '关注商品',
gzg_cancel bigint COMMENT '取消关注商品',
gzp_add bigint COMMENT '关注人',
gzp_cancel bigint COMMENT '取消关注人',
buzhi_cnt bigint COMMENT '点不值次数',
zhi_cnt bigint COMMENT '点值次数',
zan_cnt bigint COMMENT '点赞次数',
share_cnts bigint COMMENT '分享次数',
bl_cnt bigint COMMENT '爆料数',
fb_cnt bigint COMMENT '好价发布数',
online_cnt bigint COMMENT '活跃次数',
checkin_cnt bigint COMMENT '签到次数',
fix_checkin bigint COMMENT '补签次数',
house_point bigint COMMENT '幸运屋金币抽奖次数',
house_gold bigint COMMENT '幸运屋积分抽奖次数',
pack_cnt bigint COMMENT '礼品兑换次数',
gold_add bigint COMMENT '获取金币',
gold_cancel bigint COMMENT '支出金币',
surplus_gold bigint COMMENT '剩余金币',
event bigint COMMENT '电商点击次数',
gmv_amount bigint COMMENT 'gmv',
gmv_sales bigint COMMENT '订单数'
)
PARTITIONED BY( dt string)
--stat_dt
date COMMENT '互动日期',
以上がODSからADSまで、データウェアハウスの階層化を徹底解説!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。