


ウィスコンシン大学マディソン校などが共同で投稿しました!最新マルチモーダル大型モデルLLaVAリリース、そのレベルはGPT-4に迫る

ビジュアル コマンドの微調整が一般的です。
この文書は Visual structural Tuning と呼ばれ、ウィスコンシン大学マディソン校、Microsoft Research、コロンビア大学が共同で作成したものです。
著者には、Haotian Liu、Chunyuan Li、Qingyang Wu、Yong Jae Lee が含まれます。

同時に、研究者らはコード、モデル、データセットを GitHub でオープンソース化しました。この論文はArxivにも掲載されています。
説明
では、LLaVA の機能とは一体何なのでしょうか?論文の内容を詳しく見てみると、この論文に詳しくない人にとっては少し奇妙に感じるかもしれません。
まずは LLaVA 自体の内容を見てみましょう。
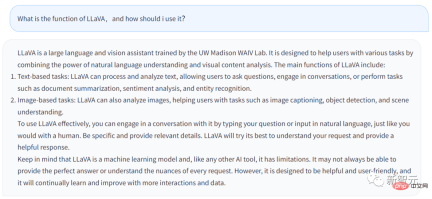
上記の回答は LLaVA のチャットボットから生成されたものです。私が入力した質問は、LLaVA の機能とは何か、そして何をすべきかということです。ユーザーはそれを利用しますか?
答えは次のとおりです。
LLaVA は、UW マディソン WAIV 研究室で訓練された大規模な言語および視覚アシスタントです。 LLaVA は、自然言語理解機能とビジュアル コンテンツ分析機能を活用して、ユーザーがさまざまなタスクを処理できるように設計されています。
LLaVA の主な機能は次のとおりです:
· テキストベースのタスク: LLaVA はテキストを処理および分析できるため、ユーザーは次のことを行うことができます。 LLaVA は、質問をしたり、ユーザーとチャットしたり、文書の要約の調整、センチメント分析、エンティティ認識など、ユーザーが入力したタスクを完了したりできます。
· 画像ベースのタスク: LLaVA は、画像の分析、画像の説明、オブジェクト認識の実行、シーンの分析と理解が可能です。
ユーザーが LLaVA をより適切に適用したい場合は、人間と話すのと同じように、LLaVA に直接話しかけることができます。できるだけ詳細を提供してください。LLaVA はより完全な回答を生成します。
同時に、結局のところ、LLaVA は機械学習モデルであり AI ツールであることを覚えておく必要があります。ツールである限り、限界があります。 LLaVA は、ユーザーが入力した質問に毎回完全に回答するとは限りません。
もちろん、LLaVA も常に学習と改善を続けており、その機能はますます強力になります。
LLaVA の回答から、一般的に、チャットボットの機能は GPT とそれほど変わらないことがわかります。ただし、LLaVA は画像に関連するいくつかのタスクを処理できます。
展示カラー研究者らは、Arxiv 論文で LLaVA の技術的詳細を詳しく説明しています。
機械生成の命令を使用してデータに従い、大規模言語モデル (LLM) の命令を微調整すると、新しいタスクのゼロポイント機能が向上することを知っておくことが重要です。このアイデアは、マルチモーダルな分野では検討されていません。
論文では、研究者らは言語専用 GPT-4 を使用して、マルチモーダル言語画像の命令に従うデータを生成することを初めて試みました。
研究者らは、この生成されたデータに命令を条件付けることで、エンドツーエンドでトレーニングされた大規模なマルチモーダル ステートフル モデルである大規模な言語および視覚アシスタントである LLaVA を導入しました。 、一般的な視覚と言語の理解のためにビジュアル エンコーダーと LLM を接続します。
初期の実験では、LLaVA が優れたマルチモーダル チャット機能を実証し、時には目に見えない画像/コマンドや合成マルチモーダル チャットでマルチモーダル GPT-4 パフォーマンスを出力することが示されています。データセットに従って命令を実行したところ、85.1% の相対スコアを達成しました。
Science Magazine 用に微調整すると、LLaVA と GPT-4 の相乗効果により、92.53% という新たな最先端の精度が達成されました。
研究者らは、GPT-4 によって生成された視覚的なコマンド調整のためのデータ、モデル、コード ベースを公開しました。
マルチモーダル モデル
まず定義を明確にします。
大規模マルチモーダル モデルとは、テキストや画像などの複数の入力タイプを処理および分析できる機械学習テクノロジに基づくモデルを指します。
これらのモデルは、より広範囲のタスクを処理できるように設計されており、さまざまな形式のデータを理解できます。これらのモデルは、テキストと画像を入力として受け取ることで、説明を理解し、編集して、より正確で関連性の高い回答を生成する能力を向上させます。
人間は、視覚や言語を含む複数のチャネルを通じて世界と対話します。それぞれのチャネルには、世界の特定の概念を表現し伝達する上で独自の利点があり、それによって世界をより深く理解することが容易になるからです。 。
人工知能の中心的な目標の 1 つは、マルチモーダルな視覚および言語の指示に効果的に従い、人間の意図と一致し、さまざまな現実生活を完了できる万能アシスタントを開発することです。タスク、世界ミッション。
その結果、開発者コミュニティは、分類、検出、セグメンテーション、説明などのオープンワールドの視覚的理解を強力な機能を備えた言語強化された基本ビジョン モデルの開発に新たな関心を抱くようになりました。 、ビジュアルの生成と編集。
これらの機能では、各タスクは単一の大きなビジュアル モデルによって独立して解決され、タスクの指示はモデル設計で暗黙的に考慮されます。
さらに、言語は画像コンテンツを説明するためにのみ使用されます。これにより、言語は視覚信号を人間のコミュニケーションの共通チャネルである言語意味論にマッピングする上で重要な役割を果たすことができます。ただし、その結果、対話性やユーザーの指示への適応性が制限された固定インターフェイスを持つモデルが多くなります。
そして、大規模言語モデル (LLM) は、言語がより広範な役割を果たすことができることを示しています。一般的なアシスタントのための共通インターフェイス、さまざまなタスクの指示を言語で明示的に表現し、目的を達成するためのガイドとして機能します。最終的にトレーニングされたニューラル アシスタントは、問題を解決するために対象のタスクに切り替えます。
たとえば、ChatGPT と GPT-4 の最近の成功は、この LLM が人間の指示に従う能力を実証し、オープンソース LLM の開発に対する大きな関心を刺激しました。
LLaMA は、GPT-3 と同等のパフォーマンスを持つオープンソース LLM です。現在進行中の作業では、サンプルに続くさまざまな機械生成の高品質命令を活用して LLM のアライメント機能を向上させ、独自の LLM と比較して優れたパフォーマンスを報告しています。重要なのは、この作業はテキストのみであるということです。
この論文では、研究者らはビジュアル コマンド チューニングを提案していますが、これはコマンド チューニングをマルチモーダル空間に拡張する初めての試みであり、ユニバーサルなビジュアル アシスタントを構築する道を切り開くものです。具体的には、この論文の主な内容は次のとおりです。
データに続くマルチモーダル命令。主要な課題は、データを追跡するための視覚的な言語の指示が不足していることです。データ改革の観点と、ChatGPT/GPT-4 を使用して画像とテキストのペアを適切なコマンドに従う形式に変換するパイプラインを紹介します。
大規模なマルチモーダル モデル。研究者らは、CLIPのオープンセット視覚エンコーダと言語デコーダLaMAを接続することで大規模マルチモーダルモデル(LMM)を開発し、生成された指導用視覚言語データに基づいてエンドツーエンドで微調整した。実証研究では、生成されたデータを使用した LMM 命令チューニングの有効性が検証され、一般的な命令に従うビジュアル エージェントを構築するための実践的な提案が提供されます。研究チームは GPT 4 を使用して、Science QA マルチモーダル推論データセットで最先端のパフォーマンスを達成しました。 ############オープンソース。研究チームは、生成されたマルチモーダル命令データ、データ生成とモデルトレーニング用のコードライブラリ、モデルチェックポイント、ビジュアルチャットデモを公開しました。
結果の表示

LLaVA はあらゆる種類の問題を処理でき、生成された回答は包括的かつ包括的であることがわかります。論理的。
LLaVA は、GPT-4 のレベルに近いマルチモーダル機能を示しており、ビジュアル チャットに関して GPT-4 相対スコアは 85% です。
推論に関する質問と回答の観点からは、LLaVA は新しい SoTA-92.53% にも到達し、マルチモーダルな思考チェーンを打ち破りました。
以上がウィスコンシン大学マディソン校などが共同で投稿しました!最新マルチモーダル大型モデルLLaVAリリース、そのレベルはGPT-4に迫るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AM
生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AMGoogleはこのシフトをリードしています。その「AIの概要」機能はすでに10億人以上のユーザーにサービスを提供しており、誰もがリンクをクリックする前に完全な回答を提供しています。[^2] 他のプレイヤーも速く地位を獲得しています。 ChatGpt、Microsoft Copilot、およびPE
 このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM
このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM2022年、彼はソーシャルエンジニアリング防衛のスタートアップDoppelを設立してまさにそれを行いました。そして、サイバー犯罪者が攻撃をターボチャージするためのより高度なAIモデルをハーネスするにつれて、DoppelのAIシステムは、企業が大規模に戦うのに役立ちました。
 世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM
世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM出来上がりは、適切な世界モデルとの対話を介して、生成AIとLLMを実質的に後押しすることができます。 それについて話しましょう。 革新的なAIブレークスルーのこの分析は、最新のAIで進行中のForbes列のカバレッジの一部であり、
 2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM
2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM労働者2050年。全国の公園は、ノスタルジックなパレードが街の通りを通り抜ける一方で、伝統的なバーベキューを楽しんでいる家族でいっぱいです。しかし、お祝いは現在、博物館のような品質を持っています。
 あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AM
あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AMこの緊急かつ不安な傾向に対処するために、TEM Journalの2025年2月版の査読済みの記事は、その技術のディープフェイクが現在存在する場所に関する最も明確でデータ駆動型の評価の1つを提供します。 研究者
 Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM
Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM新薬を策定するのにかかる時間を大幅に短縮することから、より環境に優しいエネルギーを生み出すまで、企業が新境地を破る大きな機会があります。 しかし、大きな問題があります:スキルを持っている人々が深刻な不足があります
 プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM
プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM数年前、科学者は、特定の種類のバクテリアが酸素を摂取するのではなく、電気を生成することで呼吸するように見えることを発見しましたが、どのようにしたのかは謎でした。 Journal Cellに掲載された新しい研究は、これがどのように起こるかを特定しています:微生物
 AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM
AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM今週のRSAC 2025会議で、SNYKは「The First 100 Days:How AI、Policy&Cybersecurity Collide」というタイトルのタイムリーなパネルを開催しました。ニコール・ペルロス、元ジャーナリストとパートネ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Dreamweaver Mac版
ビジュアル Web 開発ツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

