
ホームページ >テクノロジー周辺機器 >AI >自動運転データクローズドループの理想と現実
自動運転データクローズドループの理想と現実

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-29 19:25:121434ブラウズ
近年、自動運転業界ではデータ閉ループが注目を集めており、多くの自動運転企業が独自のデータ閉ループシステムを構築しようとしています。
実際、データのクローズド ループは新しい概念ではありません。従来のソフトウェア エンジニアリングの分野では、データ クロージャはユーザー エクスペリエンスを向上させる重要な方法として使用されています。誰もが経験があると思いますが、ソフトウェアを使用しているときに、「このソフトウェアによるデータ収集を許可しますか?」というポップアップウィンドウが画面上に表示され、関連する規制に同意すると、データが収集されます。ユーザーエクスペリエンスを向上させるために使用されます。
クライアント ソフトウェアが問題をキャプチャすると、バックグラウンドで対応するデータがキャプチャされ、開発チームが問題を分析し、ソフトウェアを修復および改善して、テストに引き渡します。テストチーム ソフトウェアの新しいバージョンはクラウドに配置され、ユーザーによって端末に更新されます。これは、ソフトウェア エンジニアリングにおけるデータの閉ループ プロセスです。
自動運転シナリオでは、通常、問題データはテスト車両で収集され、量産車両で収集できる車両はほとんどありません。収集後、データに注釈を付ける必要があり、エンジニアは新しいデータを使用してクラウドでニューラル ネットワーク モデルをトレーニングし、再トレーニングされたモデルは通常、OTA を通じて車両に展開されます。
#完全なデータ閉ループには、通常、データ収集、データ リフロー、データ処理、データ アノテーション、モデル トレーニング、テストと検証が含まれます。
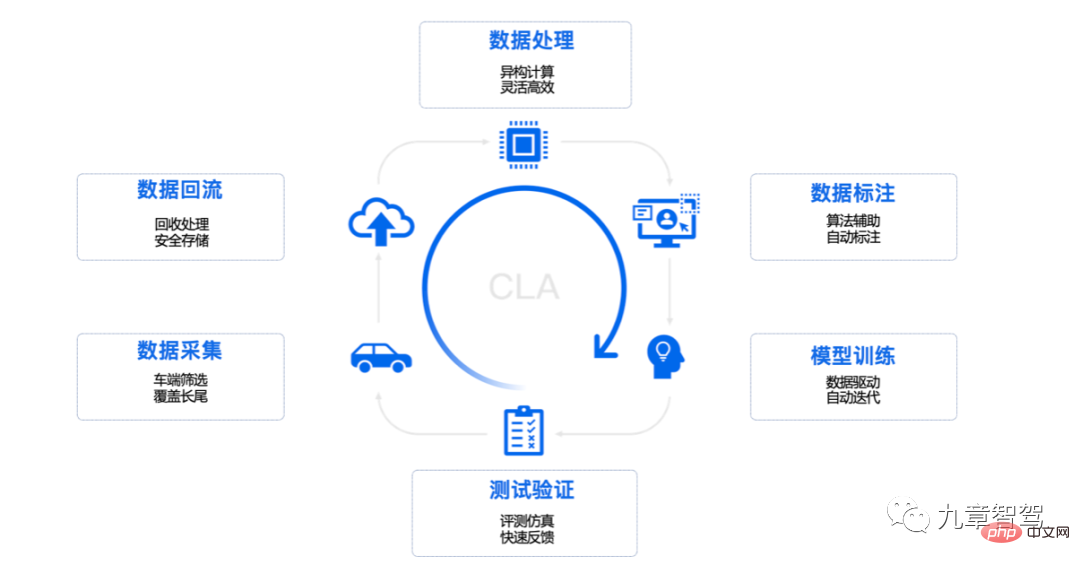
#Momenta データの閉ループ プロセスの図
Tesla を例に挙げると、自動運転ハードウェアを搭載した車両は、シャドウ モードでルールとトリガーによってフィルタリングされたデータを収集し、意味的にフィルタリングされたデータがクラウドに送り返されます。その後、エンジニアはクラウドのツールを使用してデータに何らかの処理を実行し、処理されたデータをデータ クラスターに配置し、これらの有効なデータを使用してモデルをトレーニングします。モデルがトレーニングされた後、エンジニアはトレーニングされたモデルを車両ターミナルに展開して一連の指標テストを行い、検証された新しいモデルはドライバーが使用できるように車両ターミナルに展開されます。このモデルでは、新しいデータが継続的にトリガーされて送信され、サイクルが形成されます。この時点で、完全なデータ駆動型の反復開発サイクルが形成されます。
現在、データ閉ループを使用してアルゴリズムの反復を実行することが、自動運転機能を向上させる唯一の方法であるとほぼ認識されています。多くの OEM と自動運転 Tier 1 は独自のデータ クローズド ループ システムを構築しており、データ クローズド ループ アーキテクトという専任のポジションさえ持っています。
データ閉ループの意味は何ですか?データクローズドループが量産車に導入される背景は何ですか?量産車にデータ クローズド ループを実装する際の問題点とその対処方法は何ですか?
次に、この記事ではこれらのトピックについて 1 つずつ説明します。
01 データ クローズド ループの重要性
Zhijia Technology MAXIEYE の紹介によると、「データ クローズド ループはパフォーマンスだけを重視するものではありません」機能のパフォーマンスが向上し、シャドウモードの形で新機能を検証できると同時に、データトリガーのカテゴリに応じて、システムの他の側面の最適化にも役立ちます。レーダー/カメラの障害検出として機能し、返されたデータに基づいてしきい値を最適化できますパフォーマンス レベルでは、データ バックホールは基本的に、AEB、LKA、ELK、ACC、TJA、NOA などのすべてのパフォーマンスを最適化できます。データ バックホール OTA を通じて AEB、ACC、TJA などのシステム機能を継続的にアップグレードし、新機能のシャドウ モードをプリ埋め込んでいます。」
現在、さまざまな企業が独自のデータを構築しています。彼らが達成したいと考えている主な効果には、コーナーケースのデータ収集の効率の向上、モデルの機能の一般化の向上、およびアルゴリズムの反復の推進が含まれます。
#1.1 特殊なケースのデータを収集するL2 以降の製品である限り、すべてが進化し続ける能力を持っている必要があります。自動運転システムが進化し続けるためには、コーナーケースデータを継続的に取得する必要があります。ますます多くのコーナーケースが「未知」から「既知」に変わるにつれて、限られた形式のルートで限られた数の試験車両を通じて新しいコーナーケースを発掘することはますます困難になっています。
データ収集システムをより広範囲のシーンをカバーする量産車両に展開することで、現在の自動運転システムが十分に対処できない状況に遭遇したときにデータ バックホールをトリガーするためのより良い方法になります。 。
たとえば、L2 運転支援を備えた量産車両に AEB システムを導入し、ドライバーのブレーキ、アクセル、ステアリング、操舵などのデータを収集できます。ドライバーがこれらの操作を実行したときに AEB システムが応答しない理由を分析するために使用されます。 AEB システムの機能を向上させるのに十分な応答が得られないという問題に対処するには、対応する改善を行う必要があります。
1.2 モデルの汎化能力を向上させる
現在、高レベルの支援運転 高速道路から市街地へ移動中です。高速などの比較的単純なシーンを解決する場合、基本的には市販車のデータを返す必要はなく、テスト車で収集したデータのみを使用してモデルをトレーニングするだけで十分ですが、都市シーンの複雑さは大きく影響します。また、各都市の道路状況には多くの違いがあります。たとえば、広州では道路を物を牽引する三輪車がどこでも猛スピードで走っているのを見かけますが、上海ではほとんど見かけません。
したがって、多くの自動運転ティア 1 企業や自動車会社は、シーン統合、つまり、車両の運転支援システムが主流都市のさまざまな道路状況に適切に対応できることに対する強い需要を持っています。自動車会社はユーザーの走行範囲を制限することができないため、運転支援機能が狭い地域にのみ提供されると、ユーザー層の範囲が大幅に狭まってしまい、これは自動車会社が望んでいることではないことは明らかです。
シナリオを開くという目標を達成するには、モデルの汎化能力を大幅に向上させる必要があります。モデルの汎化能力を大幅に向上させるには、さまざまなシナリオに対応するデータを可能な限り収集する必要があります。十分な規模と多様性を持つデータを蓄積できるのは、大規模な実際の人間の運転データに基づく乗用車の運転支援だけです。
1.3 アルゴリズムの反復を駆動する
前述したように、深層学習に基づく人工知能このアルゴリズムは 10 年以上開発されてきました。この間、モデルの進化とコンピューティング能力の発達により、自動運転システムがビッグデータを消化できるようになりました。さらに、自動運転システムのアップグレードが必要な場合は、それに応じて知覚、計画などの能力を向上させる必要があり、データを使用してアルゴリズムを継続的に進化させることは、知覚、計画、およびその他の能力を向上させる効率的な方法です。他の側面。
都市 NOA - つまり、都市におけるポイントツーポイントのナビゲーション支援機能は、多くの OEM と自動運転 Tier1 の次の焦点です。ナビゲーション支援運転機能、知覚システム 意味認識、障害物認識、走行可能領域認識はいずれも一定の精度が要求されるが、その基準はまだ達成されていない。
現在の主流の知覚システム ネットワーク アーキテクチャは、BEV Transformer モデルに基づいており、最適化はソフトウェア エンジニアまたはアルゴリズム アーキテクトのみに依存しています。このモデルには改善の余地があまりありません。 BEV Transformer アーキテクチャは大量のデータを収容でき、モデル効果の向上が期待されます。
計画レベルでは、データドライブも役割を果たすことができます。テスラは、初期値として部分制約の下での最適解を使用し、その後、増分法を使用して新しい制約を継続的に追加し、制約を追加した後に最適化問題を解いて、最終的に計画問題の最適解を取得していました。 Tesla のエンジニアは、この方法のためにオフラインで多くの事前生成を行い、オンラインで並列最適化を行ったので、各候補パスの計算時間は依然として 1 ~ 5 ミリ秒と長くなります。テスラが 2022 年 9 月 30 日の AI デーで明らかにした内容によると、テスラのエンジニアは現在、一連のデータ駆動型デシジョン ツリー生成モデルを使用して、自動運転システムが計画された経路を迅速に生成できるようにしています。このデータドリブンのデシジョンツリー生成モデルは、テスラ車両の人間ドライバーの運転データと時間制約のない最適な経路をトレーニングの真の値として使用し、候補計画経路を 100us 以内に生成することができ、候補計画の生成を大幅に短縮します. パスタイム。
上記のことから、優れたデータ閉ループ システムを構築することが自動運転システムの機能を向上させる重要な方法であることがわかります。
02 データクローズドループの背景
現在、多くの量産車両には運転支援システムが搭載されており、人間が運転できるようになりました。量産車 データ収集は難しくなく、自動運転システムの路上試験走行距離は1億kmを超えます。さらに、チップの計算能力もさらに強化されており、たとえば、NVIDIA の OrinX チップの計算能力は最大 254TOPS であるため、大型モデルが知覚システムに適用され始めており、自動運転システムがビッグデータを消化できるようになりました。一方で、クラウドテクノロジーは比較的成熟しており、自動運転は徐々にデータドリブンの時代に入り始めています。
MAXIEYE社の説明は「正確に言うと、単なるデータ駆動ではなく、AIアルゴリズムとデータが共同駆動している。AIアルゴリズムは学習効率の問題を解決し、データは学習コンテンツの問題を解決する」としている。 、アルゴリズムとデータは共生関係です。"
"深層学習に基づく人工知能アルゴリズムの開発は 10 年を超えました。この 10 年の初期段階では、教師あり学習が行われています。教師あり学習には、大量の手動アノテーションが必要であり、AI の進歩を大きく制限するという致命的な欠陥がありますが、近年、教師なし学習アルゴリズムと半教師あり学習アルゴリズムは徐々に普及してきました。 「世界が出現し始め、コンピューターは自己学習を通じて継続的にデータをクリーンアップし、アルゴリズムを反復できるようになりました。したがって、データ駆動型のアプローチによる自動運転技術を開発する条件は熟しました。」
万里の長城サロン インテリジェント センター所長のヤン ジフェン氏は講演で次のように述べました。「車両全体の観点から見ると、L2 から L4 までの閉ループ アーキテクチャとデータ閉ループは 2022 年に完成する予定です。 「サイド アーキテクチャとクラウド アーキテクチャはさらに統合されます。継続します。次の競争は、データ マイニング、データの効果的な使用、テクノロジー スタック全体によるデータの理解、そして大規模インフラストラクチャ上で全体のコンピューティング効率のバランスをどのように取るかです。」
03 データ クローズド ループの問題点と実装上の対策
現在、自律型システムにおけるデータ クローズド ループの重要性については全員がコンセンサスに達しています。データ閉ループが量産車両に実装される時期は基本的に成熟しています。では、各社のデータクローズドループの実際の導入はどのようになっているのでしょうか?企業のデータ閉ループ システムの有効性をどのように判断すればよいでしょうか?
著者は、スマート運転技術 MAXIEYE から、自動運転 Tier 1 ではデータ閉ループを技術的に実現することは問題ではないことを学びました。 Tier 1 – データクローズドループを通じて自動車メーカーに力を与えることができるかどうか。第二に、データ閉ループの効果は、製品の反復がデータ閉ループによって駆動されるかどうか、返されたデータに基づいてソフトウェアとアルゴリズムを最適化でき、OTA を通じて定期的に端末に展開できるかどうかにも依存します。
現在、データ閉ループ機能のレベルに応じて、自動運転ティア 1 は 3 つのカテゴリに分類できます。1 つ目は、大規模な質量を達成したデータ閉ループです。 2 つ目は、収集車両がクローズド ループを実現するタイプであり、3 つ目は、データのクローズド ループを実現する能力がまだ達成されていないタイプです。現時点では、前者のタイプはまだ少数派です。
著者と業界関係者の間で交換された情報によると、現在、ほとんどの企業は収集車両をデータ ソースとして使用しています。ユーザーのプライバシー、インフラ、コストなどのさまざまな要因により、自動運転システムの反復アップグレードのための量産車両の大規模なデータ収集はまだ実現していません。一部の企業は、クローズドループデータ活用のための量産車のデータを収集するプロセスをまだ確立していない、またはプロセスを確立してデータを収集しているものの、データを有効に活用できていない企業もあります。
数社が量産車からデータを収集すると報じられているが、現在収集されているデータは主に現在の自動運転システムの故障診断に使用されていると業界関係者は報告している。 、など。深層学習モデルの反復には使用されません。
つまり、大規模量産車から収集したデータを活用して大規模量産のデータクローズドループを実現している企業はほとんどありません。駆動システム能力の自動向上を実現します。では、データのクローズドループの大量生産における問題点は何でしょうか?これらの問題点に対処する戦略は何でしょうか?
大量生産の実践において考慮する必要がある問題には、データ収集と使用のコンプライアンスを確保する方法、データ検証の問題を解決する方法が含まれますが、これらに限定されません。 、およびデータ収集機能を統合する方法 自動運転システムの共存、データ処理の難しさ、データ駆動型ソフトウェア システムの複雑さの高さ、モデル トレーニングの難しさなど。
3.1 データ収集と使用におけるコンプライアンスの問題
コンプライアンスは測量とデータに分けられます。マッピング コンプライアンスとプライバシー コンプライアンス: 測量とマッピングのコンプライアンスには主に国家地理情報を収集するときのコンプライアンスが含まれ、プライバシー コンプライアンスには主にユーザーのプライバシー関連データを収集するときのコンプライアンスが含まれます。
測量と地図のコンプライアンスに関しては、近年、国はデータセキュリティの管理を強化し、返されるデータの範囲を制限するために関連する法律や規制を導入しています。 2022 年の「830 新規制」以降、道路上の車両によって収集されるデータは測量および地図データに属します。企業が測量データと地図データを使用したい場合は、その後のデータ暗号化とデータ コンプライアンスが不可欠です。
まず第一に、道路上でデータを収集する場合、企業は国家測量および地図作成の資格を取得し、それに対応する申請を行う必要があり、そうでない場合、収集プロセスは国家安全保障およびその他の部門によって阻止されます。現在、中国には関連資格を保有する機関が合計約 30 社あり、応用範囲が広く国内の多くの都市で取得できる電子航法国家 A 級資格を取得している企業もあれば、B 級資格を取得している企業もある。幅広い用途を持つ資格ですが、規模は小さくなり、特定の都市でのみ取得できるようになります。
測量・地図の資格は取得が難しいため、長期にわたる業務の蓄積が必要であり、また、測量・地図の資格を維持するためには、企業が対応する測量・地図サービスを備えていることが必要です。したがって、OEM と自動運転ティア 1 は通常、資格のあるサプライヤーまたはユニットに委託しており、たとえば、一部のクラウド ベンダーは、顧客がデータの取得、処理、使用に関するコンプライアンス計画を策定するのを支援しています。
データを収集した後、車側で感度を解除して暗号化する必要があり、クラウド (一般的に言えばプライベート クラウド) にアップロードした後、ある程度のコンプライアンスが必要になります。この部分は、認定されたサプライヤーまたはユニットが測量と地図のコンプライアンスを支援します。一部の非常に機密性の高いデータについては、画像販売業者が収集し、データの機密性を解除して画像販売業者が管理するサーバーに保存する必要があります。
また、測量・地図データを漏洩してはならず、特にデータを国外に持ち出したりしてはならず、中国人以外は測量・地図データを取得したり、測量・地図データを操作したりすることはできません。社内で。
一般に、OEM と自動運転 Tier1 は独自のデータ センターを設立しますが、セキュリティ上の理由から、これらのデータ センターは比較的閉鎖されています。 OEM および自動運転ティア 1 が、コンプライアンス要件に基づいてトレーニングやシミュレーションなどを行うために、これらのデータ センターに保存されているデータを使用する必要がある場合、関連するモデルをデータ センターに展開して使用する必要があります。
一部の業界専門家は、「測量と地図作成のコンプライアンスプロセスは複雑すぎ、資格の取得も困難です。誰もが高精度地図への依存をできる限り減らしたいと考えています」と述べています。これは、現在業界で人気があります。これが、「知覚とライト マップを重視する」ソリューションの理由の 1 つです。しかし、実際には、ライト マップが必ずしも「優れている」わけではありません。マップ データがあることの効果は確実にあるためです。 「ないよりはマシです。この現在の傾向が必ずしも最終形であるとは限りませんし、必ずしも最良であるとは限りません。はい、私たちはそれがよりシンプルになることを願っています。」
プライバシーの観点からコンプライアンスに準拠しているため、企業が量産車両からデータを収集するにはユーザーの承認が必要です。 WeChatを使用する場合と同様に、企業はユーザーに最初に認可契約に署名し、どのデータが収集され、どのような使用行動が記録されるかをユーザーに通知することを要求します。
現時点では、プライバシー コンプライアンスの観点から、国はどのデータを収集できるか、どのデータを収集できないかを規定する特に具体的な計画をまだ発表していません。その代わりに、比較的広範な条項があるだけです。データ収集主体を規定する。ユーザーのプライバシーが漏洩してはならない。」
実際の運用では、ユーザー情報に関連するデータを感度を下げる必要があります。たとえば、ナンバー プレート番号を隠す必要があります。
3.2 データ確認の問題
自動運転業界に必要なカメラやレーザーを車に集めることはできるでしょうか?あるいはミリ波で形成されたデータはどうでしょうか?
Moshi Intelligent のプロダクト マネージャー、Su Linfei 氏は次のように紹介しました。「中国の「個人情報保護法」の関連規定に従い、法律で許可されていないデータ収集は規制の対象となります。ドイツでは、旧ドイツ連邦情報保護局により、ドライバーが被害者でない場合に、同意なく他のドライバーの顔や車両を録画することは個人情報保護法違反となるという規定がある。車両の所有者が他人の情報を記録することで法律に違反している可能性がありますが、新エネルギー車に関連する自動運転産業は非常に新しい分野であるため、現時点では法的規定がありません。量産車によって収集されたデータは、車の所有者が所有する必要があります。」
車の所有者が自分の車を使用して収集したデータを、他の部門で使用することを許可できますか?
現時点では、関連する法的規定や制限はありません。しかし、携帯電話やインターネットなどの他の業界では、それが広く許可されています。
車の所有者がアップロードしたデータは誰が取得できるのでしょうか?
自動車産業チェーンの分業の観点からは、百度の無人タクシーなどの無人車両運行会社と、 2 番目はホストファクトリーです。ただし、前者は比較的小さいため、後者に焦点を当てます。
OEM はユーザーに最も近いため、ユーザーがアップロードしたデータを取得するのが最も簡単です。世界的に見て、テスラはこの点で最高の OEM です。
現状では、OEMがデータを外部に公開することはほとんどなく、その結果、自動運転Tier1がOEMカスタマイズ機能の実装を支援した後、Tier1自身が行わない限り、これらの機能を利用する際のユーザーからのフィードバックデータを収集することは困難です。試乗車もたくさんあります。そうなると、自動運転Tier 1がユーザーのフィードバックデータに基づいてその後の関連機能の最適化を行うことが難しくなり、データの閉ループを実現することが難しくなります。
Moshi Intelligent のプロダクト マネージャーである Su Linfei 氏は、著者に次のように語りました。「OEM 向けのプロジェクトを完了した後、OEM がデータ インターフェイスをオープンしない場合、OEM がデータ インターフェイスをオープンにするのは困難になります。ユーザーからのフィードバックを収集し、そのデータを基に、このモデルの製品性能をさらに反復していきます。最終的には、ほとんどの自動運転システムサプライヤーはプロジェクト運営を中核とする企業となり、製品性能が後れを取るにつれて徐々に淘汰されていきました。
さらに悪いことに、自動運転システムのソース コードをオープンソースにする傾向が現れて以来、一部の OEM は自動運転機能を実現するために独自のデータ閉ループ システムを構築したいと考えており、そのため消極的です。サプライヤーとデータを共有することです。しかし、OEMがこれを行うのは合理的ではないと思います。自動運転のエコシステム全体から見ると、誰もが自分の職務を遂行し、専門家が専門的なことを行うのが最善であると思います。しかし、業界は「まだ開発の比較的初期段階にあります。おそらく誰もが挑戦して、より大きな主導権を握りたいと思うでしょう。」
新エネルギー OEM の専門家は次のように述べています。サプライヤーはデータを理解できないため、サプライヤーにデータを提供したくない サプライヤーはどのように自分たちに還元できるでしょうか? データを提供した後、相手はデータをどのように使用するかわからないかもしれません。自動運転ソリューションを OEM に提供する場合、OEM はデータ使用権を開放できます。もちろん、オープンデータ使用権の前提条件はコンプライアンスです。サプライヤーは、OEM から提供されたデータを受け取るとき、およびデータを使用するときに、プロセス全体がコンプライアンスに準拠していることを確認する必要があります。
OEM にとって、サプライヤーにデータを公開しない場合は、データの価値を自分たちで調査する必要があります。初期の頃は、このデータの具体的な価値を誰も知りませんでしたが、それを使用することによってのみ、その価値が徐々に発見されるようになりました。 OEM は、まずサプライヤーにデータを渡し、そのコピーを自社で保管し、サプライヤーはデータの価値を発見した後に OEM に返すことができます。
現在、一部の OEM はサプライヤーに対し、SOP 後のソフトウェアの反復支援を継続するよう要求しており、サプライヤーはこれをデータを取得する機会として利用することもできます。この状況はサプライヤーと協力して達成できます。もちろん、OEM の観点から見ると、この方法にはまだいくつかの欠陥があります。反復後に効果が向上することをサプライヤーが保証するのは難しいからです。また、OEM が反復の効果を検証することは困難であるため、OEM は多くの場合、中間結果に関するデータ (感覚ターゲットの認識結果など) のインターフェースを開くことをサプライヤーに要求し、OEM が中間結果の統計指標を通じてサプライヤーの反復を検証できるようにします。 。 効果。
現時点では、主に相互信頼と誠実な協力の精神を両当事者が持つことが必要です。OEM はデータの使用権をサプライヤーに開放し、サプライヤーは定期的にデータを使用する権利を開放します。ソフトウェアを更新すると、その効果が確認できるため、連携を継続できます。ただ、誰もが明らかな効果を実感していないため、このモデルはまだ広く受け入れられていません。
3.3 データ収集はシステム リソースを占有します
量産車のデータ収集はシステム リソースを占有します。コンピューティング、ストレージなど。理論的には、コンピューティング リソースやネットワーク帯域幅などに制限はないと想定できますが、実際の実装プロセスでは、収集されたデータが量産型の自動運転システムの通常の動作に影響を与えないようにする方法が重要になります。たとえば、自動運転システムの遅延に影響を与えないようにする方法など、これは解決すべき問題です。
もちろん、一部の企業は、リソース占有の問題が発生しないように、自動運転システムが実行されていないときにデータをアップロードします。ただし、自動運転システムが稼働していないときにのみデータをアップロードするのでは、収集できるデータ量が制限されるのではないかとの見方も業界内にはあり、現段階でも可能な限り多くのデータを収集する必要がある。そして、設計時にはデータ収集が自動運転システムの動作に与える影響を考慮する必要がある。
3.4 データのアノテーションとその後の処理が難しい
量産機からのデータ返却後と推定車、自転車から毎日送信されるデータ量は約 100 メガバイトです。研究開発段階では、車両の総数は数十台から数百台にすぎません。しかし、量産段階では、車両の数は数万台、数十万台、あるいはそれ以上に達することがあります。そして、量産段階では、フリート全体で毎日生成されるデータの量は膨大になります。
データ量の急激な増加により、ストレージ容量とデータ処理速度の両方に課題が生じています。量産後は、データ処理のレイテンシを研究開発段階と同じレベルに保つ必要があります。しかし、基盤となるインフラストラクチャが対応できない場合、データ量の増加に応じてデータ処理の遅延も増加し、研究開発プロセスの進捗が大幅に遅くなります。システムの反復では、この効率の低下は許容できません。
業界の専門家は著者に、「量産車から送信される大規模なデータを処理できる能力を備えた企業は、現時点では見たことがありません。たとえ、データクローズドループレベルでは比較的最先端の新車製造部隊の新車メーカーでは、たとえ量産車1台が毎日5分程度のデータを送り返したとしても、これほどの量のデータには対応できないだろう。現在のストレージ デバイス、ファイル読み取りシステム、コンピューティング システムのせいで、ツールなどはまだ膨大な量のデータに対応できません。」
増加するデータ量に対処するにはデータの増加に応じて、基盤となるインフラストラクチャとプラットフォームの設計をアップグレードする必要があります。
エンジニアリング チームは、完全なデータ アクセス SDK を開発する必要があります。視覚データとレーダー データのファイル サイズは非常に大きいため、データ アクセス、クエリ、ジャンプ、およびデコードのプロセスが十分に効率的である必要があり、そうでないと研究開発の進捗が大幅に遅くなります。
車両側のデータがクラウドに送信された後、エンジニアリング チームは大量のデータにタイムリーにラベルを付ける必要があります。業界では現在、補助的なアノテーションに事前トレーニングされたモデルを使用していますが、データ量が多い場合、アノテーションには依然として多くの作業が必要です。
データにラベルを付けるときは、ラベル付け結果の一貫性を確保する必要もあります。現在、業界では完全に自動化されたデータ アノテーションがまだ実装されておらず、ワークロードの一部を完了するには依然として手動作業が必要です。手作業では、データ量が膨大な場合にラベル付け結果の一貫性をどのように確保するかも大きな課題です。
また、自動運転に関連するデータは量が多いだけでなく、その種類も多様であるため、データ処理も困難になります。データの種類は、車両データ、位置データ、環境センシング データ、アプリケーション データ、個人データなどを含むソースに応じて分類され、構造化データと非構造化データを含む形式に応じて分類されます。データ サービスの種類には、ファイル、オブジェクト、規格を統一する方法や、さまざまな種類のストレージとアクセス インターフェイスを調整する方法も大きな問題です。
3.5 データ駆動型ソフトウェア システムは非常に複雑です
従来の V 字型開発モデルを適用するのは困難ですデータ閉ループ。さらに、現在、業界には高レベルの自動運転のための統一されたソフトウェア開発プラットフォームとミドルウェアが存在しません。
ある企業の自動運転部門の技術専門家は著者に、「データと深層学習モデルによって駆動される自動運転機能の反復システムは、ソフトウェア 2.0 と呼ぶことができます。このモデルでは、チーム構築、研究開発プロセス、テスト方法、ツール チェーンを含むシステム全体は、データを中心に構築されています。」
ソフトウェア 1.0 の時代、誰もがどのようなコードを提出したか、何があったのか期待される 効果を評価するのは簡単です。しかし、ソフトウェア 2.0 の時代では、各人の貢献が全体的な効果に及ぼす影響を測定することがより困難になり、全員が互いに通信するものはもはや明確に目に見えるコードではないため、事前に予測することも困難になります。ただし、データおよびデータベースの通信のモデルが更新されました。
データ量が非常に少ない場合、たとえばモバイル インターネット アプリケーション用の AI ビジョン アルゴリズムを開発するとき、データ量が少ないため、関与するビジュアル モデル エンジニアは基本的に Windows や Ubuntu のフォルダーは個別に管理されており、チーム メンバーは名前を変更したさまざまなフォルダーを直接使用して相互に転送するため、データ交換やコラボレーションには非常に非効率的でした。
しかし、自動運転タスクとなると、私たちは何十万枚もの写真に直面し、何百人もの人々がシステムを共同開発します。それぞれの変更には、数百、あるいはさらには複数のモジュールが含まれます。何千も。各モジュールのコード品質を評価する方法と、モジュール間に競合があるかどうかを確認する方法は、比較的複雑なタスクです。今のところ、このシステムはまだ貧弱で、エンジニアリングの部分が十分に成熟していないと思います。
ソフトウェア 2.0 の段階でも、まだ対処する必要がある問題は、特定のシナリオおよび全体的な状況に対する新しいデータの影響をどのように測定するか、および再リスクを回避する方法です。新しいデータに基づいたエンジニアリング トレーニングされたモデルは、一部の特定のタスクでは向上しますが、全体的なパフォーマンスは低下します。これらの問題を解決するには、単体テストを実行して、データの追加が解決したいセグメント化されたシナリオに役立つかどうか、また全体的な状況に役立つかどうかを確認する必要があります。
たとえば、特定のタスクについて、元のデータ セットに 2,000 万枚の写真が含まれており、その後 500 枚の新しい写真が追加された場合、この特定のタスクを解決する能力は向上しますが、場合によってはこれも意味します。グローバル タスクを処理するとモデルのスコアが低下することがわかります。
さらに、視覚的なタスクの場合、指標に基づいて新しいデータがモデルに与える影響を判断するだけでなく、具体的な影響がどのようなものであるかを実際に確認する必要もあります。最適化が期待どおりかどうかを確認します。指標だけを見ていると、指標は良くなったものの、実際の業績はまだ期待に届かないという事態も起こりえます。
各更新がグローバルに最適であることを保証するための一連のインフラストラクチャも必要です。このインフラストラクチャには、データ管理、トレーニング評価などが含まれます。テスラは、この点で業界の最前線にいます。そのデータ駆動型リンク全体は、当初から業界をリードするように設計されており、2019 年から 2022 年にかけて、製品をサポートするために大きな変更は必要ありません。
3.6 モデルのトレーニングの難易度が増加します
データの収集、保存、ラベル付けなどの問題を解決した後.、その後のモデルのトレーニングと関数の反復はまだ課題です。
トレーニング量産車両から返される大量のデータには、トレーニング中に I/O によってデータが「スタック」しないように、効率的なファイル転送システムが必要です。
同時に、十分なコンピューティング能力が必要です。計算能力を向上させるには、マルチカードの並列クラスタを構築することが一般的ですが、トレーニング中に効率的なカード間通信を維持してデータ伝送遅延を軽減し、各カードの計算能力を最大限に有効活用することも課題となります。考慮する必要があります。
モデル トレーニングにおけるコンピューティング能力の需要に対処するために、一部の OEM は独自のインテリジェント コンピューティング センターを特別に構築しています。しかし、インテリジェント コンピューティング センターの構築コストは非常に高く、中小企業にとってこれはほとんど不可能です。
#課題はまだたくさんありますが、時間の経過とともに、現在の問題が 1 つずつ解決されることが期待できます。それまでに、データ クローズド ループは量産車に真に実装できるようになり、量産車への実装後に収集されたデータはデータ クローズド ループ システムにフィードバックされ、自動運転システムをより高いレベルに押し上げることになります。
以上が自動運転データクローズドループの理想と現実の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。