
ホームページ >バックエンド開発 >Python チュートリアル >デンドログラムを使用して Python でビジュアル クラスタリングを実装する方法
デンドログラムを使用して Python でビジュアル クラスタリングを実装する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-28 20:49:051982ブラウズ
デンドログラム
デンドログラムは、オブジェクト、グループ、または変数間の階層関係を示す図です。樹状図は、同様の特性を持つ観測値のグループを表すノードまたはクラスターで接続された枝で構成されます。枝の高さまたはノード間の距離は、グループがどの程度異なっているか、または類似しているかを示します。つまり、枝が長くなるほど、またはノード間の距離が長くなるほど、グループの類似性は低くなります。枝が短いほど、またはノード間の距離が小さいほど、グループは類似します。
デンドグラムは、複雑なデータ構造を視覚化し、同様の特性を持つデータのサブグループまたはクラスターを識別するのに役立ちます。これらは、生物学、遺伝学、生態学、社会科学、および類似性や相関性に基づいてデータをグループ化できるその他の分野で一般的に使用されます。
背景知識:
「デンドログラム」という言葉は、ギリシャ語の「dendron」(木)と「gramma」(描画)に由来しています。 1901 年、英国の数学者で統計学者のカール ピアソンは、樹形図を使用して、さまざまな植物種間の関係を示しました [1]。彼はこのグラフを「クラスター グラフ」と呼びました。これは樹状図の最初の使用と考えられます。
データの準備
クラスタリングには複数の企業の実際の株価を使用します。簡単にアクセスできるように、データは Alpha Vantage が提供する無料 API を使用して収集されます。 Alpha Vantage は無料 API とプレミアム API の両方を提供しています。API 経由でアクセスするにはキーが必要です。Alpha Vantage の Web サイトを参照してください。
import pandasaspd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}テクノロジー、小売、石油・ガス、その他の業界から 20 社が選ばれました。
import time
all_data={}
forkey,valueincompanies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url=f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response=requests.get(url)
data=response.json()
time.sleep(15)
if'Time Series (Daily)'indataanddata['Time Series (Daily)']:
df=pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns= {'1. open':key}, inplace=True)
all_data[key]=df[key]上記のコードは、頻繁にブロックされないように、API 呼び出し間に 15 秒の一時停止を設定します。
# find common dates among all data frames
common_dates=None
fordf_key, dfinall_data.items():
ifcommon_datesisNone:
common_dates=set(df.index)
else:
common_dates=common_dates.intersection(df.index)
common_dates=sorted(list(common_dates))
# create new data frame with common dates as index
df_combined=pd.DataFrame(index=common_dates)
# reindex each data frame with common dates and concatenate horizontally
fordf_key, dfinall_data.items():
df_combined=pd.concat([df_combined, df.reindex(common_dates)], axis=1)上記のデータを必要な DF に統合します。これはすぐ下で使用できます
階層的クラスタリング
階層的クラスタリングは、機械学習および機械学習用のクラスタリング アルゴリズムの一種です。データ分析。ネストされたクラスターの階層を使用して、類似性に基づいて類似したオブジェクトをクラスターにグループ化します。このアルゴリズムは、単一のオブジェクトから開始してそれらをクラスターにマージする凝集型と、大きなクラスターから開始してそれをより小さなクラスターに再帰的に分割する分割型のいずれかになります。
すべてのクラスタリング手法が階層クラスタリング手法であるわけではなく、樹状図はいくつかのクラスタリング アルゴリズムでのみ使用できることに注意してください。
クラスタリング アルゴリズム scipy モジュールで提供される階層的クラスタリングを使用します。
1. トップダウン クラスタリング
import numpyasnp import scipy.cluster.hierarchyassch import matplotlib.pyplotasplt # Convert correlation matrix to distance matrix dist_mat=1-df_combined.corr() # Perform top-down clustering clustering=sch.linkage(dist_mat, method='complete') cuts=sch.cut_tree(clustering, n_clusters=[3, 4]) # Plot dendrogram plt.figure(figsize=(10, 5)) sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90) plt.title('Dendrogram of Company Correlations (Top-Down Clustering)') plt.xlabel('Companies') plt.ylabel('Distance') plt.show()
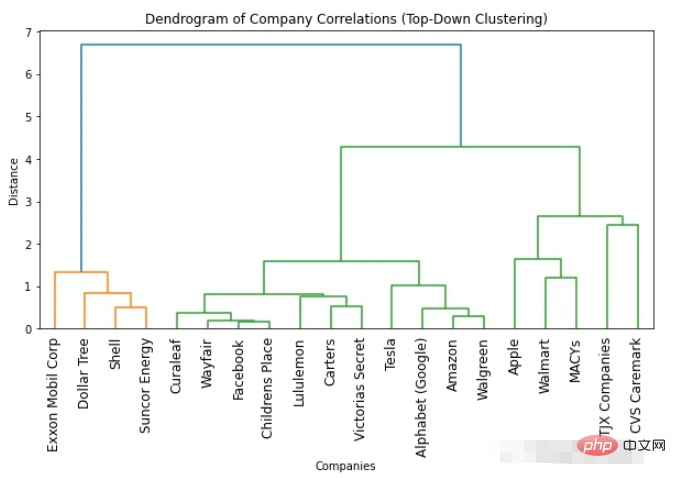
##樹状図に基づいて最適なクラスター数を決定する方法
最適なクラスター数を見つける最も簡単な方法は、結果の樹状図で使用されている色の数を確認することです。最適なクラスターの数は、色の数から 1 つ少ない数です。したがって、上記の樹状図によれば、最適なクラスター数は 2 です。 最適なクラスター数を見つける別の方法は、クラスター間の距離が突然変化するポイントを特定することです。これは「変曲点」または「エルボ点」と呼ばれ、データの変動を最もよく捉えるクラスターの数を決定するために使用できます。上の図では、異なる数のクラスター間の最大距離変化は 1 クラスターと 2 クラスターの間で発生することがわかります。したがって、繰り返しになりますが、最適なクラスター数は 2 です。樹状図から任意の数のクラスターを取得
樹状図を使用する利点の 1 つは、クラスター内の樹状図を確認することで、オブジェクトを任意の数のクラスターにクラスター化できることです。 。たとえば、2 つのクラスターを見つける必要がある場合は、樹状図の一番上の垂直線を見て、クラスターを決定します。たとえば、この例では、2 つのクラスターが必要な場合、最初のクラスターには 4 社が存在し、2 番目のクラスターには 16 社が存在します。 3 つのクラスターが必要な場合は、2 番目のクラスターをさらに 11 社と 5 社に分割できます。さらに必要な場合は、この例に従ってください。2. ボトムアップ クラスタリング
import numpyasnp import scipy.cluster.hierarchyassch import matplotlib.pyplotasplt # Convert correlation matrix to distance matrix dist_mat=1-df_combined.corr() # Perform bottom-up clustering clustering=sch.linkage(dist_mat, method='ward') # Plot dendrogram plt.figure(figsize=(10, 5)) sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90) plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)') plt.xlabel('Companies') plt.ylabel('Distance') plt.show()
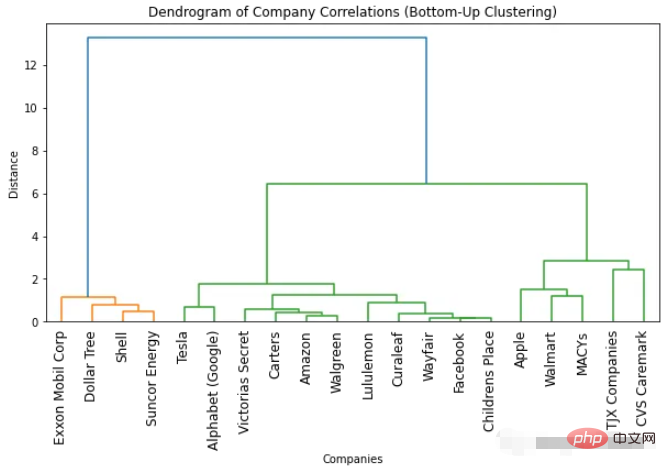 ##ボトムアップ クラスタリングで取得した樹状図 トップダウン クラスタリングと同様です。最適なクラスター数は依然として 2 です (色数と「変曲点」法に基づく)。しかし、より多くのクラスターが必要な場合は、いくつかの微妙な違いが観察されるでしょう。使用される方法が異なるため、結果にわずかな違いが生じるのは正常です。
##ボトムアップ クラスタリングで取得した樹状図 トップダウン クラスタリングと同様です。最適なクラスター数は依然として 2 です (色数と「変曲点」法に基づく)。しかし、より多くのクラスターが必要な場合は、いくつかの微妙な違いが観察されるでしょう。使用される方法が異なるため、結果にわずかな違いが生じるのは正常です。
以上がデンドログラムを使用して Python でビジュアル クラスタリングを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。