
ホームページ >テクノロジー周辺機器 >AI >ハルビン工業大学と南洋工業大学が世界初の「マルチモーダルディープフェイク検出と測位」モデルを提案:AIGCにフェイクを隠す場所を与えない
ハルビン工業大学と南洋工業大学が世界初の「マルチモーダルディープフェイク検出と測位」モデルを提案:AIGCにフェイクを隠す場所を与えない

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-25 10:19:061666ブラウズ
安定拡散などの視覚生成モデルの急速な発展により、高忠実度の顔画像が自動的に偽造される可能性があり、ディープフェイクの問題はますます深刻になっています。
ChatGPT のような大規模な言語モデルの出現により、大量の偽記事が簡単に生成され、悪意を持って虚偽の情報が拡散される可能性もあります。
この目的を達成するために、画像およびテキスト モダリティにおける上記の AIGC テクノロジーの偽造に対処する一連のシングルモーダル検出モデルが設計されました。ただし、これらの方法は、新たな捏造シナリオにおけるマルチモーダルなフェイクニュースの改ざんにうまく対処できません。
具体的には、マルチモーダルメディア改ざんでは、さまざまなニュース報道の写真に含まれる重要人物の顔 (図 1 のフランス大統領の顔) が置き換えられ、テキストキーが置き換えられます。フレーズまたは単語が改ざんされています (図 1 では、肯定的なフレーズ「歓迎します」が否定的なフレーズ「辞任を強いられます」に改ざんされています)。
これにより、主要なニュース人物の身元が変更または隠蔽されるだけでなく、ニューステキストの意味が改変または誤解され、大規模に拡散されるマルチモーダルなフェイクニュースが作成されます。インターネット上で。
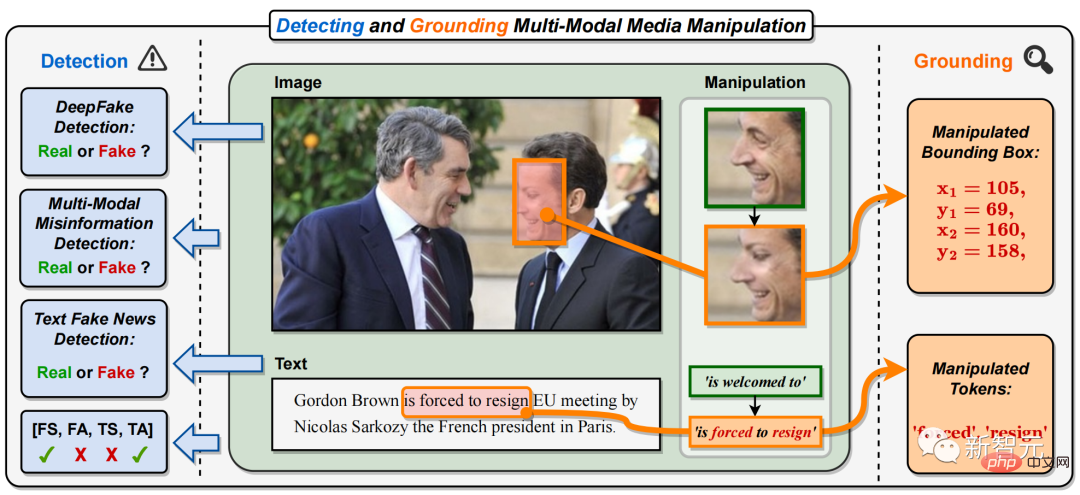
## 図 1. この論文では、マルチモーダル メディア改ざんを検出および特定するタスクを提案しています (DGM4) )。既存のシングルモーダル DeepFake 検出タスクとは異なり、DGM4 は、入力された画像とテキストのペアが true か false かを予測するだけでなく、より詳細な改ざんタイプを検出し、画像改ざん領域の位置を特定しようとします。テキスト改ざん、単語。このタスクでは、真と偽のバイナリ分類に加えて、改ざん検出についてのより包括的な説明と深い理解を提供します。

#表 1: 提案された DGM4 と既存の画像およびテキストの偽造検出 関連タスクの比較マルチモーダルメディア改ざんタスクの検出と特定
この新しい課題を理解するために、ハルビン工業大学 (深セン) と南洋理工大学の研究が行われています。研究者らは、マルチモーダルメディア改ざん (DGM4) を検出して特定するタスクを提案し、DGM4 データセットを構築してオープンソース化し、さらにマルチモーダル階層改ざん推論も提案しました。モデル。現在、この作品は CVPR 2023 に含まれています。

On 記事のアドレス: https://arxiv.org/abs /2304.02556
GitHub:https://github.com/rshaojimmy/MultiModal-DeepFake
#プロジェクトのホームページ: https://rshaojimmy.github.io/Projects/MultiModal-DeepFake
図 1 および表 1 に示すように、検出また、マルチモーダル メディア操作の検出と接地 (DGM4) と既存のシングルモーダル改ざん検出の違いは次のとおりです。
1) とは異なります。既存の DeepFake 画像検出および偽テキスト検出手法では、単一モーダルの偽情報のみを検出できるため、DGM4 では画像とテキストのペアにおけるマルチモーダリティの同時検出が必要です。 ##2) バイナリ分類に焦点を当てた既存の DeepFake 検出とは異なり、DGM4 はさらに、画像改ざん領域とテキスト改ざん単語の特定を考慮します。これには、画像とテキストのモダリティ間の改ざんについて、より包括的かつ詳細な推論を実行する検出モデルが必要です。
マルチモーダル メディア改ざんデータ セットの検出と特定DGM
4の研究をサポートするために、図 2 に示すように、この研究の貢献 世界初の
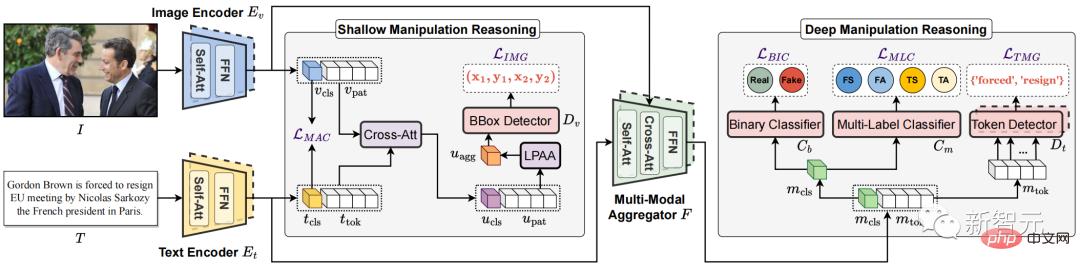
マルチモーダルメディア改ざんの検出と位置特定(DGM4)データセットを開発しました。 #図 2. DGM4データセット DGM 4 データセットでは、顔置換改ざん (FS)、顔属性改ざん (FA)、テキスト置換改ざん (TS)、テキスト属性改ざん (TA) の 4 種類の改ざんを調査します。 図 2 は、(a) 改ざんの種類の数の分布、(b) ほとんどの改ざんされた領域を含む、DGM4 の全体的な統計情報を示しています。画像のサイズは小さい(特に顔属性の改ざんの場合)、(c) テキスト属性の改ざんは、テキスト置換改ざんよりも改ざんされた単語が少ない、(d) テキスト感情スコアの分布、(e) 各改ざんタイプのサンプル数。 このデータは、77,426 の元の画像とテキストのペアと 152,574 の改ざんされたサンプル ペアを含む、合計 230,000 の画像とテキストのペアのサンプルを生成しました。改ざんされたサンプルのペアには、66722 件の顔置換改ざん、56411 件の顔属性改ざん、43546 件のテキスト置換改ざん、および 18588 件のテキスト属性改ざんが含まれます。 この記事では、マルチモーダル改ざんがモダリティ間で微妙な意味論的な不一致を引き起こすと考えています。したがって、モダリティ間の意味論的特徴を融合および推論することによって、改ざんされたサンプルのクロスモーダル意味論的不一致を検出することが、DGM4 に対処するこの記事の主なアイデアです。 図 3. 提案されたマルチモーダル階層型改ざん推論モデル HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER) マルチモーダル階層改ざん推論モデル HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER) を提案します。 具体的には、図 3 に示すように、HAMMER モデルには次の 2 つの特徴があります。 1) 浅い改ざん推論では、# を介して##操作を意識した対照学習 を使用して、画像エンコーダーとテキスト エンコーダーによって抽出された画像とテキストの単一モーダルの意味論的特徴を調整します。同時に、シングルモーダルの埋め込み機能は、情報のやり取りにクロスアテンション メカニズムを使用し、ローカル パッチ アテンション集約メカニズム (ローカル パッチ アテンション集約) が画像改ざん領域を特定するように設計されています。 ##2) 深層改ざん推論では、マルチモーダル アグリゲーターのモダリティを意識したクロスアテンション メカニズムを使用して、マルチモーダル セマンティック機能をさらに融合します。これに基づいて、特別な マルチモーダル シーケンス タグ付けとマルチモーダル マルチラベル分類 実験結果
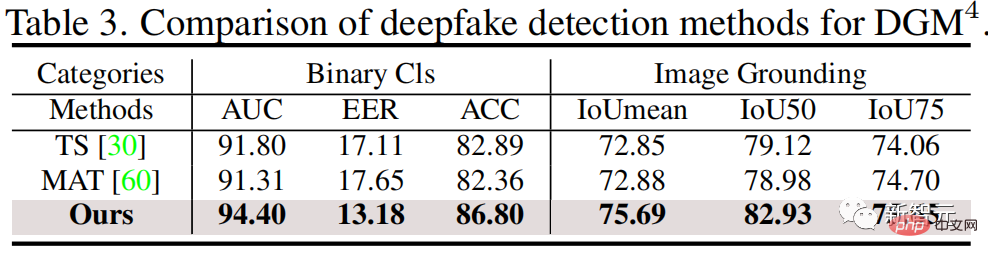
# 図 4. マルチモーダル改ざん検出と位置特定結果の視覚化 図5 . 改ざんされたテキストに対するモデル改ざん検出アテンションの視覚化 図 4 は、マルチモーダル改ざん検出と位置特定の視覚的な結果を示しており、HAMMER が改ざん検出と改ざん検出を正確かつ同時に実行できることを示しています。ローカリゼーションタスク。図 5 は、改ざんされた単語に対するモデル アテンションの視覚化結果を示しており、HAMMER が改ざんされたテキストと意味的に矛盾する画像領域に焦点を当てることによって、マルチモーダルな改ざん検出と位置特定を実行することをさらに示しています。 この作業のコードとデータ セットのリンクは、このプロジェクトの GitHub で共有されています。誰でもこの GitHub リポジトリにスターを付けて、DGM4 を使用することを歓迎します。データセットとハンマー DGM4 問題を勉強しましょう。 DeepFake の分野は、画像の単一モダリティ検出だけでなく、より広範なマルチモダリティ改ざん検出の問題でもあり、早急に解決する必要があります。 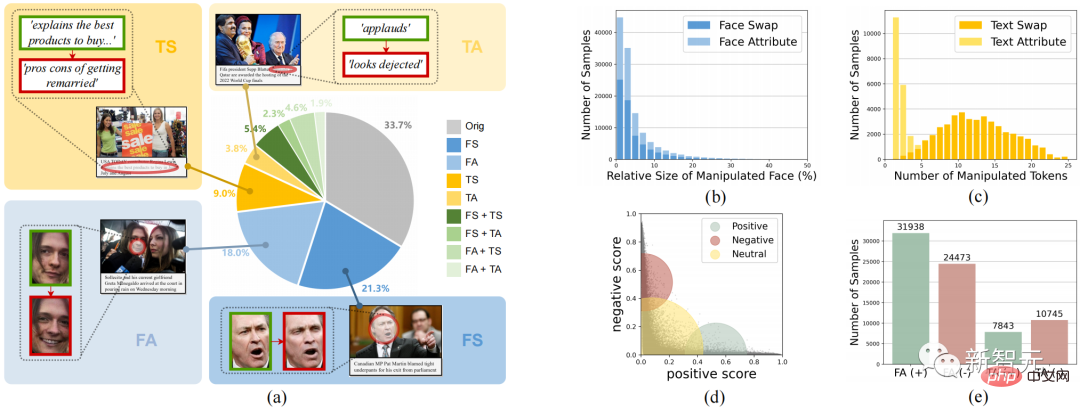


この研究は、マルチモーダルなフェイクニュースに対処するために、マルチモーダルなメディア改ざんを検出および特定するという新しい研究トピックを提案します。
以上がハルビン工業大学と南洋工業大学が世界初の「マルチモーダルディープフェイク検出と測位」モデルを提案:AIGCにフェイクを隠す場所を与えないの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。