


近年、さまざまな主題分野の研究の進歩に伴い、科学文献やデータが爆発的に増加しており、学術研究者が大量の情報から有用な洞察を発見することがますます困難になっています。通常、人は科学知識を得るために検索エンジンを利用しますが、検索エンジンは科学知識を自律的に整理することができません。
今回、Meta AI の研究チームは、科学知識を保存、組み合わせ、推論できる新しい大規模言語モデルである Gaoptica を提案しました。

- #紙のアドレス: https://gaoptica.org/static/paper.pdf
- トライアルアドレス: https://gaoptica.org/
Gaoptica モデルはどのくらい強力ですか?それ自体でレビュー論文を要約して要約します:

 # 尋ねられた質問に対して知識豊富な回答をしてください:
# 尋ねられた質問に対して知識豊富な回答をしてください:
 これらのタスクは人類学者 A にとって依然として必要です。困難な任務でしたが、ギャラクティカは非常にうまくやり遂げました。チューリング賞受賞者のヤン・ルカン氏も次のように賞賛のツイートをした:
これらのタスクは人類学者 A にとって依然として必要です。困難な任務でしたが、ギャラクティカは非常にうまくやり遂げました。チューリング賞受賞者のヤン・ルカン氏も次のように賞賛のツイートをした:
# ギャラクティカ モデルの具体的な詳細を見てみましょう。 
モデルの概要
ギャラクティカ モデルは、4,800 万件以上の記事を含む、論文、参考資料、知識ベース、その他多くのソースからなる大規模な科学コーパスでトレーニングされています。 、教科書や配布資料、何百万もの化合物やタンパク質に関する知識、科学ウェブサイト、百科事典など。キュレーションされていない Web クローラーベースのテキストに依存する既存の言語モデルとは異なり、Galaxy のトレーニングに使用されるコーパスは高品質で高度にキュレーションされています。この研究では、過剰適合することなく複数のエポックに対してモデルをトレーニングし、トークンを繰り返し使用することで上流および下流のタスクのパフォーマンスが向上しました。ギャラクティカは、さまざまな科学的タスクにおいて既存のモデルよりも優れた性能を発揮します。 LaTeX 方程式などの技術的知識の探索タスクでは、Galaxy と GPT-3 のパフォーマンスは 68.2% 対 49.0% でした。ギャラクティカは推論にも優れており、数学的な MMLU ベンチマークではチンチラを大幅に上回っています。
Galatica は、一般的なコーパスでトレーニングされていないにもかかわらず、BIG ベンチでも BLOOM や OPT-175B よりも優れたパフォーマンスを発揮します。さらに、PubMedQA や MedMCQA 開発などの下流タスクで 77.6% と 52.9% という新たな最高パフォーマンスを達成しました。
簡単に言うと、この研究では、内部の仕組みを模倣するために、段階的な推論を特別なトークンにカプセル化しています。これにより、ギャラクティカのトライアル インターフェイスで以下に示すように、研究者は自然言語を使用してモデルと対話できるようになります。
Galaxy では、テキスト生成に加えて、化学式やタンパク質配列を含むマルチモーダル タスクも実行できることは言及する価値があります。創薬分野への貢献となります。 
実装の詳細
この記事のコーパスには、論文、参考文献、百科事典、その他の科学資料に由来する 1,060 億個のトークンが含まれています。この研究には、自然言語リソース(論文、参考書)と自然界の配列(タンパク質配列、化学形態)の両方が含まれていると言えます。コーパスの詳細を表 1 および表 2 に示します。
コーパスを取得したので、次のステップはデータを操作する方法です。一般に、トークン化の設計は非常に重要です。たとえば、タンパク質配列がアミノ酸残基で記述されている場合は、文字ベースのトークン化が適切です。トークン化を実現するために、この研究ではさまざまなモダリティで特殊なトークン化を実行しました。具体的な例は次のとおりです (これに限定されません):
- 参照: 特別な参照トークン [START_REF] および [END_REF] を使用して参照をラップします。
- 段階的推論: 作業メモリ トークンを使用して、段階的推論をカプセル化し、内部の作業メモリ コンテキストをシミュレートします;
- 数値: 数値を個別のトークンに分割します。たとえば、737612.62 → 7,3,7,6,1,2,.,6,2;
- SMILES 式: シーケンスを [START_SMILES] と [END_SMILES] で囲み、文字ベースのトークン化を適用します。同様に、この研究では [START_I_SMILES] と [END_I_SMILES] を使用して異性体の SMILES を表します。例: C(C(=O)O)N→C, (,C,(,=,O,),O,),N;
- DNA シーケンス: 適用one 各ヌクレオチド塩基をトークンとして扱う文字ベースのトークン化。開始トークンは [START_DNA] と [END_DNA] です。たとえば、CGGTACCCTC→C、G、G、T、A、C、C、C、T、C。
# 以下の図 4 は、論文への参照を処理する例を示しています。参照を処理するときは、グローバル識別子と特殊トークン [START_REF] および [END_REF] を使用して参照の場所を表します。

#データセットが処理された後の次のステップは、それを実装する方法です。 Galatica は、Transformer アーキテクチャに基づいて次の変更を加えました:
- GeLU アクティベーション: さまざまなサイズのモデルに GeLU アクティベーションを使用します;
- コンテキスト ウィンドウ: 異なるサイズのモデルの場合、長さ 2048 のコンテキスト ウィンドウを使用します;
- バイアスなし: PaLM に従い、高密度カーネルまたはレイヤー仕様ではバイアスは使用されません;
- 学習場所の埋め込み: 学習場所の埋め込みがモデルに使用されます;
- 語彙: BPE を使用して、50,000 のトークンを含む語彙を構築します。
#表 5 に、さまざまなサイズのモデルとトレーニング ハイパーパラメーターを示します。
 #実験
#実験
重複したトークンは無害とみなされます
図 6 からわかるように、トレーニングの 4 エポックの後、検証損失は減少し続けています。 120B パラメータを持つモデルは、5 番目のエポックの開始時にのみオーバーフィットを開始します。既存の調査では、トークンの重複がパフォーマンスに悪影響を与える可能性があることが示されているため、これは予想外のことでした。この研究では、30B モデルと 120B モデルが時代ごとに二重の減少効果を示し、検証損失が横ばい (または上昇) に続いて減少することもわかりました。この効果は各エポックの後に強くなり、特にトレーニング終了時の 120B モデルで顕著になります。図 8 の結果は、実験に過剰適合の兆候がないことを示しており、トークンを繰り返すことで下流タスクと上流タスクのパフォーマンスが向上する可能性があることを示しています。

数式を入力するのが遅すぎます。プロンプトを使用すると、LaTeX を生成できます:
 化学反応では、Galaxy は化学方程式 LaTeX の反応生成物を予測する必要があります。モデルは反応物のみに基づくことができます。推論すると、結果は次のようになります:
化学反応では、Galaxy は化学方程式 LaTeX の反応生成物を予測する必要があります。モデルは反応物のみに基づくことができます。推論すると、結果は次のようになります:
 いくつかの追加の結果を表 7 に示します。
いくつかの追加の結果を表 7 に示します。
# #
ギャラクティカの推理力。この研究は最初に MMLU 数学ベンチマークで評価され、評価結果が表 8 に報告されています。ギャラクティカは、より大きな基本モデルと比較して強力なパフォーマンスを発揮し、より小さな 30B ギャラクティカ モデルであっても、トークンを使用するとチンチラのパフォーマンスが向上するようです。
この研究では、Galaxy の推論機能をさらに調査するために MATH データセットも評価しました。

実験結果から、思考の連鎖とプロンプトの点で、Galaxy は基本的な PaLM モデルよりもはるかに優れていると結論付けました。これは、数学的タスクを処理するには、Galaxy がより良い選択肢であることを示唆しています。
#下流タスクの評価結果を表 10 に示します。 Galatica は他の言語モデルを大幅に上回り、ほとんどのタスク (Gopher 280B) でより大きなモデルを上回ります。チンチラと比べてパフォーマンスの差は大きく、チンチラは一部の課題、特に高校の科目や、数学的で記憶力をそれほど必要としない課題でより優れているようでした。対照的に、ギャラクティカは数学や大学院レベルのタスクでより良いパフォーマンスを発揮する傾向があります。

この研究では、入力された文脈に基づいて引用を予測するチンチラの能力、つまり科学文献を整理するチンチラの能力も評価されました。結果は次のとおりです。
その他の実験内容については、元の論文を参照してください。
以上がこの大きなモデルは、数式や参考文献を使用して論文を単独で「書く」ことができます。試用版は現在オンラインになっています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIエージェントを使用してパーソナライズされたニュースダイジェストを作成しますApr 12, 2025 am 11:18 AM
AIエージェントを使用してパーソナライズされたニュースダイジェストを作成しますApr 12, 2025 am 11:18 AM導入 大規模な言語モデル(LLM)の機能は迅速に進んでいます。これらにより、さまざまなLLMアプリケーションを構築できます。これらは、タスクの自動化からワークフローの最適化にまで及びます。 1つのエキサイティングなアプリケーションはです
 米国のAIポリシーは、「安全」から「セキュリティ」に急激にピボットしますApr 12, 2025 am 11:15 AM
米国のAIポリシーは、「安全」から「セキュリティ」に急激にピボットしますApr 12, 2025 am 11:15 AMドナルド・トランプ大統領は、彼の任期の1日目にジョー・バイデン前大統領のAIの大統領命令を取り消しました(開示:私はバイデン政権中に国土安全保障省でAIの上級カウンセラーを務めました)、およびJD VA副大統領
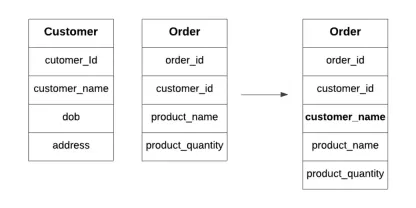 データベースの非正規化とは何ですか?Apr 12, 2025 am 11:10 AM
データベースの非正規化とは何ですか?Apr 12, 2025 am 11:10 AM導入 毎秒数が重要な忙しいカフェを走らせることを想像してみてください。個別の在庫リストと注文リストを常にチェックする代わりに、すべての重要な詳細を1つの読みやすいボードに統合します。これはデノマリザに似ています
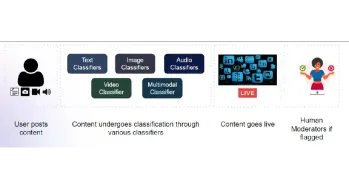 コンテンツモデレートのためのマルチモーダルモデルの構築Apr 12, 2025 am 10:51 AM
コンテンツモデレートのためのマルチモーダルモデルの構築Apr 12, 2025 am 10:51 AM導入 攻撃的な投稿がポップアップ表示されないときに、お気に入りのソーシャルメディアプラットフォームをスクロールしていると想像してください。レポートボタンを押す前に、それはなくなりました。それはコンテンツモデラティです
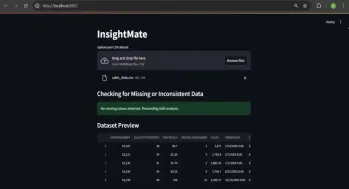 Insightmateでデータの洞察を自動化しますApr 12, 2025 am 10:44 AM
Insightmateでデータの洞察を自動化しますApr 12, 2025 am 10:44 AM導入 今日のデータが多い世界では、巨大なデータセットの処理はかなり圧倒される可能性があります。それが洞察客の出番です。それはあなたのデータを簡単にするように設計されています。データセットをアップロードするだけで、Instanが表示されます
 ベクトルストリーミング:錆を使用したメモリ効率の高いインデックスApr 12, 2025 am 10:42 AM
ベクトルストリーミング:錆を使用したメモリ効率の高いインデックスApr 12, 2025 am 10:42 AM導入 埋め込みのベクトルストリーミングが導入されています。これは、大規模なドキュメントの埋め込みを最適化するように設計されています。 Rustの並行性を使用して非同期チャンクと埋め込みを可能にすると、メモリの使用が減少し、
 レプリットエージェントとは何ですか? |入門ガイド - 分析VidhyaApr 12, 2025 am 10:40 AM
レプリットエージェントとは何ですか? |入門ガイド - 分析VidhyaApr 12, 2025 am 10:40 AM導入 会話と同じように簡単にアプリを開発することを想像してください。セットアップする複雑な開発環境はなく、構成ファイルを調べる必要はありません。コンセプトを貴重なアプリに変換する
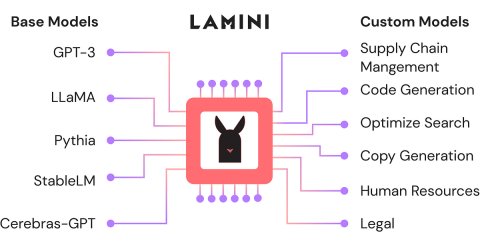 ラミニを使用してオープンソースLLMを微調整します。分析vidhyaApr 12, 2025 am 10:20 AM
ラミニを使用してオープンソースLLMを微調整します。分析vidhyaApr 12, 2025 am 10:20 AM最近、大規模な言語モデルとAIの台頭により、自然言語処理における無数の進歩が見られました。テキスト、コード、画像/ビデオ生成などのドメインのモデルは、人間のような推論とPをアーカイブしています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SublimeText3 中国語版
中国語版、とても使いやすい

