

 テクノロジー周辺機器AIリチャード・サットンは、畳み込みバックプロパゲーションは遅れをとっており、AI のブレークスルーには新しいアイデア、つまり連続バックプロパゲーションが必要であると率直に述べました。
テクノロジー周辺機器AIリチャード・サットンは、畳み込みバックプロパゲーションは遅れをとっており、AI のブレークスルーには新しいアイデア、つまり連続バックプロパゲーションが必要であると率直に述べました。リチャード・サットンは、畳み込みバックプロパゲーションは遅れをとっており、AI のブレークスルーには新しいアイデア、つまり連続バックプロパゲーションが必要であると率直に述べました。

「可塑性の喪失」は、ディープ ニューラル ネットワークの最も一般的に批判される欠点の 1 つであり、ディープ ラーニングに基づく AI システムが学習を継続できないと考えられる理由の 1 つでもあります。
人間の脳にとって、「可塑性」とは、新しいニューロンとニューロン間の新しい接続を生成する能力を指し、これは継続的な学習の重要な基盤です。年齢を重ねるにつれて、脳の可塑性は徐々に低下し、学んだことを定着させることができなくなります。ニューラルネットワークも同様です。
鮮明な例は、2020 年のウォームスタート トレーニングが証明されたことです。最初に学習した内容を破棄し、データ全体を一度に学習することによってのみ、集中的なトレーニングを通じてのみ、より良い学習を達成できます。結果。
深層強化学習 (DRL) では、AI システムは多くの場合、ニューラル ネットワークによって以前に学習されたすべてのコンテンツを「忘れ」、コンテンツの一部だけを再生に保存する必要があります。バッファから、そしてゼロからの継続的な学習を実現します。このネットワークのリセット方法は、深層学習が学習を継続できないことを証明しているとも考えられます。
では、学習システムの柔軟性を維持するにはどうすればよいでしょうか?
最近、強化学習の父であるリチャード・サットンは、CoLLAs 2022 カンファレンスで「深層継続学習における可塑性の維持」と題した講演を行い、この問題を解決できると考えられることを提案しました。答え: 連続逆伝播アルゴリズム (連続逆伝播)。
リチャード・サットンは、最初にデータセットの観点から可塑性損失の存在を証明し、次にニューラルネットワーク内から可塑性損失の原因を分析し、最後に連続的な可塑性の損失を解決する方法としての逆伝播アルゴリズム: 有用性の低い少数のニューロンを再初期化する この多様性の継続的な注入により、深いネットワークの可塑性を無期限に維持できます。
以下は、元の意味を変えることなく AI Technology Review によって編集されたスピーチの全文です。
1 可塑性損失の実際の存在
ディープラーニングは本当に継続学習の問題を解決できるのでしょうか?
答えは「いいえ」です。主に次の 3 つの点で次のとおりです。
- 「解決不可能」とは、深さのない線形ネットワークを指します。学習速度は最終的には非常に遅くなります;
- 深層学習で使用される専門的な標準化された手法は、1 回限りの学習でのみ効果があり、継続的な学習に反します;
- リプレイ キャッシュ自体は、ディープ ラーニングが実現不可能であることを認める極端な方法です。
したがって、この新しい学習モデルに適したより良いアルゴリズムを見つけて、1 回限りの学習の制限を取り除く必要があります。
まず、分類タスクに ImageNet と MNIST データ セットを使用し、回帰予測を実装し、連続学習効果を直接テストして、教師あり学習における可塑性損失の存在を証明しました。 。
ImageNet データセット テスト
ImageNet は、名詞でタグ付けされた何百万もの画像を含むデータセットです。カテゴリごとに 700 以上の画像を含む 1,000 のカテゴリがあり、カテゴリ学習とカテゴリ予測に広く使用されています。
以下は、32*32 サイズにダウンサンプリングされたサメの写真です。この実験の目的は、深層学習の実践からの最小限の変更を見つけることです。各カテゴリの 700 枚の画像を 600 個のトレーニング サンプルと 100 個のテスト サンプルに分割し、次に 1000 個のカテゴリを 2 つのグループに分けて、長さ 500 の二値分類タスク シーケンスを生成しました。すべてのデータ セットの順序がランダムに乱れていました。各タスクのトレーニング後、テスト サンプルでモデルの精度を評価し、独立して 30 回実行し、次の二値分類タスクに入る前に平均値を取得します。

500 個の分類タスクは同じネットワークを共有します。複雑さの影響を排除するために、タスク切り替え後にヘッド ネットワークがリセットされます。標準的なネットワーク、つまり 3 層の畳み込み層と 3 層の全結合層を使用しますが、1 つのタスクに 2 つのカテゴリのみが使用されるため、ImageNet データセットの出力層は比較的小さい可能性があります。各タスクでは、100 個のサンプルごとがバッチとして取得され、合計 12 個のバッチと 250 エポックのトレーニングが行われます。最初のタスクを開始する前に、Kaiming 分布を使用して重みを初期化する初期化が 1 回だけ実行されます。クロスエントロピー損失には運動量ベースの確率的勾配降下法が使用され、ReLU 活性化関数が使用されます。
ここで 2 つの疑問が生じます:
1. タスク シーケンスのパフォーマンスはどのように変化しますか?
2. どのタスクのパフォーマンスが向上しますか?最初の最初のミッションのほうが良いでしょうか?それとも、後続のタスクは前のタスクの経験から恩恵を受けるでしょうか?
次の図は答えを示しています。継続学習のパフォーマンスは、トレーニング ステップ サイズとバックプロパゲーションによって総合的に決定されます。
これはバイナリ分類問題であるため、確率は 50% で、影付きの領域は標準偏差を表しますが、これは重要ではありません。線形ベンチマークでは、線形レイヤーを使用してピクセル値を直接処理しますが、ディープ ラーニング手法ほど効果的ではありませんが、この違いは重要です。
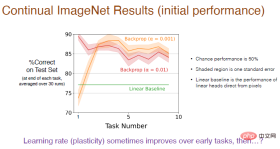
注: 小さい学習率 (α=0.001) を使用すると、最初の 5 つのタスクの精度が高くなります。パフォーマンスは徐々に向上します。 , しかし、長期的には減少する傾向があります。
その後、タスク数を 2000 に増やし、継続学習効果に対する学習率の影響をさらに分析し、50 タスクごとの平均精度を計算しました。結果を以下に示します。
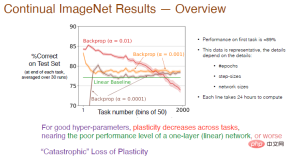
# 凡例: 最初のタスクの α=0.01 の赤い曲線の精度は約 89% です。 50 を超えると精度が低下し、タスクの数がさらに増加すると、可塑性が徐々に失われ、最終的な精度は線形ベースラインよりも低くなります。 α=0.001の場合、学習速度が遅くなり、可塑性も急激に低下し、精度は線形ネットワークよりもわずかに高くなるだけです。
したがって、適切なハイパーパラメータの場合、タスク間の可塑性が減衰し、ニューラル ネットワークの 1 層のみを使用する場合よりも精度が低くなります。赤い曲線は、ほぼ「」であることを示しています。可塑性の壊滅的な損失。」
トレーニング結果は、反復数、ステップ数、ネットワーク サイズなどのパラメーターにも依存します。図の各曲線のトレーニング時間は、複数のトレーニングで 24 時間です。システムを実行するとき 性的実験では実用的ではない可能性があるため、次にテスト用に MNIST データ セットを選択します。
MNIST データ セット テストMNIST データ セットには、0 から 9 までの 10 のカテゴリを持つ合計 60,000 個の手書き数字画像が含まれており、28*28 のグレースケール画像です。 . .
Goodfellow らは、順序をシャッフルしたり、ピクセルをランダムに配置したりして、新しいテスト タスクを作成しました。右下の画像は、生成された配置画像の例です。これを採用します。タスク シーケンス全体を生成するには、各タスクで 6000 枚の画像がランダムに表示されます。ここではタスクの内容は追加されず、ネットワークの重みは最初のタスクの前に 1 回だけ初期化されます。オンラインのクロスエントロピー損失をトレーニングに使用でき、精度指標を使用して継続学習の効果を測定し続けることができます。

ニューラル ネットワーク構造は 4 つの完全に接続された層で、最初の 3 層のニューロンの数は 2000、次の層のニューロンの数は 2000 です。最後の層は10です。 MNIST データセットの画像は中心に配置され、スケーリングされるため、畳み込み演算は実行されません。すべての分類タスクは、運動量のない確率的勾配降下法を使用して同じネットワークを共有し、その他の設定は ImageNet データセットでテストされたものと同じです。
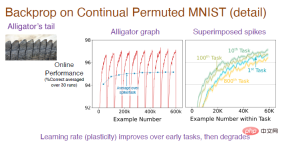
注: 中央の図は、タスク シーケンスを独立して 30 回実行し、平均を取った結果です。各タスクには 6000 のサンプルがあります。分類タスクであるため、最初のランダムな推測は次のとおりです。予測精度は10%で、モデルが画像の配置ルールを学習すると予測精度は徐々に上がっていきますが、タスクを切り替えると精度が10%に低下するため、全体の傾向は常に変動しています。右の図は各タスクに対するモデルの学習効果を示しており、初期精度は 0 ですが、時間の経過とともに徐々に効果が向上します。 10 番目のタスクの精度は 1 番目のタスクよりも優れていますが、100 番目のタスクでは精度が低下し、800 番目のタスクの精度は最初のタスクよりもさらに低くなります。
プロセス全体を理解するには、凸部分の精度の分析に焦点を当て、それを平均して中間画像の青い曲線を取得する必要があります。最初は精度が徐々に向上し、100 番目のタスクまでは横ばいになることがはっきりとわかります。では、なぜ 800 回目のタスクで精度が急激に低下するのでしょうか?
次に、学習効果をさらに観察するために、より多くのタスク シーケンスで異なるステップ値を試しました。結果は次のとおりです。
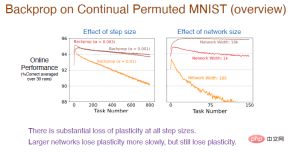
注: 赤い曲線は前の実験と同じステップ値を使用しており、精度は実際に塑性損失は比較的大きい。
#同時に、学習率が高くなるほど、可塑性はより早く低下します。すべてのステップ サイズ値で大きな塑性損失が発生します。さらに、隠れ層のニューロンの数も精度に影響します。茶色の曲線のニューロンの数は 10,000 です。ニューラル ネットワークのフィッティング能力が強化されているため、この時点では精度は非常にゆっくりと低下します。ただし、ネットワークのサイズが大きくなるほど、サイズが小さくなるほど、可塑性はより早く低下します。
では、ニューラル ネットワークの内部から見て、なぜ可塑性が失われるのでしょうか?
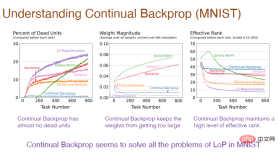
下の図でその理由を説明します。 「死んだ」ニューロンの過剰な数、ニューロンの過剰な重量、およびニューロンの多様性の損失はすべて、可塑性損失の原因であることがわかります。
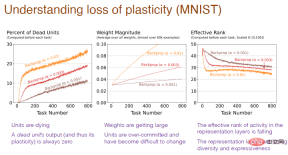
# 注: 横軸は引き続きタスク番号を表し、最初の図の縦軸は「死」を表します。 " 神経 ニューロンのパーセンテージ。「死んだ」ニューロンは、出力と勾配が常に 0 であり、ネットワークの可塑性を予測できないニューロンです。 2 番目のグラフの縦軸は重量を表します。 3 番目のグラフの縦軸は、残りの隠れニューロンの数の実効レベルを表します。
2 既存手法の限界
バックプロパゲーション以外の既存の深層学習手法が可塑性の維持に役立つかどうかを分析しました。
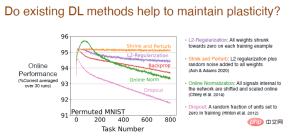
結果は、L2 正則化法が可塑性損失を軽減し、プロセス中に重みを 0 に減らし、動的に実行できることを示しています。調整され、展性を維持します。
収縮法と摂動法は L2 正則化に似ていますが、基本的に可塑性を失うことなく、すべての重みにランダム ノイズを追加して多様性を高めます。
他のオンライン標準化手法も試しましたが、最初は比較的うまくいきましたが、学習が進むにつれて可塑性の損失が深刻になりました。 Dropout 法の性能はさらに悪く、一部のニューロンをランダムに 0 に設定して再学習したところ、可塑性損失が急激に増加することがわかりました。
さまざまな方法は、ニューラル ネットワークの内部構造にも影響を与えます。正則化手法を使用すると、「死んだ」ニューロンの割合が増加します。これは、重みを 0 に縮小する過程で重みが 0 に留まると、出力が 0 になり、ニューロンが「死滅」するためです。また、収縮と摂動によって重みにランダムなノイズが追加されるため、「死んだ」ニューロンがそれほど多くなくなります。正規化方法も「死んだ」ニューロンが多く、間違った方向に進んでいるように見えますが、ドロップアウトも同様です。
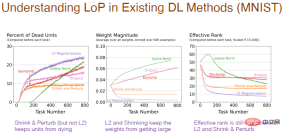
タスクの数に応じて重みが変化する結果はより合理的です。正則化を使用すると、非常に小さな重みが得られます。収縮と摂動は正則化に基づいてノイズを追加し、重みの減少は比較的弱まります。標準化すると重みが増します。しかし、L2正則化、収縮、摂動については、隠れニューロン数の実効レベルが比較的低く、多様性を維持する性能が低いことが問題となっている。
ゆっくりと変化する回帰問題 (SCR)
すべてのアイデアとアルゴリズムは、ゆっくりと変化する回帰問題実験から派生したもので、これは新しい理想化されたものです。継続的な学習に焦点を当てた質問。
この実験では、ランダムな重みをもつ単層ニューラル ネットワークによって形成された目的関数を達成することが目的であり、隠れ層ニューロンは 100 個の線形閾値ニューロンです。
分類は行っておらず、数値を生成しただけであるため、これは回帰問題です。 10,000 トレーニング ステップごとに、反転する入力の最後の 15 ビットから 1 ビットを選択するため、これはゆっくりと変化する目的関数です。
私たちの解決策は、同じネットワーク構造を使用し、ニューロンの隠れ層を 1 つだけ含み、活性化関数が微分可能であることを保証することですが、隠れ層ニューロンは 5 つになります。 。 これは RL と似ています。エージェントの探索範囲は対話環境に比べて非常に狭いため、近似的な処理しか実行できません。目的関数が変化した場合は、近似値を変更してみてください。そうすることで処理が容易になります。いくつかの体系的な実験を行うためです。
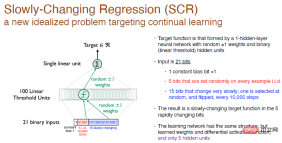
# 凡例: 入力は 21 ビットのランダムな 2 進数で、最初のビットは値 1 の入力定数偏差です。 、中央の 5 ビットは独立した同一分布の乱数、他の 15 ビットはゆっくりと変化する定数で、出力は実数です。重みは 0 にランダム化され、1 または -1 をランダムに選択できます。
ステップ値と活性化関数の変更が学習効果に及ぼす影響をさらに研究しました。たとえば、ここでは、tanh、sigmoid、relu 活性化関数が使用されています:
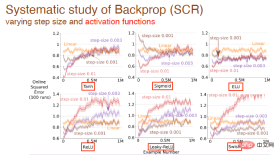
およびすべてのアルゴリズムの学習効果に対する活性化関数形式の影響:
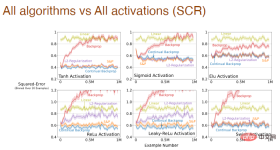
ステップ サイズと活性化関数が同時に変化する場合、Adam バックプロパゲーションの影響の体系的な分析も行いました。
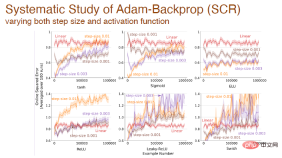
最後に: 異なる活性化関数を使用した後、Adam メカニズムに基づいて異なるアルゴリズム間で誤差が変化します:
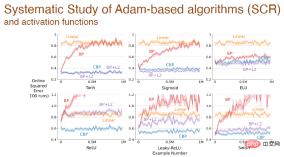
上記の実験結果は、 深層学習 この方法は、もはや継続的な学習には適していません。 新しい問題に遭遇すると、学習プロセスが非常に遅くなり、深さの利点が反映されなくなります。深層学習における標準化された手法は一度限りの学習にのみ適しており、継続的な学習に使用できるように深層学習の手法を改良する必要があります。
3 連続バックプロパゲーション
畳み込みバックプロパゲーション アルゴリズム自体は、優れた連続学習アルゴリズムになりますか?
#私たちはそうではないと考えています。
畳み込みバックプロパゲーション アルゴリズムには、主に、小さなランダムな重みによる初期化と各タイム ステップでの勾配降下という 2 つの側面が含まれています。最初に小さな乱数を生成して重みを初期化しますが、それが再度繰り返されることはありません。理想的には、いつでも同様の計算を実行できる学習アルゴリズムが必要になるかもしれません。では、畳み込み逆伝播アルゴリズムを継続的に学習させるにはどうすればよいでしょうか?
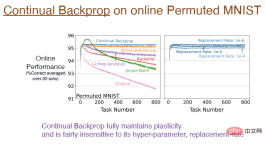
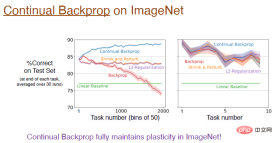
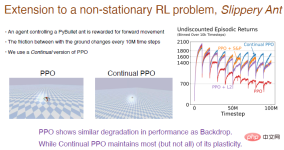
最も簡単な方法は、 いくつかのタスクを実行した後に初期化するなど、 選択的に再初期化することです。しかし同時に、ネットワーク全体を再初期化することは、ニューラル ネットワークが学習したすべてを忘れることを意味するため、継続的な学習においては合理的ではない可能性があります。したがって、ニューラル ネットワークの一部を選択的に初期化する方がよいでしょう。たとえば、いくつかの「死んだ」ニューロンを再初期化するか、ユーティリティに従ってニューラル ネットワークを並べ替えて、ユーティリティの低いニューロンを再初期化するなどです。 ランダム選択の初期化のアイデアは、2012 年に Mahmood と Sutton によって提案された生成およびテスト方法に関連しています。必要なのは、いくつかのニューロンを生成し、その実用性をテストすることだけです。連続バックプロパゲーション アルゴリズムは、これら 2 つの概念の間の橋渡しとして構築されます。生成とテストの方法にはいくつかの制限があり、隠れ層と出力ニューロンを 1 つだけ使用し、いくつかの深層学習方法で最適化できる多層ネットワークに拡張します。 最初に、ネットワークを単一の出力ではなく複数のレイヤーに設定することを検討します。 前の研究では、効用の概念について言及しました。重みが 1 つしかないため、この効用は重みレベルの概念にすぎません。ただし、複数の重みがあります。最も単純な一般化は、重みの合計レベルで効用を考慮することです。 もう 1 つのアイデアは、出力の重みだけでなく特徴のアクティビティを 考慮して、重みの合計に平均特徴活性化関数を乗算することです。したがって、異なる比率を割り当てます。私たちは学習を続けて高速に実行し続けることができるアルゴリズムを設計したいと考えており、有用性を計算する際には特徴の可塑性も考慮します。最後に、特徴の平均寄与が出力バイアスに転送され、特徴の削除の影響が軽減されます。 グローバルに効用を測定することと ニューラルな影響を測定する必要がある表現される関数全体の要素の数は、入力重み、出力重み、活性化関数などの局所的な尺度に限定されません; (2) ジェネレーターをさらに改善する必要があります。現在は初期分布からのみサンプリングが実行されます。パフォーマンスを向上させる初期化方法についても検討します。 実験結果は、連続バックプロパゲーションがオンラインで配置された MNIST データセットを使用してトレーニングされ、 が可塑性を完全に維持することを示しています。 下の図の青い曲線は、この結果を示しています。 注: 右側の図は、継続学習に対するさまざまな置換率の影響を示しています。たとえば、1e の置換率-6 は、毎回のステップが 1/1000000 の表現を置き換えることを意味します。つまり、2000 個の特徴があると仮定すると、500 ステップごとに各層で 1 つのニューロンが置き換えられます。この更新速度は非常に遅いため、置換率はハイパーパラメータの影響をあまり受けず、学習効果に大きな影響を与えません。 連続バックプロパゲーションでは、「死んだ」ニューロンはほとんどありません。 ユーティリティは平均的な機能のアクティブ化を考慮するため、ニューロンが「死んだ」場合は、すぐに置き換えられます。そして、ニューロンを置き換え続けるため、より小さな重みを持つ新しいニューロンが得られます。ニューロンはランダムに初期化されるため、それに応じてより豊かな表現と多様性が保持されます。 では、連続バックプロパゲーションはより深い畳み込みニューラル ネットワークに拡張できるでしょうか? #答えは「はい」です。 ImageNet データセットでは、連続バックプロパゲーションによって可塑性が完全に保存され、モデルの最終精度は約 89% でした。実際、初期トレーニング段階では、これらのアルゴリズムのパフォーマンスは同等ですが、前述したように、置換率の変化は非常にゆっくりであり、タスクの数が十分に大きい場合にのみ近似がより良くなります。 ここでは、「Slippery Ant」問題を例として、強化学習の実験結果を示します。 「滑りやすいアリ」問題は、非定常補強問題の拡張であり、基本的に PyBullet 環境と似ています。唯一の違いは、地面とエージェントの間の摩擦です。 1,000万歩ごとに増加し、変化が起こります。選択的に初期化できる、連続逆伝播に基づく PPO アルゴリズムの連続学習バージョンを実装しました。 PPO アルゴリズムと連続 PPO アルゴリズムの比較結果は次のとおりです。 注: PPO アルゴリズムは、最初は良好なパフォーマンスを示しましたが、トレーニングが進むにつれてパフォーマンスは低下し続けました。と収縮が導入され、摂動アルゴリズムが緩和されます。連続 PPO アルゴリズムは比較的良好に実行され、可塑性の大部分が維持されました。 興味深いのは、PPO アルゴリズムによってトレーニングされたエージェントは歩くのに苦労することしかできないのに対し、PPO アルゴリズムによって継続的にトレーニングされたエージェントは非常に遠くまで走ることができるということです。 深層学習ネットワークは主に 1 回限りの学習に最適化されており、ある意味、継続的な学習にはまったく役に立たない可能性があります。 。 失敗。正規化やドロップアウトなどの深層学習手法は継続学習には役に立たない可能性がありますが、連続逆伝播など、これに基づいていくつかの小さな改善を行うことは非常に効果的です。 連続バックプロパゲーションは、ニューロンの有用性に応じてネットワークの特徴を並べ替えます。特にリカレント ニューラル ネットワークの場合、並べ替え方法にはさらに改善が加えられる可能性があります。 強化学習アルゴリズムは、ポリシー反復のアイデアを利用しています。継続的な学習の問題は存在しますが、深層学習ネットワークの可塑性を維持することで、RL とモデルベースの RL に大きな新たな可能性が開かれます。 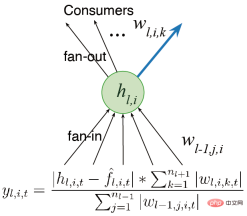
4 結論
以上がリチャード・サットンは、畳み込みバックプロパゲーションは遅れをとっており、AI のブレークスルーには新しいアイデア、つまり連続バックプロパゲーションが必要であると率直に述べました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AM
Huggingface smollmであなたの個人的なAIアシスタントを構築する方法Apr 18, 2025 am 11:52 AMオンデバイスAIの力を活用:個人的なチャットボットCLIの構築 最近では、個人的なAIアシスタントの概念はサイエンスフィクションのように見えました。 ハイテク愛好家のアレックスを想像して、賢くて地元のAI仲間を夢見ています。
 メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AM
メンタルヘルスのためのAIは、スタンフォード大学でのエキサイティングな新しいイニシアチブによって注意深く分析されますApr 18, 2025 am 11:49 AMAI4MHの最初の発売は2025年4月15日に開催され、有名な精神科医および神経科学者であるLuminary Dr. Tom Insel博士がキックオフスピーカーを務めました。 Insel博士は、メンタルヘルス研究とテクノでの彼の傑出した仕事で有名です
 2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM
2025年のWNBAドラフトクラスは、成長し、オンラインハラスメントの成長と戦いに参加しますApr 18, 2025 am 11:44 AM「私たちは、WNBAが、すべての人、プレイヤー、ファン、企業パートナーが安全であり、大切になり、力を与えられたスペースであることを保証したいと考えています」とエンゲルバートは述べ、女性のスポーツの最も有害な課題の1つになったものに取り組んでいます。 アノ
 Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM
Pythonビルトインデータ構造の包括的なガイド-AnalyticsVidhyaApr 18, 2025 am 11:43 AM導入 Pythonは、特にデータサイエンスと生成AIにおいて、プログラミング言語として優れています。 大規模なデータセットを処理する場合、効率的なデータ操作(ストレージ、管理、アクセス)が重要です。 以前に数字とstをカバーしてきました
 Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM
Openaiの新しいモデルからの代替案からの第一印象Apr 18, 2025 am 11:41 AM潜る前に、重要な注意事項:AIパフォーマンスは非決定論的であり、非常にユースケース固有です。簡単に言えば、走行距離は異なる場合があります。この(または他の)記事を最終的な単語として撮影しないでください。これらのモデルを独自のシナリオでテストしないでください
 AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM
AIポートフォリオ| AIキャリアのためにポートフォリオを構築する方法は?Apr 18, 2025 am 11:40 AM傑出したAI/MLポートフォリオの構築:初心者と専門家向けガイド 説得力のあるポートフォリオを作成することは、人工知能(AI)と機械学習(ML)で役割を確保するために重要です。 このガイドは、ポートフォリオを構築するためのアドバイスを提供します
 エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM
エージェントAIがセキュリティ運用にとって何を意味するのかApr 18, 2025 am 11:36 AM結果?燃え尽き症候群、非効率性、および検出とアクションの間の隙間が拡大します。これは、サイバーセキュリティで働く人にとってはショックとしてはありません。 しかし、エージェントAIの約束は潜在的なターニングポイントとして浮上しています。この新しいクラス
 Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM
Google対Openai:学生のためのAIの戦いApr 18, 2025 am 11:31 AM即時の影響と長期パートナーシップ? 2週間前、Openaiは強力な短期オファーで前進し、2025年5月末までに米国およびカナダの大学生にChatGpt Plusに無料でアクセスできます。このツールにはGPT ‑ 4o、Aが含まれます。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

